类型推断
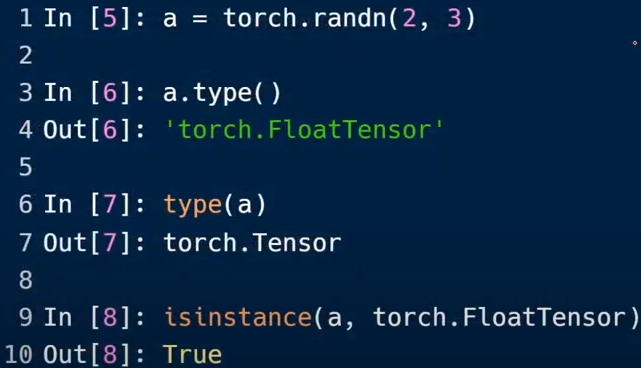
torch.randn():随机初始化
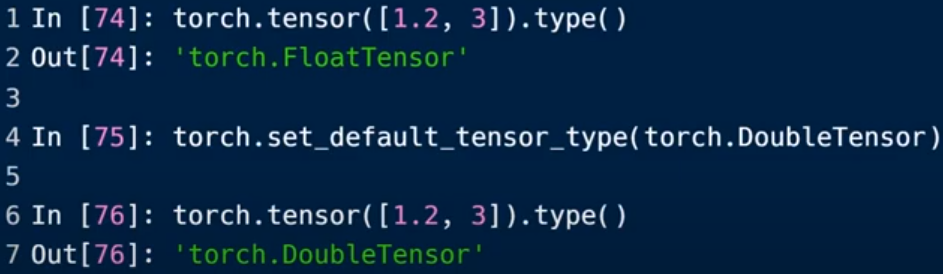
a.type():返回类型
type():返回基本类型
isinstance() :检查类型
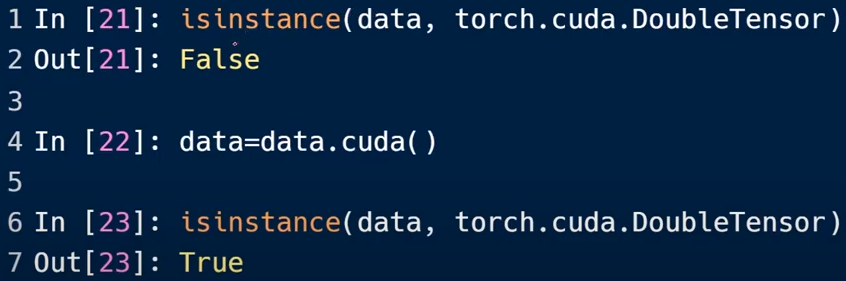
cuda会影响数据类型
标量

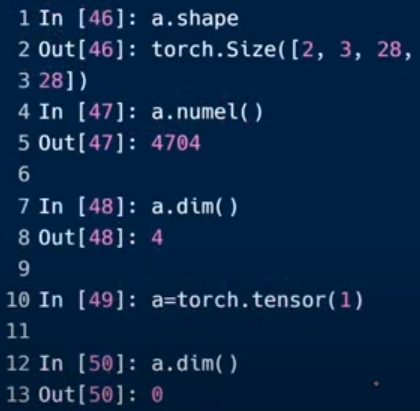
维度(dimention)为0的标量
标量的shape:
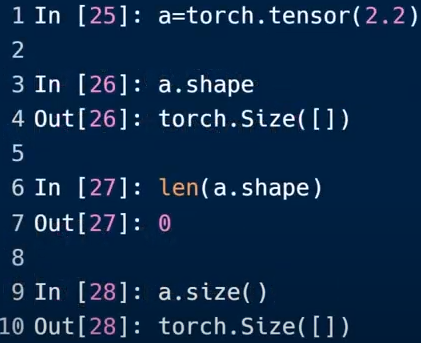
返回类型为【】(空的list),返回长度也为0
a.dimension()也为0
Dim1

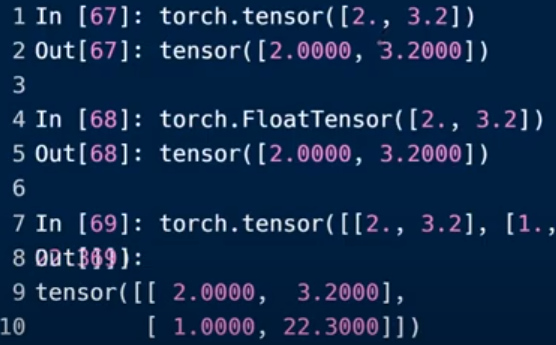
torch.tensor() : 输入具体数据
torch.FloatTensor() :输入类型大小
Dim1的shape

Dim2
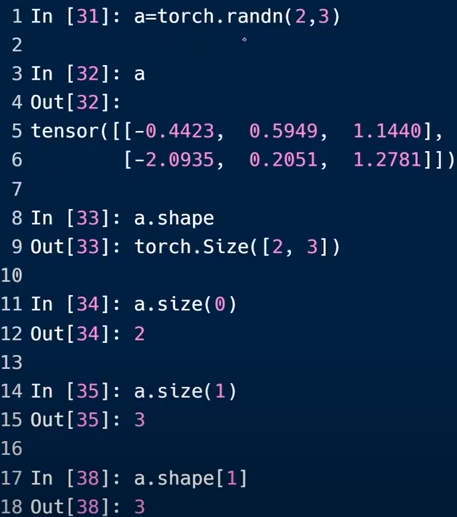
Dim3
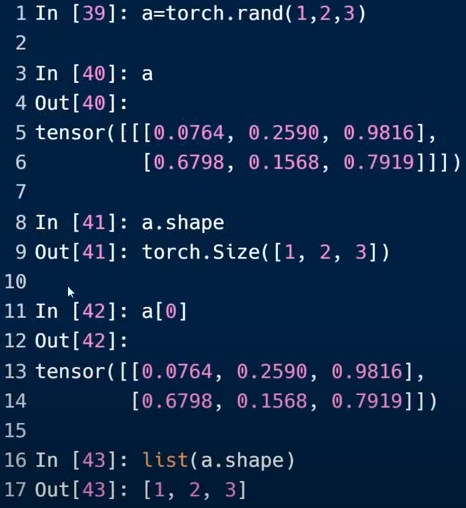
Dim4(一般用于图像)
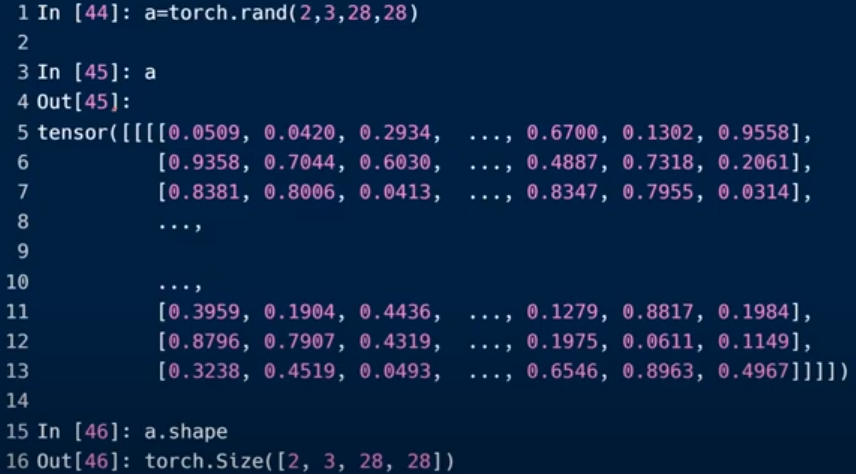
创建Tensor
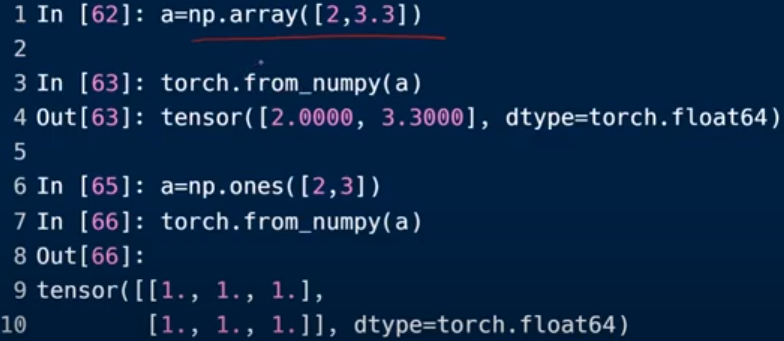
import from numpy
从numpy转化为tensor类型, 数据类型(float)不变,变量类型(np→numpy)变了
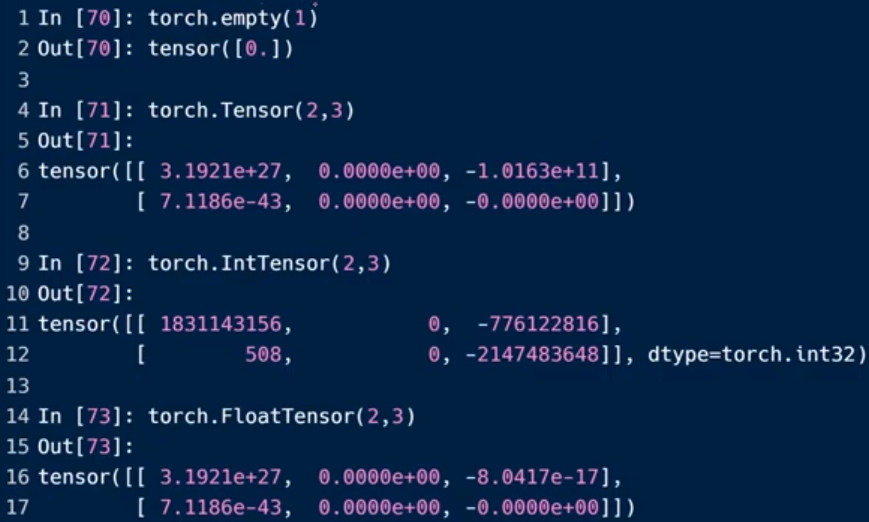
生成未初始化tensor
设置默认类型
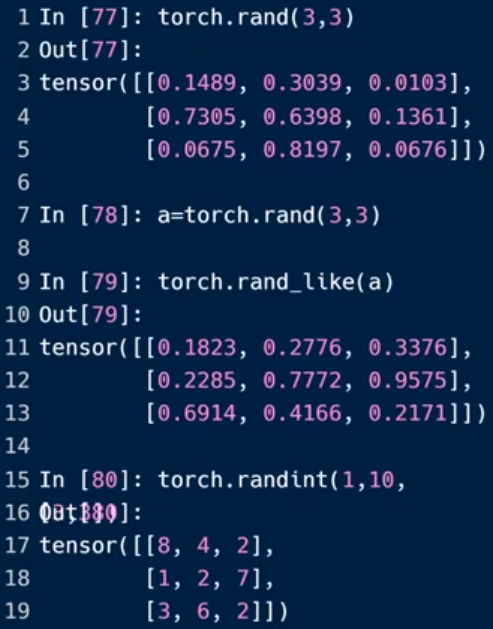
随机初始化
torch.rand() :随机采样【0,1】之间的数
torch.rand_like(a): 采样出与a相同类型的tensor
torch.randint(min,max,[type]):不包含最大值
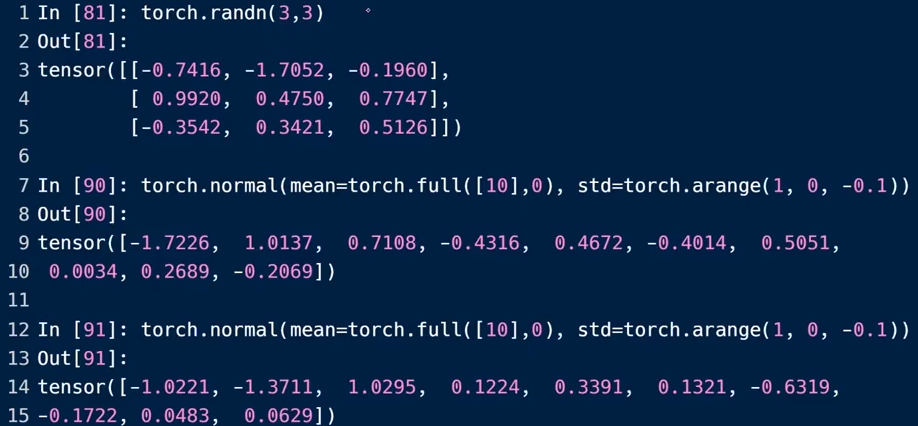
正态分布随机初始化
torch.normal(mean,std): 自定义的正态分布,需要给出相同数量的均值和方差
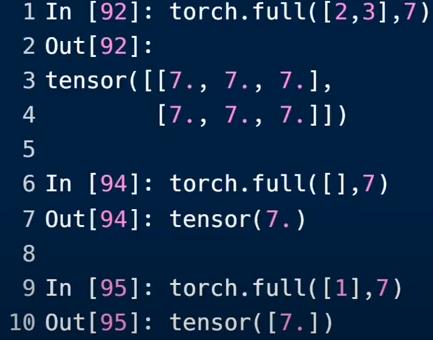
重复填充
torch.full():类型为[]时,表示生成的为标量
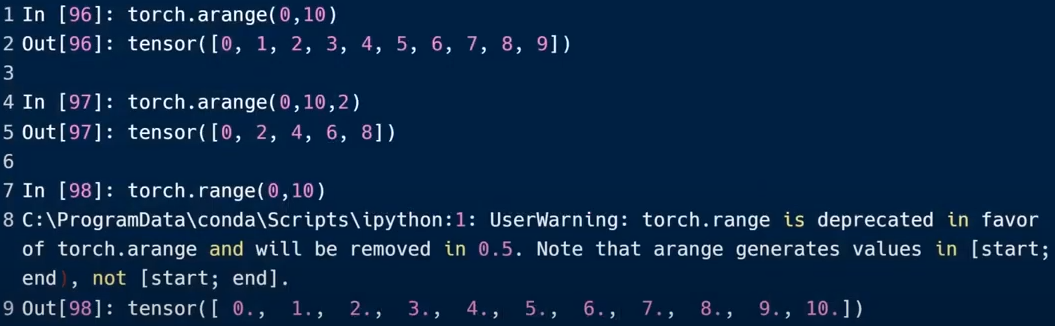
范围
torch.arange():生成不包含最大值的等差数列
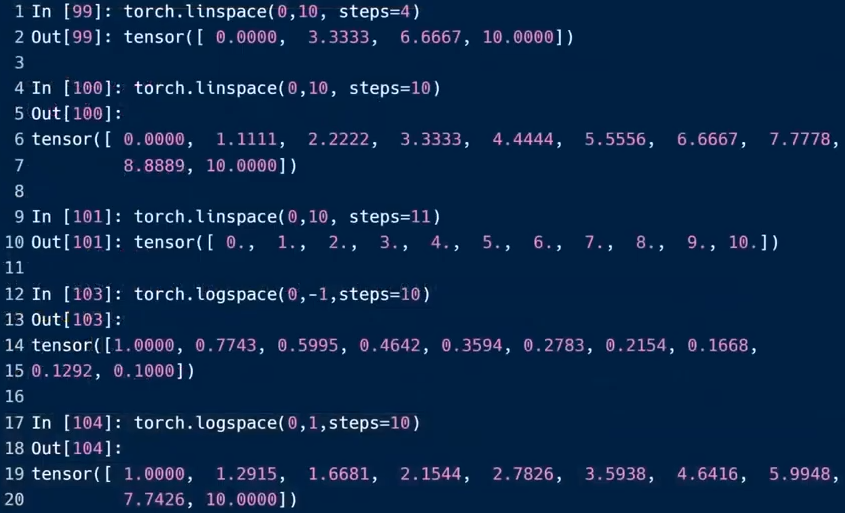
torch,linspace(min,max,steps= ):包含最大值,steps是切分后的数量
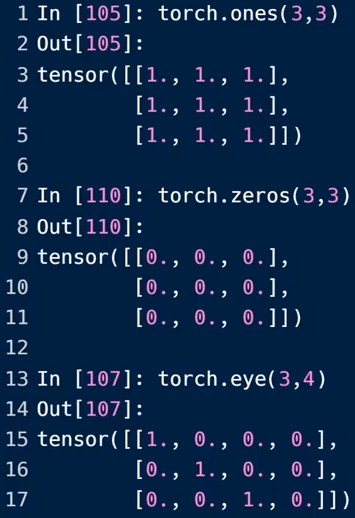
全1/零/单位矩阵
torch.eye():中如果不是方阵,多余部分为0
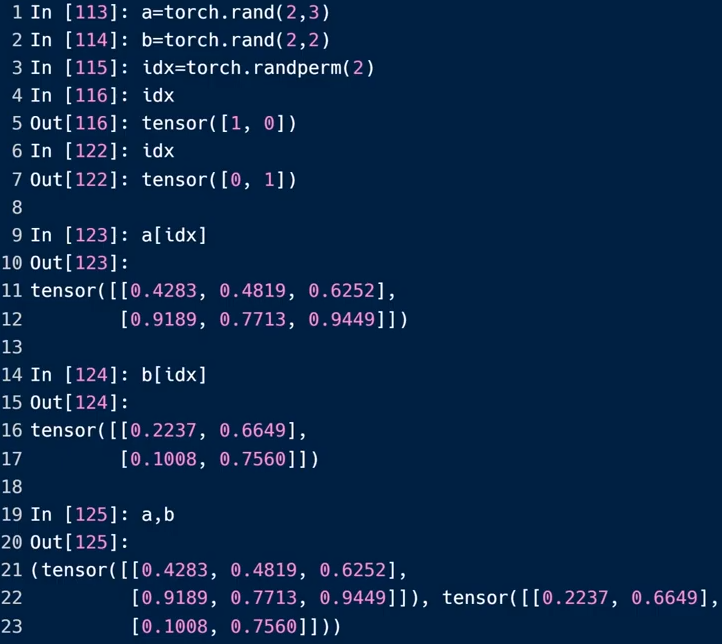
随机打散
torch.randperm(): 生成不包含最大值的索引

下面对第一维进行shuffle,randperm中的参数必须与类型的第一维相同。a和b的idx相同,防止匹配错误
下图表示,randperm中定义需要两个索引时,分别返回a b的对应索引值
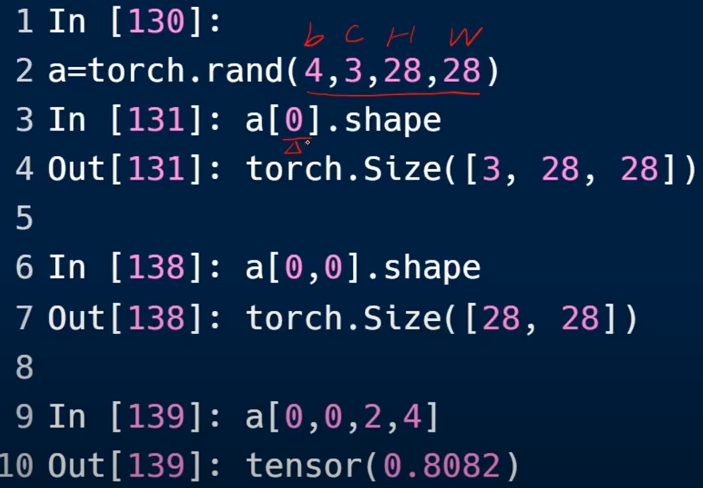
切片和索引
索引
取不到“ :”后的元素
-1表示最后一个元素
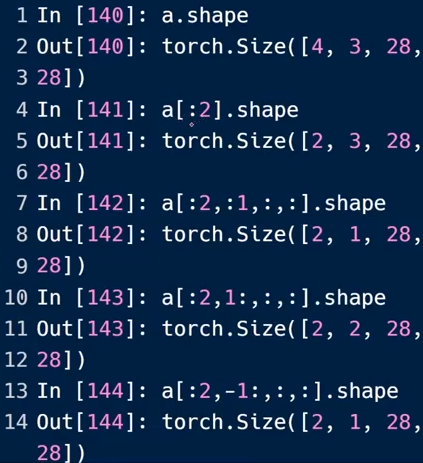
分段采样
出现两个“:”表示的是:start :end :step(默认为1,为1可省略)
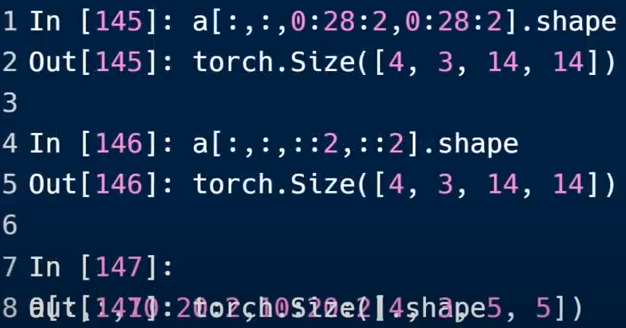
指定维度采样
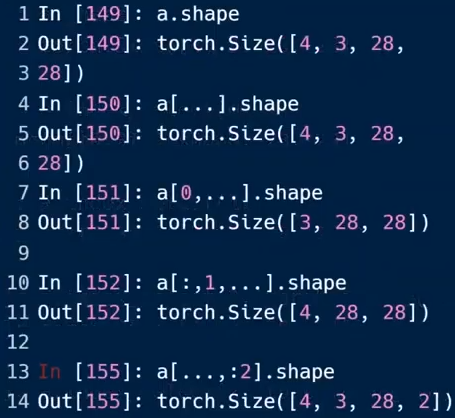
“ ...”:表示同时取多个维度,只能全选或已知前后具体采样维度,剩下的全选,某一维度取“1”时,会自动降维
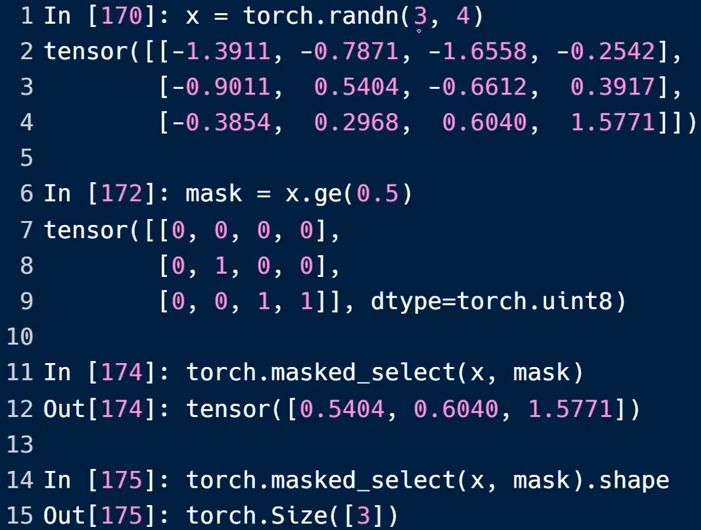
根据MASK选择
先根据条件,得到一定的掩码,根据满足条件的掩码值重新在原始数据中进行选择
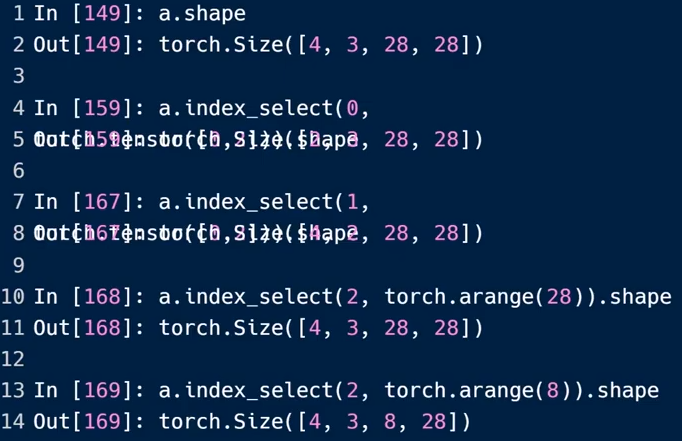
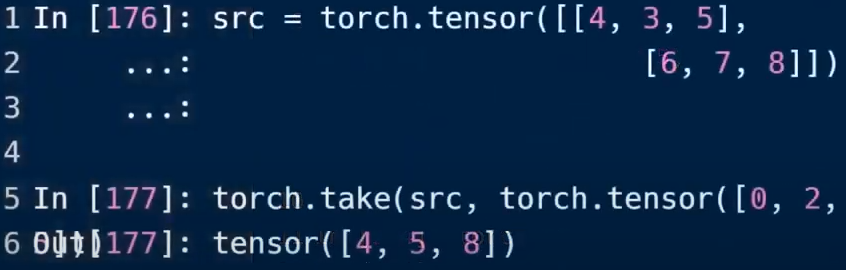
铺展(Flatten)索引值
纬度变化
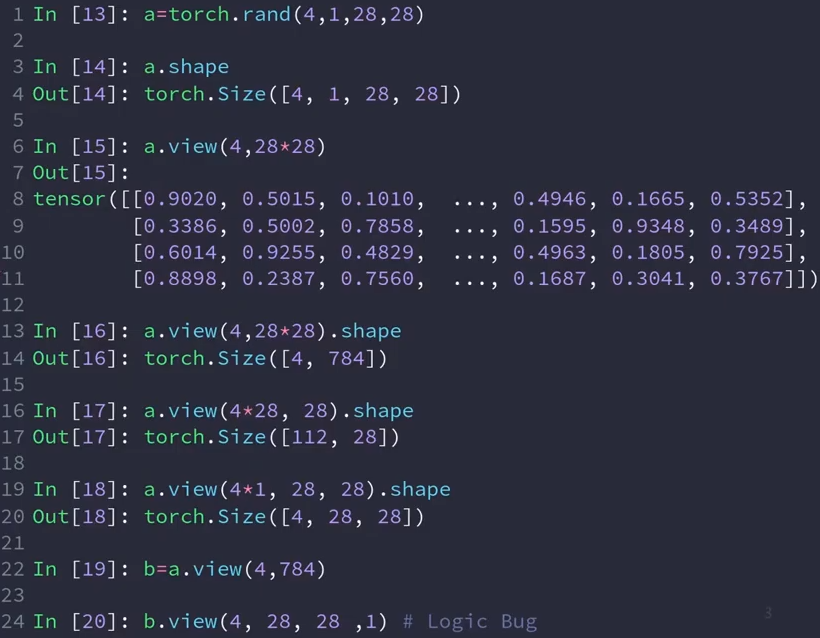
View Reshape

增维(Unsqueeze)
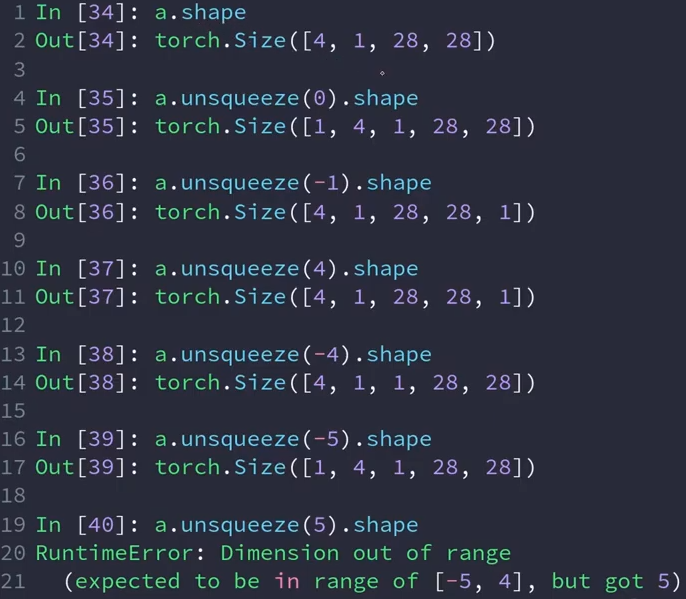
下面的a为标量,在第0维与第1维添加维度后,分别会变为[1,2] [2,1]
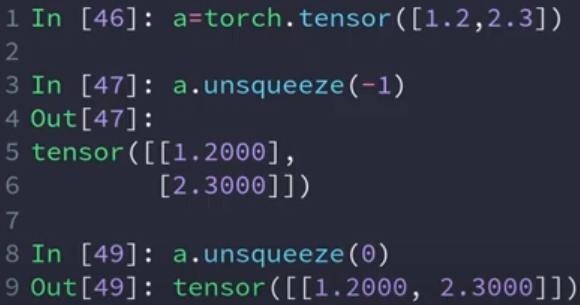
下面是bias向权重类型变化过程
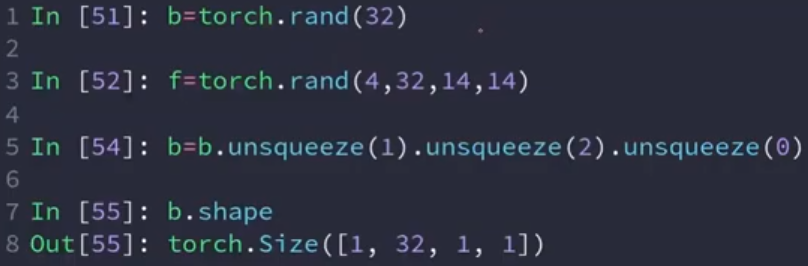
降维(squeeze)
如果没有具体参数,将去除所有为“1”的维度
带有参数,将对对应维度进行去除
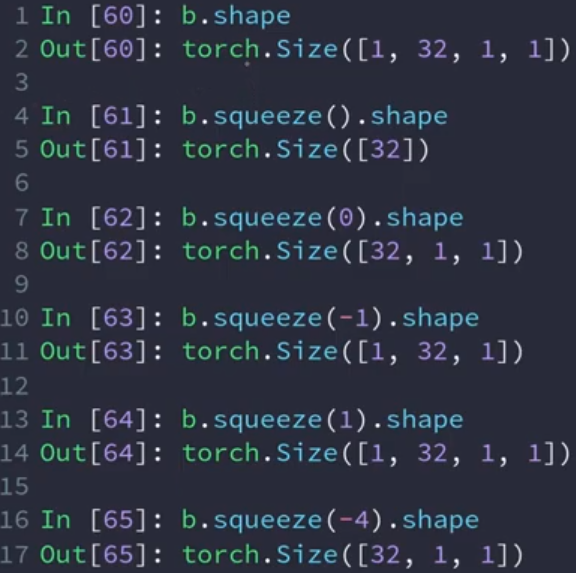
扩展(expand)
总维度必须相同,且只能从1维度扩展到指定维度或直接相同
“-1”保持原来维度不变
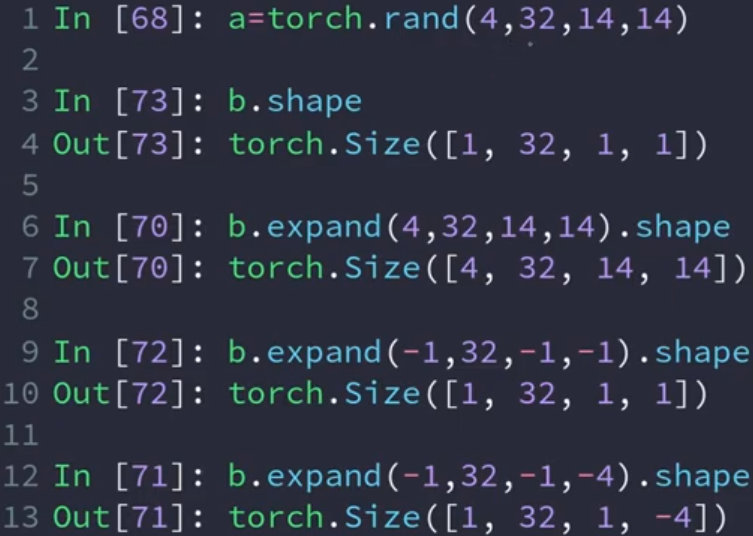
重复(repeat)
与expand参数不同,每个维度的值表示对对应维度进行的重复次数。
矩阵转置(transpose)
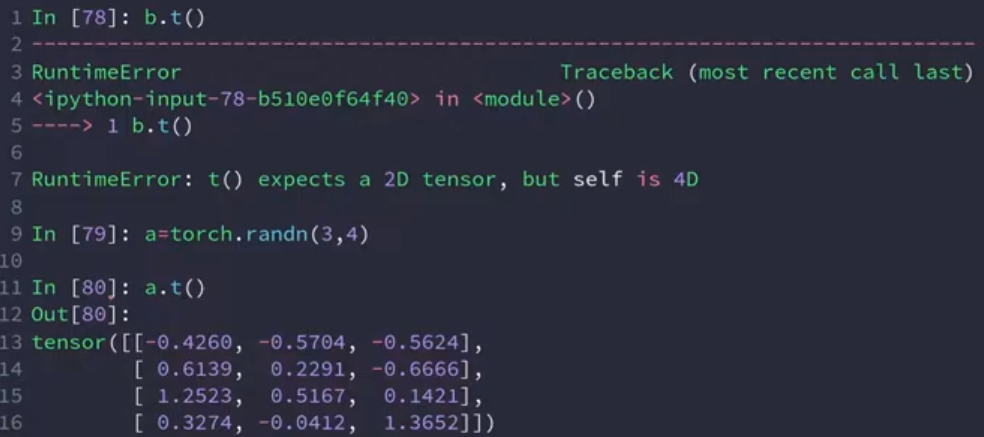
下面两行函数说明,即使前后的总体数据类型的大小相同,但是相同维度所表示的意义也进行了交换,因此不再表示同一Tensor
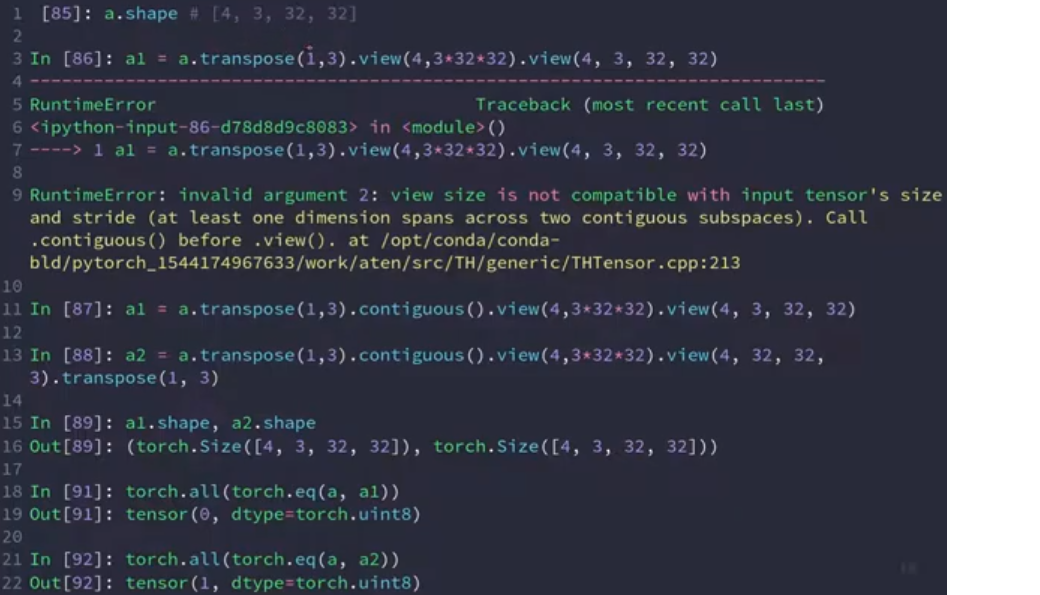
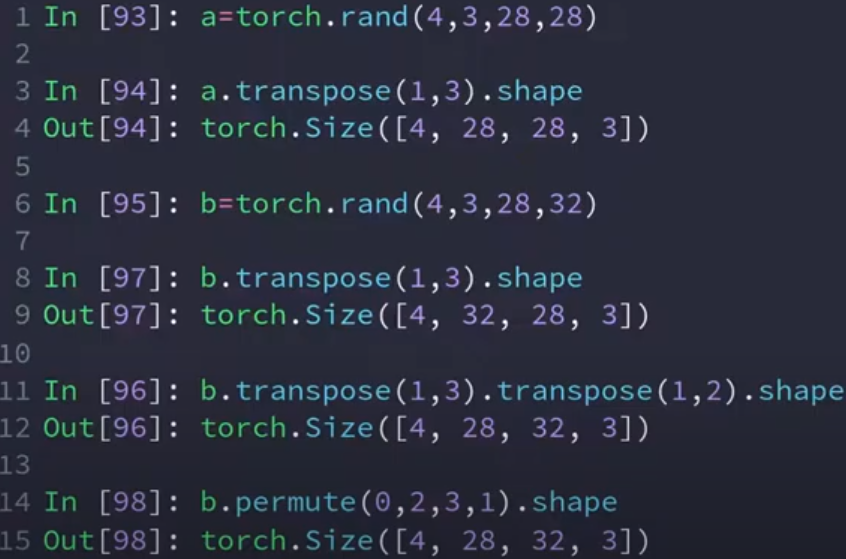
permute
可以自动调用transpose,并保证维度顺序的顺利交换
本文地址:https://blog.csdn.net/qq_42518956/article/details/107621610
希望与广大网友互动??
点此进行留言吧!



实现List排序的默认方法和自定义方法)
)






触摸屏通信(图文))





 Mycat分片(分库分表)配置)

