文章目录
- 1 数据准备
- 1.1 数据集拆分
- 1.2 创建词库vocabulary
- 1.3 batch数据,创建Iterator
- 2 Word Averaging模型
- 3 RNN模型
- 4 CNN
三种分类方式:Word Averaging模型、RNN、CNN。
1 数据准备
第一步是准备数据。代码中用到的类库有spacy、torchtext。
torchtext中有data.Field用来处理每个文本字段。dataLabelFiled处理标签字段。
1.1 数据集拆分
将数据集分为训练集、验证集和测试集。了解每种数据集的数据量,查看每一条数据的样子。
每一条句子是一个样本。
1.2 创建词库vocabulary
TEXT.build_vocab(train_data, max_size=25000, vectors="glove.6B.100d", unk_init=torch.Tensor.normal_)
LABEL.build_vocab(train_data)
设置词表大小,用词向量初始化词表。
1.3 batch数据,创建Iterator
训练的时候是一个batch,一个batch训练的。torchtext会将短句子pad到和最长的句子长度相同。
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits((train_data, valid_data, test_data), batch_size=BATCH_SIZE,device=device)
数据准备好了,就开始用模型训练吧。
2 Word Averaging模型
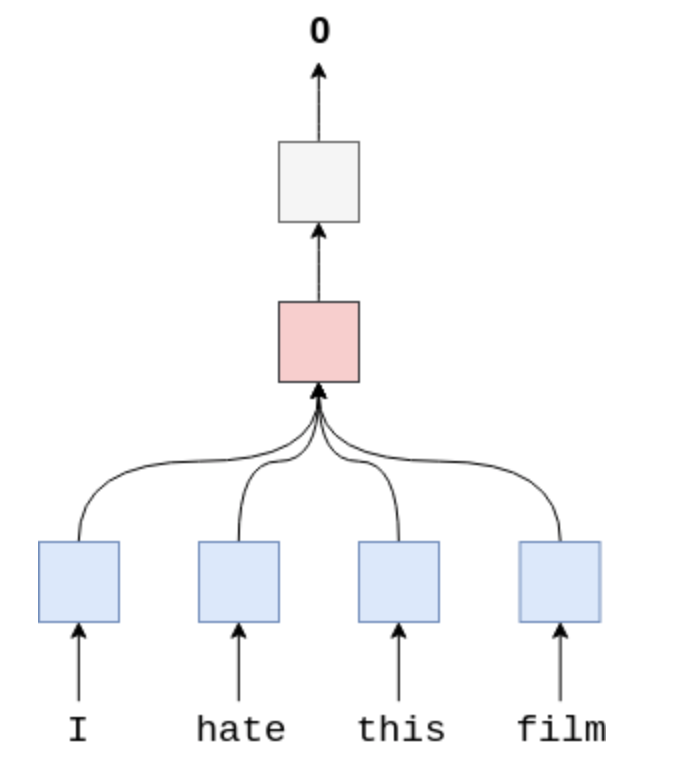
我们首先介绍一个简单的Word Averaging模型。这个模型非常简单,我们把每个单词都通过Embedding层投射成word embedding vector,然后把一句话中的所有word vector做个平均,就是整个句子的vector表示了。
接下来把这个sentence vector传入一个Linear层,做分类即可。
怎么做平均呢?我们使用avg_pool2d来做average pooling。我们的目标是把sentence length那个维度平均成1,然后保留embedding这个维度。
avg_pool2d的kernel size是 (embedded.shape[1], 1),所以句子长度的那个维度会被压扁。
import torch.nn as nn
import torch.nn.functional as Fclass WordAVGModel(nn.Module):def __init__(self, vocab_size, embedding_dim, output_dim, pad_idx):super().__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)self.fc = nn.Linear(embedding_dim, output_dim)def forward(self, text):embedded = self.embedding(text) # [sent len, batch size, emb dim]embedded = embedded.permute(1, 0, 2) # [batch size, sent len, emb dim]pooled = F.avg_pool2d(embedded, (embedded.shape[1], 1)).squeeze(1) # [batch size, embedding_dim]return self.fc(pooled)
接下来就是模型训练、评价。
优化函数:nn.BCEWithLogitsLoss()
优化方法:Adm
评价:损失函数值,准确率。
3 RNN模型
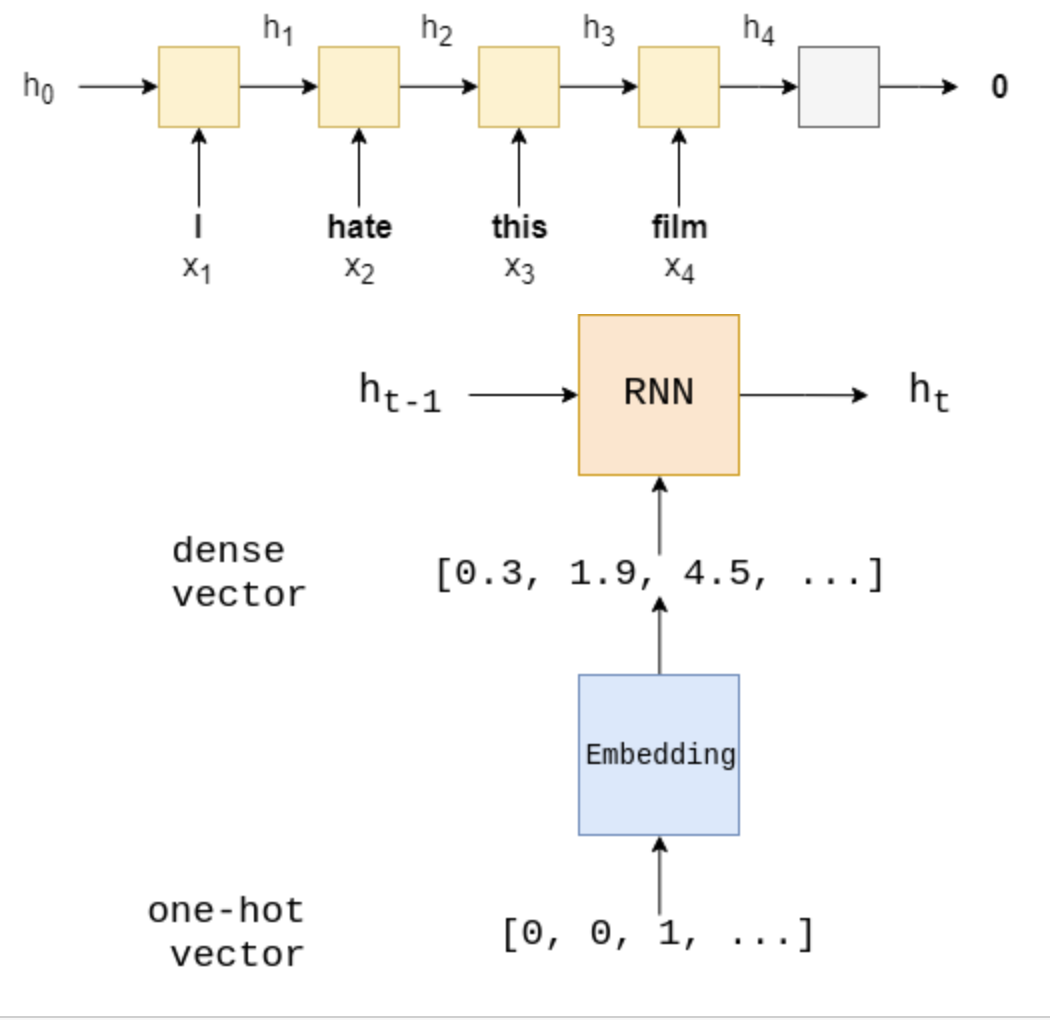
我们使用最后一个hidden state hTh_ThT来表示整个句子。
然后我们把hTh_ThT通过一个线性变换f,然后用来预测句子的情感。
class RNN(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout, pad_idx):super().__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout)self.fc = nn.Linear(hidden_dim*2, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, text):embedded = self.dropout(self.embedding(text)) #[sent len, batch size, emb dim]output, (hidden, cell) = self.rnn(embedded)#output = [sent len, batch size, hid dim * num directions]#hidden = [num layers * num directions, batch size, hid dim]#cell = [num layers * num directions, batch size, hid dim]#concat the final forward (hidden[-2,:,:]) and backward (hidden[-1,:,:]) hidden layers#and apply dropouthidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)) # [batch size, hid dim * num directions]return self.fc(hidden.squeeze(0))4 CNN
CNN可以把每个局域的特征提出来。在用于句子情感分类的时候,其实是做了一个ngram的特征抽取。
首先做一个embedding,得到每个词的词向量,是一个k维的向量。每个词的词向量结合到一起,得到一个nxk的矩阵。n是单词个数。
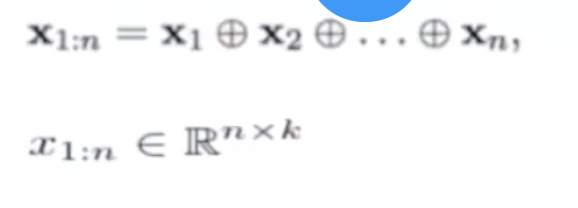
其次卷积层filter。现在相当于一个hgram。最后转化为h个单词。
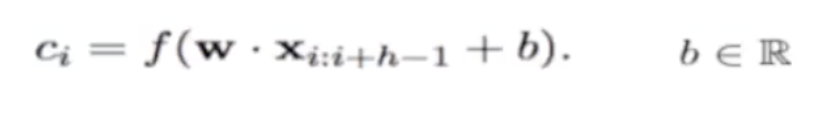
w是hxk的。
每一个h单词的窗口都会被这个filter转化。c=[c1,c2,...cn−h−1]c=[c_1,c_2,...c_{n-h-1}]c=[c1,c2,...cn−h−1]

上图中是一个卷积核为(3,embedding_size)的卷积。每次作用于3个单词,形成3-gram结果。
一般来说会选用多个卷积核:下图是作用了3个(3,embedding_size)卷积核。也可以使用不同尺寸的卷积核。

第三步,做一个max-over-time pooling。C^=max{c}\widehat{C}=max\{c\}C=max{c}
如果有m个filter,我们会得到z=[C1^,C2^,...Cm^]z=[\widehat{C_1},\widehat{C_2},...\widehat{C_m}]z=[C1,C2,...Cm]
第四步,对z做一个线性变换,得到分类。
class CNN(nn.Module):def __init__(self, vocab_size, embedding_size, output_size, pad_idx, n_filters, filter_sizes, dropout):super(CNN, self).__init__()self.embedding = nn.Embedding(vocab_size, embedding_size, padding_idx=pad_idx)self.convs = nn.ModuleList([nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(fs, embedding_size)) for fs in filter_sizes])self.linear = nn.Linear(len(filter_sizes) * n_filters, output_size)self.dropout = nn.Dropout(dropout)def forward(self, text):# text : [seq_len, batch_size]text = text.permute(1, 0) # [batch_size,seq_len]embed = self.embedding(text) # [batch_size, seq_len, embedding_size]embed = embed.unsqueeze(1) # [batch_size, 1, seq_len, embedding_size]# conved中每一个的形状是:[batch_size, n_filters, seq_len-filter_sizes[i]+1,embedding_size-embedding_size+1]# 因为kernel_size的第二个维度是embedding_sizeconved = [conv(embed) for conv in self.convs]# conved中每一个的形状是:[batch_size, n_filters, seq_len-filter_sizes[i]+1]conved = [F.relu(conv).squeeze(3) for conv in conved]# pooled中的每一个形状是:[batch_size, n_filters, 1]pooled = [F.max_pool1d(conv, conv.shape[2]) for conv in conved]# pooled中的每一个形状是:[batch_size, n_filters]pooled = [conv.squeeze(2) for conv in pooled]cat = self.dropout(torch.cat(pooled, dim=1)) # [batch_size, len(filter_sizes) * n_filters]return self.linear(cat) # [batch_size,output_size]N_FILTERS = 100
FILTER_SIZES = [3, 4, 5]
DROPOUT = 0.5
cnn_model = CNN(VOCAB_SIZE, EMBEDDING_SIZE, OUTPUT_SIZE, PAD_IDX, N_FILTERS, FILTER_SIZES, DROPOUT)
代码中的卷积核分别为:(3,embedding_size),(4,embedding_size),(5,embedding_size)
每次卷积完成之后,[batch_size, n_filters, seq_len-filter_sizes[i]+1,embedding_size-embedding_size+1],最后一个维度为1。
因为多个卷积之后的形状不一样,通过max_pooling层后统一变为[batch_size, n_filters]。这样就可以将多个卷积的结果拼接在一起,送入全连接层。
:Unknow tag(c:forEach)错误解决办法,jstl.jar包以及standard.jar包下载与导入)


)
:restful的crud实现删除方式)

)
)
:restful的crud实现增加方式)
)

:restful的crud的项目原型介绍)
)






