bt种子抓取
- 1. 抓取你想要的数据
- 2. 爬取bt种子
- 3. 抓取磁力链
迷上了追番.. . bt种子+xunlei来解决。
推荐一个网站https://mikanani.me。可以搜索你想要的动漫… 以bt的形式下载,或者复制磁力链。
1. 抓取你想要的数据
- 需要了解requests, etree库,etree用来解析html页面的。
- 需要了解html页面结构。能够分析页面,获取数据存放在dom中的规则。etree是以页面标签为一个个的对象的。需要etree的规则来匹配html元素结点。
- 爬虫为了解放手工,自动化收集数据。
2. 爬取bt种子
爬取斗罗大陆。
https://mikanani.me/Home/Search?searchstr=%E6%96%97%E7%BD%97%E5%A4%A7%E9%99%86
它应该是个单体项目,没看到有xhr请求。无需转包,发送请求,就响应整个页面。
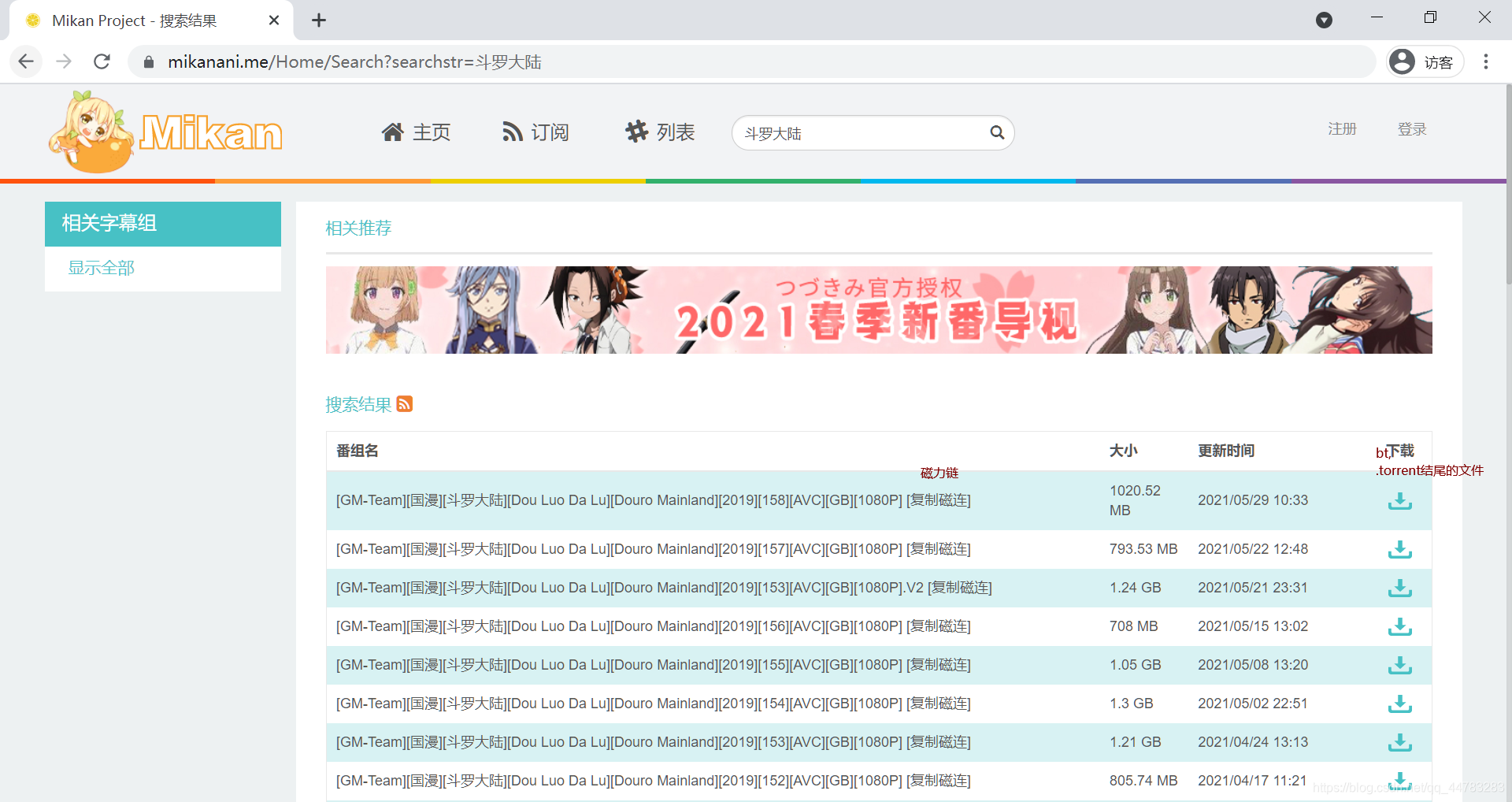
分析网页
不难发现,是个表格,每个tr下的第四个td,为什么不是第三个,etree就是第四个,td下的第一个a标签中的href属性就是想要的数据了。
https://mikanani.me/Download/20210529/e20a447ed38b85b0e2717336d8980240e600ff46.torrent
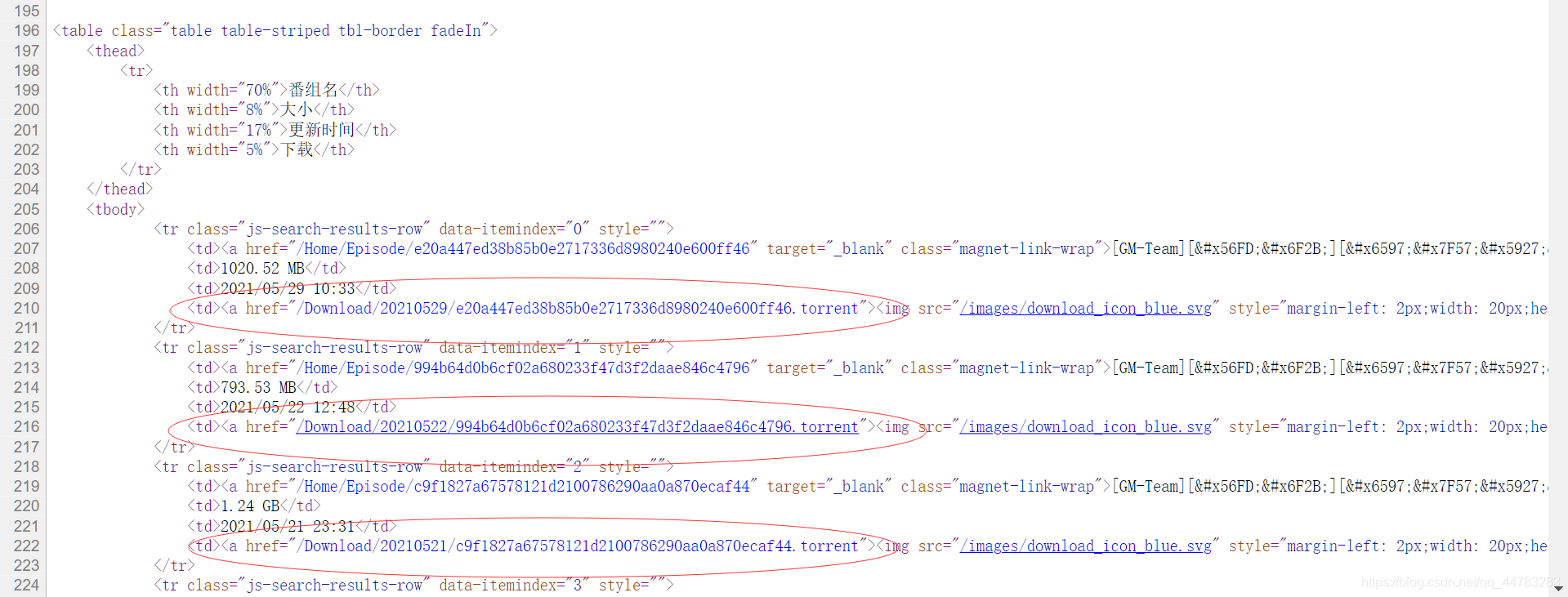
完整代码
设置请求头。
import requests as req
from lxml import etreeimport urllib
import osresp = req.get('https://mikanani.me/Home/Search?searchstr=%E6%96%97%E7%BD%97%E5%A4%A7%E9%99%86')## print(resp.text)html = etree.HTML(resp.text)print(type(html), html)# 获取a标签, 放下载链接。
res = html.xpath('//tr[@class="js-search-results-row"]//td[4]//a')main_url = 'https://mikanani.me'header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'}local_path = 'E:\python\crawler\mikanani\download'
def download_video(): i = 0;for a_tag in res:dict = eval(str(a_tag.attrib))download_url = main_url + dict.get('href')print(download_url + str(i) + '下载中..')# urllib.request.urlretrieve(download_url, os.path.join('', str(i) + '.torrent'))r = req.get(download_url, stream=True, headers = header)with open(os.path.join(local_path, str(i) + ".torrent"), "wb") as f:for chunk in r.iter_content(chunk_size=1024 * 1024):if chunk:f.write(chunk)i = i + 1print('下载完成.. 抓取个数..', len(res))if __name__ == "__main__":download_video()
3. 抓取磁力链
页面分析
数据绑定到data-clipboard-text这个属性。取到&前面就行了。
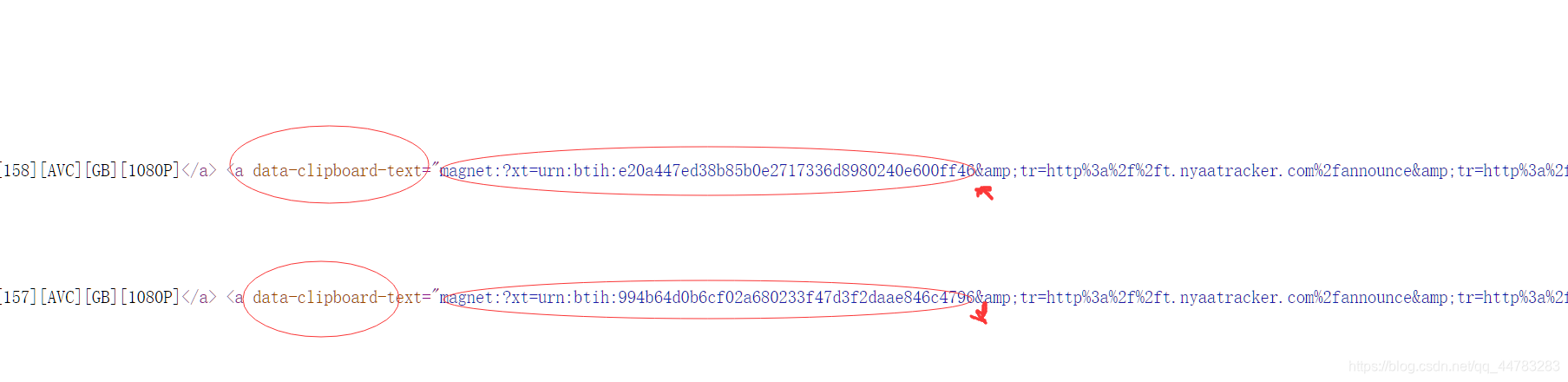
代码实现
# data-clipboard-textimport requests as req
from lxml import etreeimport osresp = req.get('https://mikanani.me/Home/Search?searchstr=%E6%96%97%E7%BD%97%E5%A4%A7%E9%99%86')## print(resp.text)html = etree.HTML(resp.text)print(type(html), html)res = html.xpath('//tr[@class="js-search-results-row"]//td[1]//a[2]')header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'}def download_video(): i = 0;for a_tag in res:dict = eval(str(a_tag.attrib))magent = dict.get('data-clipboard-text').split('&')[0]print(magent + '.. 写入文件...' + str(i))with open('斗罗大陆.txt', 'a+') as f:f.write(magent + '\n')i = i + 1print('下载完成.. 抓取个数..', len(res))if __name__ == "__main__":download_video()
:数据库概述)


:数据库相关概念)



:mongoose第三方模块)


:mongodb增)


:mongodb安装)


)
:mongodb增2)
)