
2019 年第 64 篇文章,总第 88 篇文章
本文大约 6400 字,阅读大约需要 17 分钟
原文链接:https://www.dataquest.io/blog/jupyter-notebook-tutorial/
Jupyter notebook 是一个很强大的交互式和展示数据科学项目的工具,它可以作为一个开发文档,包含代码、解释说明文字、代码运行结果、数学公式等等,功能非常强大,也是现在非常流行的工具。
本文会通过一个简单的数据分析例子来介绍 Jupyter notebook 的使用方法。这里的例子就是给定一个自 1955 年发布以来,一共 50 年时间的美国 500 家公司的数据,任务是分析这些公司的利润变化过程。
1. 安装
最简单的安装方式就是通过 Anaconda 进行安装,Anaconda 是使用最广泛的环境管理工具,并且它可以预先安装很多常用的第三方库,包括 numpy 、pandas 、matplotlib 等。
具体的 Anaconda 可以查看之前公众号发表过的一篇文章--Python 基础入门--简介和环境配置。
除了通过 Anaconda 安装,也可以直接采用 pip
pip install jupyter
2. 创建你的第一个 Notebook
这一部分将介绍如何运行和保存 notebooks,熟悉 Jupyter notebook 的结构和交互界面。这里将通过一个例子来熟悉一些核心的用法,更好的了解 Jupyter notebook 的使用。
运行 Jupyter
在 Windows,可以通过添加到开始菜单的快捷方式运行 Jupyter ,当然也可以通过在命令行输入命令 jupyter notebook 开始运行,然后会在默认浏览器中打开一个新的窗口,窗口内容如下:
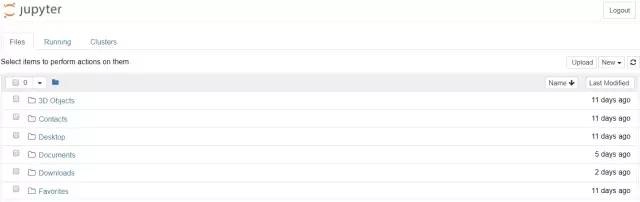
当然上述还不是一个 notebook,它是 Notebook 的管理界面,用于管理当前文件夹的所有 Notebooks。
注意,这里仅仅展示 Jupyter 运行时候的所在文件夹内的文件和文件夹,也就是在命令行运行 jupyter notebook 时所在的文件夹,当然这个也可以改变,运行命令的时候可以指定文件夹位置,即输入:
jupyter notebook filepath
此外,这里在浏览器上的 URL 地址是类似 http://localhost:8888/tree,其中 localhost 是表示本地地址,然后 8888 是端口。
接下来就是创建一个新的 notebook,可以如下图所示,在管理界面的右上角位置,点击 New 菜单,这里就可以选择 Python 3 (或者其他的版本),然后就可以创建成功,并且是在新的窗口打开这个 notebook,在默认命名就是 Untitled.ipynb。
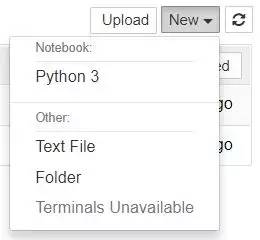
ipynb 文件
每个 ipynb 文件都是通过 JSON 格式来描述 notebook 的内容,包括每个单元及其内容,都是通过 metadata 的格式展示。这里可以在打开 ipynb 文件后,菜单中选择 Edit->Edit Notebook Metadata ,进行编辑。
notebook 界面
现在开始介绍下 notebook 的界面信息,一个新的 notebook 界面如下图所示。

这里有两个术语需要知道--cells 和 kernels ,两个都是非常重要的术语:
kernel:表示计算引擎,用于执行 notebook 中的代码块cell:单元块,用于展示文本或者是代码。
单元(Cells)
首先介绍的是 Cells ,一个 Cell 就是上图中绿色框部分,它是 notebook 的主要部分,通常有两种主要的 cell 类似:
code cell:包括需要执行的代码,以及其运行结果Markdown cell:包含的是 Markdown 格式的文本并且其执行结果
下图展示了一个简单的例子,第一行 Jupyter 入门教程 这个就是一个 Markdown cell ,这里展示的是执行这个 cell 的结果,如果需要执行一个 cell ,可以点击 Run 按钮,或者快捷键 Ctrl + Enter 即可,然后下方两个都是 code cell ,第一个是导入第三方库,第二个则是打印一段话以及其运行结果。
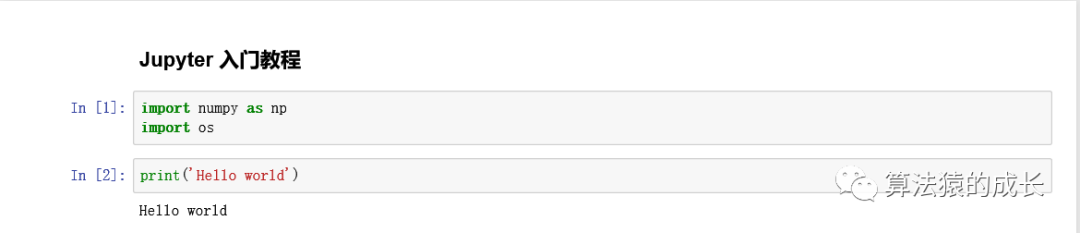
可以注意到 code cell 的左侧会有一个标签 In [1] ,这里的数字表示该代码块运行的次序,即在该 notebook 中,如果没有执行,显示的是 In [ ] ,如果是该 notebook 第一个运行的代码块,则是 In [1] ,如果再次运行,则显示 In [2],依次类推,同个代码块多次执行,这个数字也是会改变的。而 In 是 Input 的缩写。如果代码块运行时间有点久,它会显示 In [*] ,表示当前代码块正在运行中。
对于 notebook,还可以直接展示变量的数值,或者是函数的返回值,不需要调用 print 函数,如下图所示,当然它只会打印当前单元的最后一行的内容。

还需要注意的一件事情就是,对于一个单元,如果正在编辑,其边界框显示的是绿色,而运行时候则显示蓝色。这里展示的就是两种模式,即绿色表示编辑模式,蓝色表示命令模式。
快捷键
notebook 有很多快捷键,可以通过菜单中的 Help->Keyboard Shortcuts 查看,也可以直接用快捷键 Ctrl+Shift+P 查看。下面简单介绍一些快捷键:
编辑模式和命令模式可以通过
Esc和Enter进行转换,一般是按Esc进入命令模式,Enter进入编辑模式
在命令模式下:
在
cell之间上下浏览采用上下箭头,或者Up和Down键A表示在当前cell上方插入一个新的cell,而B则是下方插入新的cellM表示变为Markdown cell,而Y是表示变为code cell连续按两次
D是删除当前cellZ是撤销操作Shift加上Up或者Down可以一次选择多个cells,接着采用Shift + M可以合并多个cells
Markdown
Markdown 是一个轻量级的易于学习使用的标记语言,主要用于格式化文本文字。它的语法类似 HTML 语言,是一个非常有帮助的语言,可以用于添加注释说明或者添加图片。
可以尝试在 Jupyter notebook 中输入下面的文字,记住是在 Markdown cell中:
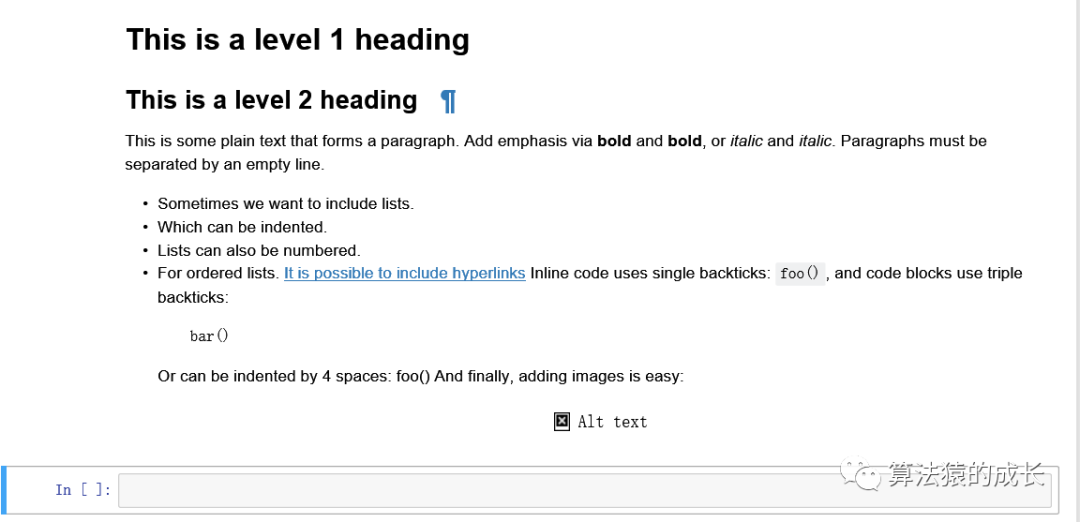
# This is a level 1 heading
## This is a level 2 heading
This is some plain text that forms a paragraph.
Add emphasis via **bold** and __bold__, or *italic* and _italic_.
Paragraphs must be separated by an empty line.
* Sometimes we want to include lists.
* Which can be indented.
1. Lists can also be numbered.
2. For ordered lists.
[It is possible to include hyperlinks](https://www.example.com)
Inline code uses single backticks: `foo()`, and code blocks use triple backticks:
```
bar()
```
Or can be indented by 4 spaces:
foo()
And finally, adding images is easy: 
得到的结果如下图所示:
如果想添加图片,有三种做法:
使用网络上的图片,添加其网络链接 URL,比如上述例子就是这种做法,URL 是 https://www.example.com/image.jpg
采用一个本地 URL,那么图片就只能使用在该 notebook 中,比如在同一个 git 仓库中
菜单栏选择 “Edit->Insert Image",这种做法会将图片转换为字符串形式并存储在
.ipynb文件中,这种做法会增加ipynb文件的大小
Markdown 的使用方法可以参考其发明者 John Gruber 的官方教程:
https://daringfireball.net/projects/markdown/syntax
Kernels
每个 notebook 都有一个 kernel。当执行一个单元内的代码的时候,就是采用 kernel 来运行代码,并将结果输出显示在单元内。同时 kernel 的状态会保留,并且不止局限在一个单元内,即一个单元内的变量或者导入的第三方库,也是可以在另一个单元内使用的,并不是相互独立的。
某种程度来说,notebook 可以看做是一个脚本文件,除了增加了更多输入方式,比如说明文字、图片等等。
这里同样用一个代码例子进行介绍 kernel 的这种特性,如下图所示,分别在两个单元内输入两段代码,第一个单元内时导入 numpy 并定义函数 square(),而第二个单元内就调用了这个函数 square() ,并成功运行输出结果。
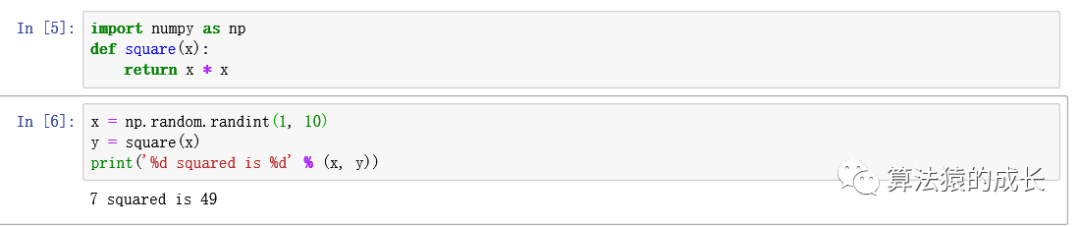
大部分情况下都是自顶向下的运行每个单元的代码,但这并不绝对,实际上是可以重新回到任意一个单元,再次执行这段代码,因此每个单元左侧的 In [ ] 就非常有用,其数字就告诉了我们它是运行的第几个单元。
此外,我们还可以重新运行整个 kernel,这里介绍菜单 Kernel 中的几个选项:
Restart:重新开始 kernel,这会清空 notebook 中所有的变量定义Restart & Clear Output: 和第一个选项相同,但还会将所有输出都清除Restart & Run All: 重新开始,并且会自动从头开始运行所有的单元内的代码
通常如果 kernel 陷入某个单元的代码运行中,希望停止该代码的运行,则可以采用 Interupt 选项。
选择一个 kernel
在 Kernel 菜单中同样提供了一个更换 kernel 的选项,最开始创建一个 notebook 的时候,就是选择了一个 kernel ,当然这里能否选择其他的 kernel ,取决于是否有安装,比如 Python 的版本,当你同时安装了 python3.6 和 python2.7 ,那么就有这两个选择,除了 Python 语言,Juypter notebook 支持的 kernel 还包括其他超过一百种语言,比如 Java、C、R、Julia 等等。
3. 数据分析例子
现在就开始文章开始说的数据分析例子,即从一份公司财富数据中分析公司的利润变化情况。
命名 notebooks
首先,给 notebook 命名一个有意义的名字,比如 jupyter-notebook-tuorial,可以直接在 notebook 界面直接点击上方文件名,如果未命名,那就是 Untitle.ipynb ,当然也可以返回管理界面进行命名,如下所示,选择 notebook 后,上方会出现一行选项,包括:
Duplicate:复制Shutdown:停止该 notebook 的 kernelView:查看 notebook 内容Edit:编辑其metadata内容
以及还有一个删除文件的选项。
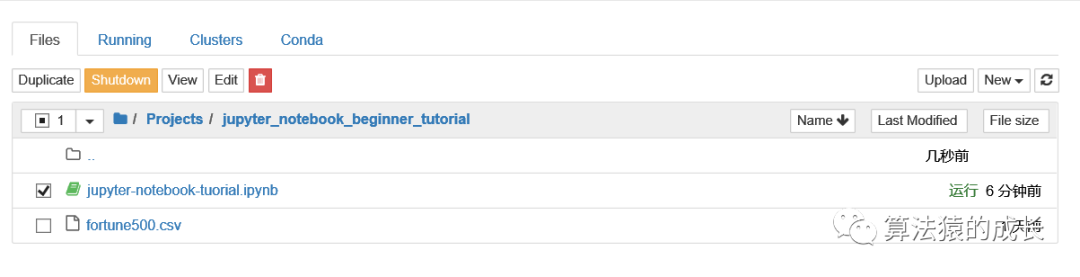
注意,关闭 notebook 的界面并不会关掉 notebook 的 kernel,它会一直在后台运行,在管理界面看到 notebook 还是绿色状态,就表明其在运行,这需要选择 Shutdown 选项,或者命令行里关掉 Jupyter notebook 的命令。
准备工作
首先导入一些需要用的第三方库:
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
pandas 用于处理数据,Matplotlib 用于绘制图表,而 seaborn 可以让图表更加漂亮。通常也需要导入 Numpy ,不过在本例中我们将通过 pandas 来使用。此外,%matplotlib inline 这并不是 python 的命令,它是 Jupyter 中独有的魔法命令,它主要是让 Jupyter 可以捕获 Matplotlib 的图片,并在单元输出中渲染。
接着就是读取数据:
df = pd.read_csv('fortune500.csv')
保存和检查点(checkpoint)
在开始前,要记得定时保存文件,这可以直接采用快捷键 Ctrl + S 保存文件,它是通过一个命令--“保存和检查点”实现的,那么什么是检查点呢?
每次创建一个新的 notebook,同时也创建了一个 checkpoint 文件,它保存在一个隐藏的子文件夹 .ipynb_checkpoints 中,并且也是一个 .ipynb 文件。默认 Jupyter 会每隔 120 秒自动保存 notebook 的内容到 checkpoint 文件中,而当你手动保存的时候,也会更新 notebook 和 checkpoint 文件。这个文件可以在因为意外原因关闭 notebook 后恢复你未保存的内容,可以在菜单中 File->Revert to Checkpoint 中恢复。
对数据集的探索
现在开始处理我们的数据集,通过 pandas 读取后得到的是称为 DataFrame 的数据结构,首先就是先查看下数据集的内容,输入以下两行代码,分别表示输出数据的前五行,和最后五行的内容。
df.head()
df.tail()
输出内容如下所示:
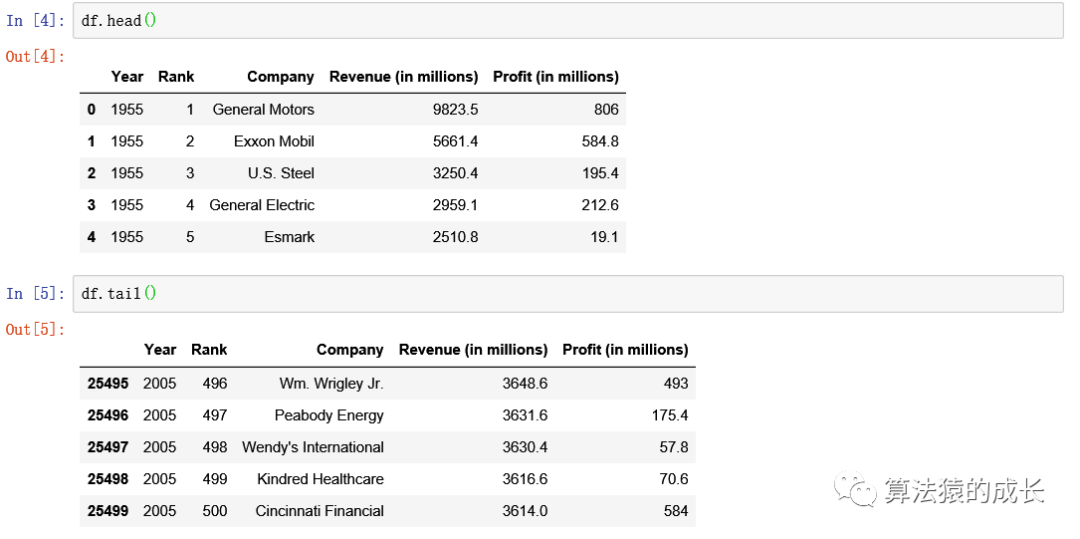
通过查看,我们了解到每行就是一个公司在某一年的数据,然后总共有 5 列,分别表示年份、排名、公司名字、收入和利润。
接着,为了方便,可以对列重命名:
df.columns = ['year', 'rank', 'company', 'revenue', 'profit']
然后,还可以查看数据量,如下所示:
len(df)
如下图所示,总共有 25500 条数据,刚好就是 500 家公司从 1955 到 2005 的数据量。

接着,我们再查看数据集是否和我们希望导入的一样,一个简单的检查方法就是查看数据类型是否正确:
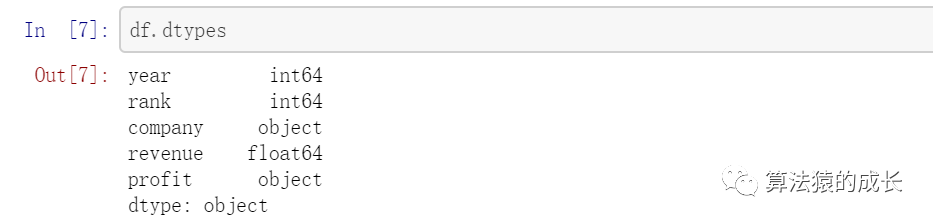
这里可以发现 profit 数据类型居然是 object 而不是和收入 revenue 一样的float64 类型,这表示其中可能包含一些非数字的数值,因此我们需要检查一下:
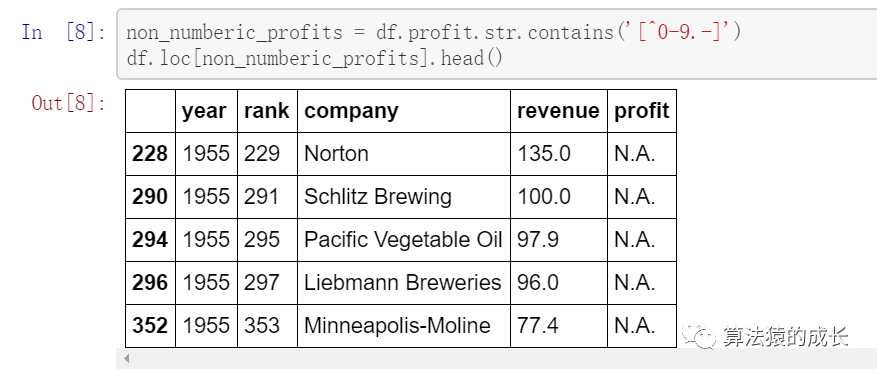
输出结果表明确实存在非整数的数值,而是是 N.A,然后我们需要确定是否包含其他类型的数值:

输出结果表示只有 N.A ,那么该如何处理这种缺失情况呢,这首先取决有多少行数据缺失了 profit :

369 条数据缺失,相比于总共 25500 条数据,仅占据 1.5% 左右。如果缺失的数据随着年份的变化符合正态分布,那么最简单的方法就是直接删除这部分数据集,代码如下所示
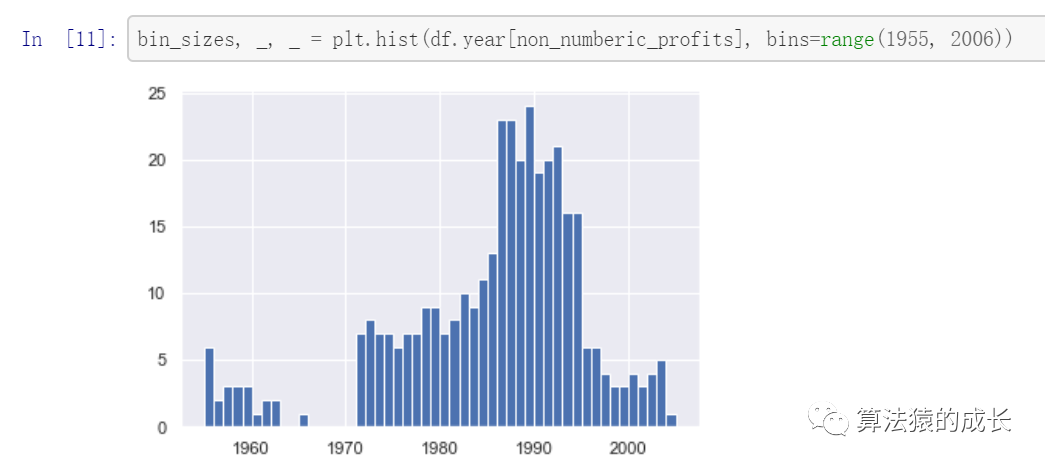
从结果看,缺失数据最多的一年也就是 25 条也不到,相比每年 500 条数据,最多占据 4%,并且只有在 90 年代的数据缺失会超过 20 条,其余年份基本在 10 条以下,因此可以接受直接删除缺失值的数据,代码如下:
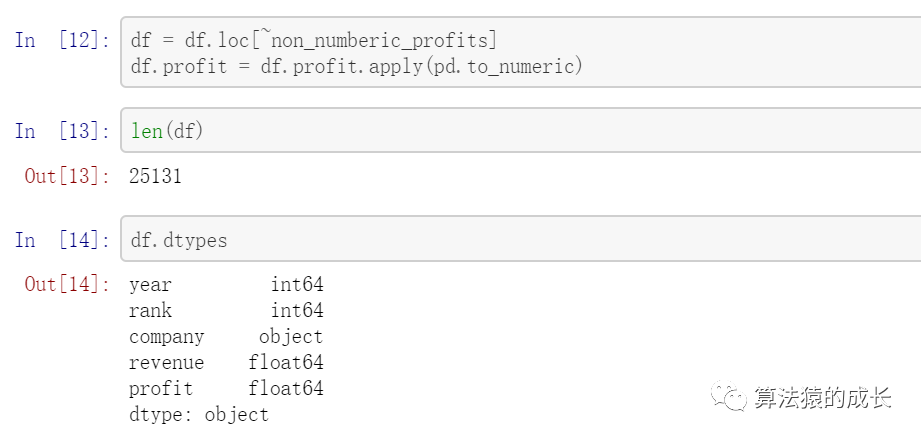
删除数据后,profit 就是 float64 类型了。
简单的数据探索完成了,接下来进行图表的绘制。
采用 matplotlib 进行绘制图表
首先绘制随着年份变化的平均利润表,同时也会绘制收入随年份的变化情况,如下图所示:
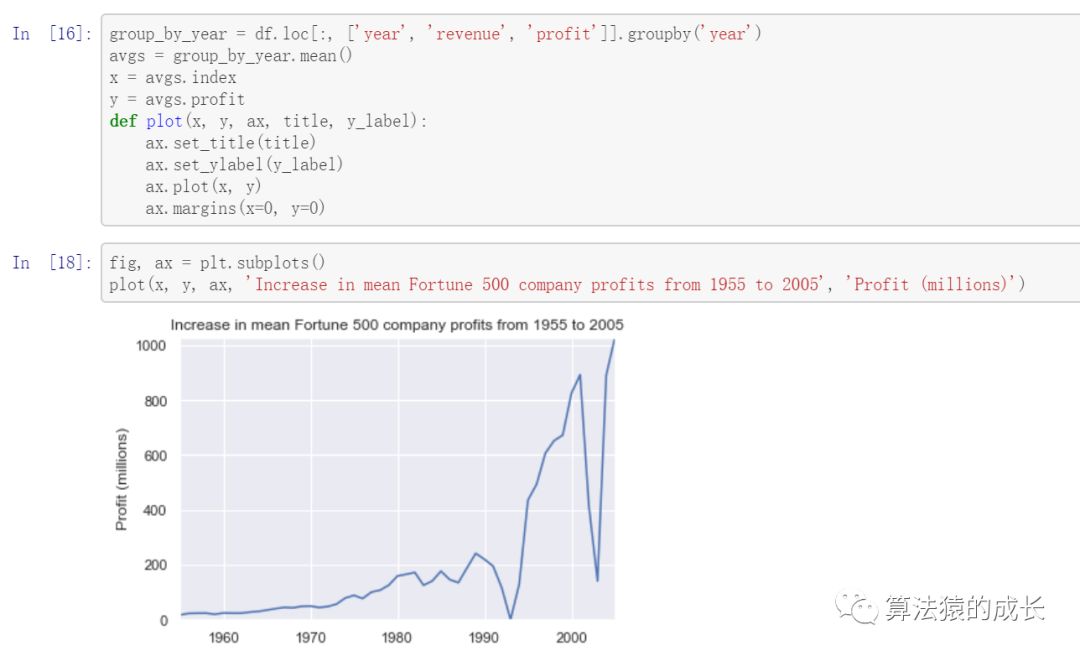
结果看起来有点类似指数式增长,但出现两次巨大的下降情况,这其实和当时发生的事件有关系,接下来可以看看收入的变化情况,如下图所示:
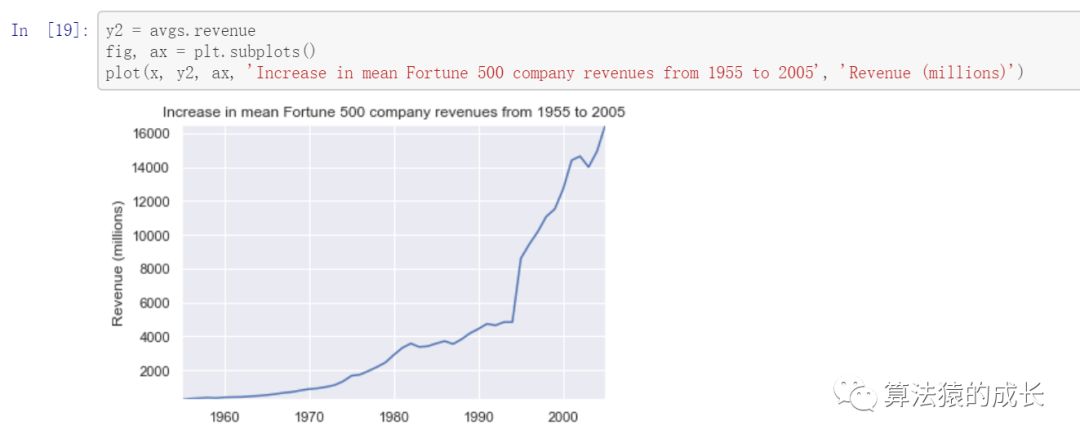
从收入看,变化并没有像利润一样出现两次波动。
参考 https://stackoverflow.com/a/47582329/604687,我们添加了利润和收入的标准差情况,用于反馈同一年不同公司的收入或者利润差距,如下图所示:
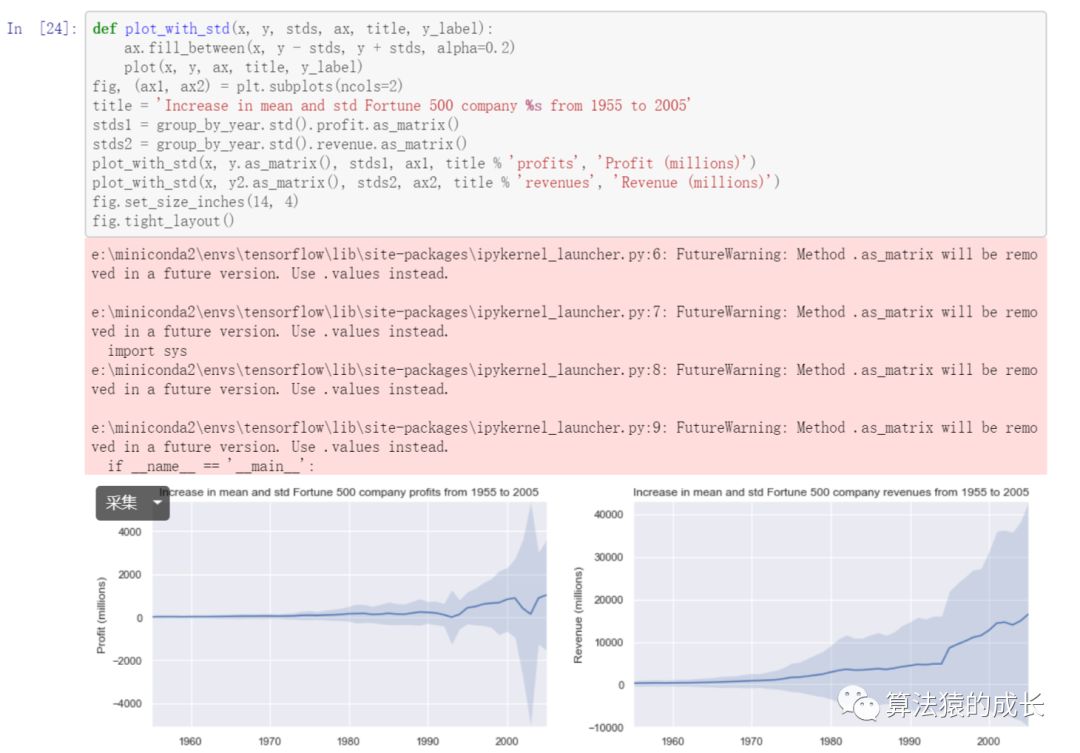
结果表明了不同公司的差距还是很大的,存在有收入几十亿,也有亏损几十亿的公司。
其实还有很多问题可以深入探讨,但目前给出的例子已经足够入门 Jupyter notebook,这部分例子展示了如何分析探索数据,绘制数据的图表。
参考
Markdown:https://www.markdownguide.org/getting-started
https://stackoverflow.com/a/47582329/604687
最后本文的代码和教程可以公众号后台回复“Jupyter”获取链接地址,或者点击阅读原文。
欢迎关注我的微信公众号--算法猿的成长,或者扫描下方的二维码,大家一起交流,学习和进步!

如果觉得不错,在看、转发就是对小编的一个支持!

:react-hello-react之脚手架文件_public)
)

:react-hello-react之脚手架文件_src)




:react-hello-react之一个简单的helloworld)

:react-hello-react之一个简单的helloworld)


:react-hello-react之一个简单的helloworld)

:react-hello-react之样式的模块化)


