1 基本框架
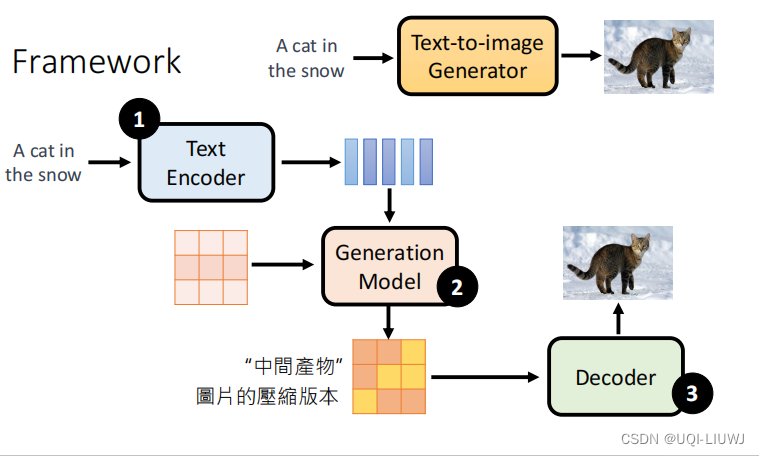
- ①:文字变成向量
- ②:喂入噪声+文字encoder,产生中间产物
- ③:decoder 还原图片
2 text encoder
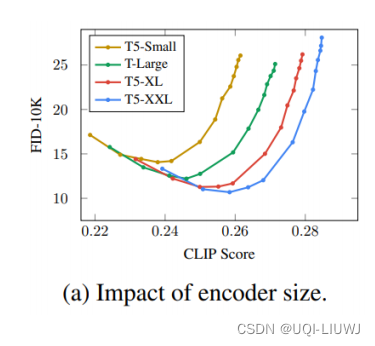
这张图越往右下表示效果越好,可以看到text encoder尺寸越大,对后续生成图片的增益越多
3 评价图片生成好坏的标准
3.1 FID
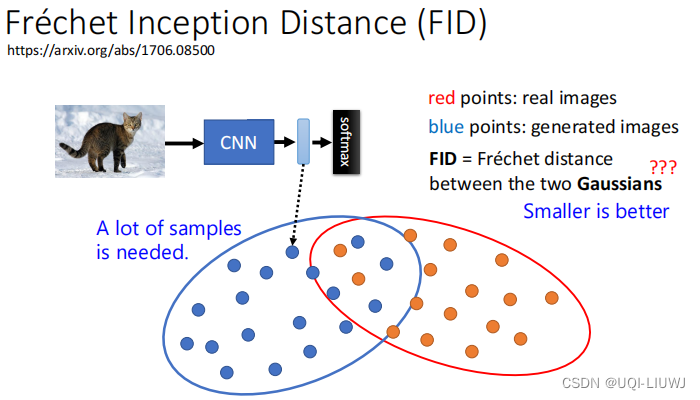
- 现有一个训练好的CNN 模型,可以生成真实影像和生成图像的representation
- 这两组表征的分布越近,效果越好
- ——>我们sample 一堆图片,然后生成一组同语义的图片,计算他们分布的distance
3.2 CLIP
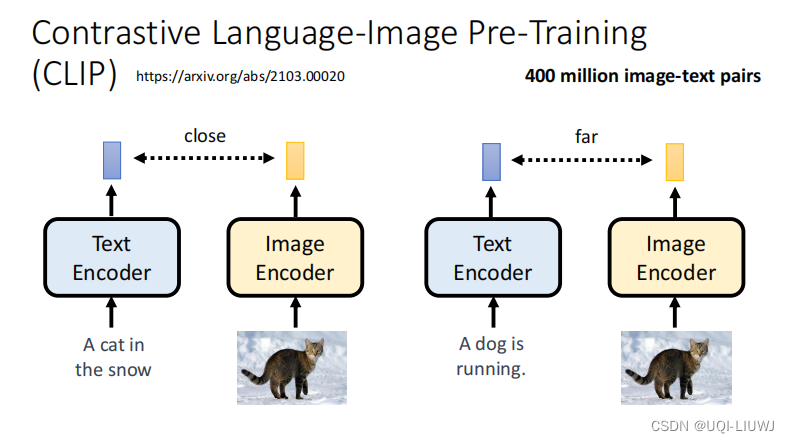
- 如果图片和文字是成对的,那么他们的representation越近表示生成的图片效果越好
4 decoder
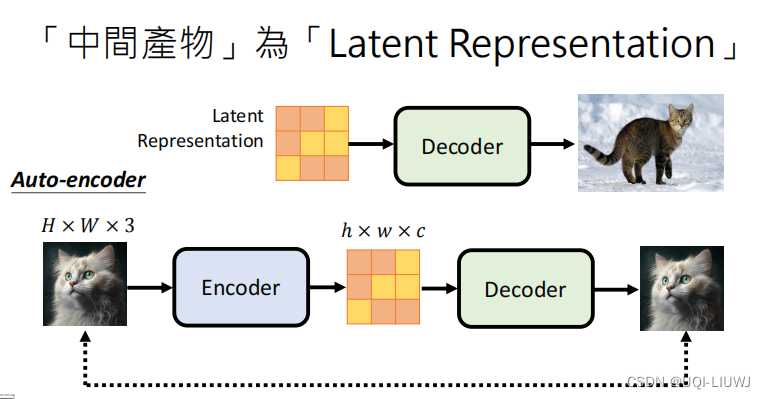
- 训练一个auoto encoder
- 训练完把decoder拿出来用即可
5 噪声加的位置
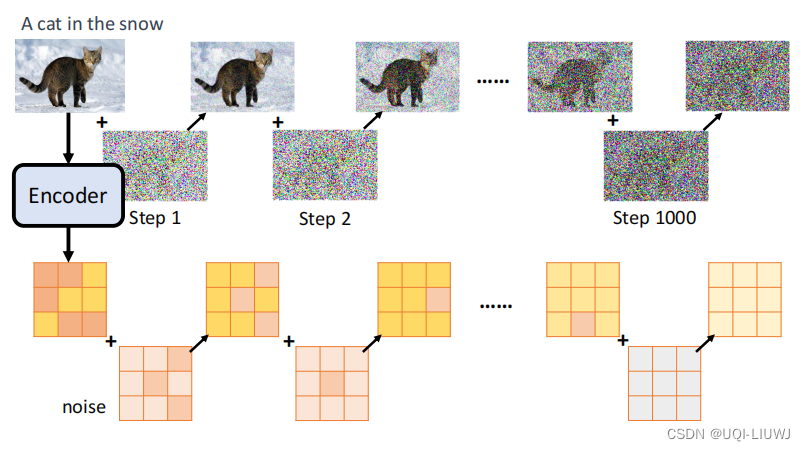
- 之前defusion model 中,noise是加在图片上
- 但现在产生的东西已经不是图片了
- ——>noise 加在中间产物上
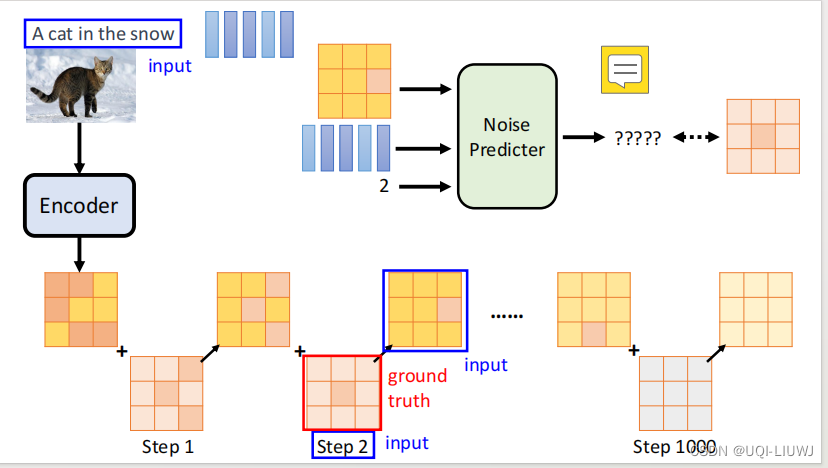
大体上和diffusion model 类似,这里就是最后多接一个decoder,将中间产物变成图片
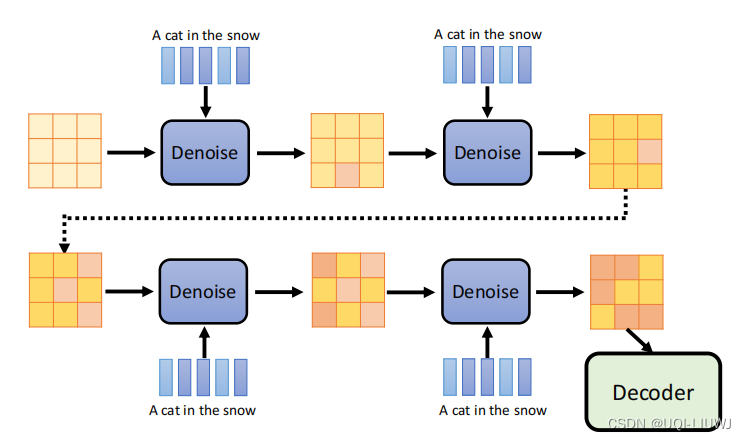

)
)

)







,必会题,思维题)






