转载的文章链接:
为什么使用全局平均池化层?
关于 global average pooling
https://blog.csdn.net/qq_23304241/article/details/80292859
在卷积神经网络的初期,卷积层通过池化层(一般是 最大池化)后总是要一个或n个全连接层,最后在softmax分类。其特征就是全连接层的参数超多,使模型本身变得非常臃肿。
之后,有大牛在NIN(Network in Network)论文中提到了使用全局平局池化层代替全连接层的思路,以下是摘录的一部分资料:
global average poolilng。既然全连接网络可以使feature map的维度减少,进而输入到softmax,但是又会造成过拟合,是不是可以用pooling来代替全连接。
答案是肯定的,Network in Network工作使用GAP来取代了最后的全连接层,直接实现了降维,更重要的是极大地减少了网络的参数(CNN网络中占比最大的参数其实后面的全连接层)。Global average pooling的结构如下图所示:
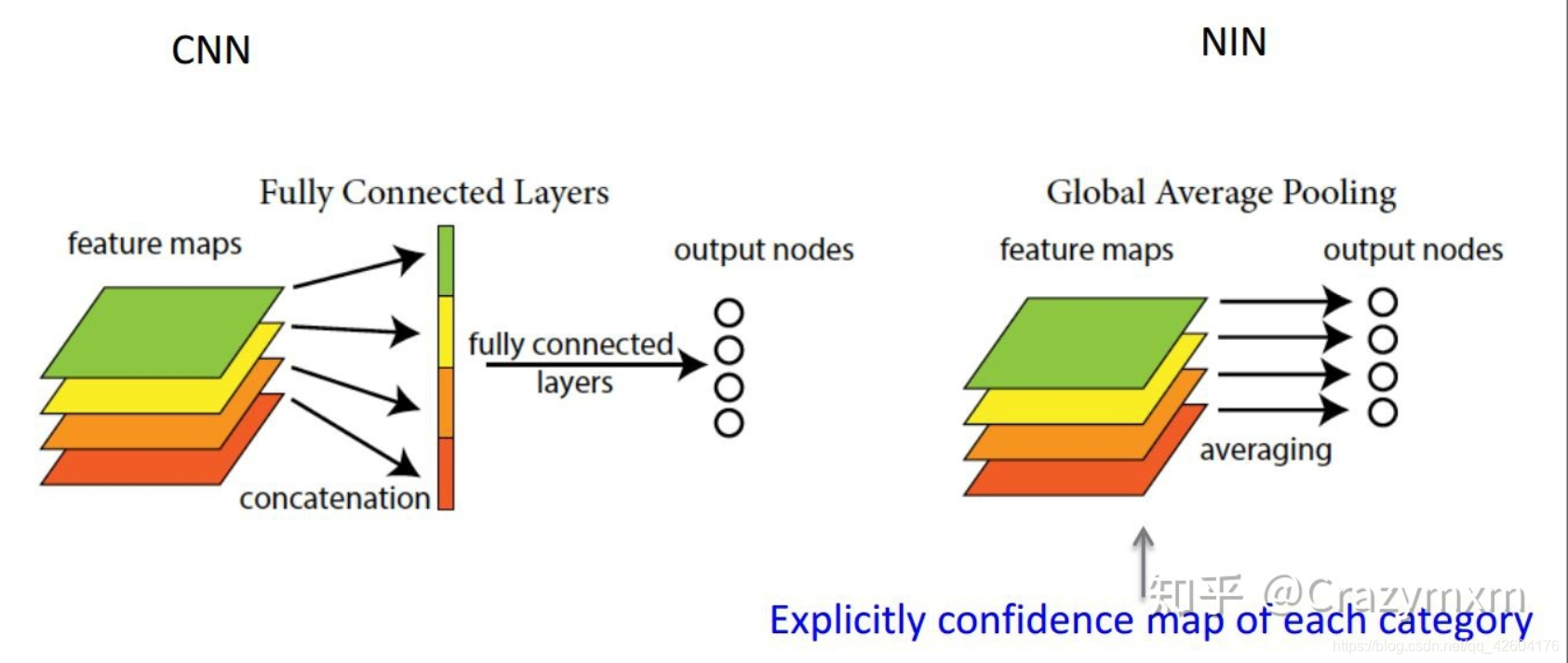
由此就可以比较直观地说明了。这两者合二为一的过程我们可以探索到GAP的真正意义是:对整个网路在结构上做正则化防止过拟合。其直接剔除了全连接层中黑箱的特征,直接赋予了每个channel实际的内别意义。
实践证明其效果还是比较可观的,同时GAP可以实现任意图像大小的输入。但是值得我们注意的是,使用gap可能会造成收敛速度减慢。
但是,全局平均池化层比较全连接层,为什么会收敛速度变慢,它们对模型的训练有什么差异呢?我没有找到相关的文章的介绍。以下是发挥我自己的想象(很有可能是错误的)来理解的几个点:
1.全连接层结构的模型,对于训练学习的过程,可能压力更多的在全连接层。就是说,卷积的特征学习的低级一些,没有关系,全连接不断学习调整参数,一样能很好的分类。
此处是完全猜测,没有道理。
2.全局平均池化层代替全连接层的模型,学习训练的压力全部前导到卷积层。卷积的特征学习相较来说要更为"高级"一些。(因此收敛速度变慢?)
为什么这么想呢?我的理解是,全局平均池化较全连接层,应该会淡化不同特征间的相对位置的组合关系(“全局”的概念即如此)。因此,卷积训练出来的特征应该更加“高级”。
3. 以上的两个观点联合起来,可以推导出,全局平均池化层代替全连接层虽然有好处,但是不利于迁移学习。因为参数较为“固化”在卷积的诸层网络中。增加新的分类,那就意味着相当数量的卷积特征要做调整。而全连接层模型则可以更好的迁移学习,因为它的参数很大一部分调整在全连接层,迁移的时候卷积层可能也会调整,但是相对来讲要小的多了。
这3点完全是我个人的理解,希望有大牛留言批评指正。
global average pooling 与 average pooling 的差别就在 “global” 这一个字眼上。global与 local 在字面上都是用来形容 pooling 窗口区域的。 local 是取 feature map 的一个子区域求平均值,然后滑动这个子区域; global 显然就是对整个 feature map 求平均值了。
因此,global average pooling 的最后输出结果仍然是 10 个 feature map,而不是一个,只不过每个feature map 只剩下一个像素罢了。这个像素就是求得的平均值。 官方 prototxt 文件 里写了。网络进行到最后一个average pooling 层的时候,feature map 就剩下了 10 个,每个大小是 8 * 8。顺其自然地作者就把pooling 窗口设成了 8 个像素,意会为 global average pooling 。可见,global averagepooling 就是窗口放大到整个 feature map 的 average pooling 。
每个讲到全局池化的都会说GAP就是把avg pooling的窗口大小设置成feature map的大小,这虽然是正确的,但这并不是GAP内涵的全部。GAP的意义是对整个网络从结构上做正则化防止过拟合。既要参数少避免全连接带来的过拟合风险,又要能达到全连接一样的转换功能,怎么做呢?直接从feature map的通道上下手,如果我们最终有1000类,那么最后一层卷积输出的feature map就只有1000个channel,然后对这个feature map应用全局池化,输出长度为1000的向量,这就相当于剔除了全连接层黑箱子操作的特征,直接赋予了每个channel实际的类别意义。
)



网络讲解以及tensorflow代码实现)
)











方法与示例)

