Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
作者:Omer Lachish
最近,我们已经开始使用RQ库代替Celery库作为我们的任务运行引擎。第一阶段,我们只迁移了那些不直接进行查询工作的任务。这些任务包括发送电子邮件,确定哪些查询需要刷新、记录用户事件和其他维护工作。
在部署完成之后我们注意到,任务数量相同的情况下,与Celery库相比,RQ库需要更多的CPU去执行这些任务。我想我应该分享一下我是如何分析和解决这个问题的。
关于Celery库和RQ库的区别
Celery库和RQ库都有工作进程的概念,而且都使用分支来允许多种任务并行运行。当你启动一个Celery工作进程时,它会分到几个不同的进程,每个进程会自主地处理任务。使用RQ库,一个主进程将只会实例化一个子进程(称为“Worker Horse”),该子进程在执行完一个单独的任务后将会结束。当主进程从队列中提取另一项任务时,它将会派出一个新的Work Horse。
在RQ库中,通过使用更多的工作进程,即可实现与Celery相同的并行性。 但是,Celery库和RQ库之间存在着细微的区别:Celery进程在启动时会实例化多个子进程,并将其重用于多个任务。 而使用RQ库时,你必须给每一个任务分配进程。 两种方法都有优点和缺点,但这些内容不在本文讨论范围之内。
标杆分析法
在介绍任何内容之前,我想要确定一个基准,即一个工作容器处理1000项任务需要多长时间。我决定把重心放在record_event工作上,因为它是一种频繁的,轻量级的操作。我使用time命令来衡量性能,这里需要修改一下源代码:为了得出完成1000项任务所需的时间,我倾向于采用RQ库的burst模式,该模式在处理完作业后会退出流程。
我想避免测量那些被安排在基准测试时间段的任务。因此,在task/general.py中的record_event声明上方,通过将@job('default')替换为@job('benchmark'),可以将record_event移至一个名为benchmark的专用队列。
现在我们可以开始计时了。首先,我想查看一个进程启动和停止需要多长时间(没有任何工作)以便之后可以从任何结果中减去该时间:

在我的计算机上,进程初始化需要14.7秒。我会记住这个时间。
然后,我将1000个虚拟的record_event任务添加进benchmark队列中:

现在,运行相同的命令,看看处理1000项任务需要多长时间:

减去14.7秒的启动时间,我们看到4个进程处理1000项任务需要102秒。现在,让我们尝试找出原因!为此,在进程工作的同时,我们将使用py_spy模块。
分析
让我们再增加1000项任务(因为上次的测试已经删除了所有任务),运行进程并同时监控它们所耗费的时间:
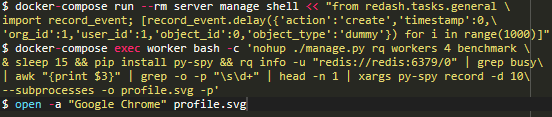
我知道,最后一条命令非常短。 理想情况下,出于可读性考虑,我会在每个“ &&”上都打断该命令,但是这些命令应该在同一个docker-compose exec worker bash session中按顺序运行。所以,以下是其功能的快速分析:在后台中,burst模式下,开启了4个进程。
等待15秒(大致让它们完成启动。
安装py-spy模块。
运行rq-info命令,并且为其中一个进程进行分层控制。
在该控制过程中记录10秒中的活动情况并将其保存到profile.svg文件中。
结果如下火焰图所示:
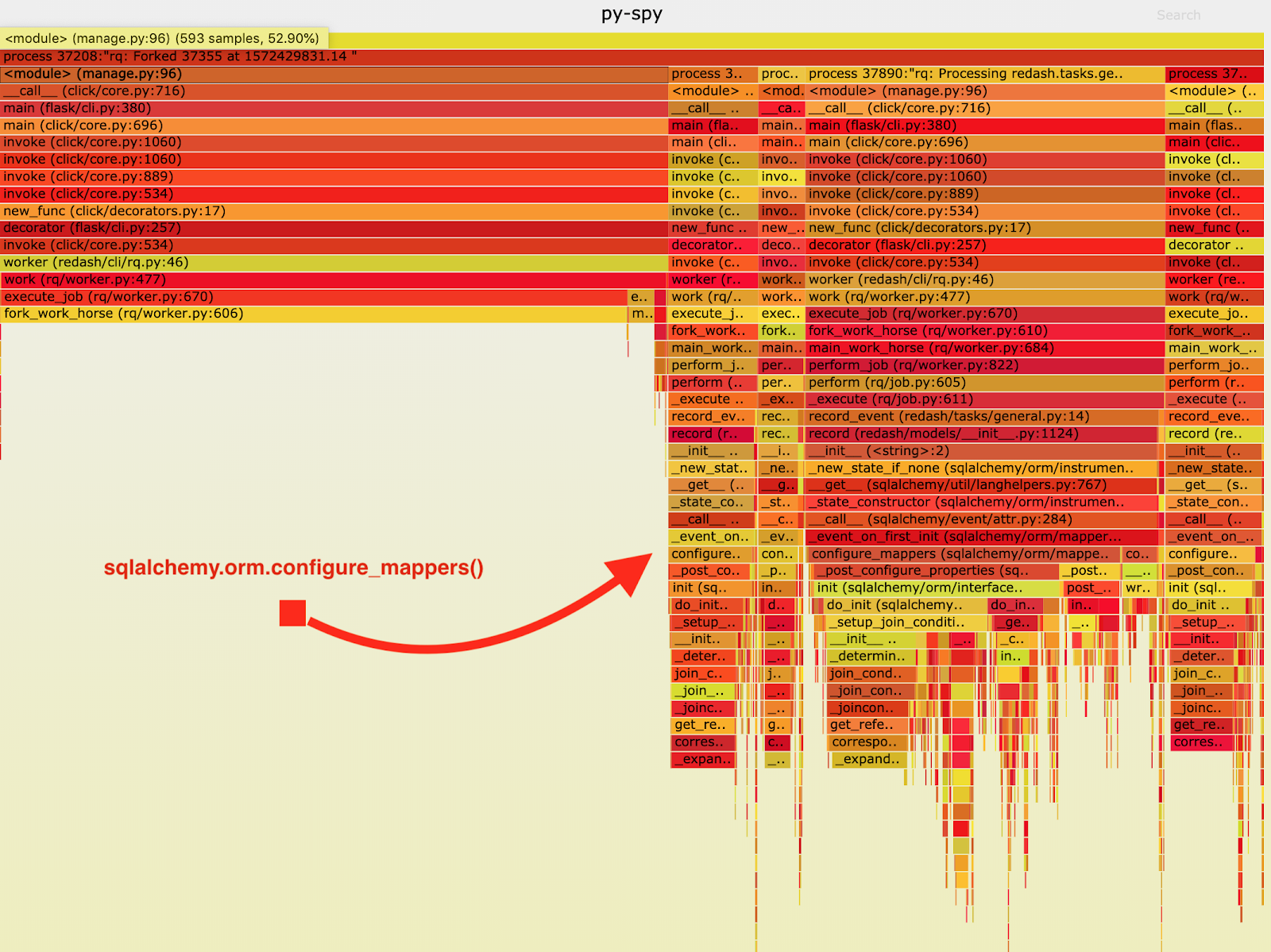
从火焰图中,我注意到record_event在sqlalchemy.orm.configure_mappers中花费了很大一部分的执行时间,并且每次处理一项工作时这种情况都会出现。从它们的文档当中,我知道了:初始化到目前为止已构建的所有映射器的映射器间关系。
的确不需要在每一个分支上都发生这种事情。所以,我们可以在主进程当中一次性地初始化这些关系,避免在多个子进程当中重复性这些工作。
因此,在启动进程之前,我已经对sqlalchemy.org.configure_mappers()进行了调用,并再次进行了测试:
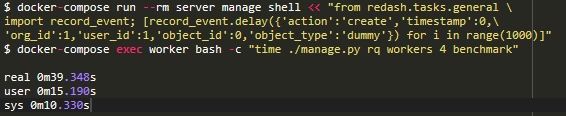
如果我们减去14.7秒的启动时间,4个线程处理1000项任务的时间将从102秒减少到24.6秒。 比以前提高了4倍! 通过修复此程序,我们成功地将RQ生产资源减少了4倍,并保持了相同的吞吐量。
我认为,你应该记住,在单线程和多线程的情况下,应用的行为是有所不同的。如果每一项任务没有繁重的重复的工作要做,通常最好在分到多个线程之前进行一次。这些事情在测试和开发过程中不会出现,因此请确保您进行充分的测试并挖掘出任何会出现的性能问题。英文原文:https://blog.redash.io/how-we-spotted-and-fixed-a-performance-degradation-in-our-python-code/
译者:Lyx


浮点型变量逻辑比较)




笔试题:不使用任何中间变量如何将a、b的值进行交换)
)


#define)




使用const修饰值不允许改变的变量)


