Tesseract
简介
Tesseract(/'tesərækt/) 这个词的意思是"超立方体",指的是几何学里的四维标准方体,又称"正八胞体"。不过这里要讲的,是一款以其命名的开源 OCR(Optical Character Recognition, 光学字符识别) 软件。
所谓 OCR 是图像识别领域中的一个子领域,该领域专注于对图片中的文字信息进行识别并转换成能被常规文本编辑器编辑的文本。
在 1995 年 Tesseract 曾是世界前三的 OCR 引擎,而且在现在的免费 OCR 引擎中,其识别精度也仍然是出类拔萃的。因为其免费与较好的效果,许多的个人开发者以及一些较小的团队在使用着 Tesseract ,诸如验证码识别、车牌号识别等应用中,不难见到 Tesseract 的身影。
程序安装
安装PIL
pip install Pillow
安装Tesseract
pip install tesseract
安装pytesseract
pip install pytesseract
编写程序
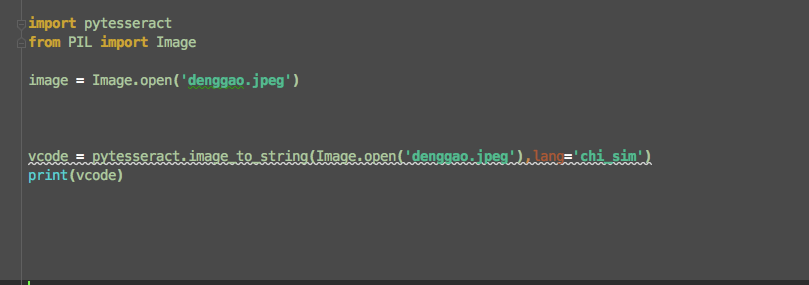
import pytesseract from PIL import Imageimage = Image.open('code1.png')vcode = pytesseract.image_to_string(image) print(vcode)
图片
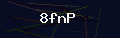
运行程序报如下错误
pytesseract.pytesseract.TesseractError
pytesseract.pytesseract.TesseractError: (1, 'Error opening data file /usr/local/Cellar/tesseract/3.05.01/share/tessdata/chi_sim.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory. Failed loading language \'chi_sim\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')
处理办法如下:
安装tesseract-ocr
分别下载
tesseract-ocr 和 tesseract-ocr语言包
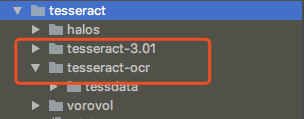
下载解压后放到 site-packages/tesseract/即可
如下图
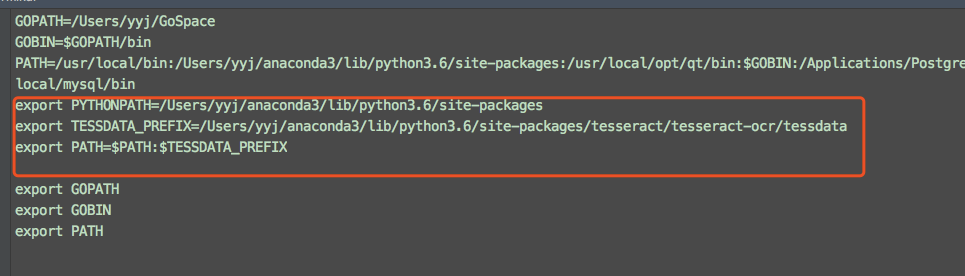
添加环境变量
如下图
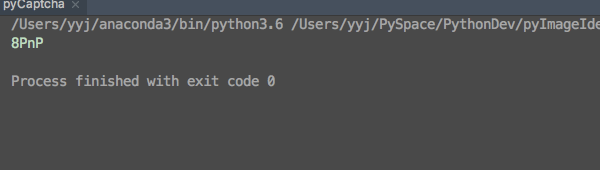
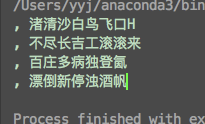
再次执行程序如下
中文识别遇到如下错误

需要添加语言包chi_sim
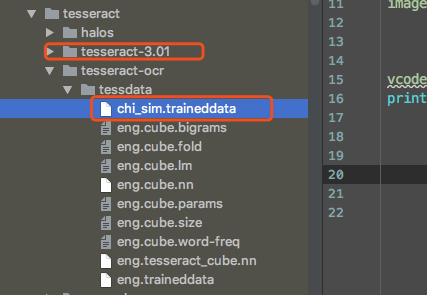
如上图,注意我这里是3.0.1的,所以要添加比这个版本小的文件,添加了3.0.4或5的都不行。















)



