
原 文 摘 要
针对智慧城市建设中各种业务数据对地名地址匹配准确度和效率不高的问题,本文提出一种面向智慧城市的高精度地名地址匹配方法。该方法在基于中文分词的地名地址匹配技术框架下,综合利用精细化地名地址库构建、地名地址特征分词库构建和基于用户搜索行为大数据分析 3 种关键技术提高地址匹配度和匹配精度。利用该方法对智慧德清建设项目中工商法人 6537 条数据和 130988 条精细化地址样本数据进行实验与分析。实验结果表明,在智慧城市大数据环境下,相比于传统地名地址匹配方法,该方法匹配精度高,效率也大大提升,同时在匹配度与精确度两个指标上匹配结果更加均衡。❖0
引 言
当前,智慧城市的建设如火如荼,空间位置信息作为城市信息的重要维度受到越来越多的重视。在城市工商、税务、规划、公安、银行等职能单位拥有的业务数据中,通常以文本形式描述区域、街路、门牌号码等空间位置信息[1]。如何将这些文本描述的空间位置信息与精确的空间位置进行匹配是地名地址匹配技术的关键问题[2]。因而,高效、高精度的地名地址匹配技术成为智慧城市建设空间位置信息获取与应用的必然需求[3]。如何建立适用于大数据环境下的地名地址匹配方法,并提供数据分析、定位以及可视化等功能,已成为我国智慧城市发展中的现实需要[4]。
由于中文地名地址的特殊性,中文地名地址的匹配一直以来也是地理信息领域研究的热点和难点问题。近年来,国内专家学者针对地名地址匹配的工作开展了大量研究。马照亭等基于可伸缩地址模型提出一种基于地址分词的自动地理编码算法,根据地理编码编制地址词典,利用地址词典进行地址分词形成地址要素及其级别,最终根据查询条件进行匹配[5]; 赵阳阳等提出基于地址要素识别机制的地名地址分词算法,基于整词二分分词词典,采用 FMM 算法,增加了基于地址要素的识别机制,从而有效地实现了对地名地址串的拆分[6]; 魏金明等针对市域地址数据特点,提出了一种基于置信度的地址匹配方法,该方法以地址数据库为基础,依托规范化地址编码,利用分词算法和置信度筛选的方法匹配数据,通过人机交互的方式扩充地址库,实现了地址的自动匹配定位[7]。
上述匹配方法主要都是从技术层面在某一个具体的关注点上提高匹配的精度,忽略了智慧城市大数据环境下的数据本身语义多样性、采集源异构等特征。目前这些高效准确的地名地址匹配技术并不能完全满足智慧城市建设的需求,无法提供高效精准的匹配和智能化服务,兼容性不强,覆盖面不广。因此,本文提出一种面向智慧城市的高精度地名地址匹配方法,首先在基于中文分词的地名地址匹配技术框架下,通过精细化标准地名地址库构建覆盖全面的全文检索索引库; 其次结合中文地名地址语义特点和通用地址表述方式,对通用地名地址词组设置不同的权重,构建面向地名地址匹配的特征分词库,以提高分词库的专业性,降低分词过程中的冗余和错误率; 最后,利用深度学习技术,将用户搜索行为和匹配结果进行统计与分析,进一步补充和完善专业特征分词库,提高地名地址匹配效率,以满足智慧城市建设的需求。
1
基于中文分词的地名地址匹配方法
基于中文分词的地名地址匹配采用的是全文检索技术[8],主要分为索引创建和索引搜索两个过程( 如图 1 所示) 。高精度地名地址库作为样本库,每一条地名地址都对应采集的精确空间坐标,索引创建利用分词库,通过分词组件对样本库中的地名地址文本字符串进行分词,形成一个一个的单词,然后对这些单词建立索引。匹配就是索引搜索的过程,将待匹配的字符串通过分词组件进行分词,然后与索引库中的索引进行匹配,找出匹配度最高的索引,然后得出与地名地址样本库中一致的空间位置,以此实现非空间信息向空间信息的转换[9-10]。
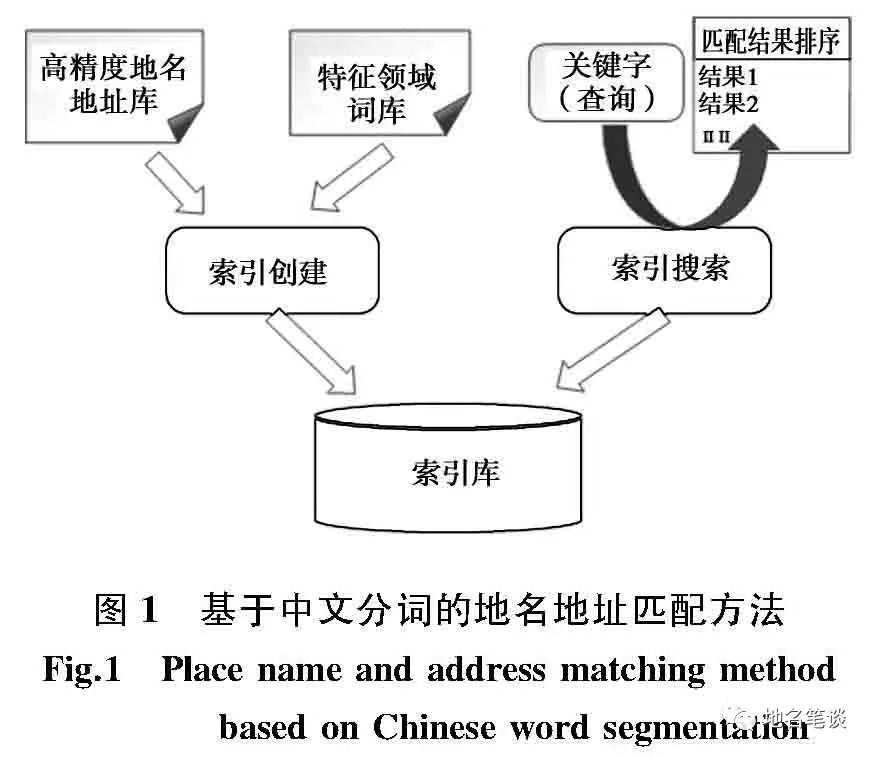
索引创建和索引搜索都离不开分词。分词是通过分词算法将标准化后的地址字符串分解成多个地址要素词组的过程。目前常用的中文分词方法主要有基于字符串匹配的分词方法、基于统计的分词方法、基于知识理解的分词方法和基于语义的分词方法。以“浙江省杭州市西湖区保俶北路 83 号”为例,对地址进行分词,可得到“浙江省 | 杭州市 | 西湖区 | 保俶北路 | 83 | 号”这组地址要素词组。同一条地名地址字符串,不同的分词库和不同的分词算法会得出不一样的分词结果,如上述地址也可分词为“浙江 | 省 | 杭州 | 市 | 西湖 | 区 | 保俶 | 北 | 路 | 83 号”。
影响全文检索的核心是样本库的详细程度和分词的准确性。样本库越丰富,描述越准确,则索引库越全,匹配的命中率和准确度越高。分词库越丰富,分词库语义特征越明显,则分词结果越好,索引创建和索引搜索的准确度越高。
2
面向智慧城市的高精度地名地址匹配方法
2.1 构建精细化的标准地名地址库
标准地名地址库的建立是地址匹配的基础和前提,需要将采集的城市地名地址按照确定的模型进行标准化,然后对标准地址要素进行编码。这些地址要素一般包括行政区域、街道名、小区名、门址和楼址、标志物名等。标准地名地址数据库存储各类地址的标准名称和空间坐标的唯一编码。在匹配过程中,输入的关键词需要在标准地名地址库中进行检索和匹配,因而标准库越详细,匹配的契合度就越高。本文采用以下3种方式实现全覆盖、高精度、实时更新的智慧城市标准地名地址库。
1) 多源采集模式。在传统的人工测绘采集方式的基础上,结合高分影像和在线众包模式实现区域内地名地址的全覆盖和高精度采集,采集的地名地址细化到门牌楼址信息。
2) 地址线性内插和模拟。对于不能够在标准地名地址库中准确查询匹配的数据进行地址线性内插和模拟,基本实现全覆盖地址数据[11]。我们利用待匹配地址的门牌号在地址库中查询相邻最近的前后一对地址门牌号,结合所在道路的门牌号编码规则,根据距离线性内插得到待匹配地址的空间位置。如查找 7 号地址,可利用已有空间位置的 5 号和 9 号进行内插和模拟。同时,当有新的门牌地址空间数据更新到地址空间数据库时,将之前匹配结果中内插匹配的部分重新利用上述流程计算一遍,让内插匹配的空间位置更接近真实位置。
3) 建立协同更新机制。在精细地名地址采集形成的数据库体上,采用多部门业务协同机制,实现多个涉及地名地址数据使用与更新的部门( 如民政、测绘、工商、公安) 之间的业务协同,实现地名地址数据的实时更新[12]。
通过以上 3 种方法的结合使用,可以形成完整的智慧城市地名地址数据库,在此基础上对所有的数据进行检查和标准化,形成精细化标准地名地址库,为地址匹配和索引库建立奠定基础。
2.2 建立面向地名地址匹配的专业特征分词库
中文地址分词具有准确性、高效性、通用性、适用性 4 个原则[13]。其中准确性关系到地址匹配的效率,提高分词准确性是地址分词的主要目标。国内对中文分词技术已进行了大量的研究,技术较为成熟,分词准确率已经超过 95%,本文主要采用基于字典匹配的分词方法。
基于字典匹配的分词方法又叫作基于字符串的分词方法或机械分词方法[14]。这种方法是基于词典的,即分词库,然后将待拆分的汉语字符串,按照一定的扫描规则与分词库的词条进行匹配。因而,基于分词库的匹配模式,最关键的是分词库的内容,不同的分词库和解析器,对同一个地址字符串则会分解成不同的词组[15]。如“保俶北路 83 号”可能会被分解为“保俶 | 北 | 路 | 83 | 号”或 “保俶北路 | 83 | 号”,显然后面一种分解更加符合实际情况。为保证地址字符串能准确地分解为符合实际需求的词组,本文通过在精细化标准地名地址库的基础上,对分词库的词语进行权重设置,建立面向地名地址的专业特征分词库。
1) 在分词库中加入具有地名和空间特征的通用词语,如“街道、路、巷,楼、幢、栋、小区”等词语,分词库中对这些词语设置高权重值。
2) 通过正则表达式,从精细地名地址样本库中提取具体的地名地址词组,主要包括具体的行政区划名称、街道马路名、楼幢名等,将这些词语也加入分词库,并设置高权重值。
3) 在基础中文词库的基础上减去与地名地址关系不大的一些特征词,降低与地名地址无关匹配,提高地名地址匹配的准确度。
2.3 利用深度学习完善分词库和提高匹配精度
随着人工智能技术的不断深化,深度学习在机器学习领域获得巨大进展,它用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征,在学习各类数据的规律中扮演着重要的角色[16]。类似于人类的学习能力,深度学习旨在利用计算机程序模拟出自学习系统,完成各种学习,可以使分类或预测变得更加简单[17]。
在智慧城市建设与出行导航过程中,我们发现描述空间位置语句十分复杂,目前还没有技术可以实现 100%的正确匹配。采用深度学习,让用户搜索行为和匹配结果进行学习,则可以不断提高匹配精度。用户在使用地名地址匹配进行检索时,都会使用正确且具有实际空间语义的词,这些词隐藏着用户行为习惯和个人认知,将这些词语进行记录,不断地加入分词库,让分词库不断完善和专业化; 同时将用户从匹配候选结果中选择的结果与搜索关键词进行关联,建立样本和标签的对应关系,生成深度学习样本数据,不断进行训练和学习,当下次进行相同关键词进行地名地址检索时,深度学习优先选择与之关联的地名地址作为结果词条。通过深度学习的地名地址匹配方法能预先自我纠错,提高匹配精度和效率,自动获取和发现所需要的知识和信息。
3
试验与分析
为了验证上述匹配方法的有效性,在智慧德清时空信息云平台的建设过程中,本文以智慧德清工商企业 6537 条数据作为待匹配试验数据,以德清 130988 条精细化为地址样本数据,通过空间内插和模拟后新增了 52300条地址数据,形成 183288 条全覆盖地址数据,并根据在线业务协同系统,每天平均更新 50 条地址数据和 43 条地名数据。在中文盘古分词库 146260 条的基础上新增 821条德清地名地址专业词,形成智慧德清地名地址专业分词库,见表 1。

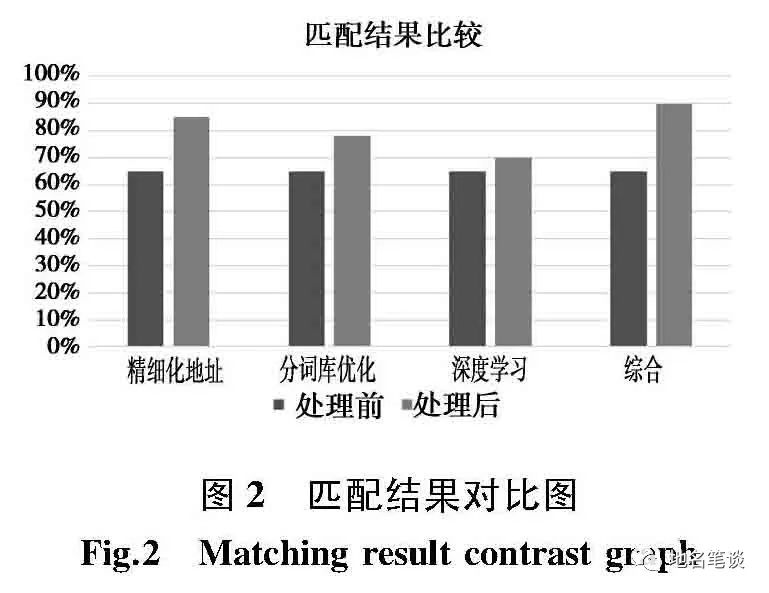
试验结果表明,在默认的中文分词匹配方法下,匹配准确率为 65%,通过精细化地址样本库完善能提高到85%,通过分词库优化能提高到 78%,通过基于用户搜索行为的深度学习能提高到 70%,通过 3 种方式的综合运用,可以将整个匹配结果从原来的 65%提高到 90%,如图2 所示。
4
结束语
智慧城市大数据环境下的地名地址匹配技术对推动智慧城市、智慧应用的发展提供了有力的技术支持。本文基于中文分词的全文检索匹配方法,针对全文检索的原理,提出通过精细地名地址库的建立、地名地址业务协同模式的采用来实现地名地址数据的常态化更新; 提取行政区划、道路、房屋等测绘地理信息专业词谱,建立面向地名地址匹配的中文分词库; 通过对用户搜索行为的深度学习来完善分词库,并提高匹配关联度 3 种方式的综合运用水平,能有效提高地名地址匹配准确率,能够较好满足智慧城市建设中各类专题部门的地址信息空间化需求。该方法在处理智慧城市大规模数据时,相比于传统地名地址匹配算法,在一定程度上提升了效率和性能,有效地提高了地名地址在智慧城市建设中的应用价值。
参考文献[1] 李琴,梁寒冬,付蔚霞.宁波市地名地址数据建设与用[J]. 测绘与空间 地 理 信 息,2017,40 (8) : 212 -214,217.
[2] 江洲,李琦.地理编码( Geocoding) 的应用研究[J].地理与地理信息科学 2003(3) : 22-2.
[3] 李林,程宇翔.智慧重庆地理编码系统研究与应用[J].地理空间信息 2015,13(6) : 40-43,12.
[4] 许普乐,王杨,黄亚坤,等.大数据环境下基于贝叶斯推理的中文地名地址匹配方法[J]. 计算机科学, 2017,44(9) : 266-271.
[5] 马照亭,李志刚,孙伟,等.一种基于地址分词的自动地理编码算法[J].测绘通报 2011(2) : 59-62.
[6] 赵阳阳,王亮,仇阿根.地址要素识别机制的地名地址分词算法[J].测绘科学 2013,38(5) : 74-76.
[7] 魏金明,仲伟政.基于置信度的地址匹配方法初探[J].测绘科学 2015,40(1) : 122-125.
[8] 李奇.基于 REST 风格的地理编码服务研究[D]. 青岛: 山东科技大学 2012.
[9] 张雪英,闾国年,李伯秋,等.基于规则的中文地址要素解析方法[J].地球信息科学学报,2010,12 (1) : 9-16.
[10] 吕欢欢. 基于地理信息公共服务平台的语义地名地址匹配方法研究[D].阜新: 辽宁工程技术大学 2014.
[11] 闵星,周冲,曹伟.基于内插的一种门牌地址匹配方法的研究与实现[J].测绘与空间地理信息,2015,38(6) : 119-120,12.
[12] 李东阳,方俊杰,许大璐.GIS 技术支持下的多部门地名地址业务协同研究与实现[J]. 测绘通报,2016(10) : 121-124.
[13] 谭侃侃. 基于规则的中文地址分词与匹配方法[D].青岛: 山东科技大学 2011.
[14] 程琦,梁武卫,汪培.基于复合字典的地名地址匹配技术[J].城市勘测 2018(1) : 76-78,82.
[15] 陈建英. 面向中文地址的分词引擎设计及实现[D].北京: 中国科学院大学 2015.
[16] 奚雪峰,周国栋.面向自然语言处理的深度学习研究[J].自动化学报 2016,42(10) : 1445-1465.
[17] 来斯惟,徐立恒,陈玉博,等.基于表示学习的中文分词算法探索[J].中文信息学报 2013,27(5) : 8-1.
作者简介张剑( 1985- ) ,男,湖北监利人,浙江省自然资源监测中心工程师,硕士,2010 年毕业于中南大学地图制图学与地理信息工程专业,主要从事空间地理大数据分析及应用工作。叶远智,浙江省自然资源监测中心。翁宝凤,浙江省自然资源监测中心。End
原载于《测绘与空间地理信息》2019年11期。地名笔谈小组搜集整理,如文字识别录入偶有差错,请见谅。非商业用途,如有侵权请联系删除。转载请注明。
往期推荐【地名地址】地名地址应用服务系统的研究与实现
2020-10-15

【地名地址】基于地名地址的政务数据空间化方法
2020-11-03
【地名地址】县区地名综合数据库建设研究
2020-11-26



点个在看,你最好看










)




...)
)



