为什么要迁移,江湖上传说windows server的稳定性不如某某某,这类议题与八卦新闻没两样,不谈,如果windows的价钱能够和linux相同或者差异不至于那么大,我才懒得换,因为穷,这才是重点。
涉及IO路径拼接,一定要Path.Combine, 反正我自己眼力比较差,手工拼接的话,有时候多一个或少一个斜杠,或者斜杠方向反了,Linux系统都会出错,搞半天不知道错在哪,如果大小写都搞错却没注意或者一时不知的话,神仙都救不了。
注意用System.Environment.NewLine代替硬编码的换行符,String.Empty代替"",这两个看不见的东西,发作的时候喝脑白金都没用。
而core在初始化的时候,会遍历wwwroot文件夹包含的所有内容,在windows中无所谓你文件夹怎么命名,在中文centos也无所谓你文件夹怎么命名。但是,如果你的生产服务器是英文系统,恰好在wwwroot中有中文文件夹的话,你都不知道为什么会全局报错。关于中文文件夹(在某些时刻会演变为乱码文件夹),我也不知哪里来的,有些客户端编辑器组件,就是包含了非英文的文件夹。所以搭建虚拟机测试环境的时候,guest系统需要安装英文版本来验证。
newtonsoft的json在反序列化枚举类型的时候,得到的是名,微软自家的json在反序列化枚举的时候,得到的是值,虽然可以通过特性来定义,但是本人对特性相当反感,全套代码不会用也不可能会用,所以有时候需要用class来代替enum。
Microsoft.AspNetCore.NodeServices 是个好东西,就简单来说,正则表达式验证库,只写一次,客户端和服务端都可以共用。
Program.Main方法里,可以建立后台线程,里面放一个全局静态的ConcurrentQueue<Action>,while(true)定时监视它,今天我们编写的是进程级的asp.net,你可以让它做很多IIS做不到的真正异步,比如说记录某些日志,扔action进去就是了,不必等待。
事情还可以做得更绝一些:开辟新进程,把代价高昂的、不确定是否会出错的、却需要立即清理内存的操作丢给它,操作完了自动关闭,在这一层面上,你可以藐视.net的垃圾回收。
如果你实在玩不来gulp也没关系,装个BundlerMinifier就行了,右键选几个js后自动压缩
能用PocoController的时候,尽量用,比如说某些频繁的API,它的资源占用最小。
为HttpClient建立池,static ConcurrentQueue<HttpClient>,两三个就够了,一般不会出错,但是谁也不能保证网络请求,错了一个就让下一个来代替,然后把出错的扔到上面的ConcurrentQueue<Action>中让它爱什么时候销毁什么时候销毁。
文件级数据库,比如说SQLite,也需要ConcurrentQueue<Action>来封装写入逻辑,绝对的保证同一时刻只有一个线程写,同时做好定时自动备份并且是每小时、每半天、每天、每星期这样的多个备份,否则不可预料的IO把你的数据库搞坏,喊天天不应。
总会遇到有人和你劝说XXX是世界上最好的语言,遇到这些事情我不会争论的,给他一份最新的岛国女演员名单就可以了。
windows上你不能覆盖一个正在运行中的dll,但是linux上可以,先覆盖,再重启,但是如果连重启都不允许的话,就开启新的端口,让前段服务器热切换,nginx的reload命令是实时的,如果你连前nginx也没有,直接kestrel面向公众,却又不允许一秒钟以上的暂停服务,那就新建服务器来等待域名DNS切换吧。
传统ASP.NET的Bundle功能现在见不到了,需要在开发阶段手动通过gulp来压缩,但是如果遇到需要实时构造js的情况怎么办? 现在既然有了NodeServices,服务端压缩在理论上不是问题,目前我还没实现,正在研究。
别折腾与XML相关的东西,凡是XML做的事,都可以用JSON来代替,光是头部一大车的uri垃圾代码与脱裤子放屁的namespace两项,足以让我彻底抛弃它。
该缓存的东西,用内存来缓存,比如说某些不可能上万条目的目录, 建一个静态字典才1M不到,却可以少做一次inner join。
该不该内联javascript,对此我分两个阶段,项目初期是内联几句最简单的代码,动态生成script标签来请求真正需要的javascript,然后把内容记录到本地indexedDB中,以后再也不请求js代码了,从本地数据库中读即可,head加一个meta标签来标识javascript是否需要重新读取,css也是同样的道理,如此一来内联的代码也就十多行,这价钱花得起。到了第二阶段,内联和本地数据库也省了,因为有了http2,服务端推送结合max-age,一次TCP连接也是花费得起的(注意这里说的是TCP, TCP!),它同样是仅一次真正传输内容。
关于 public async Task<IActionresult> xxxx() ,此异步非彼异步,具体就不详解了,请自行搜索。有时候我们需要在一个请求上下文中同时做到等同于桌面应用中的“真异步”,你就不要await,虽然visual studio会给出绿色提示说让你为某个task加上await,加上的话你才是错了。而是应该TASK的start()后干别的事情,在方法最后统一waitall。当然此方式涉及到线程开销,要根据具体问题来取舍。
可能你会需要这一段代码,否则MVC自带的 return Json(某对象) 会被强制修改为小写,据说那是JSON规范,少来,鸡毛规范和我一点关系没有,我只认识过度的自作聪明是找骂。
| 1 2 3 4 5 6 7 8 9 | services.AddMvc().AddJsonOptions(opt => { var resolver = opt.SerializerSettings.ContractResolver; if (resolver != null ) { var res = resolver as DefaultContractResolver; res.NamingStrategy = null ; // <<!-- 修正默认JSON全部变成小写的问题 } }); |
同理,关闭一切杀毒软件,包括windows defender,我就遭遇到windows defender要求上传一份sqlite的操作代码到它的服务器作分析,而这份代码是来自最新的core 1.1,又不是我写的,传或不传呢?这不重要,重要的是我因此把windows defender永久禁用。还好它没删东西,但是换做别家,可能就没这么好说话了,到时你的kestrel一直报500都不知道为什么。
通过某时间段的请求频率确定恶意刷新后,立即永久屏蔽IP,IP列表保留在内存中,Configre的app.UseMiddleware阶段就进行判断,10M的IP列表,加上集群负载均衡,压力再大的话请求azure的防火墙加持,这一切都应该是程序进行(azure有相应API),看谁玩得狠。
注意检查服务器日志,某些阿三搜索引擎、自诩为你安全着想的防火墙、三流云监测、等等,会加大你的服务器压力,从IP和UserAgent上两方面屏蔽它们。
注意识别请求路径,比如说遇到请求“/phpmyadmin”的,绝对是加入永久屏蔽IP列表。
(个人问题,不具备参考价值,请勿仿效):数据库架构尽可能简单,从前基于SQLServer,什么乱七八糟的功能都用上,但是同时也造就了迁移过程中一道巨大的壁垒,解决办法有三:
只迁移应用程序,不迁移数据库,但是如果说应用程序运行在Linux,却依然依赖于Windows上的SQLServer的话,对于系统的迁移目的来说,是掩耳盗铃。
Linux版SQLServer,且先不说它目前是RC,重点依然是个人原因,需要一台4G内存的主机,穷,买不起。当年谷歌通过廉价PC构造集群的思路,始终值得学习。
【采用】重构数据库架构,什么存储过程、地理编码、表间关联…… 通通不要了(个人问题,不具备参考价值,请勿仿效),由应用程序来代替之,数据库只保留最基本的表存储、最基本的数据类型、做到最大的兼容性,于是现在服务器A基于SQLServer、服务器B基于SQLite、服务器C基于MySQL、它们共用相同的应用程序、分布在三个地理位置,组成API集群,定时相互同步数据,让各种各样的前端服务器、移动端应用程序根据地理位置的变化、实时热切换数据源,同时使用三个不同的数据库来运作,是出于实验目的,打算再观察几个月,看看它们分别有什么表现,为以后能否在经济上优化作参考。
同时,几台www服务器组成另一个集群,处理各种客户端的交互,包括与APP交互,www集群节点也具备集群中某一节点崩溃时自动重建功能,但是不与数据库直接打交道,只与API集群交互,不可感知API服务器的再后端使用了什么数据库。如此就具备了热切换API节点的能力,为什么要构造“两道转轮”式的架构呢,因为频繁的功能更新、BUG修复,只要保证通信协议的不变,无论是WWW集群或API集群中任一节点下线,都不会影响整套系统的运行,域名的DNS服务层面上监视着WWW集群的健康状态,最终客户正在请求的某个www节点下线时,DNS服务器可感知,便会实时把最终客户的域名请求调度到下一个健康的www节点的IP,而www集群所有节点也记录了所有api集群节点的地址,可以在当前与API的通信崩溃时自动筛选到下一健康节点尝试连接,筛选的过程是地理位置优先,然后是健康状态。它们跨洋分布在三个国家,除非三个国家都同时停电,否则系统将会完好运行,最终客户不会感知到变化。
下面是我用一段JSON伪代码来描述它们之间的关系,注意颜色对应,x表示会变动的下标:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | { client: {member:[html-web, winform, ios, android], request:wwwserver[x]}, wwwserver: [ node1:{kestrel1:{server:www, request: apiserver[x]}, kestrel2:fileserver}, node2:{kestrel1:{server:www, request: apiserver[x]}, kestrel2:fileserver}, node3:{kestrel1:{server:www, request: apiserver[x]}, kestrel2:fileserver} ], apiserver: [ node1:{database:sqlite}, node2:{database:sqlserver}, node3:{database:mysql} ] } |
下面再来说说文件服务器,它们是第三层集群,也就是上面伪代码中的fileserver:
因为我的服务器中有大量的照片,它们的流量是个很大的问题,说要租CDN吗,1T流量一年300块钱左右,平均下来每个月850M,我某个主题就包含200多张照片,要花50M的流量,为什么这么大,过去1280宽度的屏幕,照片就得2560宽度,然后CSS缩小50%,通过这样间接的超采样,才能照顾retina。这 850M/每月 够塞几次牙缝?加流量吧,10T每年需要3000块钱,而这价钱可以买上好几台性能不错的服务器了,而且免流量。而且10T还不一定够,再加? 穷。 所以在很久以前的最前期,我弄了个投机办法,但不是长久之计:淘宝卖家图片空间,支持外链,它分布全国的cdn不用说了吧。我在博客园同样也上传有很多照片,不过请站长放心,我没干那事,以后也不打算干。
淘宝图片空间:总有一天它会关闭或者加某些限制的,所以目前已经不再添加新的东西进去了,但是在有些页面上,还在链接着,懒,有空再改。
【目前的方案】自建文件服务器,目前它们分布在浙江、武汉、山东、成都、美人希,www服务器会根据请求者的地理位置,返回 <img src="https://最近的文件服务器IP" />,依然是基于成本考虑,国内这四个地区服务器的总运营成本每年2000块钱左右,而且免流量。而在国外的服务器基于azure,也是买的最廉价版本,每月14.88美元,按照7的汇率换算,约104每月,每月1T流量,看似还是不够,但是要知道在网络zi-you区,绑定cloudflare的免费cdn就行了。 国内的四个文件服务器直接请求IP,反正img的src是动态的,一来免去了那道你懂的手续,二来没有dns,也相对的提升了速度。当然也留有一手后路:一个总开关统一请求美人希(反正那时候就不是快与慢的问题了)。这几个文件服务器之间也自发性的组成一个集群,它们会相互同步文件,坏了没关系,集群中的第一个感知到的节点会通过API尝试重启,三次重启失败的话会销毁旧的,同时建立一个新的服务器,然后再自动同步。
这下知道我为什么要把代码放到linux了吧,便宜,你仔细找还是可以找到的,windows不可能有这价钱,坏了拉倒,立即重建,整个自动化重建过程不到5分钟。重建后服务器间的同步填充,通过http2的流式连接,快得很。而通过core的selfhost编译出来的应用程序,你的裸机根本不需要装运行时,sftp传上去就立即启动运作,azure上就更方便了,我之前建好iso,基于iso启动就完事,传程序都免了,只需同步内容数据。
说到这,又验证了一个道理:这个世界,只分为两处:墙内和墙外。
这样一来每年总的运营成本3400块钱左右,基本上不需要再为流量操心。当然,光是这么做还不够,为了缓解瞬间并发压力,客户端缓存是必不可少的,Cache-Control 的 max-age 设置了尽可能的大,反正二进制文件不可能更改的,要改也是改img的src。同时,也通过http2来优化连接效率,关于http2,以下是我给出的配置,从一台centos 7.1裸机起步,假设已经是root:
暂时利用一下nginx:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | 添加: /etc/yum .repos.d /nginx .repo 内容: [nginx] name=nginx repo baseurl=http: //nginx .org /packages/centos/ $releasever/$basearch/ gpgcheck=0 enabled=1 yum install nginx #目前是1.10.2,先让它自动安装。重点是它会替你去折腾各种配置。 然后: yum install vim wget lsof gcc gcc -c++ bzip2 -y yum install net-tools bind-utils -y yum install expat-devel yum install git wget http: //sourceforge .net /projects/pcre/files/pcre/8 .36 /pcre-8 .36. tar .gz wget http: //zlib .net /zlib-1 .2.8. tar .gz wget https: //www .openssl.org /source/openssl-1 .0.2h. tar .gz wget http: //nginx .org /download/nginx-1 .10.2. tar .gz tar xzvf pcre-8.36. tar .gz tar zxf openssl-1.0.2h. tar .gz tar xzvf zlib-1.2.8. tar .gz tar xzvf nginx-1.10.2. tar .gz git clone git: //github .com /yaoweibin/ngx_http_substitutions_filter_module .git git clone https: //github .com /arut/nginx-dav-ext-module git clone https: //github .com /gnosek/nginx-upstream-fair git clone https: //github .com /openresty/echo-nginx-module cd nginx-1.10.2 . /configure --prefix= /etc/nginx --sbin-path= /usr/sbin/nginx --modules-path= /usr/lib64/nginx/modules --conf-path= /etc/nginx/nginx .conf --error-log-path= /var/log/nginx/error .log --http-log-path= /var/log/nginx/access .log --pid-path= /var/run/nginx .pid --lock-path= /var/run/nginx .lock --http-client-body-temp-path= /var/cache/nginx/client_temp --http-proxy-temp-path= /var/cache/nginx/proxy_temp --http-fastcgi-temp-path= /var/cache/nginx/fastcgi_temp --http-uwsgi-temp-path= /var/cache/nginx/uwsgi_temp --http-scgi-temp-path= /var/cache/nginx/scgi_temp --user=nginx --group=nginx --with- file -aio --with-threads --with-ipv6 --with-http_addition_module --with-http_auth_request_module --with-zlib=.. /zlib-1 .2.8 --with-pcre=.. /pcre-8 .36 --with-openssl=.. /openssl-1 .0.2h --with-http_dav_module --with-http_flv_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_mp4_module --with-http_random_index_module --with-http_realip_module --with-http_secure_link_module --with-http_slice_module --with-http_ssl_module --with-http_stub_status_module --with-http_sub_module --with-http_v2_module --with-mail --with-mail_ssl_module --with-stream --with-stream_ssl_module --with-cc-opt= '-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -m64 -mtune=generic' --add-module=.. /echo-nginx-module --add-module=.. /nginx-upstream-fair --add-module=.. /nginx-dav-ext-module --add-module=.. /ngx_http_substitutions_filter_module make && make install |
现在就可以按照你自己的需求配置nginx了。下面是https的配置:
yum -y install git bc git clone https: //github .com /letsencrypt/letsencrypt /opt/letsencrypt /opt/letsencrypt/letsencrypt-auto --help systemctl stop nginx /opt/letsencrypt/letsencrypt-auto certonly --standalone -d example.com -d www.example.com -d foo.example.com # -d后面是你的各种域名,注意修改 systemctl start nginx openssl dhparam -out /etc/ssl/certs/dhparam .pem 2048 |
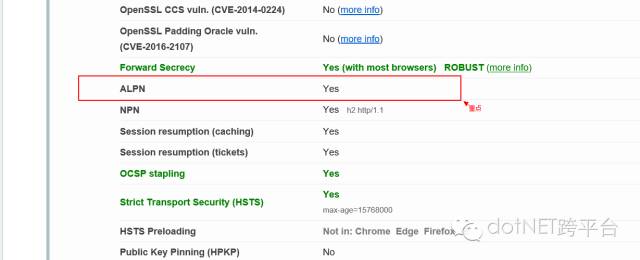
到此,你的nginx已经可以支持http2和http2了。只强调两点:1,openssl 必须是 1.0.2h 或者更高,2,如果你的服务器身在墙内,yum下载各种包的时候,有可能会遇到网络问题,这不是你的错。
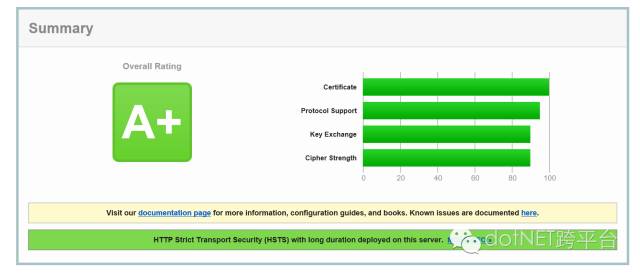
哪怕你不需要http2,但是你一定会需要https,从2017年开始,chrome会对普通http提示“这是不安全网络”,有些心理毛病的客户会据此猜测你的网站有病毒、甚至还会演变为你的网站会盗他支付宝的钱、甚至他家的鸡少下一个蛋都会说你网站有辐射,你会去和这类人解释什么叫ssl吗?我是不会的。 苹果AppStore不再接受请求http的app发布,意味着如果你的服务器同时是app的api,就必须升级。
下面是一段server的例子:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | server { listen 443 ssl http2; server_name www.*; ssl_certificate /etc/letsencrypt/live/ 你的具体路径 /fullchain .pem; ssl_certificate_key /etc/letsencrypt/live/ 你的具体路径 /privkey .pem; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_prefer_server_ciphers on; ssl_dhparam /etc/ssl/certs/dhparam .pem; ssl_ciphers 'ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:DES-CBC3-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA' ; ssl_session_timeout 1d; ssl_session_cache shared:SSL:50m; ssl_stapling on; ssl_stapling_verify on; add_header Strict-Transport-Security max-age=15768000; location / { proxy_pass http: // 你的kestrel的实际运行地址; proxy_redirect off; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $host; } } |
暂时先总结到此,文中的azure指另一个世界的azure。至于镇内的四台服务器可随时乱搞,爱怎么换就怎么换。
镇内的运营商有时候不得不做一些违背经营之道的事,也是迫不得已,体谅他们的同时,自己也不得不留一手后备之路。也幸亏他们,从前一个单机web小系统,演变为今天如此复杂的分布式。
目前还待解决的问题
1: 为什么我说要暂时利用一下nginx, 虽然说kestrel自身也可以承载https,但是目前每一个服务器节点上都运行着两个kestrel实例,如果让它们直接面向公众,就出现端口冲突问题,所以也必须通过nginx来做反向代理,否则我也不愿意折腾这事情,目前也正在想法怎么可以抛弃前端代理,现在思路是:
合并两个服务的代码,kestrel就只有一个了。
分离到两台服务器,成本翻倍,穷。
等你补充
为了整套系统的全面控制,这事情是一定要做的,而且我也不相信前端服务器必备的论点,什么DDOS,欢迎来搞。
2:TypeScript的服务端运行,通过Google搜索: typescript run on server ,你会发现很多有趣的讨论,为了更好的融合客户端与服务端。
3:GPU计算一直是我向往的事情,在我认为,Core的优势不仅仅是跨平台,“进程级”才是它的重点,目前我们处于进程级,就可以操控GPU,而且Azure已经提供了搭配Tesla处理器的主机,而目前我的这套系统也与地理坐标有着业务关联,待我收集多一些数据,再来开启这套技术怎么应用。
4:仅存于疑问阶段:根据P2P打洞原理,服务器探测到多个请求者存在于同一个相距很近的地理区域时,互相介绍两个请求者建立连接,然后这两个请求者之间互相同步内容数据,这一切都是基于javascript+indexedDB来实现。前提是他们都在打开某个不会短时间内关闭的连接。反正还待研究。
5:目前我还卡在windows的visual studio上,是因为项目库用的是visual studio online 的 git 同步备份代码,明明两个月前我还在mac的vs code上可以同步代码,现在我在非windows visual studio的一切git客户端都登不上去了,包括windows版的vs code也登不上,不是网络问题,我用户名密码也没错,连接VPN也是一样,我搜了一下说要在项目主页里面寻找一个叫Secret什么的开关,我找到了,开了也没用,而且我也没动过这些相关的东西,如果是一开始就不行,我也就认了,现在是中途不让登了,不是我的错,搞了半小时不搞了,以后有时间自建服务器。
6:升级到1.1后,visual studio可以编译,但是不让发布了,不知原因,输出界面没有任何提示,反正就是点击了发布之后,瞬间完成动作,实际却什么都没做。 现在通过自建命令行cmd文件来发布,反正以后切换平台也是命令行编译发布,也就无所谓了。
原文地址:http://www.cnblogs.com/kvspas/p/dotnet-core-2years-by-liangyichen.html
.NET社区新闻,深度好文,微信中搜索dotNET跨平台或扫描二维码关注

)


















