MySQL常用的语句语法
注意:1、 | 符号用来指出几个选中中的一个,因此NULL | NOT NULL 表示给出null 或 not null
2、包含在方括号中的关键字或子句是可选的(如 [like this])3、既没有列出所有的MySQL语句,也没有列出每一条子句和选项
4、大写的表示 MySQL语法关键字
一、命令行指令:
1、启动MySQL
net start mysql
2、连接与断开服务器
mysql -h 地址 -P 端口 -u 用户名 -p 密码
二、数据库操作
1、查看当前数据库
select database();
2、显示当前时间、用户名,数据库版本
select now(),user(),version();
3、创建库
create database [if not exists] 数据库名 数据库选项
其中数据库选项有
--选择字符集
CHARACTER SETcharset_name--校对规则
COLLATE collation_name
4、查看已有库
show databases[like 'pattern']
5、查看当前库信息
show create database 数据库名
6、修改库的选项信息
alter database 数据库名选项信息
7、删除库
drop database[if exists] 数据库名
三、表操作
1、CREATE TABLE
create table 用于创建新数据库表,更新已存在的表结构使用 alter table ,constraints 表示约束
CREATE TABLEtable_name
(column datatype [NULL | NOT NULL] [CONSTRAINTS],column datatype [NULL | NOT NULL] [CONSTRAINTS],
···
);
相对复杂的
create [temporary] table [if not exists] [库名.] 表名 (表的结构定义)[表选项]
其中 temporary 表示临时表,会话结束时表自动消失
注意:
a、每个字段必须要有数据类型,最后一个字段后不能有逗号
b、对于字段的定义:
字段名 数据类型 [NOT NULL|NULL] [DEFAULT default_value][AUTO_INCREMENT] [UNIQUE [KEY]|[PRIMARY] KEY] [COMMENT 'string']
c、表选项:
字符集
CHARSET = charset_name
如果表没设定,使用数据库字符集
存储引擎
ENGINE = engine_name
表在管理数据时,往往采用不同的数据结构,结构不同会导致处理方式、提供特性操作等也不同
常见的存储引擎:InnDB、MyISAM、Memory/Heap、BDB、Merge、Example、CSV、MaxDB、Archive
不同的存储引擎在保存表的结构和数据时常采用不同的方式
MyISAM 表文件含义: .frm 表定义, .MYD 表数据, .MYI 表索引
InnoDB 表文件含义: .frm 表定义、表空间数据和日志文件
--显示存储引擎的状态信息
SHOW ENGINES--显示存储引擎的日志或状态信息
SHOW ENGINES 引擎名 {LOGS| STATUS}
2、查看所有表
SHOW TABLES[LIKE 'pattern']SHOW TABLESFROM 表名
3、查看表结构
SHOW CREATE TABLE表名DESC 表名 / DESCRIBE 表名 / EXPLAIN 表名 /
SHOW COLUMNS FROM 表名 [LIKE 'pattern']SHOWTABLE STATUS [FROM db_name] [LIKE 'pattern']
4、ALTER TABLE
alter table 用来更新已存在表的模式,为了创建新表,应该使用create table,constrains 表示约束
ALTER TABLEtablename
(ADD column datatype [NULL | NOT NULL] [CONSTRAINTS],CHANGE column columns datatype [NULL| NOT NULL] [CONSTRAINTS],DROP column,
······
);
a、修改表本身选项
ALTER TABLE 表名 表名的选项
b、对表进行重命名
RENAME TABLE 原表名 TO 新表名
c、修改表的字段结构
ALTER TABLE 表名 操作名
有如下操作名
--增加字段
ADD [COLUMN]字段名--创建主键
ADD PRIMARY KEY(字段名)--创建唯一索引
ADD UNIQUE [索引名](字段名)--创建普通索引
ADD INDEX [索引名](字段名)--删除字段
DROP [COLUMN]字段名--支持对字段属性进行修改
MODIFY [COLUMN]字段名 字段属性--支持对字段名进行修改
CHANGE [COLUMN]原字段名 新字段名 字段属性--删除主键
DROP PRIMARY KEY
--删除索引
DROP INDEX索引名--删除外键
DROP FOREING KEY 外键
5、删除表
DROP TABLE [if exists] 表名 ...
6、清空表数据
TRUNCATE [TABLE] 表名
7、复制表结构
CREATE TABLE 表名 LIKE 要复制的表名
8、复制表结构和数据
CREATE TABLE 表名 [AS] SELECT * FROM 要复制的表名
四、数据操作
1、INSERT
insert 给表增加一行,或多行
INSERT INTO table_name [(column,···)]
VALUES(values,···);--INSERT INTOtable_name[(column,···)]
VALUES(values,···),
(values,···),
···
(values,···);
insert select 插入select 的结果到一个表
INSERT INTO table_name [(columns,···)]
SELECT columns,··· FROMtable_name,···[WHERE ···];
注意:
如果要插入的值列表包含所有字段并且顺序一致,则可以省略字段列表,
可以同时插入多条记录
字段列表可以用 “*”代替表示所有字段
2、DELETE
delete 从表中删除一行或多行
DELETE FROM table_name [WHERE ···] ;
没有条件子句,会删除所有数据
3、UPDATE
update 更新表中一行或多行
UPDATE table_name SET column_name =value,···[WHERE ···];
五、字符集编码
MySQL,数据库,表,字段均可设置编码
--数据编码与客户端编码不需一致--查看所有字符集编码项
SHOW VARIABLES LIKE 'character_set_%'
--客户端向服务器发送数据时使用的编码
character_set_client--服务器端将结果返回给客户端时使用的编码
character_set_results--连接层编码
character_set_connection
注意:
--设置编码
SETNAMES GBK;--相当于完成以下三个设置
SET 变量名 =变量值
setcharacter_set_client=gbk;
setcharacter_set_results=gbk;
setcharacter_set_connection= gbk;
六、查询语句
1、SELECT
select用于从一个或多个表(视图)中 检索数据
SELECT columns_name, ··· FROMtable_name, ···[WHERE ···],[UNION ···],[GROUP BY ···],[HAVING ···],[ORDER BY ···];
详解:
select [all | distinct] select_expr from ->where->group by[合计函数] ->having->order by ->limit
其中
1.1、select_expr
a、计算公式、函数调用、字段也是表达式
如:select 12+11,now(),name from tb_obge;
b、使用as 关键字为每个列设定别名,适用于简化列标识,避免多个列标识符重复。
如:select sheng_shi_xian as address from tb;
1.2、 from 子句
用于标识查询来源
a、使用 as 关键字为表起别名
--列如
select * from tb_obge1 as t1,tb_obge2 as t2;
b、from 子句后可以同时出现多个表。多个表会横向叠加到一起,而数据会形成一个笛卡尔积
就是下面的意思
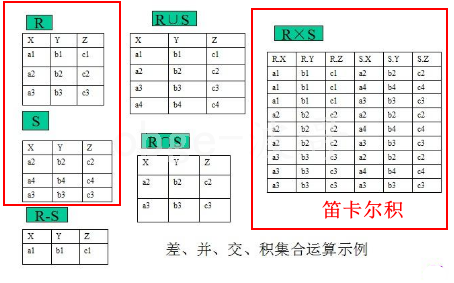
--如:
select * from tb_R,tb_S;
c、where 子句
用于从from 中获得的数据源中进行筛选。1为真,0为假,表达式由运算符和运算数组成
d、group by子句
group by 字段/ 别名 [排序方式]
分组后会进行排序,升序:ASC,降序 DESC
与group by子句常配合使用的聚合函数有--返回不同的非 NULL值数目,如count(*),count(字段)。
count
--求和
sum
--求最小值
mim--求最大值
max
--求平均值
avg
--返回带有来自一组的连接的非NULL 值的字符串结果,为组内字符串连接
group_concat
e、having 子句(条件子句)
与where 功能、用法相同、只是执行时机不同。where在开始时执行数据检测,对原数据进行过滤。having 对筛选出的结果进行再次过滤,where 不可以使用聚合函数。一般需要用到聚合函数才会用having。SQL 标准要求having子句必须引用group by 子句中的列或用于聚合函数中的列。
f、order by 子句(排序子句)
--支持对多个字段排序,升序ASC ,降序 DESC
order by 排序字段/别名排序方式[,排序字段/别名排序方式]...
g、limit 子句(限制结果集 子句)
仅对处理好的结果进行数量限制。将处理好的结果看作是一个集合,按照记录的现后顺序,索引从 0 开始
--limit 获取条数 其中,省略第一个参数,表示索引从 0 开始。
limit 起始位置,获取条数
h、distinct 选项
用于去除重复记录
2、多表联结查询
2.1、UNION
建议对每个select查询加上小括号。需要各select 查询的字段数量一样,即每个select 查询的字段列表(数量、类型)应一致,因为结果中的字段名以第一条select 语句为准。
--将多个select 查询的结果组合成一个结果集合
select ...union [ALL | DISTINCT] selelct ...
默认为distinct 方式,即所有返回的行都是唯一的。
2.2、子查询(需要用括号括起来)
a、from
from 后要求是一个表,必须给子查询结果取个别名,以简化每个查询内的条件。
--如:
select * from (select * from tb where id>0) as subfrom where id>1;
b、where
子查询返回一个值,不需要给子查询取别名
--如:
select * from tb where age =(select max(age) from tb)
c、列子查询
使用in 或 not in 子查询,查询结果返回单列
使用exists 和 not exists条件,返回1或0 ,常用于判断
--如:
select column1 from tb1 where exists (select * from tb2);
2.3、join 连接查询
将多个表的字段进行连接,可以指定连接条件。
a、内连接(inner join)
默认就是内连接,可省略inner。
只有数据存在时才能发送连接请求,即连接结果不能出现空行。
ON 表示连接条件,其条件表达式与 where 类似。
b、交叉连接(cross join)
没有条件的内连接。
--如:
select * from tb1 cross join tb2;
c、外连接(outer join)
如果数据不存在,也会出现在连接的结果中。
主要分为:左外连接和右外连接
左外连接(left outer join): 如果数据不存在,左表记录会出现,而右表以null 填充
右外连接(right outer join):如果数据不存在,右表记录会出现,而左表以null 填充
七、其他常用语句
1、CREATE INDEX
create index 用于在一个或多个列上创建索引
CREATE INDEX indexname ON tablename(column [ASC | DESC],·······)
2、CREATE PROCEDURE
create procedure 用于创建存储过程,常和delimiter一块用,parameters 表示参数列表
CREATE PROCEDURE procedure_name([parameters])BEGIN······END;
3、CREATE USER
create user 用于向系统中添加新的用户账号
CREATE USER user_name [@hostname] [IDENTIFIED BY [PASSWORD] 'password'];
4、CREATE VIEW
create view 用来创建一个或多个表上的新视图
CREATE [OR REPLACE] VIEWview_nameAS
select ··· ;
5、DROP
drop 永久地删除数据库对象(表、视图、索引、存储过程,触发器,用户等)
DROP DATABASE [TABLE | VIEW | INDEX | PROCEDURE | TRIGGER | USER] item_name;
6、事务
6.1、COMMIT
commit 用来将事务处理写到数据库
COMMIT ;
6.2、ROLLBACK
rollback 用于撤销一个事务处理块
ROLLBACK [TO savepoint_name];
6.3、SAVEPOINT
savepoint 为使用rollback 语句设立保留点
SAVEPOINT sql;
6.4、START TRANSACTION
start transaction 表示一个新的事务处理开始
START TRANSACTION;
Spring配置文件——applicationContext.xml)









mybatis配置文件——mybatis-config.xml)
)


——web.xml)

)


