1. 引言
向量检索已经成为现代搜索和推荐系统的核心组件。
通过将复杂的对象(例如文本、图像或声音)转换为数值向量,并在多维空间中进行相似性搜索,它能够实现高效的查询匹配和推荐。
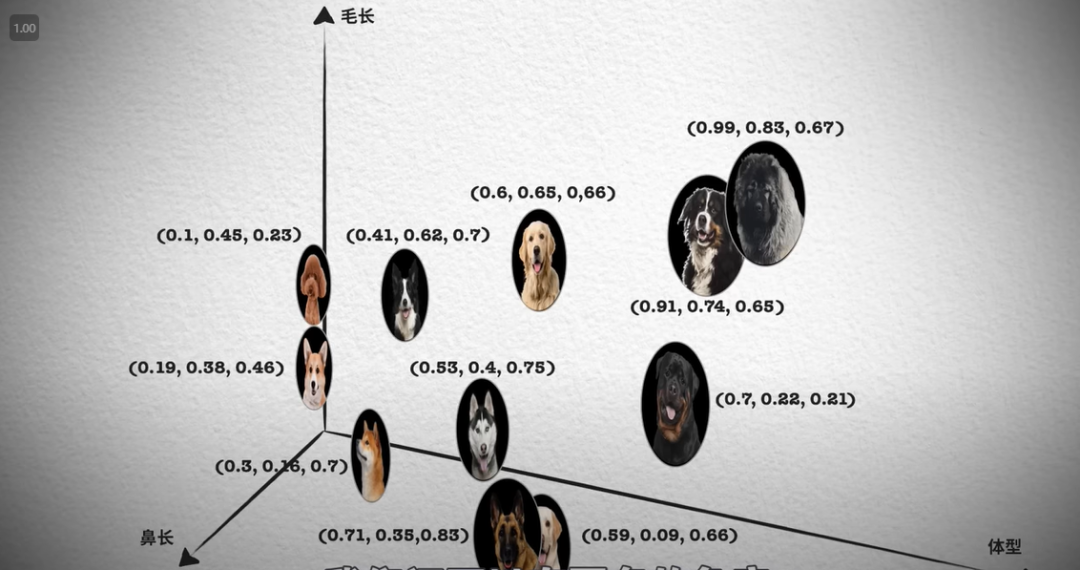
图片来自:向量数据库技术鉴赏【上集】(Ele实验室)
Elasticsearch作为一款流行的开源搜索引擎,其在向量检索方面的发展也一直备受关注。本文将回顾 Elasticsearch 向量检索的发展历史,重点介绍各个阶段的特点和进展。以史为鉴,方便大家建立起 Elasticsearch 向量检索的全量认知。
2. 初步尝试:简单向量检索的引入
Elasticsearch 最初并未专门针对向量检索进行设计。然而,随着机器学习和人工智能的兴起,对于高维向量空间的查询需求逐渐增长。
在Elasticsearch的 5.x 版本中,Elastic 爱好者们开始尝试通过插件和基本的数学运算实现简单的向量检索功能。如:一些早期的插件如 elasticsearch-vector-scoring、fast-elasticsearch-vector-scoring 就是为了满足这样的需求。
https://github.com/MLnick/elasticsearch-vector-scoring
https://github.com/lior-k/fast-elasticsearch-vector-scoring
这一阶段的向量检索主要用于基本的相似度查询,例如文本相似度计算。虽然功能相对有限,但为后续的发展奠定了基础。
扩展说明:关于机器学习功能,如果大家对 Elasticsearch 版本更迭感兴趣,印象中当时 6.X 版本推出,非常振奋人心。不过受限于非开源功能,国内的真实受众还相对较少。
3. 官方支持:进一步发展
到 Elasticsearch 7.0 版本,正式开始增加对向量字段的支持,例如通过 dense_vector 类型。这标志着Elasticsearch正式进入向量检索领域,不再只依赖于插件。
dense_vector 最早的发起时间:2018年12月13日,7.6 版本标记为 GA。
https://github.com/elastic/elasticsearch/pull/33022
https://github.com/elastic/elasticsearch-net/issues/3836
关于 dense_vector 类型的使用,推荐阅读:高维向量搜索:在 Elasticsearch 8.X 中利用 dense_vector 的实战探索。
这一阶段的主要挑战是如何有效地在传统的倒排索引结构中支持向量检索。通过与现有的全文搜索功能相结合,Elasticsearch能够提供一种灵活而强大的解决方案。
从最初的插件和基本运算,到后来的官方支持和集成,这一阶段为Elasticsearch在向量检索方面的进一步创新和优化奠定了坚实的基础。
4. 专门优化:增强的相似度计算
随着需求的增长,Elasticsearch 团队开始深入研究并优化向量检索性能。这涉及了引入更复杂的相似度计算方法,例如余弦相似度、欧几里得距离等,以及对查询执行的优化。
从 Elasticsearch 7.3 版本开始,官方引入了更复杂的相似度计算方法。特别是 script_score 查询的增强,使用户可以通过 Painless 脚本自定义更丰富的相似度计算。
https://www.elastic.co/guide/en/elasticsearch/reference/7.3/query-dsl-script-score-query.html#vector-functions
核心功能在于允许通过向量之间的夹角计算相似度,用 k 最近邻 (k-NN) 的余弦相似度距离指标,从而为相似度搜索引擎提供支持。广泛用于文本分析和推荐系统。
主要用于解决:复杂相似度需求,提供了更灵活和强大的相似度计算选项,能够满足更多的业务需求。
应用场景体现在:
(1)个性化推荐:通过余弦相似度分析用户的行为和兴趣,提供更个性化的推荐内容;
(2)图像识别和搜索:使用欧几里得距离快速检索与给定图像相似的图像;
(3)声音分析:在声音文件之间寻找相似模式,用于语音识别和分析。
值得一提的是:初始的时候,向量检索支持的维度为:1024,直到 Elasticsearch 8.8 版本,支持维度变更为:2048(这是呼声很高的一个需求)。
https://github.com/elastic/elasticsearch/pull/95257
https://discuss.elastic.co/t/vector-knn-search-with-more-than-1024-dimensions/332819
Elasticsearch 7.x 版本的增强相似度计算功能标志着向量检索能力的显著进展。通过引入更复杂的相似度计算方法和查询优化,Elasticsearch不仅增强了其在传统搜索场景中的功能,还为新兴的机器学习和AI应用打开了新的可能性。
但,这个时候你会发现,如果要实现复杂的向量搜索功能,自己实现的还很多。如果把后面马上提到的深度学习的集成和大模型的出现比作:飞行的汽车,当前的阶段还是“拉驴车”,功能是有的,但用起来很费劲。

5. 深度学习集成与未来展望
大模型时代,向量检索和多模态搜索成为“兵家”必争之地。
多模态检索是一种综合各种数据模态(如文本、图像、音频、视频等)的检索技术。换句话说,它不仅仅是根据文字进行搜索,还可以根据图像、声音或其他模态的输入来搜索相关内容。
为了更通俗地理解多模态检索,我们可以通过以下比喻和示例来加深认识:想象你走进一个巨大的图书馆,这里不仅有书籍,还有各种图片、录音和视频。你可以向图书馆员展示一张照片,她会为你找到与这张照片相关的所有书籍、音频和视频。或者,你可以哼一段旋律,图书馆员能找到相关的资料,或者提供类似的歌曲或视频。这就是多模态检索的魔力!
随着深度学习技术的不断发展和应用,Elasticsearch 已开始探索将深度学习模型直接集成到向量检索过程中。这不仅允许更复杂、更准确的相似度计算,还开辟了新的应用领域,例如基于图像或声音的搜索。尤其在Elasticsearch的 8.x 版本,这一方向得到了显著的推进。
5.1 向量化是前提
如下图所示,先从左往右看是写入,图像、文档、音频转化为向量特征表示,在 Elasticsearch 中通过 dense_vector 类型存储。
从右往左看是检索,先将检索语句转化为向量特征表示,然后借助 K 近邻检索算法(在 Elasticsearch 中借助 Knn search 实现),获取相似的结果。
看中间,Results 部分就是向量检索的结果。
综上,向量检索打破了传统倒排索引仅支持文本检索的缺陷,可以扩展支持文本、语音、图像、视频多种模态。
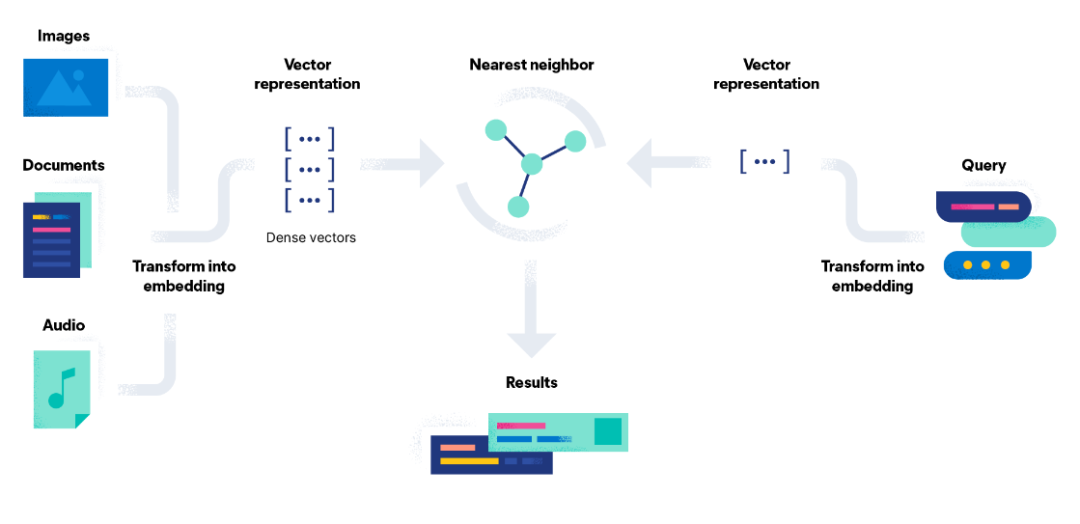
图片来自:Elasticsearch 官方文档
相信你到这里,应该理解了向量检索和多模态。没有向量化的这个过程,多模态检索无从谈起。
5.2 模型是核心
深度学习模型集成总共可分为三步:
第一步:模型导入和管理:Elasticsearch 8.x 支持导入预训练的深度学习模型,并提供相应的模型管理工具,方便模型的部署和更新。
第二步:向量表示与转换:通过深度学习模型,可以将非结构化数据如图像和声音转换为向量表示,从而进行有效的检索。
第三步:自定义相似度计算:8.x 版本提供了基于深度学习模型的自定义相似度计算接口,允许用户根据实际需求开发和部署专门的相似度计算方法。
关于深度学习,可以是自训练模型,也可以是第三方模型库中的模型,举例:咱们图搜图案例中就是用的 HuggingFace 里的:clip-ViT-B-32-multilingual-v1 模型。
Elasticsearch 支持的第三方模型列表:
| 名称 | 模型释义 |
|---|---|
| BERT | 双向Transformer模型 |
| BART | 序列到序列模型 |
| DPR bi-encoders | 双向编码器检索模型 |
| DistilBERT | 轻量化BERT |
| ELECTRA | 对抗性预训练模型 |
| MobileBERT | 针对移动设备的BERT |
| RoBERTa | 优化版BERT |
| RetriBERT | 检索-focused BERT |
| MPNet | 混合并行网络 |
| SentenceTransformers bi-encoders | 句子转换双向编码器 |
| XLM-RoBERTa | 多语言版RoBERTa |
包括如下的 Hugging Face 模型库也都是支持的。
 图片来自:HuggingFace 官方文档
图片来自:HuggingFace 官方文档 模型是Elasticsearch与深度学习集成的核心,它能将复杂的数据转化为“指纹”向量,使搜索更高效和智能。借助模型,Elasticsearch可以理解和匹配各种非结构化数据,如图像和声音,提供更为准确和个性化的搜索结果,同时适应不断变化的数据和需求。“没有了模型,我们还需要黑暗中摸索很久”。
第三方模型官网介绍:https://www.elastic.co/guide/en/machine-learning/8.9/ml-nlp-model-ref.html#ml-nlp-model-ref-text-embedding
值得一提的是:Elasticsearch 导入大模型需要专属 Python 客户端工具 Eland。
Eland是一个 Python Elasticsearch客户端,让用户能用类似Pandas的API来探索和分析Elasticsearch中的数据,还支持从常见机器学习库上传训练好的模型到Elasticsearch。
Eland是为了与Elasticsearch协同工作而开发的库。它不是Elasticsearch的一个特定版本产物,而是作为一个独立的项目来帮助Python开发者更方便地在Elasticsearch中进行数据探索和机器学习任务。
Eland 更多参见:
https://www.elastic.co/guide/en/elasticsearch/client/eland/current/index.html
https://github.com/elastic/eland
5.3 ESRE 是 Elastic 的未来
前一段时间在分别给两位阿里云、腾讯云大佬聊天的时候,都提到了 Elasticsearch Relevance Engine (ESRE) 才是 Elastic 未来。
ESRE 官方介绍如下:——Elasticsearch Relevance Engine 将 AI 的最佳实践与 Elastic 的文本搜索进行了结合。ESRE 为开发人员提供了一整套成熟的检索算法,并能够与大型语言模型 (LLM) 集成。借助ESRE,我们可以应用具有卓越相关性的开箱即用型语义搜索,与外部大型语言模型集成,实现混合搜索,并使用第三方或我们自己的模型。
ESRE 集成了高级相关性排序如 BM25f、强大的矢量数据库、自然语言处理技术、与第三方模型如 GPT-3 和 GPT-4 的集成,并支持开发者自定义模型与应用。其特点在于提供深度的语义搜索,与专业领域的数据整合,以及无缝的生成式 AI 整合,让开发者能够构建更吸引人、更准确的搜索体验。
在 Elasticsearch 8.9 版本上新了:Semantic search 语义检索功能,对官方文档熟悉的同学,你会发现如下截图内容,早期版本是没有的。
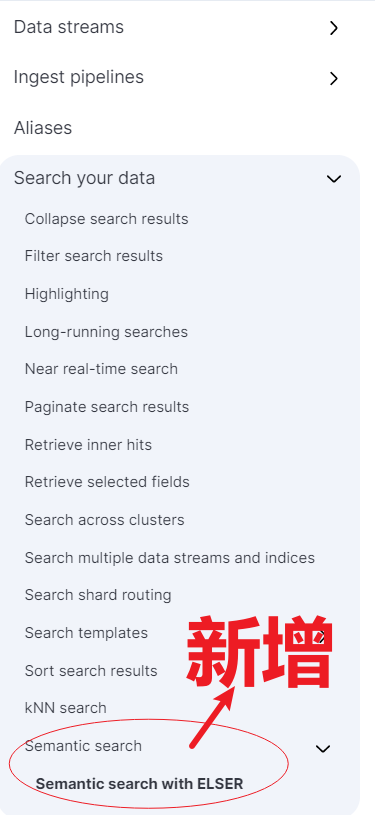
https://www.elastic.co/guide/en/elasticsearch/reference/8.9/semantic-search.html
语义搜索不是根据搜索词进行字面匹配,而是根据搜索查询的意图和上下文含义来检索结果。
更进一步讲:语义搜索不仅仅是匹配你输入的关键字,而是试图理解你的真正意图,给你带来更准确、更有上下文的搜索结果。简单来说,如果你在英国搜索“football”,系统知道你可能想要搜橄榄球,而不是足球(在美国 football 是足球)。
这种智能搜索方式,得益于强大的文本向量化等技术背景,使我们的在线搜索体验更加直观、方便和满意。
为了更清楚的解释由向量检索实现的文本检索——语义检索,这里给个动画演示一下。
动画来自:Elasticsearch 官方文档
视频刚开始,在文本里检索 connection speed requirement, 这点属于早期的倒排索引检索方式,或者叫全文检索中的短语 match_phrase 检索匹配 或者分词 match 检索匹配。这种可以得到结果。
但是,中后半段视频显示,要是咱们要检索:“How fast should my internet be” 怎么办?
其实这里转换为向量检索,fast 和 speed 语义相近,should be 和 required、needs 语义相近,internet 和 connection、wifi 语义相近。所以依然能召回结果。
这突破了传统同义词的限制,体现了语义检索的妙处!
更进一步,我们给出语义检索和传统分词检索的区别,以期望大家更好的理解语义搜索。
| 项目 | 语义搜索 | 传统分词搜索 |
|---|---|---|
| 核心技术 | 基于矢量搜索,机器学习和人工智能 | 基于文本匹配和查询扩展 |
| 搜索目的 | 理解查询的深层意义和上下文 | 直接匹配关键词或扩展的词汇 |
| 处理上下文 | 能够根据搜索者的地理位置、搜索历史等信息调整结果 | 通常不考虑这些额外的上下文信息 |
| 搜索结果的相关性 | 根据查询的意图和上下文排名结果 | 主要基于关键词的频率和位置匹配 |
| 处理同义词和多义词 | 能够理解词语在不同上下文中的意义,并据此返回结果 | 通常使用同义词表或词汇扩展工具,可能不总是理解上下文中的真正意义 |
| 对查询的理解 | 能够区分如“chocolate milk”和“milk chocolate”这样的查询,即使关键词顺序或形式相同 | 可能只是简单地匹配关键词,而不理解它们的真正意思 |
| 学习和适应能力 | 通过机器学习不断改进,根据用户的反馈和行为适应 | 通常基于固定的算法和规则,没有持续学习和适应的能力 |
| 用户体验 | 提供更准确和有上下文的结果,从而提高用户满意度 | 依赖于用户精确输入,可能返回与用户实际意图不匹配的结果 |
总体而言,深度学习集成已经成为Elasticsearch向量检索能力的有力补充,促使它在搜索和分析领域的地位更加牢固,同时也为未来的发展提供了广阔的空间。
6.小结
Elasticsearch 的向量检索从最初的简单实现发展到现在的高效、多功能解决方案,反映了现代搜索和推荐系统的需求和挑战。随着技术的不断演进,我们可以期待Elasticsearch在向量检索方面将继续推动创新和卓越。
说一下最近的感触,向量检索、大模型等新技术的出现有种感觉“学不完,根本学不完”,并且很容易限于“皮毛论”(我自创的词)——所有技术都了解一点点,但经不起提问;浅了说,貌似啥都懂,深了说,一问三不知。
这种情况怎么办?我目前的方法是:以实践为目的去深入理解理论,必要时理解算法,然后不定期将所看、所思、所想梳理成文,以备忘和知识体系化。这个过程很慢、很累,但我相信时间越长、价值越大。
欢迎大家就向量检索等问题进行留言讨论交流,你的问题很可能就是下一次文章的主题哦!
7、参考
1、https://www.elastic.co/cn/blog/text-similarity-search-with-vectors-in-elasticsearch
2、https://www.elastic.co/guide/en/elasticsearch/reference/7.3/query-dsl-script-score-query.html#vector-functions-cosine
3、https://zhuanlan.zhihu.com/p/552249981
4、https://www.elastic.co/cn/what-is/elasticsearch-machine-learning
5、https://www.elastic.co/cn/enterprise-search/generative-ai
6、https://www.elastic.co/cn/blog/may-2023-launch-announcement
7、https://www.analyticsvidhya.com/blog/2022/10/most-frequently-asked-interview-questions-on-knn-algorithm/
8、https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html
9、https://www.elastic.co/cn/blog/how-to-deploy-nlp-text-embeddings-and-vector-search
10、https://www.elastic.co/cn/blog/privacy-first-ai-search-langchain-elasticsearch
11、https://www.youtube.com/watch?v=W_ZUUDJsUtA
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
2023,做点事
视频 | Elasticsearch 8.X 企业内训之最佳实践10 讲
Elasticsearch 8.X “图搜图”实战
高维向量搜索:在 Elasticsearch 8.X 中利用 dense_vector 的实战探索

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

大模型时代,抢先一步学习进阶干货!

![[oeasy]python0081_[趣味拓展]ESC键进化历史_键盘演化过程_ANSI_控制序列_转义序列_CSI](http://pic.xiahunao.cn/[oeasy]python0081_[趣味拓展]ESC键进化历史_键盘演化过程_ANSI_控制序列_转义序列_CSI)







)




 队列操作详解及栈与队列的相互实现)




)