文章开篇问一个问题吧,一个java程序,如果其中一个线程发生了OOM,那进程中的其他线程还能运行吗?
接下来做实验,看看JVM的六种OOM之后程序还能不能访问。
在这里我用的是一个springboot程序。
/*** @author :charon* @date :Created in 2021/5/17 8:30* @description : 程序启动类* @version: 1.0*/
@SpringBootApplication
public class CharonApplication {public static void main(String[] args) {SpringApplication.run(CharonApplication.class, args);}}监测服务是否可用(http://localhost:8080/checkHealth 测试服务正常可用):
/*** @author :charon* @date :Created in 2021/5/17 8:49* @description : 测试服务是否可用* @version: 1.0*/
@RestController
public class CheckHealthController {@RequestMapping("/checkHealth")public String stackOverFlowError(){System.out.println("调用服务监测接口-----------------------");return "服务监测接口返回";}
}1.StackOverflowError(栈溢出)
栈溢出代表的是:当栈的深度超过虚拟机分配给线程的栈大小时就会出现error。
/*** @author :charon* @date :Created in 2021/5/17 8:49* @description : 测试java.lang.StackOverflowError: null的错误* @version: 1.0*/
@RestController
public class StackOverFlowErrorController {/*** 递归调用一个方法,使其超过栈的最大深度*/@RequestMapping("/stackOverFlowError")public void stackOverFlowError(){stackOverFlowError();}
}使用浏览器调用栈溢出的接口(localhost:8080/stackOverFlowError),发现后台报了栈溢出的错误。
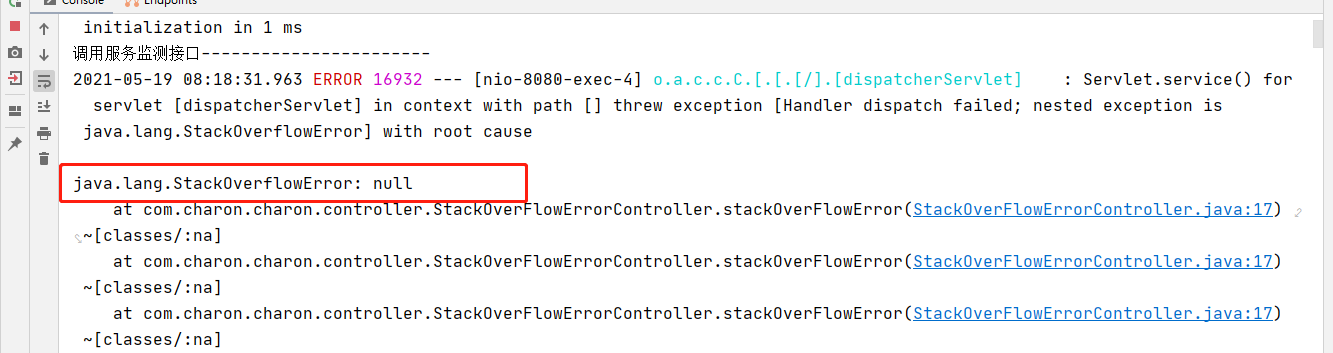
调用监测程序可用的接口,发现还是可以正常访问。

2.Java heap space(堆内存溢出)
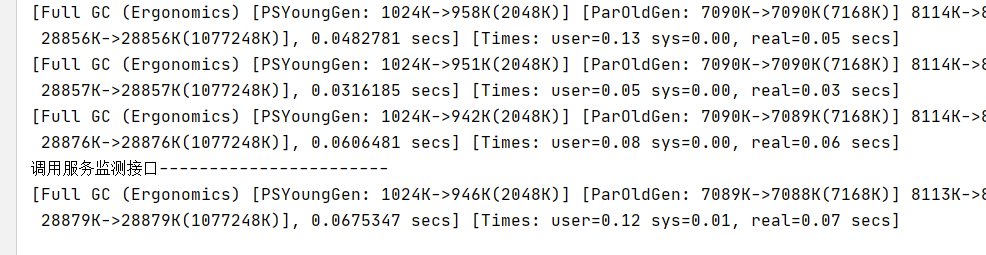
当GC多次的时候新生代和老生代的堆内存几乎用满了,频繁触发Full GC (Ergonomics) ,直到没有内存空间给新生对象了。所以JVM抛出了内存溢出错误!进而导致程序崩溃。
设置虚拟机参数(-Xms10m -Xmx10m -XX:+PrintGCDetails),如果不设置的话,可能会执行很久。
@RestController
public class JavaHeapSpaceController {/*** 使用是循环创建对象,是堆内存溢出*/@RequestMapping("/javaHeapSpace")public void javaHeapSpace(){String str = "hello world";while (true){str += new Random().nextInt(1111111111) + new Random().nextInt(222222222);/*** intern()方法:* (1)当常量池中不存在这个字符串的引用,将这个对象的引用加入常量池,返回这个对象的引用。* (2)当常量池中存在这个字符串的引用,返回这个对象的引用;*/str.intern();}}
}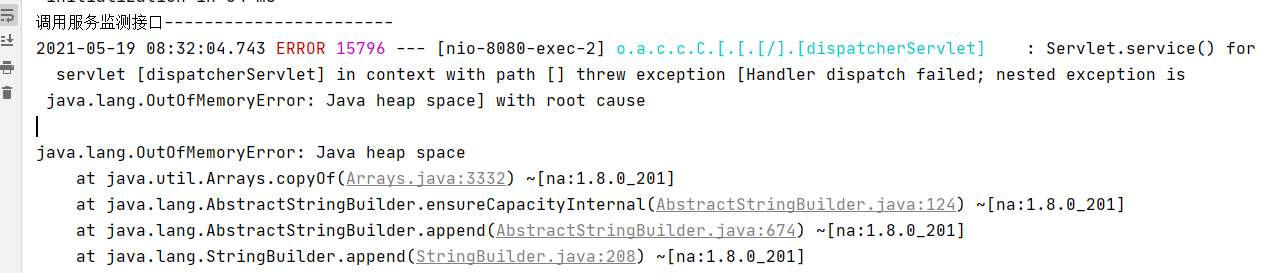
调用监测程序可用的接口,发现还是可以正常访问。
3.direct buffer memory
在写IO程序(如Netty)的时候,经常使用ByteBuffer来读取或者写入数据,这是一种基于通道(channel)和缓冲区(Buffer)的IO方式,他可以使用Native函数库直接分配对外内存,然后通过一个存储在java堆里面的DirectByteBuffer对象作为这块内存的引用操作,这样能在在一些场景中显著提高性能,因为避免了再java堆和Native堆中来回复制数据。
ByteBuffer.allocate(capacity) 这种方式是分配jvm堆内存,属于GC管辖的范围,由于需要拷贝所以速度较慢
ByteBuffer.allocateDirect(capacity) 这种方式是分配本地内存,不属于GC的管辖范围,由于不需要内存拷贝,所以速度较快
但是如果不断分配本地内存,堆内存很少使用,那么JVM就不需要执行GC,DirectByteBuffer对象就不会回收,
这时候堆内存充足,但本地内存可能已经使用光了,再次尝试分配本地内存,就会出现OutOfMemoryError
设置JVM参数: -Xms10m -Xmx10m -XX:+PrintGCDetails -XX:MaxDirectMemorySize=5m
@RestController
public class DirectBufferMemoryController {@RequestMapping("/directBufferMemory")public void directBufferMemory(){System.out.println("初始配置的最大本地内存为:"+ (sun.misc.VM.maxDirectMemory()/1024/1024)+"MB");// 在jvm参数里设置的最大内存为5M,ByteBuffer buffer = ByteBuffer.allocateDirect(6*1024*1024);}}访问内存溢出的接口(http://localhost:8080/directBufferMemory),报错之后再次访问服务监测接口,发现还是可以继续访问的。
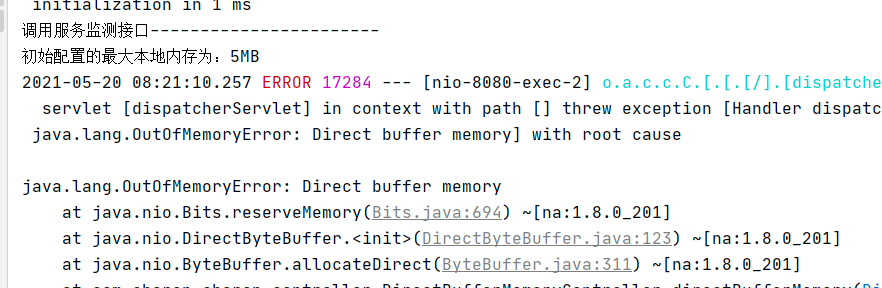
4.GC overhead limit exceeded
GC回收之间过长会抛出这个错,过长的定义是:超过98%的时间用来做垃圾回收并且只回收了不到2%的堆内存,连续多次GC都只回收了不到2%的极端情况下才会抛出,加入不抛出GC overhead limit错误,就会发生下列情况:
- GC清理的这么点内存很快就会再次被填满,形成恶性循环
- CPU使用率一直是100%,而GC没有任何效果
设置JVM参数: -Xms10m -Xmx10m -XX:+PrintGCDetails -XX:MaxDirectMemorySize=5m
@RestController
public class GcOverHeadController {@RequestMapping("/gcOverHead")public void gcOverHead(){int i = 0;List<String> list = new ArrayList<>();try{while(true){list.add(String.valueOf(++i).intern());}}catch(Throwable e){System.out.println("i的值为:" + i);e.printStackTrace();throw e;}}
}如下图所示,在报错这个异常之前,在频繁的Full GC,但是垃圾回收前后,新生代和老年代的内存差不多,就说明,垃圾回收效果不大。
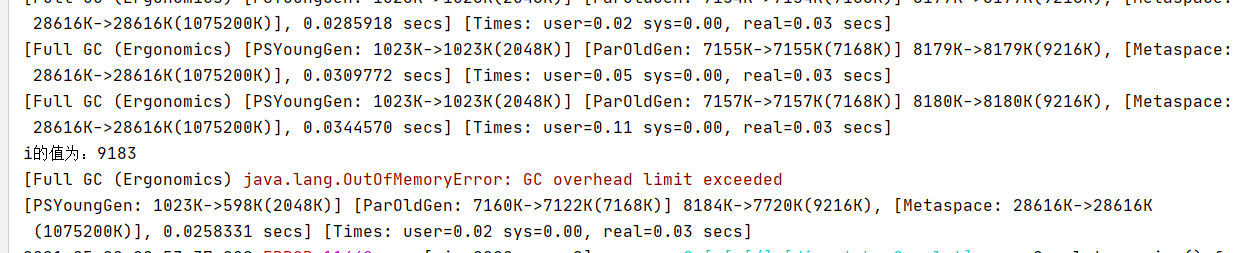
再次访问服务监测接口,发现还是可以继续访问的。
5.Metaspace
java 8及其以后的版本中使用了MetaSpace代替了永久代,它与永久代最大的区别在于:
MetaSpace并不在虚拟机内存中,而是使用本地内存,也就是说,在java8中,Class metadata被存储在MetaSpace的native Memory中
MetaSpace中存储了一下信息:
- 虚拟机加载的类信息
- 常量池
- 静态变量
- 即时编译后的代码
参数设置:-XX:+PrintGCDetails -XX:MetaspaceSize=50m -XX:MaxMetaspaceSize=50m
@RestController
public class MetaSpaceController {static class OomTest{}/*** 模拟MetaSpace溢出,不断生成类往元空间放,类占据的空间会超过MetaSpace指定的大小*/@RequestMapping("/metaSpace")public void metaSpace(){int i = 0;try{while (true){i++;/*** Enhancer允许为非接口类型创建一个java代理。Enhancer动态创建了给定类型的子类但是拦截了所有的方法,* 和proxy不一样的是:不管是接口还是类它都能正常工作。*/Enhancer enhancer = new Enhancer();enhancer.setSuperclass(OomTest.class);enhancer.setUseCache(false);enhancer.setCallback(new MethodInterceptor() {@Overridepublic Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {return methodProxy.invokeSuper(o,objects);}});enhancer.create();}}catch (Throwable e){System.out.println("i的值为:" + i);e.printStackTrace();}}
}我记得之前看过一篇公众号的文章,就是使用Fastjson创建的代理类导致的Metaspace的问题,具体地址我也忘记了。。。。。
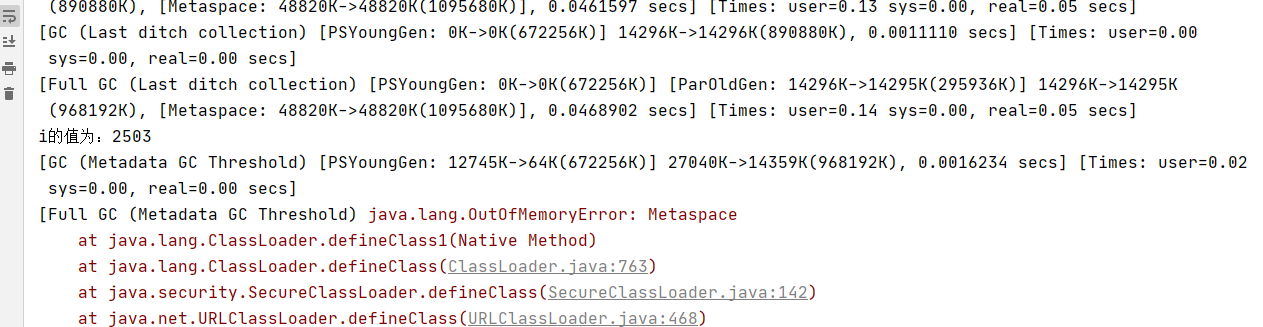
再次访问服务监测接口,发现还是可以继续访问的。
6.unable to create new thread
在高并发服务时,经常会出现如下错误,
导致原因:
- 1.应用程序创建了太多的线程,一个应用进程创建的线程超过了系统承载极限
- 2.服务器不允许应用程序创建这么多线程,linux系统默认允许单个进程可以创建的线程数为1024个(如果是普通用户小于这个值)
解决办法:
- 1.降低应用程序创建线程的数量,分析应用是否真的需要创建这么多线程
- 2.对于有的应用确实需要创建这么多的线程,可以修改linux服务器配置,扩大linux的默认限制
查看:ulimit -u
修改:vim /etc/security/limits.d/90-nproc.conf
@RestController
public class UnableCreateThreadController {/*** 友情提示:千万别在windows中运行这段代码,如果不小心和我一样试了,那就只能强制重启了*/@RequestMapping("/unableCreateThread")public void unableCreateThread(){for (int i = 0; ; i++) {System.out.println("i的值为:" + i);new Thread(()->{try{Thread.sleep(1000*1000);} catch (InterruptedException e){e.printStackTrace();}}).start();}}
}我这里是使用的root用户测试的,创建了7409个线程。大家测试的时候最好是使用普通用户测试。
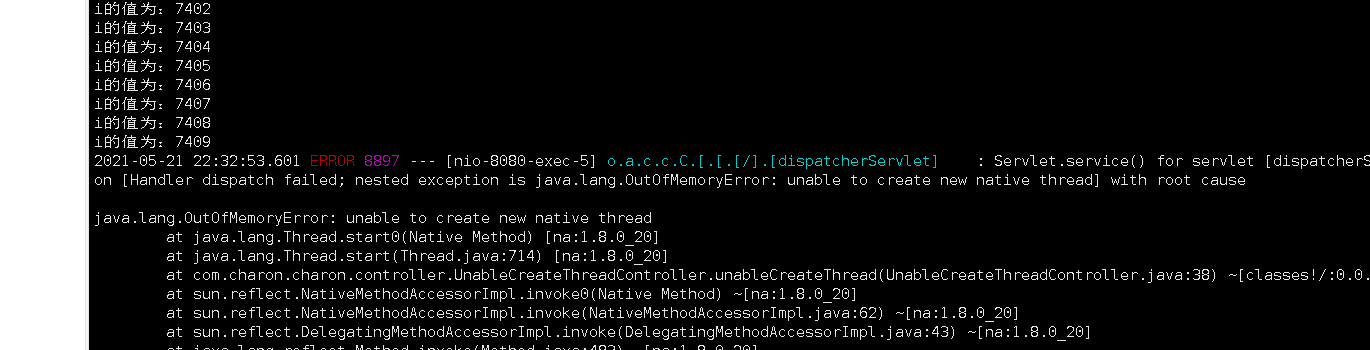
最后执行检测服务的接口,发现程序还是可以继续访问的。
小结
其实发生OOM的线程一般情况下会死亡,也就是会被终结掉,该线程持有的对象占用的heap都会被gc了,释放内存。因为发生OOM之前要进行gc,就算其他线程能够正常工作,也会因为频繁gc产生较大的影响。




![[转]IIS的完整控制类](http://pic.xiahunao.cn/[转]IIS的完整控制类)














