数据质量一直是数据仓库领域一个比较令人头疼的问题,因为数据仓库上层对接很多业务系统,业务系统的脏数据,业务系统变更,都会直接影响数据仓库的数据质量。因此数据仓库的数据质量建设是一些公司的重点工作。
一、数据质量
数据质量的高低代表了该数据满足数据消费者期望的程度,这种程度基于他们对数据的使用预期。数据质量必须是可测量的,把测量的结果转化为可以理解的和可重复的数字,使我们能够在不同对象之间和跨越不同时间进行比较。数据质量管理是通过计划、实施和控制活动,运用质量管理技术度量、评估、改进和保证数据的恰当使用。
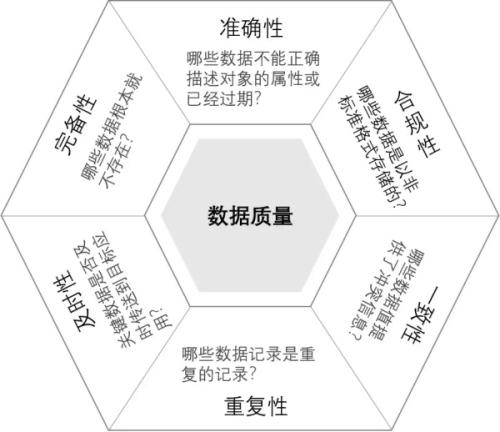
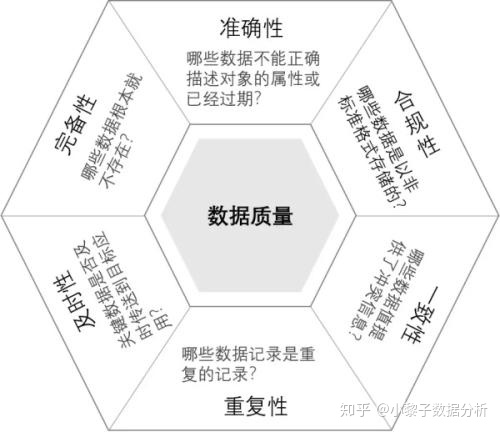
二、数据质量维度
1、准确性:数据不正确或描述对象过期
2、合规性:数据是否以非标准格式存储
3、完备性:数据不存在
4、及时性:关键数据是否能够及时传递到目标位置
5、一致性:数据冲突
6、重复性:记录了重复数据
三、数据质量分析
数据质量分析的主要任务就是检查数据中是否存在脏数据,脏数据一般是指不符合要求以及不能直接进行相关分析的数据。脏数据包括以下内容:
1、缺省值
2、异常值
3、不一致的值
4、重复数据以及含有特殊符号(如#、¥、*)的数据
我们已经知道了脏数据有4个方面的内容,接下来我们逐一来看这些数据的产生原因,影响以及解决办法。
第一、 缺省值分析
产生原因:
1、有些信息暂时无法获取,或者获取信息的代价太大
2、有些信息是被遗漏的,人为或者信息采集机器故障
3、属性值不存在,比如一个未婚者配偶的姓名、一个儿童的固定收入
影响:
1、会丢失大量的有用信息
2、数据额挖掘模型表现出的不确定性更加显著,模型中蕴含的规律更加难以把握
3、包含空值的数据会使得建模过程陷入混乱,导致不可靠输出
解决办法:
通过简单的统计分析,可以得到含有缺失值的属性个数,以及每个属性的未缺失数、缺失数和缺失率。删除含有缺失值的记录、对可能值进行插补和不处理三种情况。
第二、 异常值分析
产生原因:业务系统检查不充分,导致异常数据输入数据库
影响:不对异常值进行处理会导致整个分析过程的结果出现很大偏差
解决办法:可以先对变量做一个描述性统计,进而查看哪些数据是不合理的。最常用的统计量是最大值和最小值,用力啊判断这个变量是否超出了合理的范围。如果数据是符合正态分布,在原则下,异常值被定义为一组测定值中与平均值的偏差超过3倍标准差的值,如果不符合正态分布,也可以用原理平均值的多少倍标准差来描述。
第三、 不一致值分析
产生原因:不一致的数据产生主要发生在数据集成过程中,这可能是由于被挖掘的数据是来自不同的数据源、对于重复性存放的数据未能进行一致性更新造成。例如,两张表中都存储了用户的电话号码,但在用户的号码发生改变时只更新了一张表中的数据,那么两张表中就有了不一致的数据。
影响:直接对不一致的数据进行数据挖掘,可能会产生与实际相悖的数据挖掘结果。
解决办法:注意数据抽取的规则,对于业务系统数据变动的控制应该保证数据仓库中数据抽取最新数据
第四、 重复数据及特殊数据产生原因:
产生原因:业务系统中未进行检查,用户在录入数据时多次保存。或者因为年度数据清理导致。特殊字符主要在输入时携带进入数据库系统。
影响:统计结果不准确,造成数据仓库中无法统计数据
解决办法:在ETL过程中过滤这一部分数据,特殊数据进行数据转换。
四、数据质量管理
大多数企业都没有一个很好的数据质量管理的机制,因为他们不理解其数据的价值,并且他们不认为数据是一个组织的资产,而把数据看作创建它的部门领域内的东西。缺乏数据质量管理将导致脏数据、冗余数据、不一致数据、无法整合、性能低下、可用性差、责任缺失、使用系统用户日益不满意IT的性能。
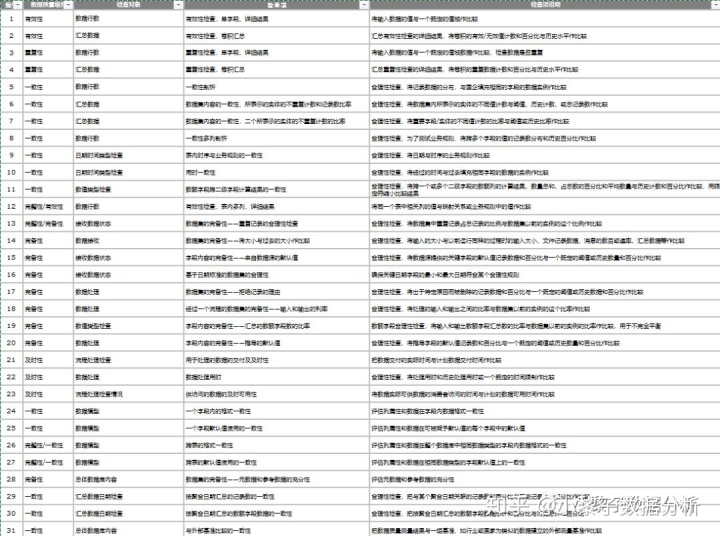
在做数据分析之前一般都应该初步对数据进行评估。初步数据评估通过数据报告来完成的,数据报告通常在准备把数据存入数据仓库时做一次,它是全面跨数据集的,它描述了数据结构、内容、规则、和关系的概况。通过应用统计方法返回一组关于数据的标准特征,包括数据类型、字段长度、列基数、粒度、值域、格式模式、隐含的规则、跨列和跨表的数据关系,以及这些关系的基数。初步评估报告的目的是获得对数据和环境的了解,并对数据的状况进行描述。数据报告应该如下:







)
)









)

