表的约束
表的约束——为了让插入的数据符合预期。
表的约束很多,这里主要介绍如下几个: null/not null,default, comment, zerofill,primary key,auto_increment,unique key 。
空属性
两个值:null(默认的)和not null(不为空)
数据库默认字段基本都是字段为空,但是实际开发时,尽可能保证字段不为空,因为数据为空没办 法参与运算。
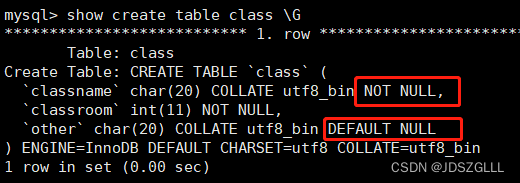
默认约束:default null
默认值
默认值:某一种数据会经常性的出现某个具体的值,可以在一开始就指定好,在需要真实数据的时候, 用户可以选择性的使用默认值。

列描述
列描述:comment,没有实际含义,专门用来描述字段,会根据表创建语句保存,用来给程序员或DBA 来进行了解。
zerofill
zerofill是一种数据库的格式化显示的约束。

int默认为11,int unsigned默认为10

超过设置的长度就按正常显示,否则补0;
主键和唯一键约束
主键:primary key用来唯一的约束该字段里面的数据,不能重复,不能为空,一张表中最多只能有一个 主键;主键所在的列通常是整数类型。
一张表中有往往有很多字段需要唯一性,数据不能重复,但是一张表中只能有一个主键:唯一键就可以 解决表中有多个字段需要唯一性约束的问题。
唯一键的本质和主键差不多,唯一键允许为空,而且可以多个为空,空字段不做唯一性比较。

主键和唯一键都不能重复,主键不能为空。
主键也可以是多个:复合主键
mysql> create table tt14(
-> id int unsigned,
-> course char(10) comment '课程代码',
-> score tinyint unsigned default 60 comment '成绩',
-> primary key(id, course) -- id和course为复合主键
-> );
Query OK, 0 rows affected (0.01 sec)
自增长
auto_increment:当对应的字段,不给值,会自动的被系统触发,系统会从当前字段中已经有的最大值 +1操作,得到一个新的不同的值。通常和主键搭配使用,作为逻辑主键。
自增长的特点:
任何一个字段要做自增长,前提是本身是一个索引(key一栏有值)
自增长字段必须是整数
一张表最多只能有一个自增长
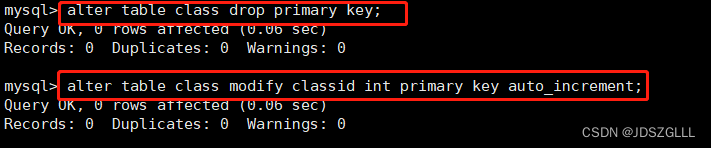
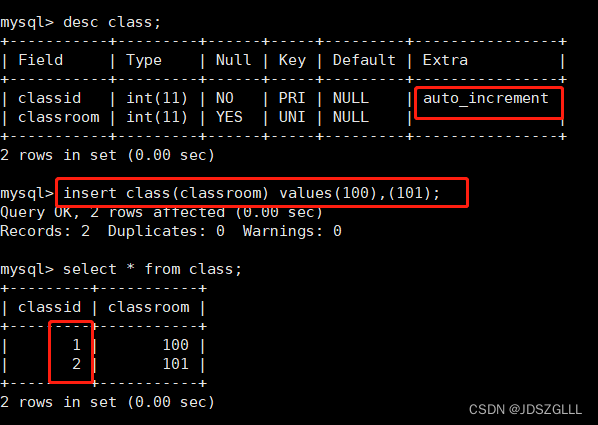
添加主键:alter table 表名 add primary key(列名);
外键
外键用于定义主表和从表之间的关系:外键约束主要定义在从表上,主表则必须是有主键约束或unique 约束。当定义外键后,要求外键列数据必须在主表的主键列存在或为null。
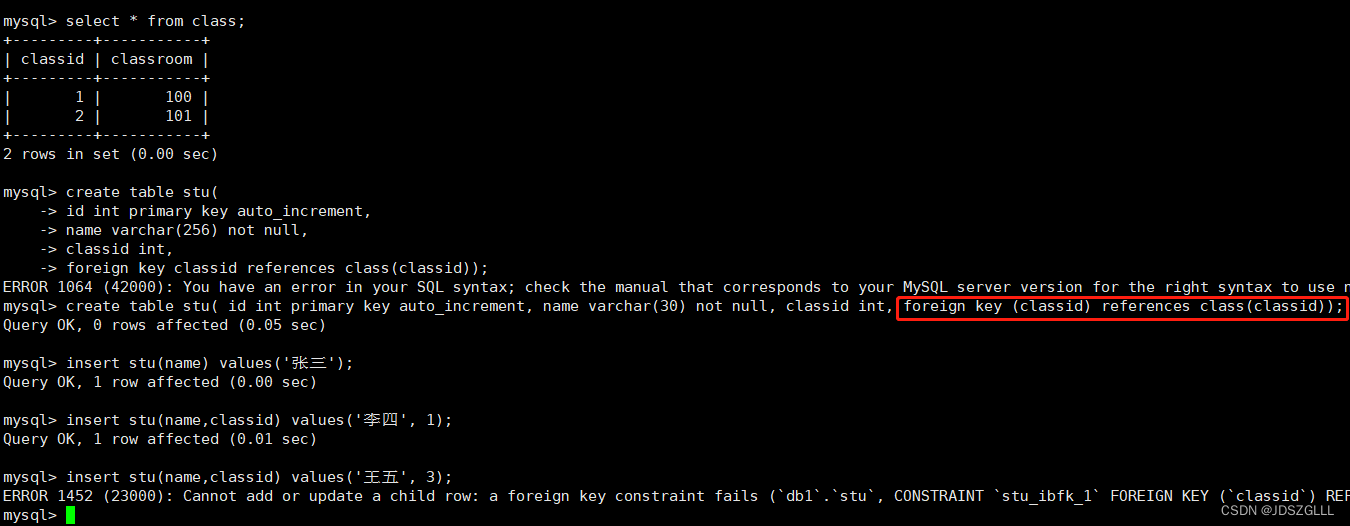

其中class为主表,stu为从表。
基础查询
修改记录
update 表名 set 列名=__ where_______
删除记录
delete from 表名 where___
主键 或者 唯一键冲突时更新
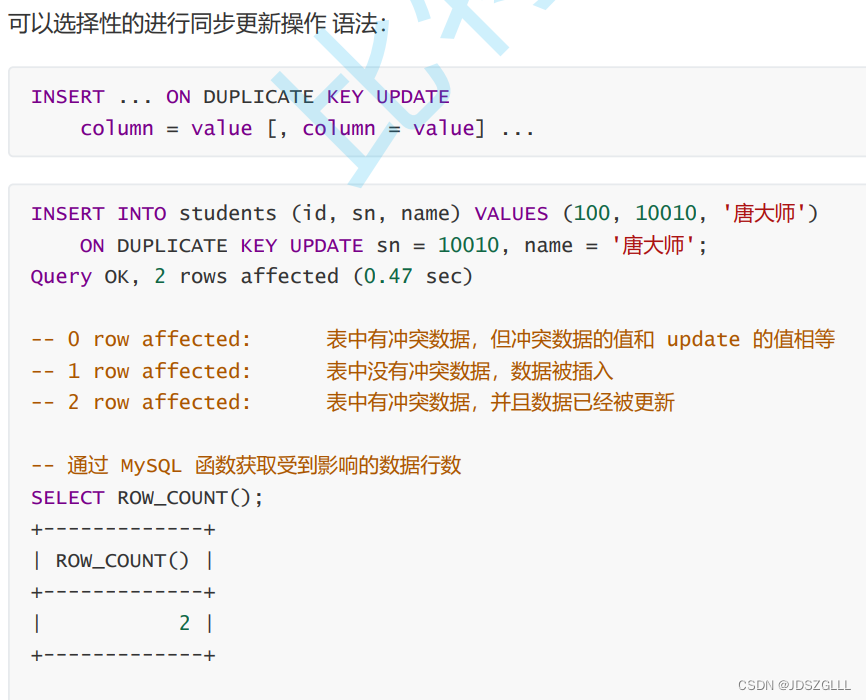
替换
replace 和insert语法完全一样,只是会在冲突时把老数据替换掉。

select指定列查询
查询结果去重:
select distinct _______
查询结果为表达式且有别名:
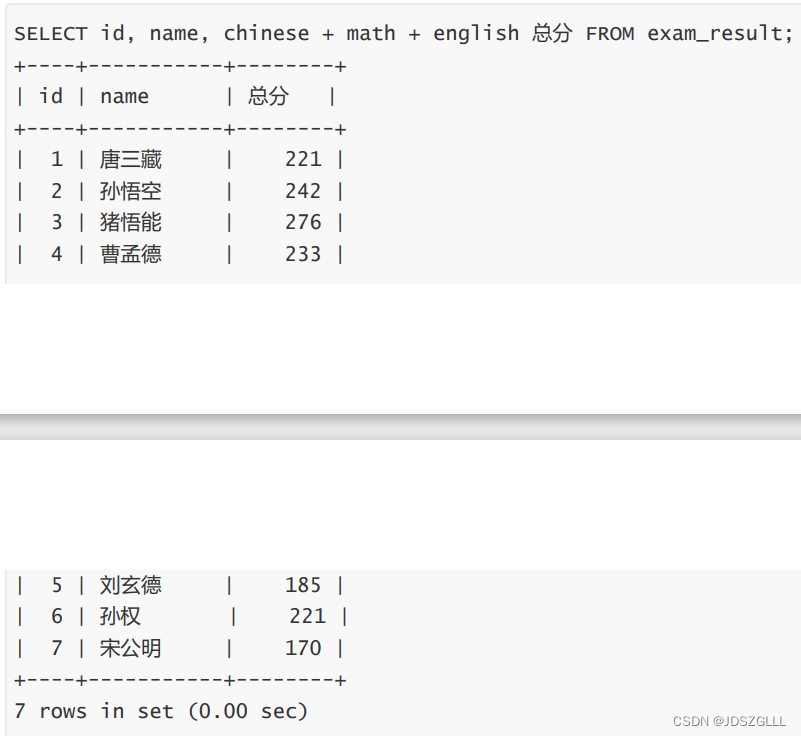
where
比较运算符

NULL值无法用来比较
where math=98 or math=99 等于 where math in(98,99)

模糊匹配:


order by
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
多字段排序,排序优先级随书写顺序
order by math desc, english asc, chinese asc;
limit

update
UPDATE table_name SET column = expr [, column = expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]
将孙悟空同学的数学成绩变更为 80 分
UPDATE exam_result SET math = 80 WHERE name = '孙悟空';
Delete
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
truncate
TRUNCATE [TABLE] table_name
truncate会重置auto_increment,且这个操作不会被记录在日志。
表格去重
-- 创建一张空表 no_duplicate_table,结构和 duplicate_table 一样
CREATE TABLE no_duplicate_table LIKE duplicate_table;
Query OK, 0 rows affected (0.00 sec)
-- 将 duplicate_table 的去重数据插入到 no_duplicate_table
INSERT INTO no_duplicate_table SELECT DISTINCT * FROM duplicate_table;
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
-- 通过重命名表,实现原子的去重操作
RENAME TABLE duplicate_table TO old_duplicate_table, no_duplicate_table TO duplicate_table;
Query OK, 0 rows affected (0.00 sec)
-- 查看最终结果
SELECT * FROM duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 200 | bbb |
| 300 | ccc |
+------+------+
3 rows in set (0.00 sec)
聚合函数
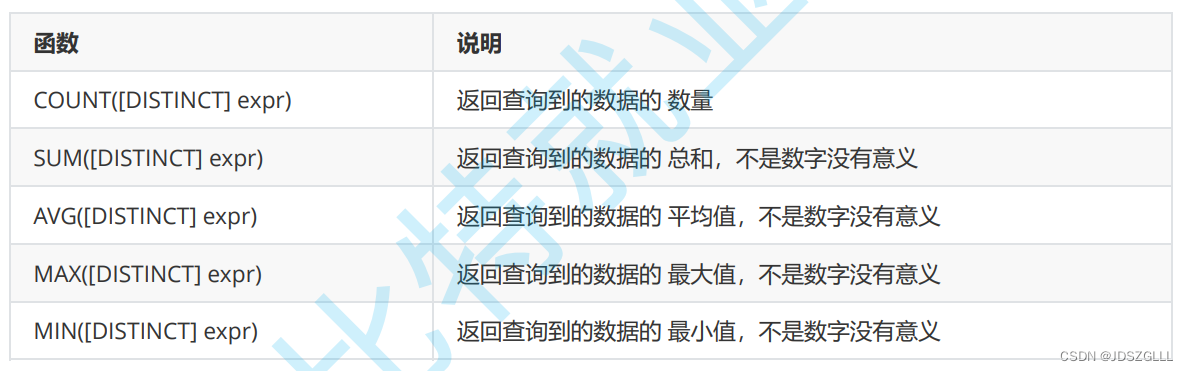
group by
在select中使用group by 子句可以对指定列进行分组查
select column1, column2, .. from table group by column;
having
having和group by配合使用,对group by结果进行过滤
SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select > distinct > order by > limit




——探寻平衡点)





十四)





线程快照生成工具 jstack:帮助开发人员分析和排查线程相关问题(死锁、死循环、线程阻塞...))


