------------ 斐波那契 数列 ---------------
【1,1,2,3,5,8,13,21,34,...】
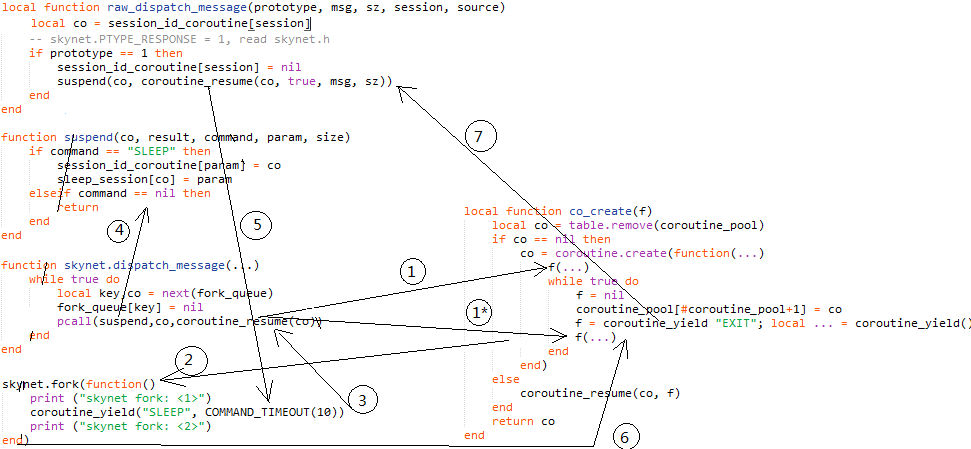
1 列表方法实现
# l=[1,1]
#
# # while len(l)<=20:
# # l.append(l[-1]+l[-2])
# # print(l)
#
# while len(l)!=4:
# l.append(l[-1]+l[-2])
# print(l)
#
2 迭代实现
# n=10
#
# n1 = 1
# n2 = 1
# n3 = 1
#
# if n<=2:
# re=1
# print(re)
# if n>2:
# m=1
# while m <= n-2:
# n3 = n1 + n2
# n1 = n2
# n2 = n3
# m+= 1
# re=n3
#
# print(re)
-------- eval() -------- 把字符串 强转 为实际的数据------------
eval('print(123)')
eval('func')()
eval 存在安全隐患---->> 会把其他关键字识别---使用
--------------- 类递归思想 列表---栈 进出思想---------------
附加题
# # 有⼀个数据结构如下所⽰,请编写⼀个函数从该结构数据中返回由指定的字段和对应的值组成的字
# # 典。如果指定字段不存在,则跳过该字段。(10分)
#
data={"time":"2016-08-05T13:13:05",
"some_id":"ID1234",
"grp1":{ "fld1":1,
"fld2":2},
"xxx2":{ "fld3":0,
"fld5":0.4},
"fld6":11,
"fld7":7,
"fld46":8}
# fields:由"|"连接的以"fld"开头的字符串,如:fld2|fld3|fld7|fld19
fields='fld2|fld3|fld7'
fields_list=fields.split('|')my_dict={}
data_list=[1]while data!=1:for key in data:if key in fields_list:my_dict[key]=data[key]if type(data[key])==dict:data_list.append(data[key]) # 如果有的话一直 添加data=data_list.pop() # 取出最后一个
print(my_dict)



![bzoj3122 [Sdoi2013]随机数生成器(bsgs+扩欧+数列)](https://img-blog.csdn.net/20170913183306298?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvd3VfdG9uZ3Rvbmc=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)