Transformer学习笔记
- 前言
- 前提条件
- 相关介绍
- Transformer
- 总体架构
- 编码器(Encoder)
- 位置编码(Positional Encoding)
- get_attn_pad_mask函数(Padding Mask)
- EncoderLayer
- MultiHeadAttention
- ScaledDotProductAttention
- PoswiseFeedForwardNet
- 解码器(Decoder)
- 位置编码(Positional Encoding)
- get_attn_subsequent_mask函数(Sequence Mask)
- 完整代码
- 参考
前言
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏或我的个人主页查看
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- 基于DETR的人脸伪装检测
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- YOLOv5:TensorRT加速YOLOv5模型推理
前提条件
- 熟悉Python
相关介绍
- Python是一种跨平台的计算机程序设计语言。是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
- PyTorch 是一个深度学习框架,封装好了很多网络和深度学习相关的工具方便我们调用,而不用我们一个个去单独写了。它分为 CPU 和 GPU 版本,其他框架还有 TensorFlow、Caffe 等。PyTorch 是由 Facebook 人工智能研究院(FAIR)基于 Torch 推出的,它是一个基于 Python 的可续计算包,提供两个高级功能:1、具有强大的 GPU 加速的张量计算(如 NumPy);2、构建深度神经网络时的自动微分机制。
- Transformer是一个用来替代RNN和CNN的新的网络结构,它能够直接获取全局的信息,而不像RNN需要逐步递归才能获得全局信息,也不像CNN只能获取局部信息。Transformer本质上就是一个Attention结构,并且其能够进行并行运算,要比RNN快上很多倍。
Transformer
- 论文地址:https://arxiv.org/abs/1706.03762
- 源码地址:https://github.com/graykode/nlp-tutorial/tree/master/5-1.Transformer
- 为什么要学习Transformer?由于最近几年,比较新的AI论文,或多或少都有Transformer的思想,比如,GPT文本生成系列论文,DETR目标检测系列论文,MaskFormer图像实例分割系列论文,等等,有兴趣,可自行搜索查阅!
总体架构
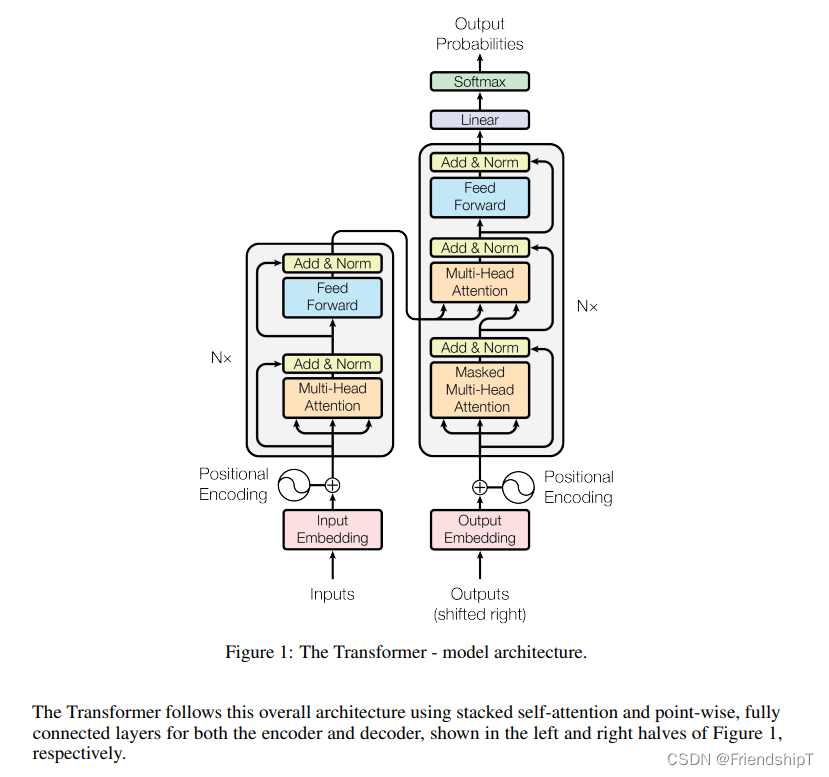
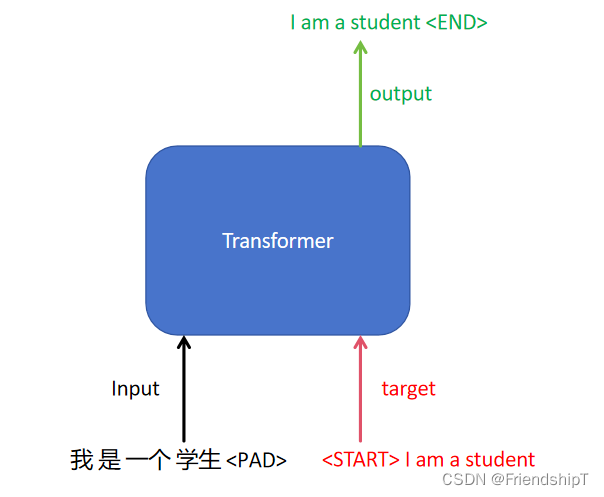
## 1. 从整体网路结构来看,分为三个部分:编码层,解码层,输出层
class Transformer(nn.Module):def __init__(self):super(Transformer, self).__init__()self.encoder = Encoder() ## 编码层self.decoder = Decoder() ## 解码层## 输出层 d_model 是我们解码层每个token输出的维度大小,之后会做一个 tgt_vocab_size 大小的softmaxself.projection = nn.Linear(d_model, tgt_vocab_size, bias=False) def forward(self, enc_inputs, dec_inputs):## 这里有两个数据进行输入,# 一个是enc_inputs 形状为[batch_size, src_len],主要是作为编码段的输入,# 这里enc_inputs = tensor([[1, 2, 3, 4, 0]]),shape:torch.Size([1, 5])# 一个dec_inputs,形状为[batch_size, tgt_len],主要是作为解码端的输入# 这里dec_inputs = tensor([[1, 2, 3, 4, 0]]),shape:torch.Size([1, 5])## enc_inputs作为输入 形状为[batch_size, src_len],输出由自己的函数内部指定,想要什么指定输出什么,# 可以是全部tokens的输出,可以是特定每一层的输出;也可以是中间某些参数的输出;## enc_outputs就是主要的输出,enc_self_attns这里没记错的是QK转置相乘之后softmax之后的矩阵值,代表的是每个单词和其他单词相关性;enc_outputs, enc_self_attns = self.encoder(enc_inputs)## dec_outputs 是decoder主要输出,用于后续的linear映射; dec_self_attns类比于enc_self_attns 是查看每个单词对decoder中输入的其余单词的相关性;# dec_enc_attns是decoder中每个单词对encoder中每个单词的相关性;dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)## dec_outputs做映射到词表大小dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size]return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
编码器(Encoder)
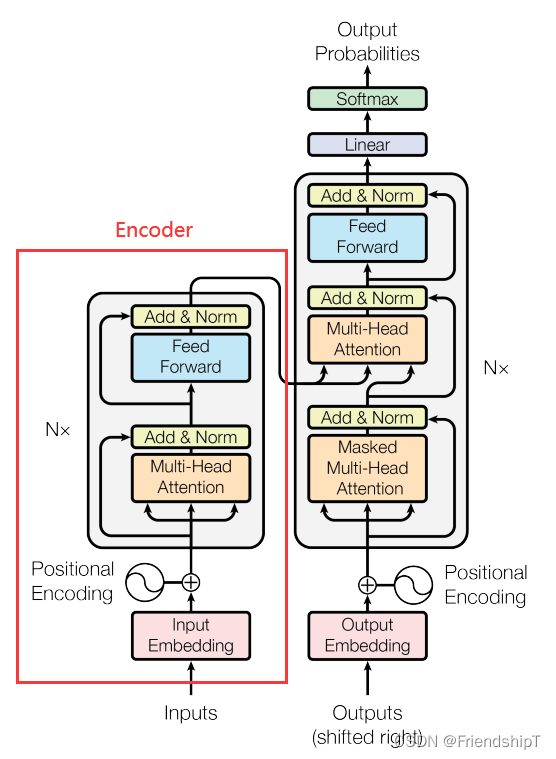
## 2. Encoder 部分包含三个部分:词向量embedding,位置编码部分,注意力层及后续的前馈神经网络
class Encoder(nn.Module):def __init__(self):super(Encoder, self).__init__()self.src_emb = nn.Embedding(src_vocab_size, d_model) ## 这个其实就是去定义生成一个矩阵,大小是 src_vocab_size * d_modelself.pos_emb = PositionalEncoding(d_model) ## 位置编码情况,这里是固定的正余弦函数,也可以使用类似词向量的nn.Embedding获得一个可以更新学习的位置编码self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) ## 使用ModuleList对多个encoder进行堆叠,因为后续的encoder并没有使用词向量和位置编码,所以抽离出来;def forward(self, enc_inputs):## 这里我们的 enc_inputs 形状是: [batch_size x source_len] # 这里是shape:torch.Size([1, 5])## 下面这个代码通过src_emb,进行索引定位,enc_outputs输出形状是[batch_size, src_len, d_model], # 这里的batch_size表示输入的句子数,一个句子有src_len个词,每个句子的词,用d_model个维度表示enc_outputs = self.src_emb(enc_inputs) # shape:torch.Size([1, 5]) Embedding后,shape:torch.Size([1, 5, 512])''''ich mochte ein bier P' 句子的词向量[[[ 0.7395, -0.3963, -0.1830, ..., 0.1230, -1.0532, -0.4132], # ich词向量,torch.Size([1, 512])[ 1.7916, -1.3049, -0.3316, ..., -0.6214, -1.1314, 0.5492], # mochte词向量,torch.Size([1, 512])[-0.0622, 0.9360, 0.0613, ..., 1.6010, -2.9987, -1.4837], # ein词向量,torch.Size([1, 512])[ 1.2109, -0.6176, -1.8097, ..., -0.4632, -1.5296, 0.2844], # bier词向量,torch.Size([1, 512])[ 1.3146, 1.8382, 1.5128, ..., 0.2111, 0.9384, 0.2603] # P词向量,torch.Size([1, 512])]],grad_fn=<EmbeddingBackward>)'''## 这里就是位置编码,把两者相加放入到了这个函数里面,从这里可以去看一下位置编码函数的实现;3.# self.pos_emb(x), x.shape: [seq_len, batch_size, d_model]# enc_outputs.transpose(0, 1).shape: [src_len, batch_size, d_model] # shape:torch.Size([5, 1, 512]enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # src_emb + pos_emb# enc_outputs.shape: [batch_size, src_len, d_model]##get_attn_pad_mask是为了得到句子中pad的位置信息,给到模型后面,在计算自注意力和交互注意力的时候去掉pad符号的影响,去看一下这个函数 4.enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # '''enc_inputs = tensor([[1, 2, 3, 4, 0]])enc_self_attn_mask = tensor([[[False, False, False, False, True], # True表示pad的位置[False, False, False, False, True],[False, False, False, False, True],[False, False, False, False, True],[False, False, False, False, True]]])'''enc_self_attns = []for layer in self.layers:## 去看EncoderLayer 层函数 5.enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)enc_self_attns.append(enc_self_attn)return enc_outputs, enc_self_attns
位置编码(Positional Encoding)

- 位置编码的公式,如下:
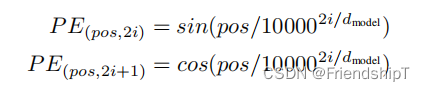
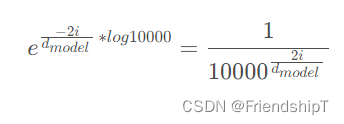
## 3. PositionalEncoding 代码实现
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout=0.1, max_len=5000):super(PositionalEncoding, self).__init__()## 位置编码的实现其实很简单,直接对照着公式去敲代码就可以,下面这个代码只是其中一种实现方式;## 从理解来讲,需要注意的就是偶数和奇数在公式上有一个共同部分,我们使用log函数把次方拿下来,方便计算;## pos代表的是单词在句子中的索引,这点需要注意;比如max_len是128个,那么索引就是从0,1,2,...,127##假设我的demodel是512,2i那个符号中i从0取到了255,那么2i对应取值就是0,2,4...510self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model) # pos ecoding ,shape : [max_len,d_model = 512]position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 初始化position序列div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # pe[:, 0::2] = torch.sin(position * div_term)## 这里需要注意的是pe[:, 0::2]这个用法,就是从0开始到最后面,步长为2,其实代表的就是偶数位置pe[:, 1::2] = torch.cos(position * div_term)##这里需要注意的是pe[:, 1::2]这个用法,就是从1开始到最后面,步长为2,其实代表的就是奇数位置## 上面代码获取之后得到的pe:[max_len*d_model]## 下面这个代码之后,我们得到的pe形状是:[max_len*1*d_model]pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe) ## 定一个缓冲区,其实简单理解为这个参数不更新就可以def forward(self, x):"""x: [seq_len, batch_size, d_model]tensor([[[ 0.4754, 0.8965, -0.2358, ..., -1.6288, -0.0859, 0.4266]],[[-0.0945, -0.8719, 0.1700, ..., 0.1514, 0.7029, 1.1040]],[[-1.4293, -1.2236, -0.8939, ..., 0.5179, 0.9243, -1.0067]],[[ 1.5126, 0.0090, -0.7605, ..., 0.1445, 0.0617, 0.6194]],[[ 1.6691, 1.0186, 0.4773, ..., -1.0291, 0.0582, 0.3893]]],grad_fn=<TransposeBackward0>)"""x = x + self.pe[:x.size(0), :]return self.dropout(x)
get_attn_pad_mask函数(Padding Mask)
- 在后面注意力机制的部分,在计算出
- softmax之前得到的矩阵大小为[len_input *len_input],代表每个单词对所有(包含自己)单词的影响力。
- get_attn_pad_mask函数这个函数用于获取一个同等大小形状的矩阵,标记哪个位置是PAD符号,之后在计算softmax之前会把这些地方置为无穷小,避免Query去关注这些无意义的PAD符号。
- 注意,本函数得到的矩阵形状是[batch_size x len_q x len_k],是对K中的pad符号进行标识,并没有对Q中的做标识,因为没必要。
- seq_q和seq_k不一定一致,例如,在交互注意力,q来自解码端,k来自编码端,所以告诉模型编码这边pad符号信息就可以,解码端的pad信息在交互注意力层是没有用到的。
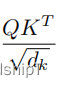
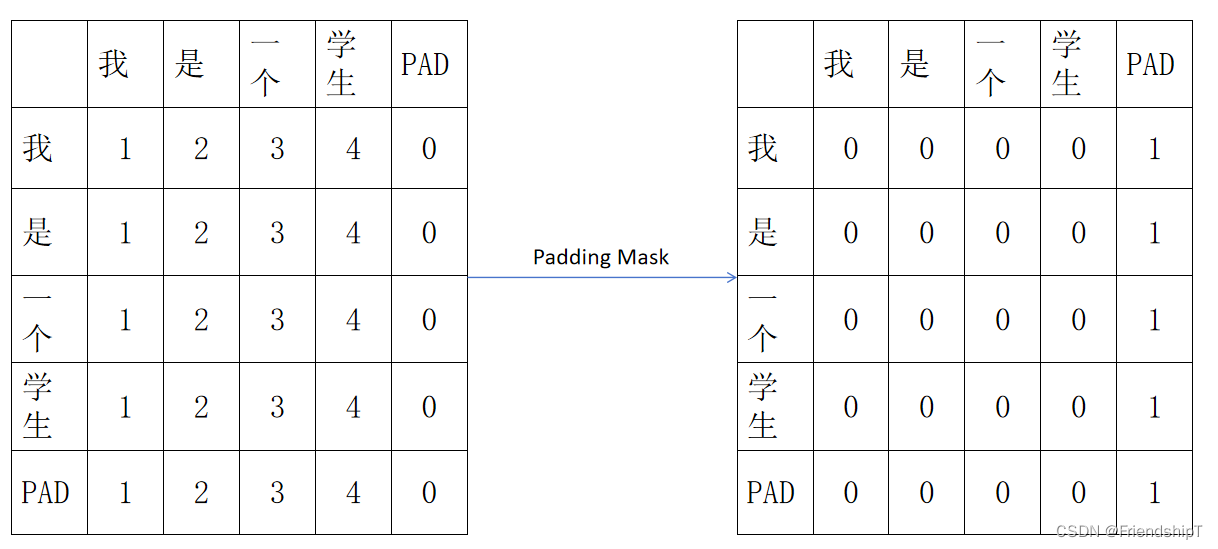
## 4. get_attn_pad_mask## 比如说,我现在的句子长度是5,在后面注意力机制的部分,我们在计算出来QK转置除以根号之后,softmax之前,我们得到的形状
## len_input * len_input 代表每个单词对其余包含自己的单词的影响力## 所以这里我需要有一个同等大小形状的矩阵,告诉我哪个位置是PAD部分,之后在计算计算softmax之前会把这里置为无穷大;## 一定需要注意的是这里得到的矩阵形状是batch_size x len_q x len_k,我们是对k中的pad符号进行标识,并没有对k中的做标识,因为没必要## seq_q 和 seq_k 不一定一致,在交互注意力,q来自解码端,k来自编码端,所以告诉模型编码这边pad符号信息就可以,解码端的pad信息在交互注意力层是没有用到的;def get_attn_pad_mask(seq_q, seq_k):batch_size, len_q = seq_q.size() # [1,5]batch_size, len_k = seq_k.size()# eq(zero) is PAD token,词表中'0'表示'P'pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k, one is masking# res = pad_attn_mask.expand(batch_size, len_q, len_k)# print(res) return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k
EncoderLayer
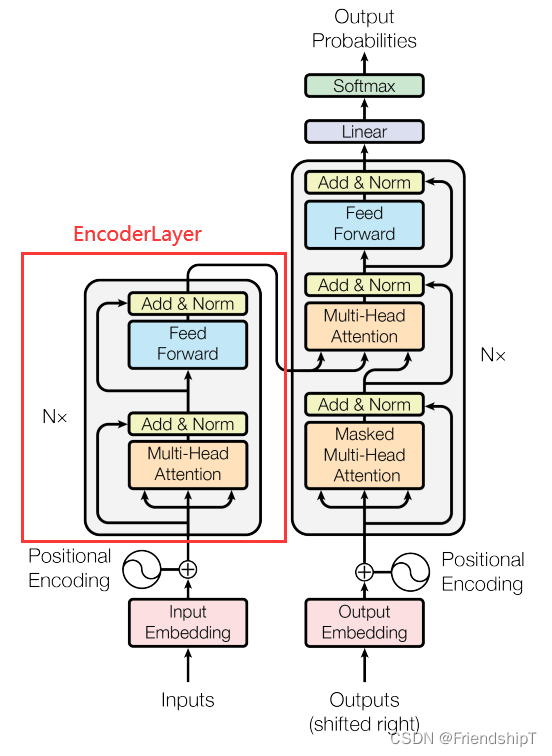
## 5. EncoderLayer :包含两个部分,多头注意力机制和前馈神经网络
class EncoderLayer(nn.Module):def __init__(self):super(EncoderLayer, self).__init__()self.enc_self_attn = MultiHeadAttention()self.pos_ffn = PoswiseFeedForwardNet()def forward(self, enc_inputs, enc_self_attn_mask):## 下面这个就是做自注意力层,输入是enc_inputs,形状是[batch_size x seq_len_q x d_model] 需要注意的是最初始的QKV矩阵是等同于这个输入的,去看一下enc_self_attn函数 6.enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,Venc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]return enc_outputs, attn
MultiHeadAttention

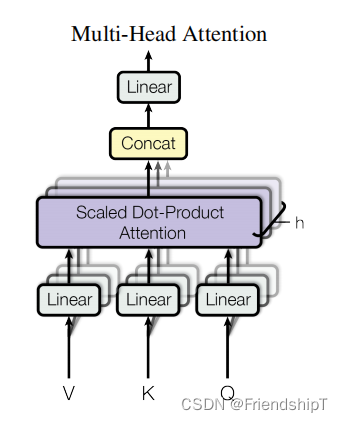
## 6. MultiHeadAttention
class MultiHeadAttention(nn.Module):def __init__(self):super(MultiHeadAttention, self).__init__()## 输入进来的QKV是相等的,我们会使用映射linear做一个映射得到参数矩阵Wq, Wk,Wvself.W_Q = nn.Linear(d_model, d_k * n_heads)self.W_K = nn.Linear(d_model, d_k * n_heads)self.W_V = nn.Linear(d_model, d_v * n_heads)self.linear = nn.Linear(n_heads * d_v, d_model)self.layer_norm = nn.LayerNorm(d_model)def forward(self, Q, K, V, attn_mask):## 这个多头分为这几个步骤,首先映射分头,然后计算atten_scores,然后计算atten_value;##输入进来的数据形状: Q: [batch_size x len_q x d_model], K: [batch_size x len_k x d_model], V: [batch_size x len_k x d_model]residual, batch_size = Q, Q.size(0)# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)##下面这个就是先映射,后分头;一定要注意的是q和k分头之后维度是一致额,所以一看这里都是dkq_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]## 输入进行的attn_mask形状是 batch_size x len_q x len_k,然后经过下面这个代码得到 新的attn_mask : [batch_size x n_heads x len_q x len_k],就是把pad信息重复了n个头上attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)##然后我们计算 ScaledDotProductAttention 这个函数,去7.看一下## 得到的结果有两个:context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q x len_k]context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]output = self.linear(context)return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]
ScaledDotProductAttention
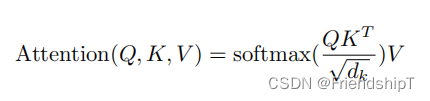
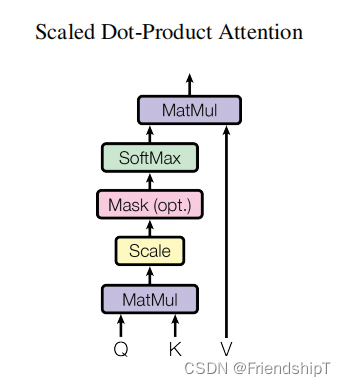
## 7. ScaledDotProductAttention
class ScaledDotProductAttention(nn.Module):def __init__(self):super(ScaledDotProductAttention, self).__init__()def forward(self, Q, K, V, attn_mask):## 输入进来的维度分别是 [batch_size x n_heads x len_q x d_k] K: [batch_size x n_heads x len_k x d_k] V: [batch_size x n_heads x len_k x d_v]##首先经过matmul函数得到的scores形状是 : [batch_size x n_heads x len_q x len_k]scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)## 然后关键词地方来了,下面这个就是用到了我们之前重点讲的attn_mask,把被mask的地方置为无限小,softmax之后基本就是0,对q的单词不起作用scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is one.attn = nn.Softmax(dim=-1)(scores)context = torch.matmul(attn, V)return context, attn
PoswiseFeedForwardNet

## 8. PoswiseFeedForwardNet
class PoswiseFeedForwardNet(nn.Module):def __init__(self):super(PoswiseFeedForwardNet, self).__init__()self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)self.layer_norm = nn.LayerNorm(d_model)def forward(self, inputs):residual = inputs # inputs : [batch_size, len_q, d_model]output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))output = self.conv2(output).transpose(1, 2)return self.layer_norm(output + residual)
或者
class PoswiseFeedForwardNet(nn.Module):def __init__(self):super(PoswiseFeedForwardNet, self).__init__()self.fc = nn.Sequential(nn.Linear(d_model, d_ff, bias=False),nn.ReLU(),nn.Linear(d_ff, d_model, bias=False))def forward(self, inputs): # inputs: [batch_size, seq_len, d_model]residual = inputsoutput = self.fc(inputs)return nn.LayerNorm(d_model).(output + residual) # [batch_size, seq_len, d_model]
解码器(Decoder)
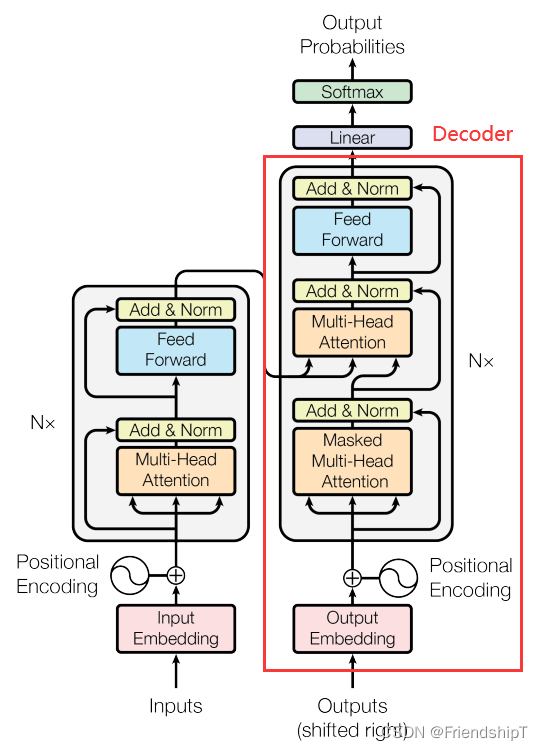
## 9. Decoder
class Decoder(nn.Module):def __init__(self):super(Decoder, self).__init__()self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)self.pos_emb = PositionalEncoding(d_model)self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs : [batch_size x target_len]dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, tgt_len, d_model]## get_attn_pad_mask 自注意力层的时候的pad 部分dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)## get_attn_subsequent_mask 这个做的是自注意层的mask部分,就是当前单词之后看不到,使用一个上三角为1的矩阵dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs)## 两个矩阵相加,大于0的为1,不大于0的为0,为1的在之后就会被fill到无限小dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)## 这个做的是交互注意力机制中的mask矩阵,enc的输入是k,我去看这个k里面哪些是pad符号,给到后面的模型;注意哦,我q肯定也是有pad符号,但是这里我不在意的,之前说了好多次了哈dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)dec_self_attns, dec_enc_attns = [], []for layer in self.layers:dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)dec_self_attns.append(dec_self_attn)dec_enc_attns.append(dec_enc_attn)return dec_outputs, dec_self_attns, dec_enc_attns
位置编码(Positional Encoding)
- 解码器(Decoder)中的位置编码(Positional Encoding),与编码器(Encoder)中的位置编码(Positional Encoding)实现一样,这里不重复赘述。
get_attn_subsequent_mask函数(Sequence Mask)
- 遮蔽未来词,让当前词看不到未来词。这个函数就是用来表示Decoder的输入中哪些是未来词,显然,这个Mask矩阵应该是一个上三角矩阵。
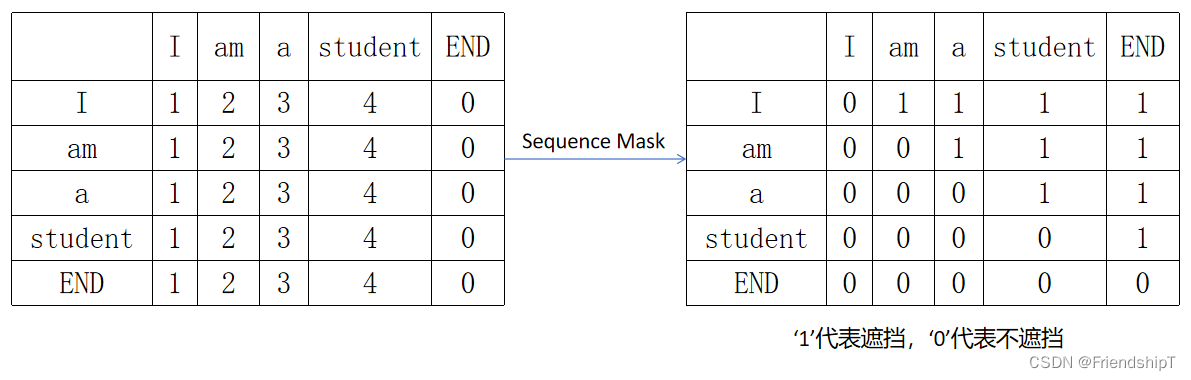
## 10
def get_attn_subsequent_mask(seq):"""seq: [batch_size, tgt_len]"""attn_shape = [seq.size(0), seq.size(1), seq.size(1)]# attn_shape: [batch_size, tgt_len, tgt_len]subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 生成一个上三角矩阵subsequence_mask = torch.from_numpy(subsequence_mask).byte()return subsequence_mask # [batch_size, tgt_len, tgt_len]
完整代码
## from https://github.com/graykode/nlp-tutorial/tree/master/5-1.Transformerimport numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import mathdef make_batch(sentences): # sentences = ['我 是 一个 学生 P', 'S I am a student', 'I am a student E']input_batch = [[src_vocab[n] for n in sentences[0].split()]] # ['我 是 一个 学生 P'] ->[[1, 2, 3, 4, 0]]output_batch = [[tgt_vocab[n] for n in sentences[1].split()]] # ['S I am a student'] -> [[5, 1, 2, 3, 4]]target_batch = [[tgt_vocab[n] for n in sentences[2].split()]] # ['I am a student E'] -> [[1, 2, 3, 4, 6]]return torch.LongTensor(input_batch), torch.LongTensor(output_batch), torch.LongTensor(target_batch)## 10
def get_attn_subsequent_mask(seq):"""seq: [batch_size, tgt_len]"""attn_shape = [seq.size(0), seq.size(1), seq.size(1)]# attn_shape: [batch_size, tgt_len, tgt_len]subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 生成一个上三角矩阵subsequence_mask = torch.from_numpy(subsequence_mask).byte()return subsequence_mask # [batch_size, tgt_len, tgt_len]## 7. ScaledDotProductAttention
class ScaledDotProductAttention(nn.Module):def __init__(self):super(ScaledDotProductAttention, self).__init__()def forward(self, Q, K, V, attn_mask):## 输入进来的维度分别是 [batch_size x n_heads x len_q x d_k] K: [batch_size x n_heads x len_k x d_k] V: [batch_size x n_heads x len_k x d_v]##首先经过matmul函数得到的scores形状是 : [batch_size x n_heads x len_q x len_k]scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)## 然后关键词地方来了,下面这个就是用到了我们之前重点讲的attn_mask,把被mask的地方置为无限小,softmax之后基本就是0,对q的单词不起作用scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is one.attn = nn.Softmax(dim=-1)(scores)context = torch.matmul(attn, V)return context, attn## 6. MultiHeadAttention
class MultiHeadAttention(nn.Module):def __init__(self):super(MultiHeadAttention, self).__init__()## 输入进来的QKV是相等的,我们会使用映射linear做一个映射得到参数矩阵Wq, Wk,Wvself.W_Q = nn.Linear(d_model, d_k * n_heads)self.W_K = nn.Linear(d_model, d_k * n_heads)self.W_V = nn.Linear(d_model, d_v * n_heads)self.linear = nn.Linear(n_heads * d_v, d_model)self.layer_norm = nn.LayerNorm(d_model)def forward(self, Q, K, V, attn_mask):## 这个多头分为这几个步骤,首先映射分头,然后计算atten_scores,然后计算atten_value;##输入进来的数据形状: Q: [batch_size x len_q x d_model], K: [batch_size x len_k x d_model], V: [batch_size x len_k x d_model]residual, batch_size = Q, Q.size(0)# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)##下面这个就是先映射,后分头;一定要注意的是q和k分头之后维度是一致额,所以一看这里都是dkq_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]## 输入进行的attn_mask形状是 batch_size x len_q x len_k,然后经过下面这个代码得到 新的attn_mask : [batch_size x n_heads x len_q x len_k],就是把pad信息重复了n个头上attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)##然后我们计算 ScaledDotProductAttention 这个函数,去7.看一下## 得到的结果有两个:context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q x len_k]context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]output = self.linear(context)return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]## 8. PoswiseFeedForwardNet
class PoswiseFeedForwardNet(nn.Module):def __init__(self):super(PoswiseFeedForwardNet, self).__init__()self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)self.layer_norm = nn.LayerNorm(d_model)def forward(self, inputs):residual = inputs # inputs : [batch_size, len_q, d_model]output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))output = self.conv2(output).transpose(1, 2)return self.layer_norm(output + residual)## 4. get_attn_pad_mask## 比如说,我现在的句子长度是5,在后面注意力机制的部分,我们在计算出来QK转置除以根号之后,softmax之前,我们得到的形状
## len_input * len_input 代表每个单词对其余包含自己的单词的影响力## 所以这里我需要有一个同等大小形状的矩阵,告诉我哪个位置是PAD部分,之后在计算计算softmax之前会把这里置为无穷大;## 一定需要注意的是这里得到的矩阵形状是batch_size x len_q x len_k,我们是对k中的pad符号进行标识,并没有对k中的做标识,因为没必要## seq_q 和 seq_k 不一定一致,在交互注意力,q来自解码端,k来自编码端,所以告诉模型编码这边pad符号信息就可以,解码端的pad信息在交互注意力层是没有用到的;def get_attn_pad_mask(seq_q, seq_k):batch_size, len_q = seq_q.size() # [1,5]batch_size, len_k = seq_k.size()# eq(zero) is PAD token,词表中'0'表示'P'pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k, one is masking# res = pad_attn_mask.expand(batch_size, len_q, len_k)# print(res) return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k## 3. PositionalEncoding 代码实现
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout=0.1, max_len=5000):super(PositionalEncoding, self).__init__()## 位置编码的实现其实很简单,直接对照着公式去敲代码就可以,下面这个代码只是其中一种实现方式;## 从理解来讲,需要注意的就是偶数和奇数在公式上有一个共同部分,我们使用log函数把次方拿下来,方便计算;## pos代表的是单词在句子中的索引,这点需要注意;比如max_len是128个,那么索引就是从0,1,2,...,127##假设我的demodel是512,2i那个符号中i从0取到了255,那么2i对应取值就是0,2,4...510self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model) # pos ecoding ,shape : [max_len,d_model = 512]position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 初始化position序列div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # pe[:, 0::2] = torch.sin(position * div_term)## 这里需要注意的是pe[:, 0::2]这个用法,就是从0开始到最后面,步长为2,其实代表的就是偶数位置pe[:, 1::2] = torch.cos(position * div_term)##这里需要注意的是pe[:, 1::2]这个用法,就是从1开始到最后面,步长为2,其实代表的就是奇数位置## 上面代码获取之后得到的pe:[max_len*d_model]## 下面这个代码之后,我们得到的pe形状是:[max_len*1*d_model]pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe) ## 定一个缓冲区,其实简单理解为这个参数不更新就可以def forward(self, x):"""x: [seq_len, batch_size, d_model]tensor([[[ 0.4754, 0.8965, -0.2358, ..., -1.6288, -0.0859, 0.4266]],[[-0.0945, -0.8719, 0.1700, ..., 0.1514, 0.7029, 1.1040]],[[-1.4293, -1.2236, -0.8939, ..., 0.5179, 0.9243, -1.0067]],[[ 1.5126, 0.0090, -0.7605, ..., 0.1445, 0.0617, 0.6194]],[[ 1.6691, 1.0186, 0.4773, ..., -1.0291, 0.0582, 0.3893]]],grad_fn=<TransposeBackward0>)"""x = x + self.pe[:x.size(0), :]return self.dropout(x)## 5. EncoderLayer :包含两个部分,多头注意力机制和前馈神经网络
class EncoderLayer(nn.Module):def __init__(self):super(EncoderLayer, self).__init__()self.enc_self_attn = MultiHeadAttention()self.pos_ffn = PoswiseFeedForwardNet()def forward(self, enc_inputs, enc_self_attn_mask):## 下面这个就是做自注意力层,输入是enc_inputs,形状是[batch_size x seq_len_q x d_model] 需要注意的是最初始的QKV矩阵是等同于这个输入的,去看一下enc_self_attn函数 6.enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,Venc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]return enc_outputs, attn## 2. Encoder 部分包含三个部分:词向量embedding,位置编码部分,注意力层及后续的前馈神经网络
class Encoder(nn.Module):def __init__(self):super(Encoder, self).__init__()self.src_emb = nn.Embedding(src_vocab_size, d_model) ## 这个其实就是去定义生成一个矩阵,大小是 src_vocab_size * d_modelself.pos_emb = PositionalEncoding(d_model) ## 位置编码情况,这里是固定的正余弦函数,也可以使用类似词向量的nn.Embedding获得一个可以更新学习的位置编码self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) ## 使用ModuleList对多个encoder进行堆叠,因为后续的encoder并没有使用词向量和位置编码,所以抽离出来;def forward(self, enc_inputs):## 这里我们的 enc_inputs 形状是: [batch_size x source_len] # 这里是shape:torch.Size([1, 5])## 下面这个代码通过src_emb,进行索引定位,enc_outputs输出形状是[batch_size, src_len, d_model], # 这里的batch_size表示输入的句子数,一个句子有src_len个词,每个句子的词,用d_model个维度表示enc_outputs = self.src_emb(enc_inputs) # shape:torch.Size([1, 5]) Embedding后,shape:torch.Size([1, 5, 512])''''ich mochte ein bier P' 句子的词向量[[[ 0.7395, -0.3963, -0.1830, ..., 0.1230, -1.0532, -0.4132], # ich词向量,torch.Size([1, 512])[ 1.7916, -1.3049, -0.3316, ..., -0.6214, -1.1314, 0.5492], # mochte词向量,torch.Size([1, 512])[-0.0622, 0.9360, 0.0613, ..., 1.6010, -2.9987, -1.4837], # ein词向量,torch.Size([1, 512])[ 1.2109, -0.6176, -1.8097, ..., -0.4632, -1.5296, 0.2844], # bier词向量,torch.Size([1, 512])[ 1.3146, 1.8382, 1.5128, ..., 0.2111, 0.9384, 0.2603] # P词向量,torch.Size([1, 512])]],grad_fn=<EmbeddingBackward>)'''## 这里就是位置编码,把两者相加放入到了这个函数里面,从这里可以去看一下位置编码函数的实现;3.# self.pos_emb(x), x.shape: [seq_len, batch_size, d_model]# enc_outputs.transpose(0, 1).shape: [src_len, batch_size, d_model] # shape:torch.Size([5, 1, 512]enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # src_emb + pos_emb# enc_outputs.shape: [batch_size, src_len, d_model]##get_attn_pad_mask是为了得到句子中pad的位置信息,给到模型后面,在计算自注意力和交互注意力的时候去掉pad符号的影响,去看一下这个函数 4.enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # '''enc_inputs = tensor([[1, 2, 3, 4, 0]])enc_self_attn_mask = tensor([[[False, False, False, False, True], # True表示pad的位置[False, False, False, False, True],[False, False, False, False, True],[False, False, False, False, True],[False, False, False, False, True]]])'''enc_self_attns = []for layer in self.layers:## 去看EncoderLayer 层函数 5.enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)enc_self_attns.append(enc_self_attn)return enc_outputs, enc_self_attns## 10.
class DecoderLayer(nn.Module):def __init__(self):super(DecoderLayer, self).__init__()self.dec_self_attn = MultiHeadAttention()self.dec_enc_attn = MultiHeadAttention()self.pos_ffn = PoswiseFeedForwardNet()def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)dec_outputs = self.pos_ffn(dec_outputs)return dec_outputs, dec_self_attn, dec_enc_attn## 9. Decoder
class Decoder(nn.Module):def __init__(self):super(Decoder, self).__init__()self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)self.pos_emb = PositionalEncoding(d_model)self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs : [batch_size x target_len]dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, tgt_len, d_model]## get_attn_pad_mask 自注意力层的时候的pad 部分dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)## get_attn_subsequent_mask 这个做的是自注意层的mask部分,就是当前单词之后看不到,使用一个上三角为1的矩阵dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs)## 两个矩阵相加,大于0的为1,不大于0的为0,为1的在之后就会被fill到无限小dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)## 这个做的是交互注意力机制中的mask矩阵,enc的输入是k,我去看这个k里面哪些是pad符号,给到后面的模型;注意哦,我q肯定也是有pad符号,但是这里我不在意的,之前说了好多次了哈dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)dec_self_attns, dec_enc_attns = [], []for layer in self.layers:dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)dec_self_attns.append(dec_self_attn)dec_enc_attns.append(dec_enc_attn)return dec_outputs, dec_self_attns, dec_enc_attns## 1. 从整体网路结构来看,分为三个部分:编码层,解码层,输出层
class Transformer(nn.Module):def __init__(self):super(Transformer, self).__init__()self.encoder = Encoder() ## 编码层self.decoder = Decoder() ## 解码层## 输出层 d_model 是我们解码层每个token输出的维度大小,之后会做一个 tgt_vocab_size 大小的softmaxself.projection = nn.Linear(d_model, tgt_vocab_size, bias=False) def forward(self, enc_inputs, dec_inputs):## 这里有两个数据进行输入,# 一个是enc_inputs 形状为[batch_size, src_len],主要是作为编码段的输入,# 这里enc_inputs = tensor([[1, 2, 3, 4, 0]]),shape:torch.Size([1, 5])# 一个dec_inputs,形状为[batch_size, tgt_len],主要是作为解码端的输入# 这里dec_inputs = tensor([[1, 2, 3, 4, 0]]),shape:torch.Size([1, 5])## enc_inputs作为输入 形状为[batch_size, src_len],输出由自己的函数内部指定,想要什么指定输出什么,# 可以是全部tokens的输出,可以是特定每一层的输出;也可以是中间某些参数的输出;## enc_outputs就是主要的输出,enc_self_attns这里没记错的是QK转置相乘之后softmax之后的矩阵值,代表的是每个单词和其他单词相关性;enc_outputs, enc_self_attns = self.encoder(enc_inputs)## dec_outputs 是decoder主要输出,用于后续的linear映射; dec_self_attns类比于enc_self_attns 是查看每个单词对decoder中输入的其余单词的相关性;# dec_enc_attns是decoder中每个单词对encoder中每个单词的相关性;dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)## dec_outputs做映射到词表大小dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size]return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attnsif __name__ == '__main__':## 句子的输入部分, ## P表示pad ,S表示句子的开始start, E表示句子的结束endsentences = ['我 是 一个 学生 P', 'S I am a student', 'I am a student E']# Transformer Parameters# Padding Should be Zero## 构建词表src_vocab = {'P': 0, '我': 1, '是': 2, '一个': 3, '学生': 4}src_vocab_size = len(src_vocab) # 5tgt_vocab = {'P': 0, 'I': 1, 'am': 2, 'a': 3, 'student': 4, 'S': 5, 'E': 6}tgt_vocab_size = len(tgt_vocab) # 7src_len = 5 # length of source # 输入句子长度tgt_len = 5 # length of target # 输出句子长度## 模型参数d_model = 512 # Embedding Size 词嵌入大小的维度d_ff = 2048 # FeedForward dimension # 前馈神经网络(FeedForward)层隐藏层维度d_k = d_v = 64 # dimension of K(=Q), V # key,query,value一般维度相同,K(在自注意力中,也是Q的大小)、V向量大小n_layers = 6 # number of Encoder of Decoder Layer # 编码器和解码器的层数n_heads = 8 # number of heads in Multi-Head Attention # 多头注意力机制的个数 model = Transformer() # Transformer网络模型print(model)criterion = nn.CrossEntropyLoss() # 损失函数optimizer = optim.Adam(model.parameters(), lr=0.001) # 优化器enc_inputs, dec_inputs, target_batch = make_batch(sentences) # 制作编码器、解码器、真实标签的输入# print(enc_inputs,dec_inputs,target_batch) # tensor([[1, 2, 3, 4, 0]]) tensor([[5, 1, 2, 3, 4]]) tensor([[1, 2, 3, 4, 6]])epochs = 10for epoch in range(epochs):optimizer.zero_grad() # 计算清零,因为optimizer.step()函数计算出的值,是叠加计算的outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)loss = criterion(outputs, target_batch.contiguous().view(-1))print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))loss.backward()optimizer.step()
参考
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention Is All You Need. 2023.
[2] https://blog.csdn.net/m0_47779101/article/details/128087403
[3] https://zhuanlan.zhihu.com/p/338817680
[4] https://zhuanlan.zhihu.com/p/407012757
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏或我的个人主页查看
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- 基于DETR的人脸伪装检测
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- YOLOv5:TensorRT加速YOLOv5模型推理




![[SQL系列] 从头开始学PostgreSQL 分库分表](http://pic.xiahunao.cn/[SQL系列] 从头开始学PostgreSQL 分库分表)
—直线插补—逐点比较法)
)


请求合并机制原理分析)
)


)




 新机 安装Cocoapods)
