东方国信

学长1
Hadoop工程师笔试题(金融事业部)
1)技术基础题(共十题,每题5分)
(1)列举在Linux系统下可以在看系统各项性能的工具(区分CPU、内存、硬盘、网络等)
(2)HDFS写入数据的实现机制
(3)Yarn支持的调度器及管理硬件资源种类
(4)如何决定一个job的map和reduce的数量
(5)在map、reduce 迭代模型中,如何实现数据去重
(6)简单描述HBase的rowkey设计原则
(7)HBase海量历史数据入库方案
(8)Hive中内部表与外部表的区别
(9)Hive中UDF、UDAF、UDTF的区别
(10)Spark Job运行架构
2)场景设计题(共二题,每题10分)
假设海量小文件使用HBase进行管理,要求对一批文件进行批量存储,并支持对单文件进行更新操作,保留历史版本信息。查询时可根据批次号获取该批次的全部文件内容,也可根据文件标识可获取单文件内容,支持最新版本及所有版本查询。根据业务场景,设计HBase存储方案。
学长2
大数据工程师笔试题
1)理论题
(1)HDFS的存储机制是什么?
(2)mapreduce的工作原理,请举个例子说明mapreduce是怎么运行的?Combiner的作用?
(3)简单介绍对Hadoop的理解,包括系统架构和Hadoop整个生态系统,详细介绍工作中曾用到过的?
(4)对流式计算storm的认识?其与Spark streaming有何区别?项目中应用到storm的应用场景简介。
2)实践题
(1)利用Spark或者mapreduce或者hive(要求建表)编写搜索日志分析:用户在0点12点对各个APP的搜索量。搜索日志存放路径为/input/data.txt.文件用竖线分割,第一列为时间字段,第三列为APP名称。字段名及字段类型可自己定义。
日志内容如下:
00:00:0012982199073774412|[网易新闻]|8|3
00:01:00|0759422001082479|[今日头条|1|1
13:01:00|2982199073774412|[网易新闻]|1|1
14:30:00|07594220010824791|今日头条]1|1
(2)现有图书管理数据库的三个数据模型如下:
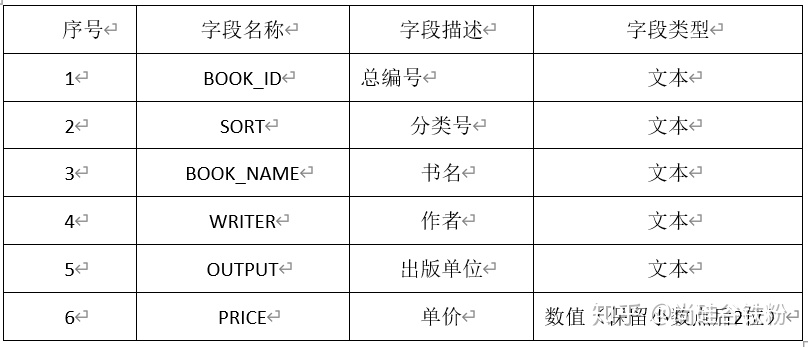
图书(数据表名:BOOK)
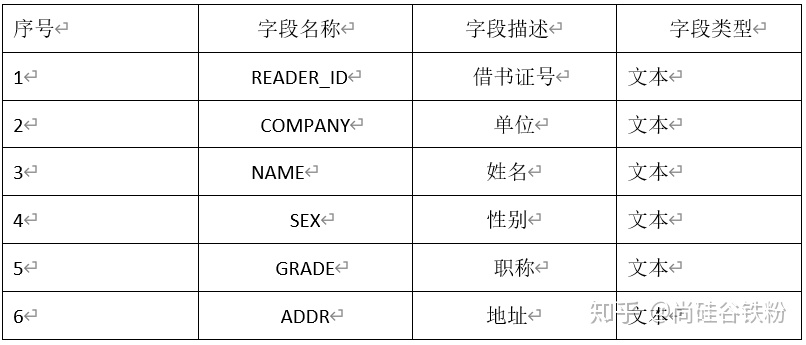
读者(数据表名:READER)
借阅记录(数据表名:BORROW LOG)
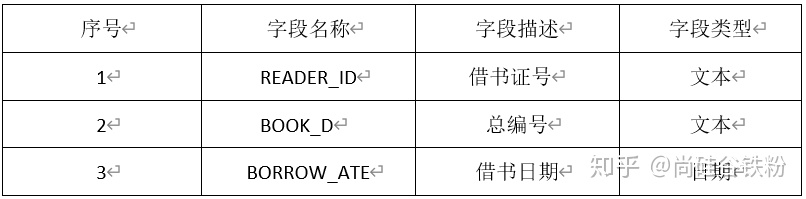
(1)创建图书管理库的图书、读者和借阅三个基本表的表结构。请写出建表语句。(Oracle实现)
(2)找出姓李的读者姓名(NAME)和所在单位(COMPANY)。(Oracle 实现)
(3)查找“高等教育出版社”的所有图书名称(BOOK_NAME)及单价(PRICE),结果按单价降序排序。(Oracle实现)
(4)查找价格介于10元和20元之间的图书种类(SORT)出版单位(OUTPUT)和单价(PRICE),结果按出版单位(OUTPUT)和单价(PRICE)升序排序。(Oracle 实现)
(5)查找所有借了书的读者的姓名(NAME)及所在单位(COMPANY)。(Oracle实现)
(6)求”科学出版社”图书的最高单价、最低单价、平均单价。(Oracle实现)
(7)找出当前至少借阅了2本图书(大于等于2本)的读者姓名及其所在单位。(Oracle实现)
(8)考虑到数据安全的需要,需定时将“借阅记录”中数据进行备份,请使用一条SQL语句,在备份用户bak下创建与“借阅记录”表结构完全一致的数据表BORROW_LOG_BAK.井且将“借阅记录”中现有数据全部复制到BORROW_1.0G_ BAK中。(Oracle实现)
(9)现在需要将原Oracle数据库中数据迁移至Hive仓库,请写出“图书”在Hive中的建表语句(Hive实现,提示:列分隔符|;数据表数据需要外部导入:分区分别以month_part、day_part 命名)
(10)Hive中有表A,现在需要将表A的月分区 201505 中 user_id为20000的user_dinner字段更新为bonc8920,其他用户user_dinner字段数据不变,请列出更新的方法步骤。(Hive实现,提示:Hlive中无update语法,请通过其他办法进行数据更新)
7.SQL优化题
(1)SELECT TAB_NAME FROM TABLES WHERE TAB_NAME =
(SELECT TAB_NAME FROM TAB_COLUMNS WHERE VERSION=604)AND DB_VER=(SELECT DB_VER FROM TAB_COLUMNS WHERE VERSION = 604),
考虑到过多子查询造成SQL性能下降,请针对上述SQL.语句进行优化,提升执行效率(Oracle实现)
UPDATE EMP SET EMP_CAT =(SELECT MAX(CATEGORY)FROM EMP_CATEGORIES),SAL_RANGE=(SELECT MAX(SAL RANGE)FROM EMP_CATEGORIES)WHERE EMP_DEPT = 0020,在含有子查询的SQL语句中,过多对表的查询会造成SQL性能下降,请针对上述SQL.语句进行优化,提升执行效率(Oracle实现)
EMP表数据量很大,user_id存在空值,以下语句会造成数据处理结果存储倾斜,请提供优化策略解决数据倾斜问题。(注:数据倾斜由关联字段空值引起,Hive实现)
SELECT* FROM EXP A JOIN DEPT B ON A.USER_ID= B.USER_ID
(2)Hbase 常用基本命令,创建表,添加记录,查看记录,删除记录。
文章来源:尚硅谷大数据培训
)










---2016年2月20日(晴))

DirectShow9在VS2005或vc6.0下编译出现问题的解决方法)


)


