
在上一篇文章里,给大家介绍了R语言的下载,界面操作,6个处理对象等等。
在这些内容的基础上,我们在这个部分为大家介绍一些实用知识,包括描述工作区结构、图形设备以及它们的参数等问题,还有初级编程和数据输入输出。
1 | 会话管理常用操作
① 首先,我们需要提出一个概念:“变量”,其实变量在各种语言或程序都会出现,是计算机语言中能储存计算结果或能表示值的抽象概念。我们先前完成的赋值操作都是把变量作为对象,是数据结果的容器,同时也是我们给结果的代号。R中变量的命名是很开放的,只需要遵守以下的原则:
1. 由字母、数字、圆点(.)、下划线组成
2. 不能有除圆点(.)、下划线 以外的符号,如(%)等
3. 不能以数字开头
4. 以圆点(.)开头后不能直接接数字
5. 与sas不同,不能以下划线开头
② 在R中创建的所有变量会存储在一个公共的工作区。要了解哪些变量定义在工作区中,可以使用函数ls()函数来展示它们:
> ls()
[1] "acc.count" "age.acc" "brk" "findruns" "findruns1" "findud"
[7] "i" "juul" "mid.age" "n" "preda" "pvec"
[13] "s" "side" "thue" "thuesen" "udcorr" "x"
[19] "xbar" "y"
#Tips:这里是LS()的小写,不是i,容易出错,另外ls后的括号不能省略,省略了就变成了变量ls了,而不是函数。这里展示的是工作区内所存储的变量,但不包括系统变量——以点开头的变量,若想要展示它们,可以用> ls(all=T)来展示所有变量,但不建议这样做。另外因为操作的缘故,结果展示可能会不同。
如果想要删除某些变量,可以通过rm()来实现:
> rm(acc.count,age.acc,brk,findruns,findruns1,findud)
> ls()
[1] "i" "juul" "mid.age" "n" "preda" "pvec" "s"
[8] "side" "thue" "thuesen" "udcorr" "x" "xbar" "y"
#Tips:可以使用> rm(list=ls())来清空整个工作区。
如果想要保存工作区到文件,可以使用> save.image()或者File菜单下的保存工作空间,或者在关闭R时出现的提醒里保存,都会保存成一个后缀名为.RData的文件。
#Tips:上面的方式只会保存工作区的R变量,但是不会保存产生的所有输出,如果想要保存输出结果,点击Files菜单下的“Save to File(保存到文件)”,就会保存所有的结果。
#Tips:当前工作目录可以通过getwd()获取,通过setwd()转换到自己想要设定的地址。比如:> setwd("C:/Users/Administrator/Documents")
③ 如果要处理的问题比较复杂,不希望逐行与R进行交互,或者在输入多行数据的情况下容易出错,在使用上箭头调整的时候很麻烦,在这些情况下,可以使用R脚本来处理,即R代码行的集合。
文件→新建程序脚本
④ 获取帮助、包、内置数据
这三个东西都属于R软件内置的文件,而帮助和包的相关内容在引言的文章中有提到过。内置数据在上一部分我们已经提过。
在命令行中通过输入> help(split)或用前缀形式> ?split都可以获取split()函数的帮助。
包可以包含用R语言写的函数,汇编代码动态加载库以及数据集。包的功能会自动执行,所以用户不需要一直加载包。使用library命令将包装入R:
> library(survival)
加载的包不被视为工作区的一部分,如果终止了本次的R,重新打开R需要重新加载包。如果需要移除已经装载的包,需要使用:
> detach("package:survival")
⑤ attach 和 detach
有的时候你要重复写一些很长的命令,在数据框中获取变量的符号就会很多比如说:> plot(women$height,women$weight)
#Tips:women是R自带的数据集,可以直接使用,不需要外部导入。
不过,R可以让你在数据框内搜寻目标变量,不使用$符号,比如:
> attach(women)
> plot(height,weight)
attach()命令相当于将women放置到系统的搜索路径中,可以使用> search()看到搜索路径:
> search()
[1] ".GlobalEnv" "women" "package:stats"
[4] "package:graphics" "package:grDevices" "package:utils"
[7] "package:datasets" "package:methods" "Autoloads"
[10] "package:base"
也可以用detach()从搜索路径删除数据框,如果不给参数,默认第二个位置的数据框被删除。
> detach()
> search()
[1] ".GlobalEnv" "package:stats" "package:graphics"
[4] "package:grDevices" "package:utils" "package:datasets"
[7] "package:methods" "Autoloads" "package:base"
⑥ subset和transform
对于选择数据子集以及变换变量创建新的数据框:
> women.sub<-subset(women,women$height<65)
> women.sub
height weight
1 58 115
2 59 117
3 60 120
4 61 123
5 62 126
6 63 129
7 64 132
> women.transform=transform(women,
+ bmi=(weight*0.45359)/((height*0.0254)^2))
> head(women.transform)
height weight bmi
1 58 115 24.03465
2 59 117 23.63077
3 60 120 23.43553
4 61 123 23.24029
5 62 126 23.04534
6 63 129 22.85097
#Tips:subset()函数是选取子集的函数,第一个参数是原始数据集,第二个参数是条件,类似于上一个部分所讲的条件选择。Transform()函数可以根据已有变量来计算新变量,或为原数据框添加新的列,改变原变量列的值,还可通过赋值NULL删除列变量。“=”不是赋值,而是表示名称,该名称被赋值给最后一步计算的向量。可以尝试> women$bmi 看一下。
2| 作图系统环境
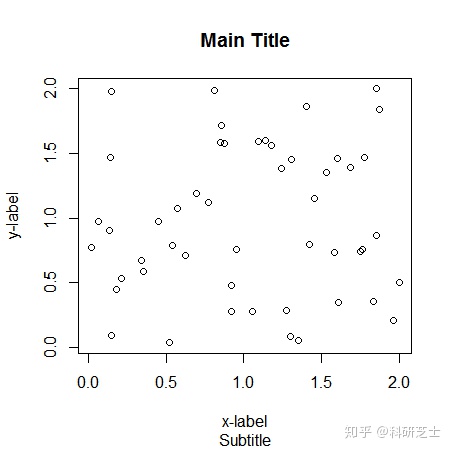
① 布局:R使用的图形模型中,通常含有的部分包括中央绘图区、坐标轴线、坐标轴数字、x-y轴标签、边界、标题、副标题、图例等等。
标准的x-y图的轴标签一般默认采用变量名,当然也可以在plot调用中覆盖标签,也可以增加进一步标题或者上方的主标题和底部的副标题。
> plot(height,weight)
> x<-runif(50,0,2)
> y<-runif(50,0,2)
> plot(x,y,main="Main Title",sub="Subtitle",xlab="x-label",ylab="y-label")
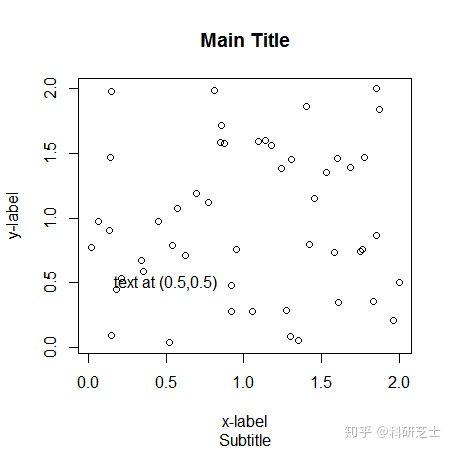
还可以在绘图区的内部,放置点和线,要么在plot()函数里设定,要么在后面用points和lines添加。同时也可以添加字符或数字文本。
> text(0.5,0.5,"text at (0.5,0.5)")
> abline(h=0.5,v=0.5)
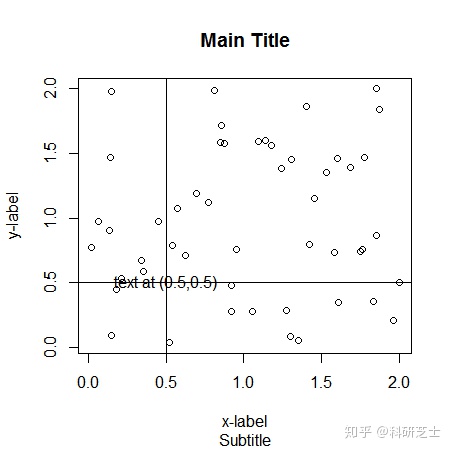
#Tips:这里调用abline()表示调取横坐标为0.5的垂直线和纵坐标为0.5的水平线,我们也可以用abline()来绘直线y=ax+b。比如> abline(1,0.5) 表示斜率为1,截距为0.5的直线。
边界信息由mtext()函数来填补,如:
> for(side in 1:4) mtext(-1:4,side=side,at=0.8,line=-1:4)
> mtext(paste("side",1:4),side=1:4,line=-1,font=2)
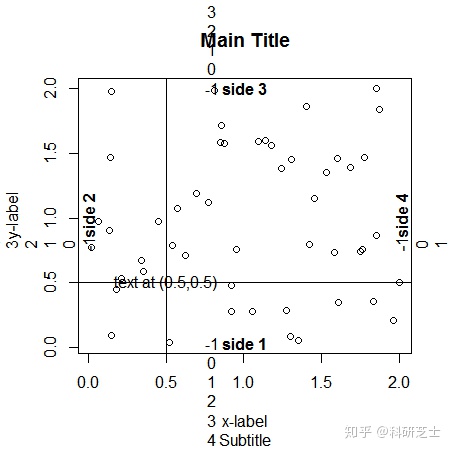
#Tips:for循环和mtext()里的side参数来调整填写的边,-1 :4是填写的内容,line=参数是调整文字离线的距离。at=用来调整具体坐标。font=2表示的是粗体字符。
② 逐步构造图形(引言里涉及这部分内容,我们来温习一下)
图形的每一部分都可以单独绘制,单独绘制图形通常允许对元素更加精确地控制,所以要达到给定效果的标准,可以先绘制不包括元素的图形(框架),随后在逐步添加元素。例如下面的空白图形构建:
> plot(x,y,type="n",xlab="",ylab="",axes=F)
#Tips:此处type=“n”,表示不绘制点,axes=F删掉坐标轴和周围的框,标题标签设置成空字符串。尽管什么也看不见,但是不代表程序什么也没做,命令已经指定了绘图区域和坐标系统,只是没有展示出来而已。
下面我们开始为我们的空白画板添加元素:
> points(x,y)
> axis(1)
> axis(2,at=seq(0.2,2.0,0.2))
> box()
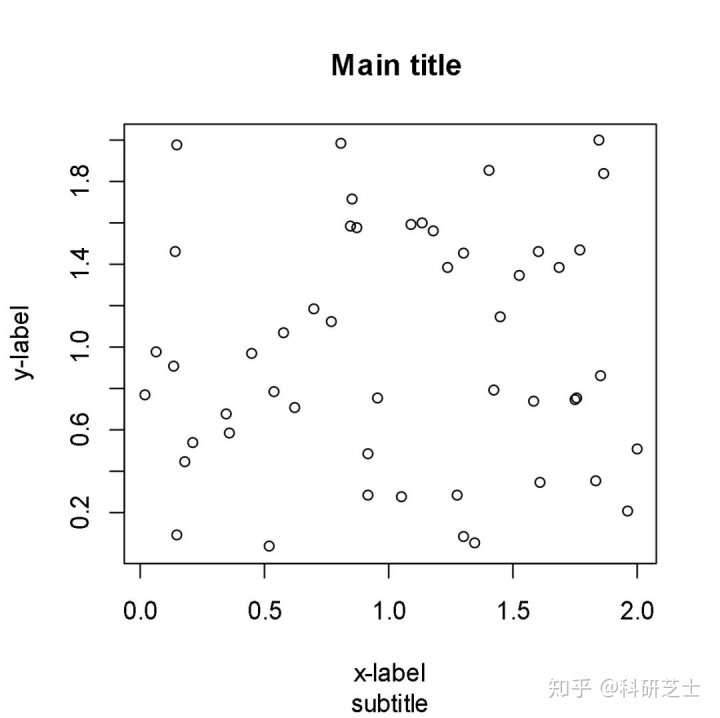
> title(main="Main title",sub="subtitle",xlab="x-label",ylab="y-label")


③ par的使用
函数par()可以对图的细节进行非常精细的控制,但是对于初学者来说比较难掌握,需要反复练习强化。
Par()设置允许控制线宽和类型、字符大小和字体、颜色、坐标轴的类型、图形图表区域的大小、图形的裁剪等。
这部分的内容等后续到作具体图形的地方,我们再来回头学习。
④ 组合图形
当希望把几个元素放到一张图上的时候,就有一些特殊的要求。如考虑为直方图叠加一个正态密度函数。下面的命令可以做出来我们想要的结果:
> x<-rnorm(100)
> hist(d,freq=F)
> curve(dnorm(x),add=T)
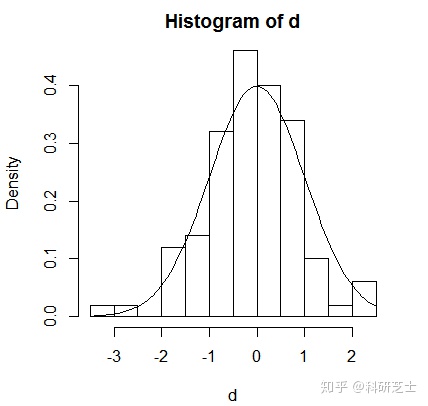
#Tips:hist()里的freq=F保证了直方图是根据概率密度而不是实际值画出来的分布曲线,rnorm()是产生随机数,dnorm()是密度函数【关于概率与分布的部分详见番外二】。add=T表示允许叠加到已有图形上。
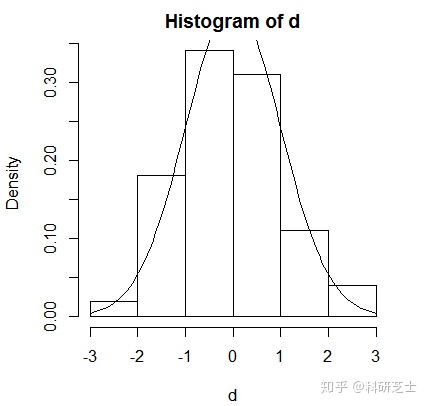
但是也会出现右图的结果,曲线没有完整地展现出来,密度函数的顶部被切去一部分。因为我们是在直方图的范围里添加的曲线,直方图的y轴上限值小于密度函数的最高点。但是,如果我们换一下顺序,先画出密度函数再做直方图也不行,因为有可能直方图顶端被切除。我们可以先去获得两个图形的最高点,然后把作图区域的扩大到容纳最高点为止:
> h<-hist(x,plot=F)
> ylim<-range(0,h$density,dnorm(0))
> hist(x,freq=F,ylim=ylim)
> curve(dnorm(x),add=T)
#Tips:调用hist时,如果plot=F,将不会画出任何图形,但是会返回一个以比例尺度表示的直方图高度的结构。此外,结合它以及dnorm(x)的最大值为dnorm(0)的事实,我们就可以计算出来包含直方图和密度图的作图的y轴范围。range调用中的0保证了条形的底部也在范围内。y值的范围通过ylim参数传递到hist()函数中。
这一部分暂时先告一段落,在这部分里,大家了解了R语言环境中的变量、脚本的使用和一些便利性简单操作,以及图形基础,下个部分我们会接触到R语言的流程控制、编码和数据读入、转换和保存等操作,敬请期待。


)
——代理模式(Proxy Pattern))

)


![Hibernate3 jar包的作用[转]](http://pic.xiahunao.cn/Hibernate3 jar包的作用[转])

的详细介绍以及推导算法)

)





函数用法)
