InnoDB引擎:
提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别
提供了行级锁和外键约束。
它的设计的目标是处理大容量数据库系统,用于缓冲数据和索引。
不支持FULLTEXT类型的数据,没有保存表的行数,当select count(*) from table 时需要扫描全表。
使用数据库事务时,该引擎是首选。
由于锁的粒度更小,写操作不会锁定全表,所以在并发较高时,使用InnoDB效率会提升。
行级锁也不是绝对的, 如果只在执行一个SQL语句时不能确定要扫描的范围,InnoDB同样会锁定全表。
MyIASM引擎:
没有提供对数据库事务的支持,也不支持行级锁和外键
因此在insert 或update时需要锁定全表,效率会降低。
存储了表的行数,当select count(*) from table 时只需要直接读取已经保存好的值而不用扫描全表。
如果读操作远远多于写操作且不需要数据库事务的支持,那么MyIASM也是很好的选择。
两种引擎的比较:
大尺寸的数据集趋向于选择InnoDB引擎,因为它支持事务处理和故障恢复。数据库大小决定了故障恢复的时间长短。InnoDB引擎可以利用事务日志进行数据恢复。
主键查询在InnoDB引擎下会相当快
大批量的insert语句(在每个insert语句中写入多行,批量插入)在MyISAM下会快一点。
Update语句在InnoDB下会更快一点。
数据结构:
B-Tree:
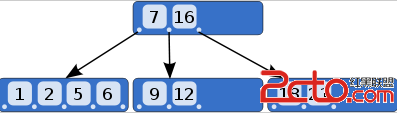
每个节点最多可以有d个分支,d成为B-Tree的度
B-Tree中的元素都是有序的,比如图中元素7左边的指针指向的节点中的元素都小于7,而元素7和16之间的指针指向的结点中的元素都处于7和16之间。正是满足这样的关系,才能实现高效的查找:首先从根节点进行二分查找,找到就返回对应的值,否则就进入相应的区间结点递归查找,直到找到对应的元素或找到null指针,找到null指针则表示查找失败。时间复杂度为O(logN).
B+Tree:
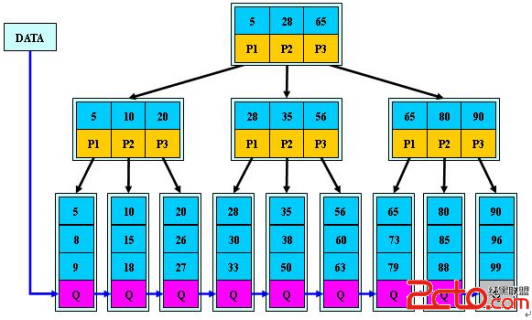
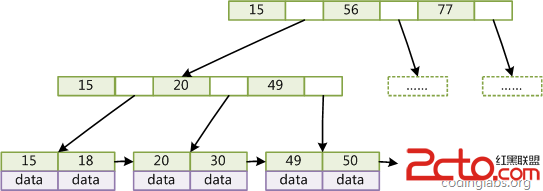
B+tree内部节点不存储数据,只存储指针,而叶子节点则只存储数据,不存储指针。
MyISAM的 B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的地址。
InnoDB引擎的索引结构同样是B+Tree,但InnoDB的索引文件本身就是数据文件,即B+Tree的数据区域存储的就是实际的数据,这种索引就是聚簇索引。
聚簇索引的数据的物理结构存放顺序与索引顺序是一致的,即:只要索引的事相邻的,那么对应的数据一定也是相邻地存放在磁盘上。
—— 多态)
![[转]c++类的构造函数详解](http://pic.xiahunao.cn/[转]c++类的构造函数详解)



![datatable绑定comboBox显示数据[C#]](http://pic.xiahunao.cn/datatable绑定comboBox显示数据[C#])
——堆区内存开辟数组和二级指针)



—— Lambda表达式的应用)




—— 容器和容器适配器)
)


