任务场景
- Photos to semantic segmentation
- Cityscapes labels to photos
- Colorization
- Facades labels to photo
- Day to night
- The edges to photo
- And so on.
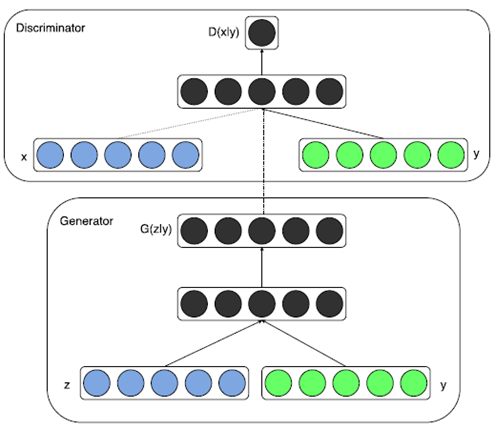
在生成器模型中,条件变量y实际上是作为一个额外的输入层(additional input layer),它与生成器的噪声输入p(z)组合形成了一个联合的隐层表达;
在判别器模型中,y与真实数据x也是作为输入,并输入到一个判别函数当中。实际上就是将z和x分别于y进行concat,分别作为生成器和判别器的输入,再来进行训练。
目标函数:
gans:
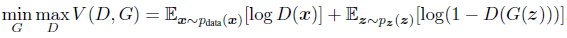
CGAN:
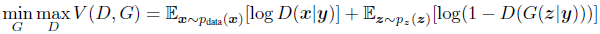
pix-2-pix:
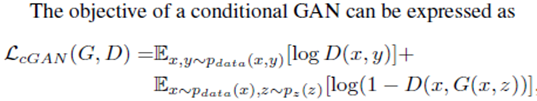
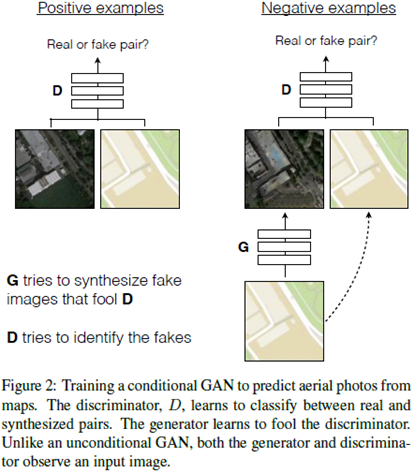
把待转换的图像x作为额外的输入,分别加进判别器和生成器中。生成器输入的是随机噪声z以及待转换的图像x。
在positive情况下,判别器输入的是待转换图像x以及与x对应的真实数据y,这时判别器尽量使得输出为1;
在negative情况下,判别器输入的是待转换图像x以及生成器生成的图像G(x,z)。也就是说,生成器不只输入了随机噪声z,还输入了待转换图像x,加入了这个条件,就可以实现定向生成;
判别器也不再只是判别某一张图像是否真实,而是判别待转换图像x与转换后图像G(x,z)是否是真实的图像对。
创新点
1、加入约束项(L1 distance encourages less blurring) ---- 生成的图像是不是接近GT。
与L2相比,文章采用了模糊更少的L1 distance(1范数可以导致稀疏解,2范数导致稠密解):
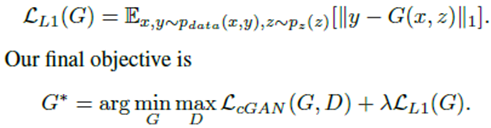
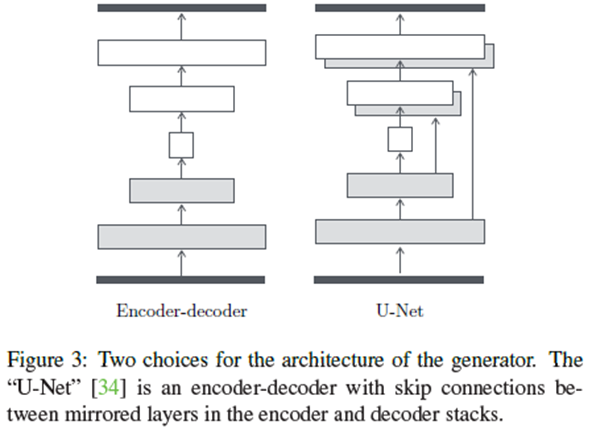
2、generator add skip connections(U-Net)
图像到图像转换问题的一个特征定义是将高分辨率输入网格映射到高分辨率输出网格。输入和输出的表面外观虽不同,但两者都是相同底层结构的渲染。因此,生成器的设计中输入的结构大致与输出的结构对齐。
之前的结构都是基于如下图的编码-解码网络,先经过几个降采样层,到达一个瓶颈后经过一个逆过程得到最终的输出。网络要求所有的信息流通过网络的所有层。对于许多图像翻译问题,输入和输出之间共享了大量低级别的信息,因此最好将这些信息直接穿过网络。为了使得生成器能够规避这样的信息瓶颈,遵循“U-Net”的形状,添加跳跃连接。假使网络有n层,网络的第i层都和n-i层有一个连接:
3.patchGAN
通常判断都是对生成样本整体进行判断,比如对一张图片来说,就是直接看整张照片是否真实。而且Image-to-Image Translation中很多评价是像素对像素的,所以在这里提出了分块判断的算法,在图像的每个N×N块上去判断是否为真,最终平均给出结果。
判别器在图像上卷积,最终平均所有的值作为D的最终输出值;
N可以比图像的大小小得多,并且效果仍然很好;
小的patchGAN的参数更少,运行更快,并且能够应用到任意大小的图像中。。
当n=1时就是pix-2-pix
Optimization and inference

扩展
L0范数是指向量中非0的元素的个数
L1范数是指向量中各个元素绝对值之和
L2范数是指向量各元素的平方和然后求平方根。
在机器学习中,以0范数和1范数作为正则项,可以求得稀疏解,但是0范数的求解是NP-hard问题; 以2范数作为正则项可以得到稠密解,并且由于其良好的性质,其解的定义很好,往往可以得到闭式解,所以用的很多。
一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。L1在特征选择时候非常有用,而L2就只是一种规则化而已。
- L0 w分量尽量稀疏 如 (0,a,0,0,b,0,0)
- L1 效果同上
- L2 w分量取值尽量均衡、稠密,即小而趋近于0 如(0.3,0.5,-0.3,0.1,-0.2,0.3,-0.3)












![[转]MySQL日志——Undo | Redo](http://pic.xiahunao.cn/[转]MySQL日志——Undo | Redo)

![[DP/单调队列]BZOJ 2059 [Usaco2010 Nov]Buying Feed 购买饲料](http://pic.xiahunao.cn/[DP/单调队列]BZOJ 2059 [Usaco2010 Nov]Buying Feed 购买饲料)




