论文信息:
题目:A Survey of Embodied AI: From Simulators to Research Tasks
作者:Jiafei Duan, Samson Yu
来源:arXiv
时间:2022
Abstract
通过评估当前的九个具体人工智能模拟器与我们提出的七个功能,本文旨在了解模拟器在具体人工智能研究中的使用及其局限性。
本文调查了实体人工智能的三个主要研究任务——视觉探索、视觉导航和实体问答(QA),涵盖了最先进的方法、评估指标和数据集。最后,通过对该领域的调查所揭示的新见解,本文将为任务选择模拟器提供建议,并对该领域的未来方向提出建议。
Introduction
本文涵盖了过去四年中开发的以下九个具体人工智能模拟器:DeepMind Lab [12]、AI2-THOR [13]、CHALET [14]、VirtualHome [15]、VRKitchen [16]、Habitat-Sim [ 17]、iGibson [18]、SAPIEN [19] 和 ThreeDWorld [20]。所选择的模拟器是为通用智能任务而设计的,与仅用于训练强化学习代理的游戏模拟器[21]不同。这些具体化的人工智能模拟器在计算机模拟中提供了现实世界的真实再现,主要采用对环境提供某种形式约束的房间或公寓的配置。这些模拟器中的大多数至少包含物理引擎、Python API 和可以在环境中控制或操作的人工代理。
Simulators for Embodied AI
Embodied AI Simulators
在本节中,本文将根据七个技术特征对九个具体的人工智能模拟器进行全面比较。
参考[13]、[20]、[31],这七个技术特征被选为评估具体人工智能模拟器的主要特征,因为它们涵盖了准确复制物理世界的环境、交互和状态所需的基本方面,因此,为通过实施例测试智力提供了合适的测试平台。参见表I,这七个特征是:环境、物理、对象类型、对象属性、控制器、动作和多代理
(Environment, Physics, Object Type, Object Property, Controller, Action, and Multi-Agent)
Environment
构建实体AI模拟器环境的方法主要有两种:基于游戏的场景构建(G)和基于世界的场景构建(W)。
参考图 1,
基于游戏的场景是根据 3D assets 构建的,而基于世界的场景是根据对象和环境的现实世界扫描构建的。完全由 3D assets 构建的 3D 环境通常具有内置的物理特征和对象类,与通过真实世界扫描创建的环境的 3D 网格相比,这些特征和对象类被很好地分段。 3Dassets 的清晰对象分割使得可以轻松地将它们建模为具有可移动关节的铰接对象,例如 PartNet [32] 中提供的 3D 模型。
相比之下,对环境和对象的现实世界扫描提供了更高的保真度和更准确的现实世界表示,有助于更好地将代理性能从模拟转移到现实世界。

如表1所示,除了 Habitat-Sim 和 iGibson 之外,大多数模拟器都具有基于游戏的场景,因为基于世界的场景构建需要更多的资源
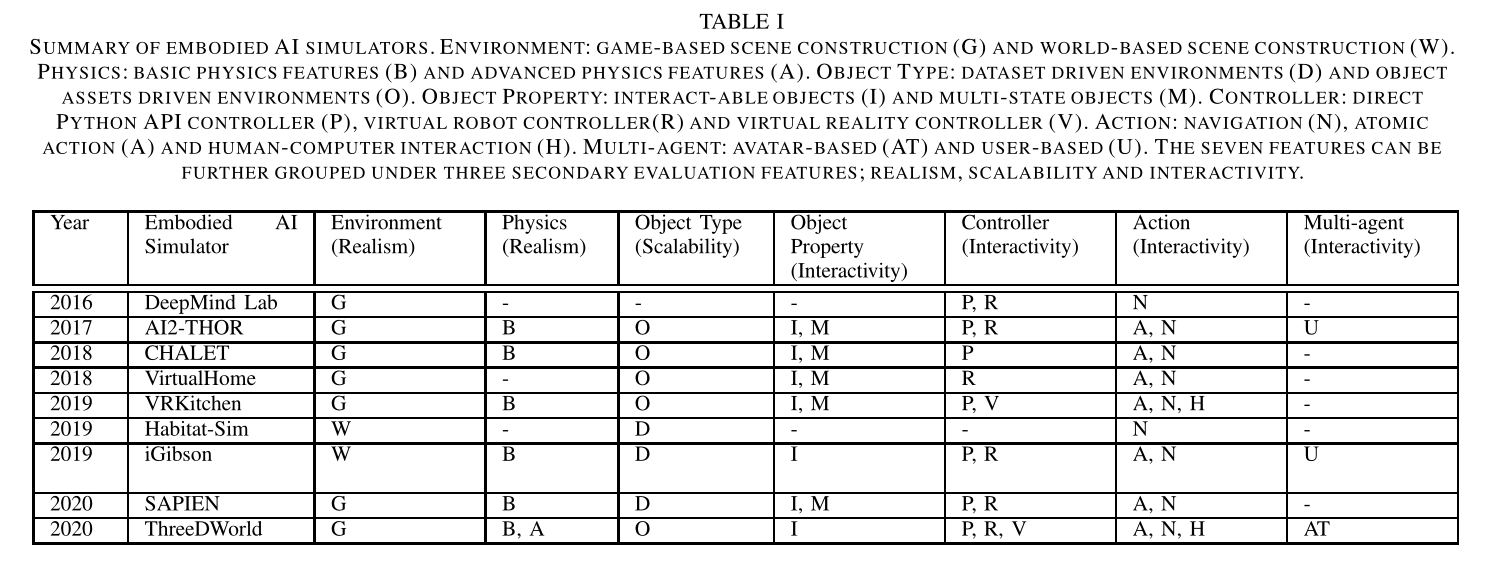
Physics
模拟器不仅必须构建真实的环境,还必须构建代理与对象或对象与对象之间的真实交互,以模拟真实世界的物理属性。我们研究模拟器的物理特征,我们将其大致分为基本物理特征(B)和高级物理特征(A)
参见图2,基本物理特征包括碰撞、刚体动力学和重力建模,而高级物理特征包括布料、流体和软体物理。
由于大多数具体的人工智能模拟器都使用内置物理引擎构建基于游戏的场景,因此它们配备了基本的物理功能。另一方面,对于像 ThreeDWorld 这样的模拟器,其目标是了解复杂的物理环境如何影响环境中的人工智能体的决策,它们配备了更先进的物理功能。
Object Type
如图 3 所示,用于创建模拟器的对象有两个主要来源。
第一类是数据集驱动环境,其中对象主要来自现有对象数据集,例如 SUNCG [33] 数据集、Matterport3D 数据集 [34] 和 Gibson 数据集 [35]。
第二种是assets 驱动环境,其中的对象来自网络,例如Unity 3D游戏资产商店。

两个来源之间的区别在于对象数据集的可持续性。数据集驱动对象的收集成本比asset 驱动对象的成本更高,因为任何人都可以在线为 3D 对象模型做出贡献。然而,与数据集驱动对象相比,确保资产驱动对象中 3D 对象模型的质量更困难。
Object Property
一些模拟器仅启用具有基本交互性(例如碰撞)的对象。高级模拟器使对象具有更细粒度的交互性,例如多状态变化。
例如,当一个苹果被切片时,它会发生状态转变为苹果片。
因此,我们将这些不同级别的对象交互分为具有**可交互对象(I)和多状态对象(M)**的模拟器。
参考表I,一些模拟器,例如AI2-THOR和VRKitchen,可以实现多种状态变化,为理解对象在现实世界中受到作用时如何反应和改变其状态提供了一个平台。
Controler
参考图4,用户和模拟器之间有不同类型的控制器接口,从直接Python API控制器(P)和虚拟机器人控制器(R)到虚拟现实控制器(V)。

机器人实施例允许与现有的现实世界机器人(例如 Universal Robot 5 (UR5) 和 TurtleBot V2)进行虚拟交互,并且可以使用 ROS 接口直接控制。虚拟现实控制器界面提供更加身临其境的人机交互,并方便使用现实世界的对应设备进行部署。例如,iGibson 和 AI2-THOR 等模拟器主要是为视觉导航而设计的,它们也配备了虚拟机器人控制器,以便于分别在 iGibson 的 Castro [36] 和 RoboTHOR [37] 等现实世界的模拟器中部署。
Action
本文将机器人操作分为三个层次:导航 Navigation(N)、原子动作 atomic action(A)和人机交互 human-computer interaction(H)。
- 导航是最低层,是所有具体人工智能模拟器的常见功能[38]。它是由代理在其虚拟环境中导航的能力定义的。
- 原子动作为人工智能体提供了一种对感兴趣的对象执行基本离散操作的方法,并且在大多数具体的人工智能模拟器中都可以找到。
- 人机交互是虚拟现实控制器的结果,因为它使人类能够控制虚拟代理实时学习并与模拟世界交互[16]。
大多数基于导航的大型模拟器,例如 AI2-THOR、iGibson 和 HabitatSim,往往具有导航、原子动作和 ROS [13]、[17]、[35],这使它们能够提供更好的对象控制和操作在执行点导航或对象导航等任务时。
另一方面,ThreeDWorld 和 VRKitchen [16]、[20] 等模拟器属于人机交互类别,因为它们的构建是为了提供高度真实的基于物理的模拟和多种状态变化。这只有通过人机交互才能实现,因为与这些虚拟对象交互时需要人类水平的灵活性。
Multi-agent
一般来说,在构建用于人工智能体的对抗性和协作性训练[39]、[40]的多智能体特征之前,模拟器需要具有丰富的对象内容。由于缺乏多代理支持的模拟器,利用这些具体人工智能模拟器中的多代理功能的研究任务较少。
对于基于多智能体强化学习的训练,目前仍在 OpenAI Gym 环境中进行 [41]。有两种不同的多代理设置。
- 第一个是 ThreeDWorld [20] 中基于化身 (AT) 的多智能体,它允许人工智能体和模拟化身之间进行交互。
- 第二个是AI2THOR [13]中基于用户(U)的多智能体,它可以扮演对偶学习网络的角色,并从模拟中与其他人工智能体的交互中学习以实现共同任务[42]
Comparision of Embodied AI Simulators
基于这七个特征以及艾伦人工智能研究所 [31] 关于体现人工智能的研究,我们提出了模拟器的第二组评估特征。它包含三个关键特征:真实性、可扩展性和交互性
如表 I 所示。3D 环境的真实性可归因于模拟器的环境和物理特性。环境模拟现实世界的物理外观,而物理模拟现实世界中复杂的物理属性。 3D 环境的可扩展性可归因于对象类型。
Research in Embodied AI
具身人工智能研究任务的三种主要类型是视觉探索、视觉导航和具身问答。
我们将重点关注这三个任务,因为大多数现有的嵌入式人工智能论文要么关注这些任务,要么利用为这些任务引入的模块来为更复杂的任务(如视听导航)构建模型。
我们将从视觉探索开始,然后转向视觉导航,最后实施 QA。这些任务中的每一个都构成了下一个任务的基础,形成了如图5所示的体现人工智能研究任务的金字塔结构,进一步暗示了体现人工智能的自然方向。

Visual Exploration
在视觉探索 [24]、[68] 中,代理通常通过运动和感知来收集有关 3D 环境的信息,以更新其环境的内部模型 [11]、[22],这可能对下游任务有用,例如视觉导航[24],[25],[69]。
目的是尽可能高效地完成此操作(例如,使用尽可能少的步骤)。
内部模型可以采用拓扑图[26]、语义图[46]、占用图[45]或空间记忆[70]、[71]等形式。这些基于地图的架构可以捕获几何和语义,与反应性和循环神经网络策略[72]相比,可以实现更有效的策略学习和规划[45]。
视觉探索通常在导航任务之前或同时进行。
- 在第一种情况下,视觉探索将内部记忆构建为先验,这对于下游导航任务中的路径规划很有用。在开始导航之前,代理可以在一定的预算(例如有限的步数)内自由地探索环境[11]。
- 在后一种情况下,代理在导航看不见的测试环境时构建地图[48]、[73]、[74],这使得它与下游任务更紧密地集成。
Aproaches
在本节中,视觉探索中的非基线方法通常被形式化为部分观察的马尔可夫决策过程(POMDP)[77]。 POMDP 可以用 7 元组(S、A、T、R、Ω、O、γ)表示,其中状态空间 S、动作空间 A、转移分布 T 、奖励函数 R、观察空间 Ω、观察分布 O 和折扣因子 γ ∈ [0, 1]。一般来说,这些方法被视为 POMDP 中的特定奖励函数
-
基线(Baselines):视觉探索有一些共同的基线[22]。对于rand-actions [17],代理从所有动作的均匀分布中进行采样。对于forward-action,它总是选择前向动作。对于forward-action+,代理选择前进动作,但如果发生碰撞则向左转。
-
好奇心(Curiosity):在好奇心方法中,智能体寻找难以预测的状态。预测误差用作强化学习的奖励信号[79]、[80]。
这侧重于内在奖励和动机,而不是来自环境的外部奖励,这在外部奖励稀疏的情况下是有益的[81]。通常有一个最小化损失的前向动力学模型: L ( s ^ t + 1 , s t + 1 ) L(\hat{s}_{t+1}, s_{t+1}) L(s^t+1,st+1)。在这种情况下,如果智能体在状态 s t s_t st 时采取行动,则 s ^ t + 1 \hat{s}_{t+1} s^t+1 是预测的下一个状态,而 s t + 1 s_{t+1} st+1 是智能体最终将进入的实际下一个状态。
好奇心的实际考虑因素已在最近的工作[79],例如使用近端策略优化(PPO)进行策略优化。
在最近的工作中,好奇心已被用来生成更高级的地图,例如语义地图[43]。随机性对好奇心方法提出了严峻的挑战,因为前向动力学模型可以利用随机性[79]来实现高预测误差(即高回报)。这可能是由于“嘈杂的电视”问题或执行代理动作时的噪音等因素造成的[81]。
一种提出的解决方案是使用逆动力学模型[68],该模型估计智能体从先前状态 st−1 移动到当前状态 st 所采取的动作 at−1,这有助于智能体了解其动作可以做什么环境中的控制。虽然此方法尝试解决环境引起的随机性,但它可能不足以解决代理行为导致的随机性。 -
覆盖(Coverage):在覆盖方法中,智能体试图最大化其直接观察的目标数量 。
通常,这将是环境中看到的区域 [22]、[24]、[44]。由于代理使用以自我为中心的观察,因此它必须根据可能存在障碍的 3D 结构进行导航。
最近的一种方法结合了经典方法和基于学习的方法[44]。它使用分析路径规划器和学习的 SLAM 模块来维护空间地图,以避免训练端到端策略时涉及的高样本复杂性。该方法还包括噪声模型,以提高物理真实性,从而适用于现实世界的机器人技术。
最近的另一项工作是场景记忆变压器,它在其策略网络 [72] 中的场景记忆上使用改编自 Transformer 模型 [83] 的自注意力机制。场景内存嵌入并存储所有遇到的观察结果,与需要归纳偏差的类似地图的内存相比,具有更大的灵活性和可扩展性。 -
重建(Reconstruction):在重建方法中,智能体尝试从观察到的视图重新创建其他视图。
过去的工作重点是360 度全景图和 CAD 模型的像素级重建 [84]、[85],这些模型通常是人类拍摄照片的精选数据集 [45]。
最近的工作已将这种方法应用于实体人工智能,这种方法更加复杂,因为模型必须根据代理的自我中心观察和自身传感器的控制(即主动感知)来执行场景重建。
在最近的一项工作中,该代理使用其以自我为中心的 RGB-D 观察来重建可见区域之外的占用状态,并随着时间的推移汇总其预测以形成准确的占用图 [45]。占用预期是一项逐像素分类任务,其中相机前面的 V x V 个单元局部区域中的每个单元都被分配了被探索和占用的概率。与覆盖方法相比,预测占用状态允许代理处理不可直接观察的区域。
最近的另一项工作侧重于语义重建而不是像素级重建[22]。该代理旨在预测采样查询位置是否存在“门”等语义概念。使用 K 均值方法,查询位置的真正重建概念是与其特征表示最近的 J 个簇质心。如果代理获得有助于预测采样查询视图的真实重建概念的视图,它将获得奖励
Evaluation Metrics
访问的目标数量。考虑不同类型的目标,例如区域[44]、[86]和感兴趣的物体[72]、[87]。访问面积指标有几个变体,例如以 m2 为单位的绝对覆盖面积以及场景中探索的区域的百分比。
Impact on downstream tasks: 视觉探索性能还可以通过其对视觉导航等下游任务的影响来衡量。这种评估指标类别在最近的作品中更常见。利用视觉探索输出(即地图)的下游任务的示例包括图像导航[26]、[73]、点导航[11]、[44]和对象导航[53]、[54]、[56]。
Dataset
对于视觉探索,一些流行的数据集包括 Matterport3D 和 Gibson V1。 Matterport3D 和 Gibson V1 都是逼真的 RGB 数据集,其中包含深度和语义分割等对于具体 AI 有用的信息。
Habitat-Sim 模拟器允许使用这些具有额外功能(如可配置代理和多个传感器)的数据集。
Gibson V1 还通过交互和逼真的机器人控制等功能进行了增强,形成了 iGibson。
最近的 3D 模拟器(如第二节中提到的模拟器)都可以用于视觉探索,因为它们至少都提供 RGB 观察。
Visual Navigation
在视觉导航中,智能体在有或没有外部先验或自然语言指令的情况下,在 3D 环境中导航至目标。
许多类型的目标已用于此任务,例如点Point、对象object、图像images、区域area。
在本文中,我们将重点关注点和对象作为视觉导航的目标,因为它们是最常见和基本的目标。它们可以进一步与感知输入和语言等规范相结合,以构建更复杂的视觉导航任务,例如先验导航、视觉和语言导航甚至embodied QA。在点导航[49]下,代理的任务是导航到特定点,而在对象导航[38]、[52]中,代理的任务是导航到特定类的对象。
最值得注意的挑战是 iGibson Sim2Real 挑战、Habitat 挑战 [36] 和 RoboTHOR 挑战。
对于每个挑战,我们将描述 2020 版本的挑战,这是截至本文的最新版本。在所有三个挑战中,智能体都仅限于以自我为中心的 RGB-D 观察。
2020 年 iGibson Sim2Real Challenge 的具体任务是点导航。 73 个高质量的 Gibson 3D 场景用于训练,而 Castro 场景(真实世界公寓的重建)将用于训练、开发和测试。存在三种情况:当环境没有障碍物时、包含代理可以与之交互的障碍物时、和/或填充有其他移动代理时。
2020 年栖息地挑战赛既有点导航任务,也有物体导航任务。具有 Gibson 数据集分割的 Gibson 3D 场景用于点导航任务,而具有由原始数据集 [11]、[34] 指定的 61/11/18 训练/验证/测试室分割的 90 个 Matterport3D 场景用于对象导航任务。
2020 年 RoboTHOR 挑战赛只有物体导航任务。培训和评估分为三个阶段。在第一阶段,代理在 60 套模拟公寓上进行训练,并在其他 15 套模拟公寓上验证其性能。在第二阶段,智能体将在四个模拟公寓及其现实世界的对应公寓上进行评估,以测试其对现实世界的泛化能力。在最后阶段,代理将在 10 套真实世界的公寓中进行评估
Categories
Point Navigation
在点导航中,智能体的任务是导航到距特定点一定固定距离内的任何位置[11]。
通常,代理在环境中的原点 (0, 0, 0) 处初始化,固定目标点由相对于原点/初始位置的 3D 坐标 (x, y, z) 指定[11]。为了成功完成任务,人工智能体需要具备多种技能,例如视觉感知、情景记忆构建、推理/规划和导航。
代理通常配备 GPS 和指南针,使其能够访问其位置坐标,并隐式地获取其相对于目标位置的方向 [17]、[49]。目标的相对目标坐标可以是静态的(即仅在程序开始时给出一次)或动态的(即在每个时间步给出)[17]。最近,由于室内环境中的定位不完善,Habitat Challenge 2020 已转向更具挑战性的任务 [47],即无需 GPS 和指南针的基于 RGBD 的在线定位。
Object Navigation
对象导航侧重于在未探索的环境中导航到由其标签指定的对象的基本思想[38]。
代理将在随机位置初始化,并负责在该环境中查找对象类别的实例。对象导航通常比点导航更复杂,因为它不仅需要许多相同的技能,例如视觉感知和情景记忆构建,还需要语义理解。这些使得对象导航任务更具挑战性,但解决起来也很有价值。
Navigation with Priors
先验导航侧重于以多模态输入(例如知识图或音频输入)的形式注入语义知识或先验的想法,或者帮助在可见和不可见的环境中训练具体人工智能代理的导航任务。过去的工作[57]使用人类先验知识集成到深度强化学习框架中,表明人工智能体可以利用类似人类的语义/功能先验来帮助代理学习在看不见的环境中导航和找到看不见的物体。
Vision-and-Language Navigation(VLN)
视觉和语言导航(VLN)是一项任务,智能体通过遵循自然语言指令学习在环境中导航。这项任务的挑战性在于依次感知视觉场景和语言。
VLN 仍然是一项具有挑战性的任务,因为它要求智能体根据过去的动作和指令来预测未来的动作 [11]。此外,代理可能无法将其轨迹与自然语言指令无缝对齐。尽管视觉和语言导航和视觉问答 (VQA) 看起来很相似,但这两项任务存在重大差异。这两项任务都可以表述为基于视觉的序列到序列转码问题。然而,与输入单个输入问题并生成答案的 VQA 相比,VLN 序列要长得多,并且需要不断输入视觉数据以及操纵相机视点的能力。
Evaluation Metrics
评估指标:视觉导航使用(1)按(归一化逆)路径长度(SPL)加权的成功率和(2)成功率作为主要评估指标[11]。
(它这里总结得不够好,建议直接看相关论文给的指标)
Dataset
与视觉探索一样,Matterport3D和Gibson V1是最流行的数据集。值得注意的是,Gibson V1 中的场景较小,并且通常具有较短的剧集(从起始位置到目标位置的 GDSP 较低)。
还使用 AI2-THOR 模拟器/数据集 与其他视觉导航任务不同,VLN 需要不同类型的数据集。大多数 VLN 作品使用 Room-to-Room (R2R) 数据集和 Matterport3D Simulator [104]。它由21,567条导航指令组成,平均长度为29个单词。在视觉对话导航[59]中,使用协作视觉与对话导航(CVDN)[105]数据集。它包含 Matterport3D 模拟器内的 2,050 个人与人之间的对话和 7,000 多个轨迹。
Embodied Question Answering
(这部分暂时不多关注)
Insight and Challenges
Insight into Embodied AI
图 6 中的互连反映了模拟器对研究任务的适用性。基于图6,Habitat-Sim和iGibson都支持视觉探索和一系列视觉导航任务中的研究任务,表明来自基于世界的场景模拟器的高保真度的重要性。
然而,由于其独特的功能使其更适合非实体人工智能独立任务(例如深度强化学习),因此一些模拟器目前无法连接到任何实体研究任务。
尽管如此,它们仍然符合被归类为嵌入式人工智能模拟器的标准。
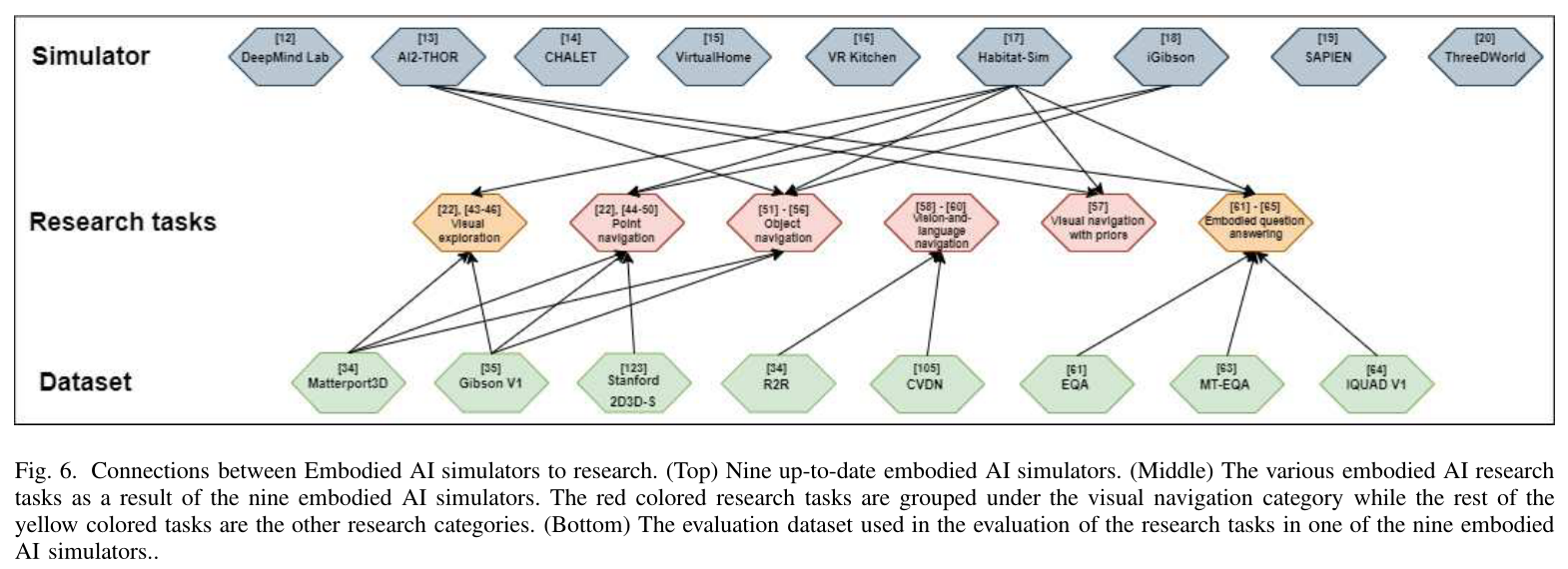
另一方面,由于这些任务的交互性质,诸如具体问答和先验视觉导航等研究任务将要求具体人工智能模拟器具有多状态对象属性。因此,AI2-THOR无疑是首选模拟器。最后,VLN 是目前唯一不使用九个具体 AI 模拟器中任何一个而是使用 Matterport3D Simulator 的研究任务 [104]。这是因为VLN之前的工作并不需要其模拟器具有交互性的特征;因此 Matterport3D 模拟器就足够了。然而,随着VLN任务的推进,我们可以预见VLN任务中需要交互,因此需要使用嵌入式AI模拟器。此外,与传统的强化学习模拟环境[41]不同,[109]专注于特定任务的训练,而具体化的人工智能模拟器提供了一个训练环境,用于训练类似于物理世界中进行的各种不同任务。
Challenges in Embodied AI Simulators
当前的具体人工智能模拟器在功能和保真度方面都达到了一定水平,这使它们与用于强化学习的传统模拟区分开来。尽管实体人工智能模拟器的差异如此之大,但实体人工智能模拟器在真实性、可扩展性和交互性等领域仍存在一些挑战。
尽管需要一种先进的基于物理的具体人工智能模拟器,但目前只有一个模拟器,即 ThreeDWorld [20] 符合这一标准。因此,严重缺乏具有高级物理特性(例如布料、流体和软体物理)的实体人工智能模拟器。我们相信 3D 重建技术和物理引擎 [117]-[119] 的进步将提高人工智能的真实性。
希望随着基于 3D 学习的方法 [126]、[127](旨在从单个或几个图像甚至通过场景生成方法 [128] 渲染 3D 对象网格)的进一步发展,我们将能够扩大大规模 3D 数据集的收集过程。
毫无疑问,AI2-THOR[13]、iGibson[18]和Habitat-Sim[17]等主流模拟器确实为推进各自的具体人工智能研究提供了良好的环境。然而,它们确实有其优点和局限性需要克服。随着计算机图形学和计算机视觉的发展,以及创新的现实世界数据集的引入,真实到模拟领域的适应是改进嵌入式人工智能模拟器的明确途径之一。真实到模拟的概念围绕着捕捉现实世界的信息,例如触觉感知[131]、人类水平的运动控制[132]和音频输入[133]以及视觉感官输入,并将它们集成以开发更真实的人工智能模拟器,可以有效地连接物理世界和虚拟世界。
Challenges in Embodied AI Research
具身人工智能研究任务标志着从“互联网人工智能”到具有多种传感器模式和潜在长轨迹的 3D 模拟环境中的自主具身学习代理的复杂性的增加 [22]、[34]。这导致智能体的记忆和内部表征变得极其重要[11]、[22]、[56]。长轨迹和多种输入类型也表明了强大的内存架构的重要性,它允许代理专注于其环境的重要部分。近年来,出现了许多不同类型的记忆,例如循环神经网络[47]、[49]、[51]、[56]、[58]、[61]-[63]、基于注意力的记忆网络内存架构,[52],[60],[72],预期占用图[45],占用图[22]和语义图[43],[46],[48],[64],[65],有些论文非常强调其内存架构的新颖性[22]、[45]、[60]、[72]。然而,虽然众所周知,循环神经网络在捕捉具体人工智能的长期依赖性方面受到限制[56]、[72],但由于缺乏记忆类型,目前仍然很难就哪种记忆类型更好[11]达成一致。专注于内存架构的工作。
在具体化人工智能研究任务中,复杂性也有所增加,从视觉探索到 VLN 和具体化 QA 的进展就可以看出,其中分别添加了语言理解和 QA 等新组件。
每个新组件都会导致人工智能代理的训练难度和时间呈指数级增长,特别是因为当前的方法通常完全基于学习。这种现象带来了两项有希望的进展,以减少搜索空间和样本复杂性,同时提高鲁棒性:结合经典和基于学习的算法的混合方法[44],[74]和先验知识合并[23],[57]。
对于更复杂的任务,消融研究更难管理[31],因为具体化人工智能中的每个新组件都使其更难测试其对代理性能的贡献,因为它被添加到现有的组件集上,并具体化人工智能模拟器在功能和问题上存在很大差异。研究任务的数量也迅速增加,这一事实使情况变得更加复杂。
最后,缺乏对多智能体设置的关注,而多智能体设置提供了有用的新任务[65]。这种缺乏关注的原因可以归因于直到最近还缺乏具有多代理功能的模拟器。用于协作和通信的多智能体系统在现实世界中很普遍[134]、[135],但目前受到的关注相对较少[31]。随着最近具有多智能体功能的模拟器的增加[13]、[20]、[55],多智能体支持(例如对多智能体算法的支持)是否足够还有待观察。
添加工具箱TooLbox的方法-以GPOPS为例)

)
)















