前言
上一篇博客介绍的是构建简单的CNN去识别手写数字,这一篇博客折腾一下自编码,理论很简单,就是实现对输入数据的重构,具体理论可以看我前面的【theano-windows】学习笔记十三——去噪自编码器
国际惯例,参考博客:
当我们在谈论 Deep Learning:AutoEncoder 及其相关模型
Autoencoders
训练代码实现
不说理论了,直接撸代码,包含两个隐层,因此网络的结构为四层:
单元数为784784的输入层→→单元数为256256的第一个隐层→→单元数为128128的第二个隐层→→单元数为784的重构输出层
接下来按照老样子构建整个训练流程:
读数据→→初始化相关参数→→定义接收数据的接口以便测试使用→→初始化权重和偏置→→定义基本模块(编码和解码)→→构建模型(先编码再解码)→→定义预测函数、损失函数、优化器→→训练
有几点一定要注意:
- 一定要定义数据的输入接口,不然后期无法拿模型做预测
- 一定要记得构建预测函数用于后期的测试阶段使用,不要只记得定义损失函数
读数据
注意初始化直接将所有像素除以255255,这与前面一篇博客不同
IMG_HEIGHT=28
IMG_WIDTH=28
CHANNELS=3
#读取数据集
def read_images(dataset_path,batch_size):imagepaths,labels=list(),list()data=open(dataset_path,'r').read().splitlines()for d in data:imagepaths.append(d.split(' ')[0])labels.append(int(d.split(' ')[1]))imagepaths=tf.convert_to_tensor(imagepaths,dtype=tf.string)labels=tf.convert_to_tensor(labels,dtype=tf.int32)image,label=tf.train.slice_input_producer([imagepaths,labels],shuffle=True)image=tf.read_file(image)image=tf.image.decode_jpeg(image,channels=CHANNELS)image=tf.image.rgb_to_grayscale(image) image=tf.reshape(image,[IMG_HEIGHT*IMG_WIDTH])image=tf.cast(image,tf.float32)image = image / 255.0image=tf.convert_to_tensor(image)inputX,inputY=tf.train.batch([image,label],batch_size=batch_size,capacity=batch_size*8,num_threads=4)return inputX,inputY初始化相关参数
learning_rate=0.01#学习率
num_steps=30000#训练次数
batch_size=256#每批数据大小
disp_step=1000#每迭代多少次显示训练日志
num_class=10#总类别
num_hidden1=256#第一层隐单元数
num_hidden2=128#第二层隐单元数
num_input=IMG_HEIGHT*IMG_WIDTH#输入、输出单元数定义数据接收接口
#定义输入接口
X=tf.placeholder(tf.float32,[None,num_input],name='X')初始化权重和偏置
#权重
weights={'encoder_h1':tf.Variable(tf.random_normal([num_input,num_hidden1])),'encoder_h2':tf.Variable(tf.random_normal([num_hidden1,num_hidden2])),'decoder_h1':tf.Variable(tf.random_normal([num_hidden2,num_hidden1])),'decoder_h2':tf.Variable(tf.random_normal([num_hidden1,num_input]))
}
#偏置
biases={'encoder_b1':tf.Variable(tf.random_normal([num_hidden1])),'encoder_b2':tf.Variable(tf.random_normal([num_hidden2])),'decoder_b1':tf.Variable(tf.random_normal([num_hidden1])),'decoder_b2':tf.Variable(tf.random_normal([num_input]))
}定义基本模块
#编码器
def encoder(x):layer1=tf.nn.sigmoid(tf.add(tf.matmul(x,weights['encoder_h1']),biases['encoder_b1']))layer2=tf.nn.sigmoid(tf.add(tf.matmul(layer1,weights['encoder_h2']),biases['encoder_b2']))return layer2
def decoder(x):layer1=tf.nn.sigmoid(tf.add(tf.matmul(x,weights['decoder_h1']),biases['decoder_b1']))layer2=tf.nn.sigmoid(tf.add(tf.matmul(layer1,weights['decoder_h2']),biases['decoder_b2']))return layer2构建模型
#构建模型
encoder_op=encoder(X)
decoder_op=decoder(encoder_op)定义预测函数、损失函数、优化器
#预测函数
y_pred=decoder_op
y_true=X
tf.add_to_collection('recon',y_pred)
#定义损失函数和优化器
loss_op=tf.reduce_mean(tf.pow(y_true-y_pred,2))
optimizer=tf.train.RMSPropOptimizer(learning_rate=learning_rate).minimize(loss_op)开始训练模型并保存结果
记得先初始化所有变量
#参数初始化
init=tf.global_variables_initializer()
input_image,input_label=read_images('./mnist/train_labels.txt',batch_size)然后就可以训练了,每次从队列中取数据
#开始训练和保存模型
saver=tf.train.Saver()
with tf.Session() as sess:sess.run(init)coord=tf.train.Coordinator()tf.train.start_queue_runners(sess=sess,coord=coord)for step in range(1,num_steps+1):batch_x,batch_y=sess.run([input_image,tf.one_hot(input_label,num_class,1,0)])sess.run(optimizer,feed_dict={X:batch_x})if step%disp_step==0 or step==1:loss=sess.run(loss_op,feed_dict={X:batch_x })print('step '+str(step)+' ,loss '+'{:.4f}'.format(loss))coord.request_stop()coord.join()print('optimization finished')saver.save(sess,'./AE_mnist_model/AE_mnist')训练结果:
step 1 ,loss 0.4566
step 1000 ,loss 0.1465
step 2000 ,loss 0.1291
step 3000 ,loss 0.1206
step 4000 ,loss 0.1158
step 5000 ,loss 0.1110
step 6000 ,loss 0.1081
step 7000 ,loss 0.1052
step 8000 ,loss 0.1039
step 9000 ,loss 0.1024
step 10000 ,loss 0.0969
step 11000 ,loss 0.0934
step 12000 ,loss 0.0934
step 13000 ,loss 0.0932
step 14000 ,loss 0.0872
step 15000 ,loss 0.0840
step 16000 ,loss 0.0832
step 17000 ,loss 0.0843
step 18000 ,loss 0.0830
step 19000 ,loss 0.0821
step 20000 ,loss 0.0813
step 21000 ,loss 0.0800
step 22000 ,loss 0.0776
step 23000 ,loss 0.0771
step 24000 ,loss 0.0754
step 25000 ,loss 0.0727
step 26000 ,loss 0.0735
step 27000 ,loss 0.0754
step 28000 ,loss 0.0739
step 29000 ,loss 0.0737
step 30000 ,loss 0.0727
optimization finished再贴一下使用上一篇博客的归一化方法得到的训练结果:
step 1 ,loss 2.1006
step 1000 ,loss 1.0853
step 2000 ,loss 1.0303
step 3000 ,loss 1.0057
step 4000 ,loss 0.9976
step 5000 ,loss 0.9814
step 6000 ,loss 0.9748
step 7000 ,loss 0.9687
step 8000 ,loss 0.9689
step 9000 ,loss 0.9576
step 10000 ,loss 0.9588
step 11000 ,loss 0.9571
step 12000 ,loss 0.9517
step 13000 ,loss 0.9495
step 14000 ,loss 0.9484
step 15000 ,loss 0.9432
step 16000 ,loss 0.9426
step 17000 ,loss 0.9378
step 18000 ,loss 0.9355
step 19000 ,loss 0.9347
step 20000 ,loss 0.9343
step 21000 ,loss 0.9322
step 22000 ,loss 0.9266
step 23000 ,loss 0.9267
step 24000 ,loss 0.9273
step 25000 ,loss 0.9269
step 26000 ,loss 0.9250
step 27000 ,loss 0.9257
step 28000 ,loss 0.9244
step 29000 ,loss 0.9199
step 30000 ,loss 0.9257
optimization finished很容易发现第二个模型收敛速度很慢,而且最后其实并未收敛到最优解,而且效果很差,相对于直接除以255255的处理方法,模型收敛就快很多,而且更倾向于收敛到了最优解 。所以数据预处理方式对结果影响也很大
测试代码实现
现载入模型:
sess=tf.Session()
#加载图和模型参数
new_saver=tf.train.import_meta_graph('./AE_mnist_model/AE_mnist.meta')
new_saver.restore(sess,'./AE_mnist_model/AE_mnist')得到我们的计算图,也就是模型结构:
graph=tf.get_default_graph()我们也可以看看在模型中保存了什么
print(graph.get_all_collection_keys())
#['queue_runners', 'recon', 'summaries', 'train_op', 'trainable_variables', 'variables']可以发现我们的重构函数recon已经保存在里面了,把它取出来,别忘了还有数据接收接口:
recon=graph.get_collection('recon')
X=graph.get_tensor_by_name('X:0')
print(recon)
#[<tf.Tensor 'Sigmoid_3:0' shape=(?, 784) dtype=float32>]接下来读一张图片,并处理一下:
images = []
img = cv2.imread('./mnist/test/4/4_20.png')
image=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
images.append(image)
images = np.array(images, dtype=np.uint8)
images = images.astype('float32')
images = np.multiply(images, 1.0/255.0)
x_batch = images.reshape(1,28*28)万事俱备,只需把处理后的图像丢入数据结构,使用函数重构即可
result=sess.run(recon,feed_dict={X:x_batch})
image_reco=np.multiply(result,255)
image_reco=image_reco.reshape(28,28)可视化结果:
plt.imshow(image_reco)
plt.show()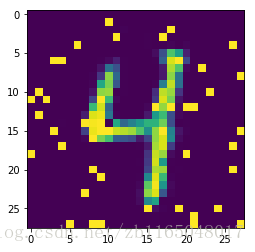
更新日志2018-8-15
看到变分自编码相关知识时,看到AE的一个缺点就是只能生成训练集类似的东东,也就是说如果我拿手写数字来训练,模型生成的东东一定就是手写数字,然后我就去拿着个模型试了一下,随便丢一张图片进来:
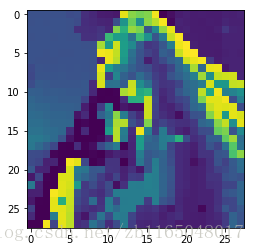
比如犬夜叉:

然后处理一下:
images = []
img = cv2.imread('./mnist/1.png')
image=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
image=cv2.resize(image,(28,28))
plt.imshow(image)
plt.show()
images.append(image)
images = np.array(images, dtype=np.uint8)
images = images.astype('float32')
images = np.multiply(images, 1.0/255.0)
x_batch = images.reshape(1,28*28)也就是将彩图转为灰度图并resize成网络图片接受接口所需的维度,即28×2828×28大小,变成了这样
生成一下
result=sess.run(recon,feed_dict={X:x_batch})
image_reco=np.multiply(result,255)
image_reco=image_reco.reshape(28,28)
plt.imshow(image_reco)
plt.show()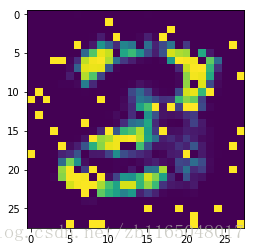
果然重构的图片长得像数字,是个8还是个2。
事实证明:使用AE做图像重构,生成的结果一定是与训练集内容相似的东东
后记
下一篇就来看看何为变分自编码,并实现它
训练代码:链接:https://pan.baidu.com/s/1HLwWo6T4QBPJxtHE5InQeA 密码:64rg
测试代码:链接:https://pan.baidu.com/s/1wIjG9KFkDsB1XFB98URcmw 密码:x7v9
数据集:链接:https://pan.baidu.com/s/1UJTAavqEPTCetgMSf-hYTw 密码:klcl


)
















