本章将接着上一篇文章,在初步实现一个渲染管线后来创建自定义的shader。上一篇文章的链接
https://blog.csdn.net/yinfourever/article/details/90516602。在本章中,将完成以下内容:
- 写一个HLSL Shader
- 定义constant buffer(常量缓冲区)
- 使用 Render Pipeline Core Library
- 支持动态合批和GPU instancing
本章最后实现的效果如下图,多个不同颜色球体,只需要一个draw call

1.Custom Unlit Shader
1.1Creating a Shader
创建一个Shader,删掉所有自带的默代码,写入以下代码。

将上一章创建的Unlit Opaque material指定为使用我们创建的这个新shader。
1.2 HLSL
Unity 新的SRP渲染管线使用HLSL,所以我们自定义的渲染管线也使用HLSL,我们使用HLSLPROGRAM and ENDHLSL

一个Shader至少应该包含vertex函数(顶点shader部分)和fragment函数(片元shader部分)。我们命名UnlitPassVertex for the vertex function and UnlitPassFragment for the other。但具体代码我们不在这个文件中实现,而是分离到一个单独的hlsl文件中,在这里include进来。

在生成的Unlit.hlsl文件中,我们使用#ifndef来避免多次引用。之后,我们声明Vertex函数的输入参数结构体和输出参数结构体

在vertex shader中,讲输入参数传递给输出参数,在fragment shader中,返回1,这样就完成了一个最简单的shader架构,虽然参数还是有错误的(position参数没有进行坐标变换处理直接从vertex shader传入到了fragment shader)

1.3 Transformation Matrices
从模型空间到裁剪空间需要两步转换,我们先用unity_ObjectToWorld矩阵转换到世界坐标空间,再用unity_MatrixVP矩阵转换到裁剪空间。
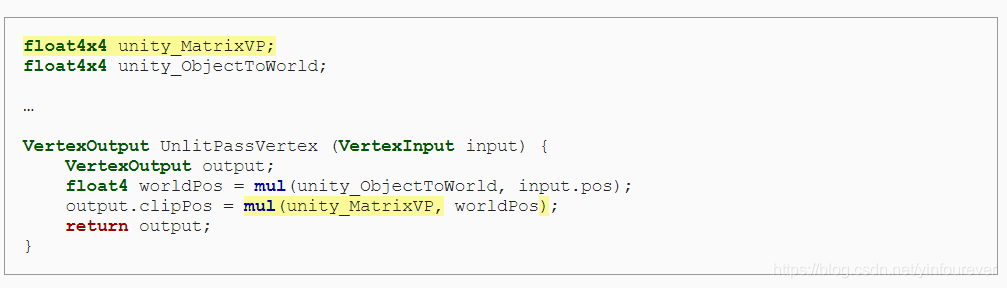
我们可以通过一个小技巧来提高运算的效率,将input的position信息,从三维向量补齐成四维,可以大大加快运算效率。

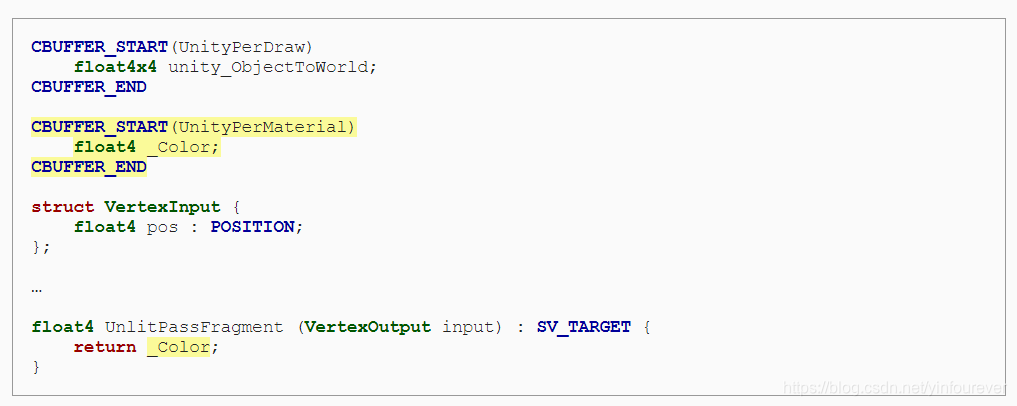
1.4 Constant Buffers
Unity没有直接提供MVP矩阵二是拆开成提供两个矩阵M和VP是因为VP矩阵在一帧中不会改变,可以重复利用。Unity将M矩阵和VP矩阵存入Constant Buffer中以提高运算效率,M矩阵存入的buffer为UnityPerDraw buffer, 也就是针对每个物体的绘制不会改变。VP矩阵则存入的是UnityPerFrame buffer,即每一帧VP矩阵并不会改变。Constant Buffer并不是所有平台都支持,目前OpenGL就不支持。
使用cbuffer keyworld来引入Constant buffer,constant buffer中还有很多其他的数据,暂时我们用不到,只使用这两个矩阵

1.5 Core Library
因为constant buffer并不是支持所有平台,所以我们使用宏来代替直接cbuffer keyword,使用CBUFFER_START 和CBUFFER_END 这两个宏需要使用Core Library,通过package manager可以安装。 安装成功后,在hlsl代码中引入common.hlsl就可以使用这两个宏了。


1.6 Compilation Target Level
我们使用#pragma target 指定shader level为3.5 代替默认的2.5,我们不支持OpenGL ES2那些老设备。

1.7 Folder Structure
我们调整下文件目录结构,使引用的文件都放入ShaderLibrary文件夹

2 Dynamic Batching
现在使用我们新创建的这个shader去渲染大量球体时,可以看到每个球体各自占用一个draw call。在fram debugger中我们可以看到提示没有合批的原因是我们没有开启动态合批。

我们根据提示,即使打开了player setting中的Dynamic Batching option选项,依然不会有效果,这是因为player setting中设置的是unity默认的渲染管线,而我们现在使用的是自定义的渲染管线,所以需要代码手动控制我们自己的这个管线开启合批功能。

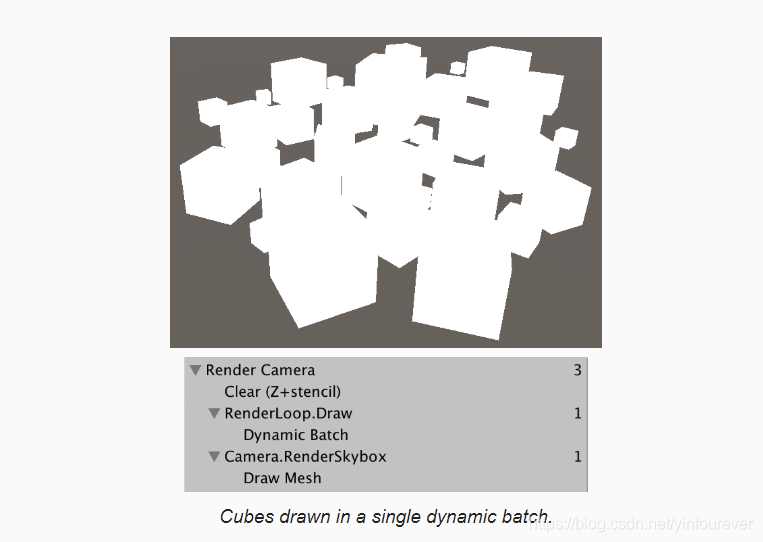
开启后,我们发现合批依然没有成功,根据提示,是因为物体的定点数太多,超过了动态合批的限制300。

把球体换成顶点数很少的方体,动态合批就成功了,可以看到只有一个draw call
2.2 Colors
当使用不同的material时,是不能动态合批的,为了证明这一点,我们加入color属性。
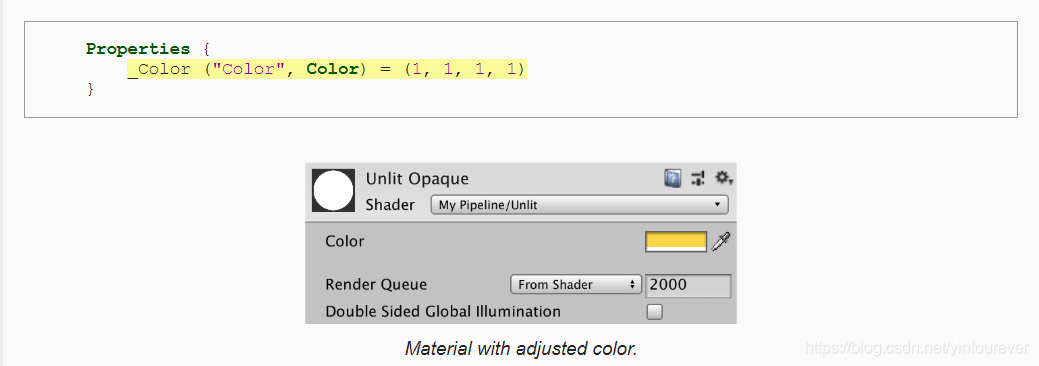
将color属性存入constant buffer中
复制一份之前的material,将复制的material中的color属性设置为其他颜色,我们可以看到合批结果为4个draw call。 这是因为对于每个material至少会产生一个draw call,unity中为了避免overdraw,会根绝空间位置信息分组渲染,对于每个material,往往会多于一个draw call。

debugger中可以看到提示不能合批的信息为使用了不同的material。

2.3 Optional Batching
动态合批是一个提升渲染效率的好方法,但是并不是所有时候都有效,甚至会拖慢渲染效率。当场景中并不存在大量使用相同material的小mesh的时候,动态合批就没什么用了,反而每帧关于动态合批的运算会降低效率。我们在自定义的渲染管线中加入一个bool值,来作为是否开启动态合批的开关。
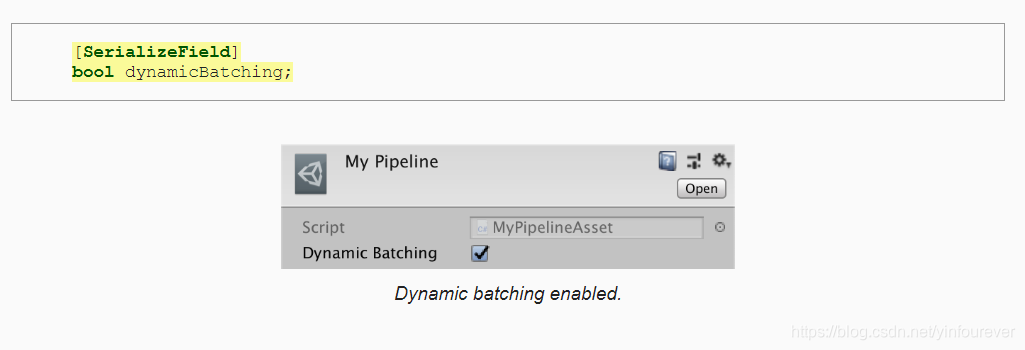
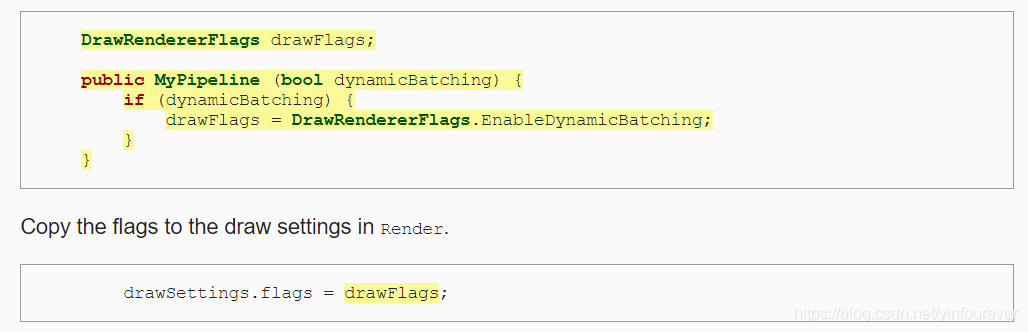
在MyPipeline的构造函数中,传入是否开启动态合批的bool值

在render函数中根据drawFlags设置动态合批是否开启
3 GPU Instancing
除了动态合批外,GPU Instancing也可以用于减少draw call。通过GPU Instancing,CPU告诉GPU在一个draw call中,渲染特定的mesh和material的组合多次。这使得使用相同mesh和material的物体渲染时不再像动态合批需要重新组成一个新的后批后的大mesh,这也就移除了对mesh大小的限制。
3.1 Optional Instancing
和之前的动态合批一样,我们也引入一个bool值控制是否开启GPU Instancing

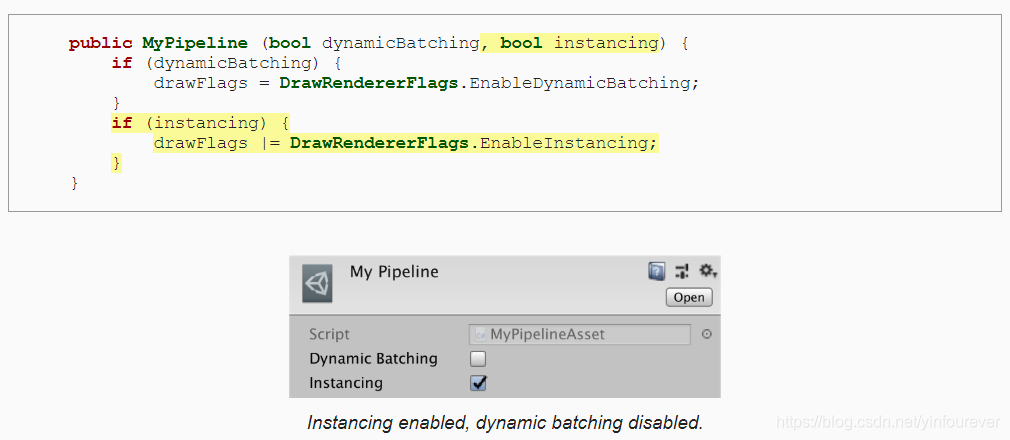
3.2 Material Support
渲染管线开启了GPU Instancing还不够,还需要使得material支持GPU Instancing,通过添加#pragma multi_compile_instancing来产生shader 变体,一个支持GPU Instancing一个不支持。在Editor中material的设置中可以看到是否开启GPU Instancing选项。

3.3 Shader Support
当GPU Instancing开启时,GPU会使用相同的constant data渲染同一个mesh多次。但是因为每个物体的位置不同,所以M矩阵就不同。为了解决这个问题,会在constant buffer中存入一个数组,用于存储待渲染的物体的M矩阵。每一个instance根据自身的index,从数组中取用数据。
我们使用unity提供的UNITY_MATRIX_M这个宏,在core library中的这个宏可以支持instancing,在使用矩阵数组的时候可以取出对应的矩阵

使用该宏需要引用UnityInstancing.hlsl这个文件。

当时用Instancing时,物体的index或被gpu传入顶点数据中,UNITY_MATRIX_M这个宏需要使用这个index数据,我们将Index数据加入到Vertex shader函数的输入结构体中,在Vertex Shader的处理函数中使用UNITY_SETUP_INSTANCE_ID 这个宏来使其生效。


除了 object-to-world matrices, 默认 world-to-object矩阵也存在了constant buffer中。但是目前我们没有需求使用他们,所以可以通过#pragma instancing_options assumeuniformscaling去掉他们提高性能

3.4 Many Colors
之前我们想实现一个场景中多个颜色的物体只能使用多个material,但是如果使用类似存储M矩阵的方式操作color属性,就可以实现用一个matrial渲染多种颜色物体。
首先创建一个脚本,包含要使用的color数据。
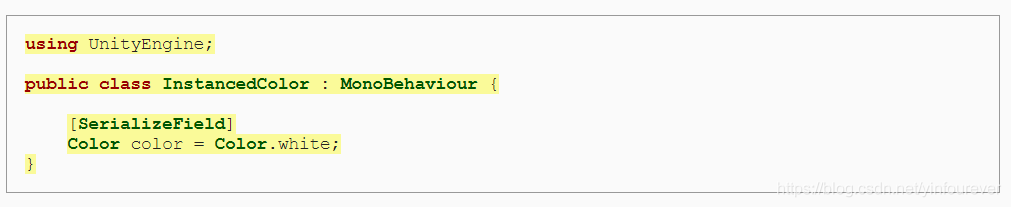
其次通过MaterialPropertyBlock函数创建一个MaterialPropertyBlock实体,通过它来设置material中的颜色。这些操作写入了OnValidate函数中,使得在editor中可以看到颜色变化效果。
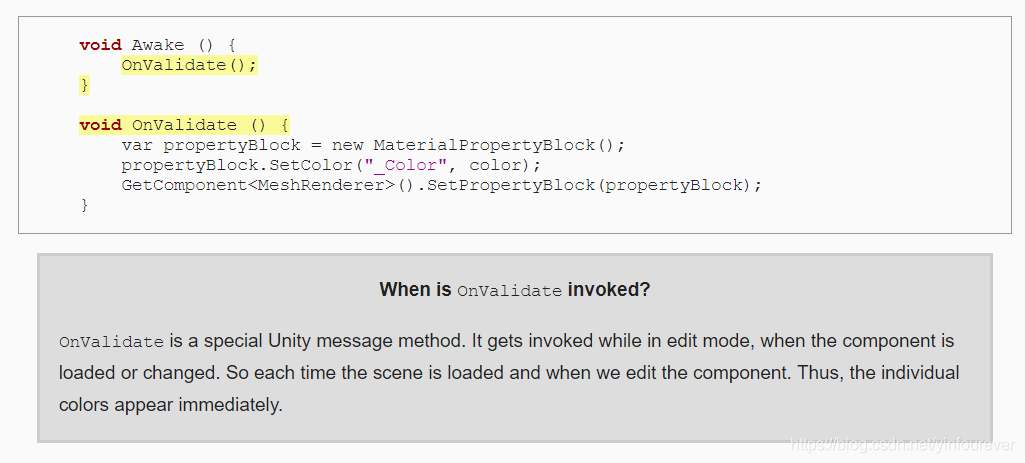
通过去掉局部变量,可以优化效率。

这时就可以用一个material渲染多种颜色了,但是到目前为止,每个物体都会产生draw call

3.5 Per-Instance Colors
像M矩阵处理的方式一样,我们也将color属性以数组形式存入constant buffer中,在使用时通过index从数组中取出。
不同于M矩阵Unity已经帮我们处理好了,color属性需要我们自己手动创建constant buffer并存入其中

在vertex shader函数的输出中,也要把index数据传递到fragment shader函数中。在fragment shdare的处理函数中,根据index取用color数据
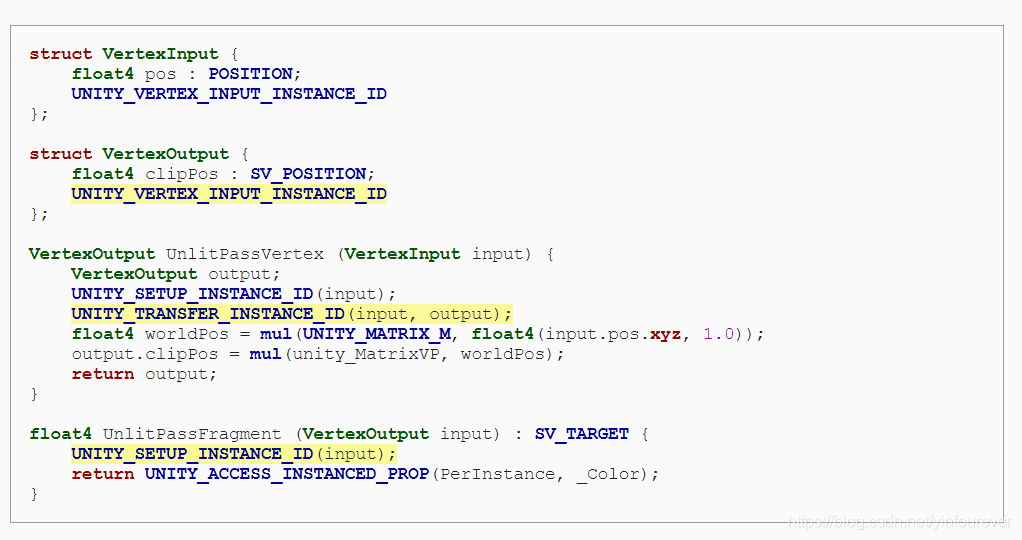
这时,我们只需使用一个material就能实现多颜色物体的渲染了,并且可以实现合并draw call。但是要注意的是constant buffer能存储多少数据是有限制的,最大数量的Instance取决于每个instance需要多少数据,除此之外,不同平台最大限制也不同。同时instance draw call的合并依然也要求需要是相同的mesh和material,比如下图中的方形和圆形虽然使用相同的material,但因为mesh不同所以依然需要不同的draw call进行渲染。




















