(1)交叉熵损失函数
蔡杰:简单的交叉熵,你真的懂了吗?zhuanlan.zhihu.com
1.1信息量
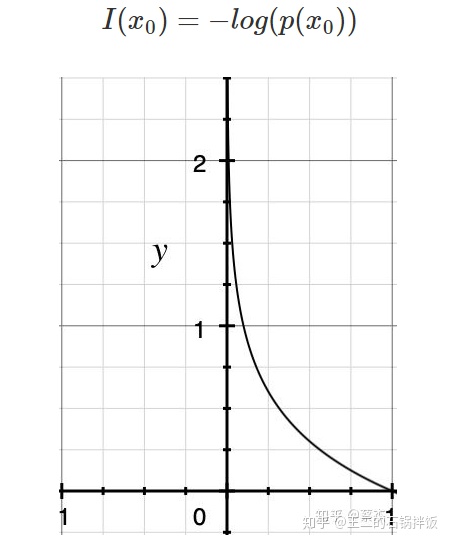
一条信息的信息量大小和他的不确定性有很大的关系,需要很多外部信息才能确定的信息,我们称之为这计划的信息量很大。
我们将事件x0的信息量定义如下,(其中p(x0)表示事件x0发生的概率:则信息量定义为:
1.2熵的概念
信息量是针对单个事件来说的,但是一件事有多种发生的可能,掷色子可能就有六种情况发生。因此熵表示的的是随机变量不确定的度量,是对所有可能事件产生的信息量的期望。
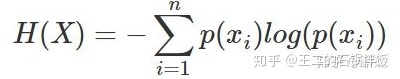
二分类的时候,只有两种情况:
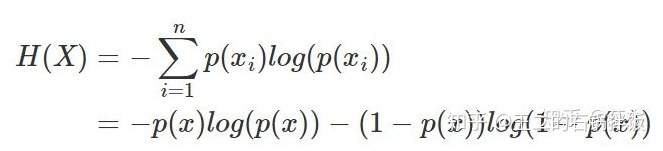
1.3相对熵
相对熵又被称为KL散度,用于衡量同一随机变量x的p(x)和q(x)两个分布差异,其中p(x) 描述样本的真实分布,q(x)描述的是预测的分布,在网络的学习的过程中q(x)需要不断的去学习来拟合准确的p(x)的分布。
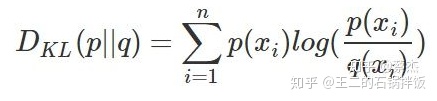
其中KL的值越小表示两个分布越接近
1.4交叉熵
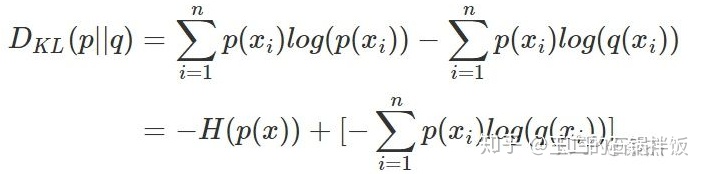
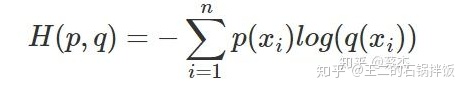
1.5使用交叉熵而不用平方差
当使用sigmoid做为激活函数的时候,平方差损失函数有时不能满足误差越大,权值调整越快,,但是交叉熵损失函数却可以很好的满足这一点
(2)smooth_L1损失函数
作者:尹相楠
链接:https://www.zhihu.com/question/58200555/answer/621174180
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
为了从两个方面限制梯度:
- 当预测框与 ground truth 差别过大时,梯度值不至于过大;
- 当预测框与 ground truth 差别很小时,梯度值足够小。
考察如下几种损失函数,其中
损失函数对
观察 (4),当
根据方程 (5),
最后观察 (6),
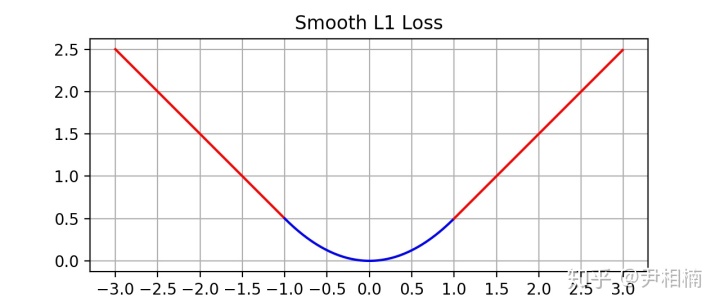
由图中可以看出,它在远离坐标原点处,图像和


)


...)


返回空值...)








最短路径)

Flask+Vue+Bootstrap3 人力资源用Web数据库)