一、引言
肺癌作为全球范围内主要死因之一,对人类健康产生了巨大威胁。准确的肺癌分类是制定有效治疗和预后评估的基础。传统的肺癌分类方法,如组织学类型和分期,虽然在临床实践中被广泛应用,但存在着诊断标准不一致、主观性强以及无法捕捉复杂的肿瘤异质性等问题。因此,开发基于机器学习的肺癌分类模型具有重要意义。
LightGBM是一种基于梯度提升决策树(Gradient Boosting Decision Tree)的机器学习算法,在肺癌分类任务中显示出了显著的优势。首先,LightGBM具有高效性能,能够处理大规模数据集和高维稀疏数据,加速了模型训练和预测过程。其次,LightGBM采用了基于直方图的决策树分割算法,能够处理非线性关系和特征交互,提高了模型的表达能力和准确性。
在肺癌分类模型的开发中,平衡准确性和可解释性是关键目标。准确性保证患者能够得到正确的分类和个性化治疗方案,提高生存率和生活质量。然而,仅追求准确性可能导致模型成为黑盒子,医生和患者难以理解和信任其结果。因此,我们需要在追求高准确性的同时,保持模型的可解释性,以便医生和患者能够理解模型的决策依据,并做出明智的决策。
二、lightGBM简介
2.1 lightGBM算法的基本原理和优势
梯度提升决策树(Gradient Boosting Decision Tree,简称GBDT)是一种集成学习算法,通过逐步迭代训练决策树模型,不断纠正前一轮迭代的错误。GBDT基于加法模型和梯度下降的思想,通过最小化损失函数的负梯度来训练模型。
「LightGBM算法在GBDT的基础上进行了改进和优化。其基本原理包括以下几个关键点:」
-
直方图算法:LightGBM采用了基于直方图的决策树分割算法,将连续特征离散化为直方图的形式,有效地减少了数据排序的时间,提高了训练速度。 -
多叶子结点分裂策略:传统的GBDT算法每次只选择一个最佳的叶子结点进行分裂,而LightGBM通过多叶子结点分裂策略,在每次分裂时计算每个叶子结点的增益,并选择增益最大的结点进行分裂。这样可以增加模型的表达能力,提高准确性。 -
特征并行化和直方图压缩:LightGBM支持特征并行化处理,并采用特征向量的稀疏化存储和直方图压缩技术,大幅降低了内存消耗,使得算法在大规模数据集上能够高效运行。
「相比传统的GBDT算法,LightGBM具有以下优势:」
-
更快的训练速度:采用了基于直方图的决策树分割算法,减少了数据排序的时间,同时支持并行化处理,大幅提高了训练速度。 -
更低的内存消耗:通过特征向量的稀疏化存储和直方图压缩技术,降低了内存占用,使得算法能够处理大规模数据集。 -
更好的准确率:采用多叶子结点分裂策略,能够处理非线性关系和特征交互,提高了模型的表达能力和准确性。
2.2 lightGBM和XGBoost的异同点
LightGBM和XGBoost都是基于GBDT算法的优化版本,它们在算法的结构和实现上存在一些异同点:
-
数据划分方式:XGBoost采用的是贪心算法,基于精确的梯度值来进行划分,而LightGBM采用的是直方图算法,计算出每个特征的直方图后,根据直方图上的信息来选择最优的划分点。 -
分裂结点方式:XGBoost采用的是近似算法,找到一个全局最优分裂点,而LightGBM采用的是局部最优法,也就是多叶子结点分裂策略,即对每个叶子结点计算增益并选择最优的叶子结点来分裂,从而提高了模型的表达能力。 -
内存消耗和速度:LightGBM在处理大规模数据集时表现更出色,因为它采用了特征向量的稀疏化存储和直方图压缩技术。而XGBoost则适用于小型或中型数据集。
2.3 lightGBM算法的局限性
尽管LightGBM在许多方面具有优势,但也存在一些局限性:
-
处理非平衡数据的能力有限:由于LightGBM采用基于直方图的算法,在处理非平衡数据时可能出现样本不均衡的问题,导致模型预测结果偏向于多数类。 -
对噪声敏感:LightGBM对噪声和异常值比较敏感,容易受到噪声的干扰,可能导致模型的准确性下降。 -
在小数据集上表现不如其他算法:由于LightGBM采用了多叶子结点分裂策略,相比传统的GBDT算法,对于小规模数据集容易发生过拟合现象,可能导致模型泛化能力不足。
三、实例展示
-
「数据集准备」
library(survival)
head(lung)
结果展示:
> head(lung)
inst time status age sex ph.ecog ph.karno pat.karno meal.cal wt.loss
1 3 306 2 74 1 1 90 100 1175 NA
2 3 455 2 68 1 0 90 90 1225 15
3 3 1010 1 56 1 0 90 90 NA 15
4 5 210 2 57 1 1 90 60 1150 11
5 1 883 2 60 1 0 100 90 NA 0
6 12 1022 1 74 1 1 50 80 513 0
-
「示例数据集简介」
这个数据集名为 "lung",包含了228个肺癌患者的临床特征和生存数据。具体来说,它包含了以下10个变量:
inst: 患者所在医院的编号。
time: 患者确诊后生存时间(单位:天)。
status: 患者是否在观察期内死亡,如果是则为1,否则为2。
age: 患者的年龄。
sex: 患者的性别,1表示男性,2表示女性。
ph.ecog: 患者的肺癌ECOG(Eastern Cooperative Oncology Group)表现评分,其中0表示正常活动,5表示完全失能。
ph.karno: 患者的Karnofsky评分,用于评估患者的一般状态和功能水平,最高得分为100,分数越低表示功能能力越差。
pat.karno: 患者入组时的Karnofsky评分。
meal.cal: 患者每日饮食摄入热量(单位:卡路里)。
wt.loss: 患者在过去6个月中的体重减轻量(单位:磅)。
这些变量可以用来预测患者的生存时间和生存率,以及探索与肺癌患者相关的临床特征。
-
「数据预处理」
summary(lung)
结果展示:
inst time status age
Min. : 1.00 Min. : 5.0 Min. :1.000 Min. :39.00
1st Qu.: 3.00 1st Qu.: 166.8 1st Qu.:1.000 1st Qu.:56.00
Median :11.00 Median : 255.5 Median :2.000 Median :63.00
Mean :11.09 Mean : 305.2 Mean :1.724 Mean :62.45
3rd Qu.:16.00 3rd Qu.: 396.5 3rd Qu.:2.000 3rd Qu.:69.00
Max. :33.00 Max. :1022.0 Max. :2.000 Max. :82.00
NA's :1
sex ph.ecog ph.karno pat.karno
Min. :1.000 Min. :0.0000 Min. : 50.00 Min. : 30.00
1st Qu.:1.000 1st Qu.:0.0000 1st Qu.: 75.00 1st Qu.: 70.00
Median :1.000 Median :1.0000 Median : 80.00 Median : 80.00
Mean :1.395 Mean :0.9515 Mean : 81.94 Mean : 79.96
3rd Qu.:2.000 3rd Qu.:1.0000 3rd Qu.: 90.00 3rd Qu.: 90.00
Max. :2.000 Max. :3.0000 Max. :100.00 Max. :100.00
NA's :1 NA's :1 NA's :3
meal.cal wt.loss
Min. : 96.0 Min. :-24.000
1st Qu.: 635.0 1st Qu.: 0.000
Median : 975.0 Median : 7.000
Mean : 928.8 Mean : 9.832
3rd Qu.:1150.0 3rd Qu.: 15.750
Max. :2600.0 Max. : 68.000
NA's :47 NA's :14
从上面可以看出,该数据集中存在很多的缺失数据,在分析之前需要「插值处理」一下。
library(mice)
input.data <- mice(lung,seed=5)
data <- complete(input.data,3)
summary(data)
结果展示:
inst time status age
Min. : 1.00 Min. : 5.0 Min. :1.000 Min. :39.00
1st Qu.: 3.00 1st Qu.: 166.8 1st Qu.:1.000 1st Qu.:56.00
Median :11.00 Median : 255.5 Median :2.000 Median :63.00
Mean :11.07 Mean : 305.2 Mean :1.724 Mean :62.45
3rd Qu.:16.00 3rd Qu.: 396.5 3rd Qu.:2.000 3rd Qu.:69.00
Max. :33.00 Max. :1022.0 Max. :2.000 Max. :82.00
sex ph.ecog ph.karno pat.karno
Min. :1.000 Min. :0.0000 Min. : 50.00 Min. : 30.00
1st Qu.:1.000 1st Qu.:0.0000 1st Qu.: 70.00 1st Qu.: 70.00
Median :1.000 Median :1.0000 Median : 80.00 Median : 80.00
Mean :1.395 Mean :0.9561 Mean : 81.89 Mean : 79.91
3rd Qu.:2.000 3rd Qu.:1.0000 3rd Qu.: 90.00 3rd Qu.: 90.00
Max. :2.000 Max. :3.0000 Max. :100.00 Max. :100.00
meal.cal wt.loss
Min. : 96.0 Min. :-24.000
1st Qu.: 712.2 1st Qu.: 0.000
Median : 975.0 Median : 7.000
Mean : 933.8 Mean : 9.706
3rd Qu.:1150.0 3rd Qu.: 15.000
Max. :2600.0 Max. : 68.000
从上面可以看出结果补充完整。
-
「模型拟合」
library(lightgbm)
library(tidymodels)
library(bonsai)
set.seed(123)
data$status <- as.factor(data$status)
lgb <- boost_tree() %>%
set_engine("lightgbm") %>%
set_mode("classification") %>%
fit(status~.,data=data)
-
「构建解释器」
library(DALEXtra)
lgb_exp <- explain_tidymodels(lgb,
data =data[,-2],
y=data$status,
label = "LightGBM")
# Breakdown图
lgb_bd <- predict_parts(lgb_exp,new_observation=data[1,-2])
plot(lgb_bd)
模型预测样本2 的值为0.971,红色或浅蓝色条形显示各变量的对预测的影响,正值表示增加患病的风险,负值减少患病的风险,预测值等于每个特征贡献的和。
# SHAP值
lgb_shap <- predict_parts(lgb_exp,
type = "shap",
new_observation = data[2,])
plot(lgb_shap,show_boxplots=FALSE)
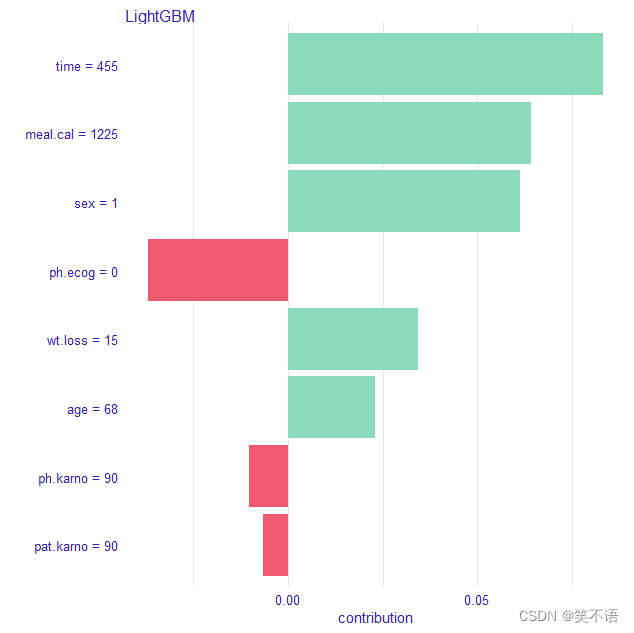
SHAP值也可以显示各变量对预测的贡献度,只不过与Breakdown的评估方法不同。红色条形对样本2 的贡献为负值,属于保护因素,浅蓝色条对预测的贡献为正值。
# CP图
library(ingredients)
lgb_cp <- ceteris_paribus(lgb_exp,data[2,])
plot(lgb_cp,subtitle = "")
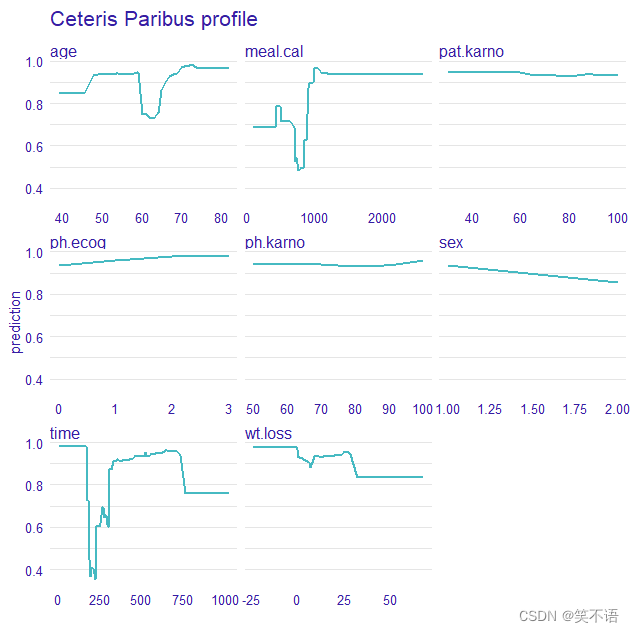
CP图可以显示每个预测变量对模型预测影响的变化曲线,如果曲线变化陡峭,则表明该变量对预测的影响较大;如果曲线平缓或呈直线,则表明该变量对预测的影响较小。
# 部分依赖图(PDP)
lgb_pd <- partial_dependence(lgb_exp)
plot(lgb_pd)
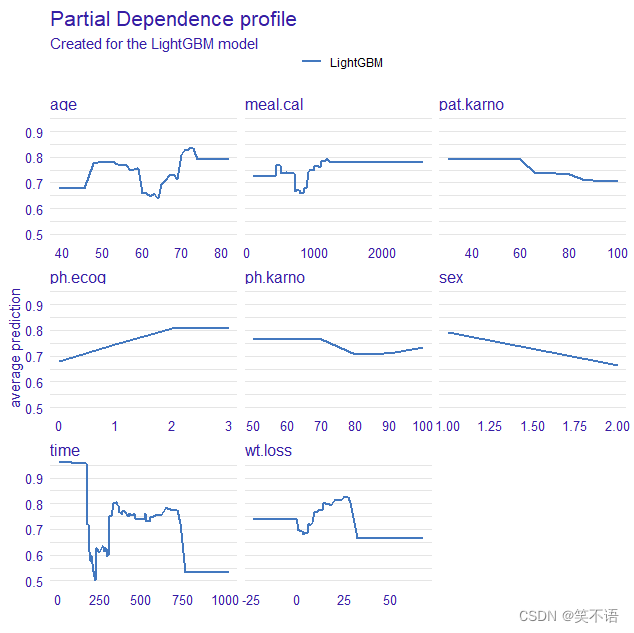
部分依赖图也可以展示变量对预测的影响。
# 变量重要性
library(vivo)
lgb_profiles <- model_profile(lgb_exp)
lgb_vi <- global_variable_importance(lgb_profiles)
plot(lgb_vi)
# 绘制ROC曲线
library(auditor)
lgb_mp <- model_evaluation(lgb_exp)
# 绘制ROC曲线
plot(lgb_mp)+geom_line(color="red",lwd=1.5,lty=2)+geom_abline()
四、结论和展望
本研究表明,LightGBM算法在肺癌分类中具有广阔的应用前景和重要的贡献。其优势包括高效处理大规模数据、准确捕捉特征之间的非线性关系、以及提供较强的解释性,这些特点使得它成为肺癌研究中一个有力的工具。通过结合临床信息和基因表达数据,LightGBM能够帮助医生进行肺癌的早期检测、分类预测以及治疗响应预测,为临床决策提供重要支持。
尽管本研究取得了一些令人鼓舞的结果,但仍然存在一些局限性和挑战。当前研究的局限性包括数据集的多样性不足、特征选择和优化的待完善性,以及对模型解释性的进一步改进空间。未来可能的研究方向包括扩大数据集的规模和多样性、优化特征选择方法、改进模型的解释性,以及解决数据隐私和安全等挑战。
结合LightGBM算法的经验和成果,可以推动乳腺癌研究的深入发展。类似于肺癌研究,LightGBM算法可以应用于乳腺癌的早期检测、分类预测和治疗响应预测,为乳腺癌的诊断和治疗提供更精准、个性化的支持。未来的研究可以借鉴当前肺癌研究的经验,结合乳腺癌特有的临床和基因表达数据,利用LightGBM算法开展更加深入的研究,为乳腺癌患者的健康提供更好的服务和支持。
*「未经许可,不得以任何方式复制或抄袭本篇文章之部分或全部内容。版权所有,侵权必究。」

)

方法)







-返回Insert操作自增索引值)







)