
文章目录
- Beginning
- Abstract
- 挑战
- 方法
- 成果
- Introduction
- 引出问题
- 早期的work及存在的问题
- 近期的work及存在的问题
- our work
- Contribution
- Related Work(paper for me)
- Oriented Object Detection
- Prior for Oriented Objects
- Label Assignment
- Tiny Object Detection
- Multi-scale Learning
- Label Assignment
- Context Information
- Feature Enhancement
- our work
- Method
- Overview
- 初始表述
- 动态重表述
- Dynamic Prior
- Coarse Prior Matching
- Finer Dynamic Posterior Matching
- Experiments
- Datasets
- Implementation Details
- Main Results
- Results on DOTA series
- Results on DIOR-R
- Resultson HBBDatasets
- 消融实验
- Analysis
- 调和不平衡问题
- 可视化
- 速度
- Conclusion
原文链接
源代码
Beginning
Abstract—>(Conclusion)—>Method—>Experiment—>Conclusion
Abstract
挑战
检测任意方向的微小物体给现有的检测器带来了巨大的挑战,特别是在标签分配方面。尽管近年来在定向目标检测器中对自适应标签分配进行了探索,但定向微小目标的极端几何形状和有限特征仍然会导致严重的不匹配和不平衡问题。具体而言,位置先验、正样本特征和实例不匹配,并且由于缺乏适当的特征监督,极端形状对象的学习存在偏差和不平衡。
方法
为了解决这些问题,我们提出了一个动态先验和由粗到精的分配器,称为DCFL。一方面,我们以动态方式对先验、标签分配和目标表示进行建模,以缓和不匹配问题。另一方面,我们利用粗糙的先验匹配和更精细的后验约束来动态分配标签,为不同的实例提供适当和相对平衡的监督
成果
在六个数据集上进行的大量实验表明,基线有了实质性的改进。值得注意的是,在单尺度训练和测试下,我们在DOTA-v1.5、DOTA-v2.0和DIOR- R数据集上获得了一级检测器的最先进性能。
Introduction
引出问题
定向边界框是一种更好的目标检测表示,因为通过引入旋转角度,极大地消除了对象的背景区域[55]。这一优势在航拍图像中表现得尤为明显,因为航拍图像中的目标是任意方向的,因此相应的目标检测数据集[7,11,35,55]和定制的定向目标检测器[10,17,18,60,62]大量涌现。
然而,一个不可忽视的事实是,在航空图像中存在着许多微小的物体。当定向对象的尺寸很小时,现有的目标探测器面临的挑战是相当显著的。特别是,定向微小物体的极端几何特性阻碍了精确的标签分配。
标签分配是目标检测中一个基本而关键的过程[68],其中需要为先验(基于锚的框,无锚的为点检测器)分配适当的标签,以监督网络训练。
早期的work及存在的问题
图1展示了为面向对象的有效标签分配奠定了基础的一些工作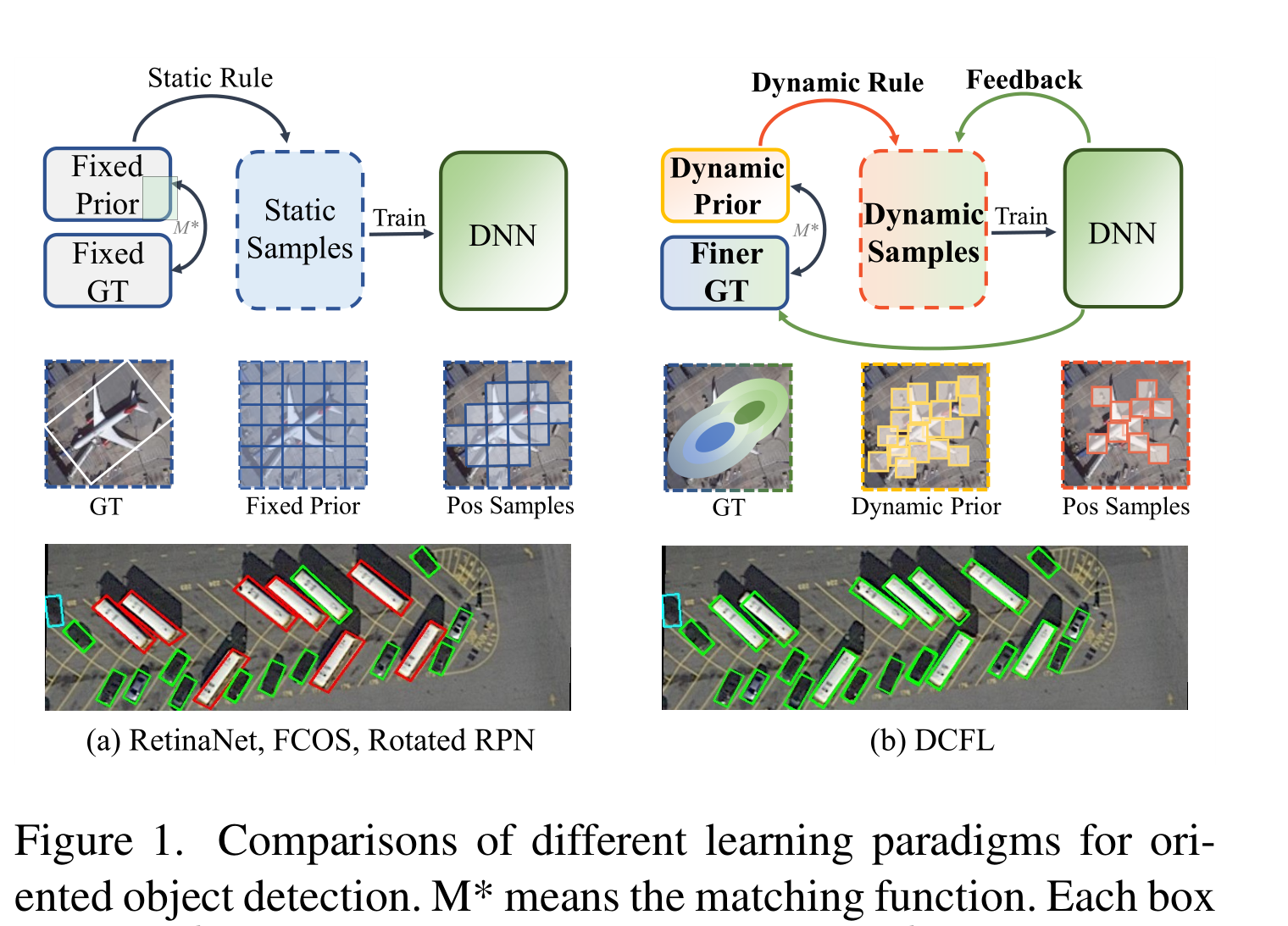
M*表示匹配函数。第二行中的每个方框表示先前的位置。第三行是对RetinaNet和DCFL的预测,其中绿色、蓝色和红色框表示真阳性、假阳性和假阴性预测。(a)retinanet、FCOS和旋转RPN在固定先验和固定先验之间静态地分配标签。(b)我们提出的DCFL动态更新先验和gt,以及动态分配标签
早期的工作是在通用目标检测器的基础上,额外预设不同角度的锚点(如旋转RPN[36])或精炼高质量的锚点(如s2-A- net[17]),然后是静态规则(如;使用MaxIoU策略[44]来分离正负(pos/neg)训练样本。因此,得到的先验框可以覆盖更多的地面真值(gt)框,并且可以预期相当大的精度提高。然而,静态分配不能根据gt的形状自适应划分正/负样本,并过滤掉低质量的样本,通常会导致性能次优。
近期的work及存在的问题
最近,自适应标签分配的探索[68]给社区带来了新的见解。对于定向目标检测,DAL[38]定义了一个预测感知的匹配度,并利用它来重新加权锚点,实现动态样本学习。此外,一些研究[21,23,26]将形状信息纳入检测器,并提出形状感知采样和测量。
尽管取得了进展,但定向微小物体的任意方向和极端尺寸仍然给探测器带来了难题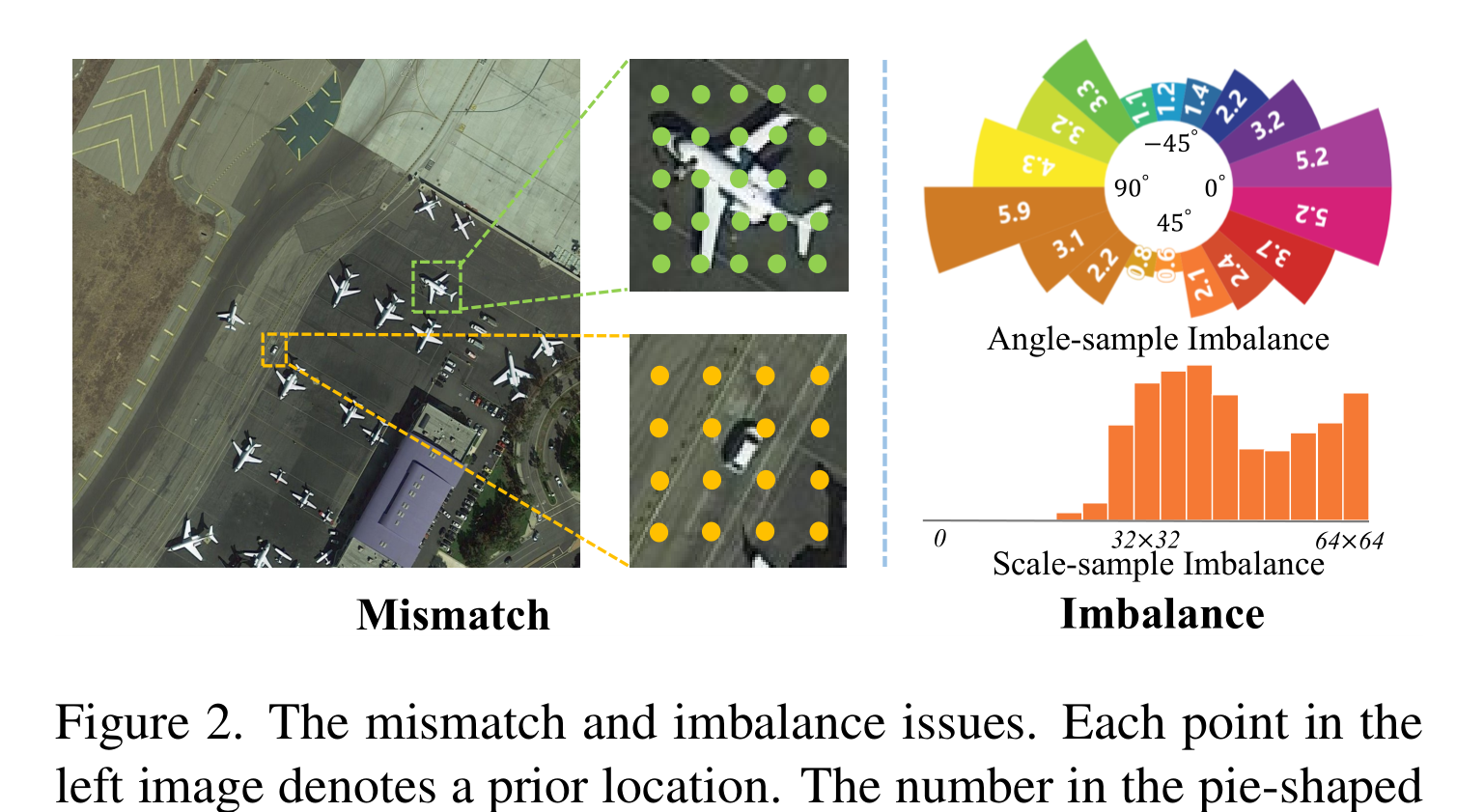
左图中的每个点表示一个先验位置。饼状柱状图中的数字表示在特定角度范围内分配给每个实例的阳性样本的平均数量
如上图所示,不匹配和不平衡的问题尤其明显。首先,在位置先验、特征和实例之间存在相互不匹配的问题。尽管一些自适应标签分配方案可能会探索更好的先验框或点的正负划分,但先验后面的采样特征位置仍然是固定的,派生的先验仍然是静态和均匀定位的,大多数先验偏离了微小物体的主体。无论我们如何划分正负样本,先验和特征本身都不能很好地匹配定向微小物体的极端形状。
其次,现有的检测器对于定向微小的物体往往会引入偏差和不平衡。更准确地说,对于基于锚的检测器,形状与锚盒不同的gt将产生低IoU,导致缺乏阳性样本。在图2中,我们计算了用RetinaNet分配给不同gts的阳性样本的平均值,并观察到对于角度和尺度远离预定义锚点的gts,极端缺乏阳性样本。对于无锚检测器,静态先验及其固定步幅限制了高质量阳性样本的上限。微小的物体只覆盖有限数量的特征点,而且这些特征点大多远离物体的主体
our work
如图1所示,我们通过以动态方式重新制定先验、标签分配和gt表示来缓解不匹配问题,这些都可以由深度神经网络(DNN)更新。同时,我们以从粗到精的方式动态渐进地分配标签,以寻求对各种实例的平衡监督。
(具体来说,我们引入了一个动态先验捕获块(PCB)来学习先验,它自适应地调整先验位置,同时保留先验的物理意义[54]。PCB的灵感来自于DETR[4]和Sparse R-CNN[48]中可学习提案的范例,它自然地避免了预定义的先验和特征之间的不匹配问题。与此范例相比,我们在保持密集检测器的快速收敛能力的同时,引入了其预先更新的灵活性[32,54]。基于动态先验,我们选择跨fpn层粗正样本(CPS)候选样本进行进一步的标签分配,CPS通过gt和动态先验之间的广义Jensen- Shannon散度39实现。GJSD能够将CPS扩展到物体附近的空间位置和相邻的FPN层,确保更多的极端形状物体的候选对象。在获得CPS后,我们用预测(后验)对这些候选样本重新排序,并用更精细的动态高斯混合模型(DGMM)表示gt,过滤掉低质量样本。所有的设计都合并到一个端到端一级检测器,没有额外的分支。)
Contribution
(1)我们发现当前面向微小目标检测的学习管道存在严重的不匹配和不平衡问题。
(2)设计了一种面向微小目标检测的动态由粗到精学习(DCFL)方案,该方案首次以动态方式对先验、标签分配和gt表示进行建模。(在DCFL中,我们提出使用GJSD构造粗阳性样本(CPS),并用更精细的动态高斯混合模型(DGMM)表示对象,获得粗到细的标签分配。)
(3)在6个数据集上进行了大量实验,展示了令人满意的结果
Related Work(paper for me)
Oriented Object Detection
Prior for Oriented Objects
锚作为通用目标检测器(如Faster R-CNN[44]、RetinaNet[30])中的经典设计,长期以来一直为目标检测提供便利。类似地,定向对象检测也受益于锚的设计。最初,旋转RPN[36]将RPN扩展到定向目标检测领域,在每个位置平铺54个锚点,预设角度和尺度。事实上,除了额外的计算成本外,枚举潜在的gt形状可以显著改善重调用。RoI Transformer[10]利用水平锚点,将rpn生成的水平提案转换为定向提案,减少了旋转锚点的数量。为了节省计算,Oriented R-CNN[56]引入了一种基于水平锚点直接预测面向提案的定向RPN。近年来,逐步出现了面向一级的目标检测器,包括基于锚点的具有箱先验的检测器[17,60]和无锚点的具有点先验的检测器[26,28]。除了s2 A-Net[17]提出生成高质量锚外,大多数都保留了固定的先验设计。
Label Assignment
ATSS[68]揭示了标签的标记在检测器的性能中起着关键作用[14,24,37]。在定向目标检测领域,DAL[38]观察了输入的先验IoU与输出的预测IoU之间的不一致性,然后将匹配度定义为动态重新加权锚点的软标签。最近,SASM[21]引入了一种形状自适应的样本选择和测量策略来提高检测性能。类似地,GGHL[23]提出通过单个二维高斯热图拟合实例主体,然后动态划分和重加权样本。此外,Oriented Reppoints[26]通过评估点的质量来更有效地分配标签,从而改进了Reppoints[65]。
Tiny Object Detection
Multi-scale Learning
基本上,可以使用多分辨率图像金字塔来获得多尺度学习。然而,vanilla图像金字塔会带来很大的计算成本。因此,一些研究[29,33,34,42,49,69]利用高效的特征金字塔网络(FPN)减少了计算量。与FPN不同,TridentNet[27]引入了各种接受野的多分支检测头,用于多尺度预测。此外,还可以对物体的尺度进行归一化,用于尺度不变的物体检测,例如SNIP[46]和SNIPER[47]在一定的尺度范围内调整图像大小并训练物体。
Label Assignment
微小物体通常具有较低的IoU和锚点,或者覆盖的特征点数量有限,因此缺乏阳性样本。ATSS[68]稍微协调了不同尺度对象的阳性样本数量。NWD[57]设计了一种新的度量来取代IoU,它可以对微小物体取样更多的阳性样本。最近,RFLA[58]利用离群值来检测微小物体以实现尺度平衡学习。
Context Information
微小物体缺乏区分特征,但物体与周围环境密切相关。因此,我们可以利用上下文信息来增强小目标检测。multi-region CNN (MRCNN)[15]和Inside-Outside Network (ION)[3]是利用局部和全局上下文信息的两个代表性作品。最近,Relation Network[22]和基于变压器的检测器[4,54,72]通过注意机制来解释实例之间的关联
Feature Enhancement
小物体的特征表示可以通过超分辨率或GAN来增强。PGAN[25]首先将GAN应用于小目标检测。此外,Bai等人[1]介绍了MT-GAN,该算法训练图像级超分辨率模型来改善小目标的RoI特征。此外,还有一些基于超分辨率的方法[2,8,40,43]。
our work
相比之下,我们的方法通过动态建模先验、标签分配和gt表示来同时处理先验不匹配和不平衡学习。同时,与两级ROI-Transformer[10]或一阶s2 A-Net[17]不同,我们将动态先验嵌入端到端一级检测器,而不引入任何辅助支路。
Method
Overview
初始表述
给定一组密集先验P∈R W×H×C (W ×H为特征图大小,C为形状信息个数,为简单起见,每个特征点有一个先验),目标检测器通过深度神经网络(Deep Neural Network, DNN)将集合P重新映射为最终检测结果D,可以简化为: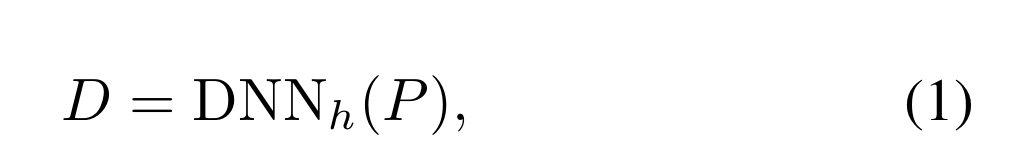
DNN h为检测头
检测结果D包含两部分:分类分数D cls∈R W×H×A (A为类号)和框位置D reg∈R W×H×B (B为框参数号)。
为了训练DNN h,我们需要在先验集P和地面真值集GT之间找到合适的匹配,并为P分配pos/ neg标签来监督网络的学习。
对于静态分配器(如RetinaNet),可以通过手工匹配函数M s获得pos标签集G: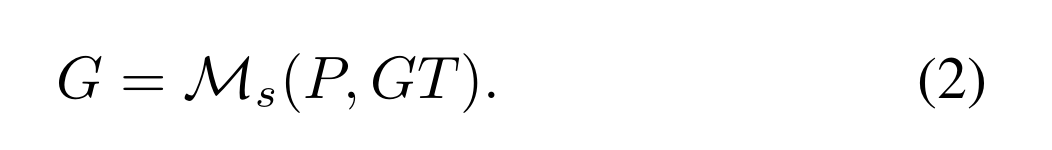
对于动态分配器[14,24,38],他们倾向于同时利用先验信息P和后验信息(预测)D,然后应用预测感知映射M D来得到集合G: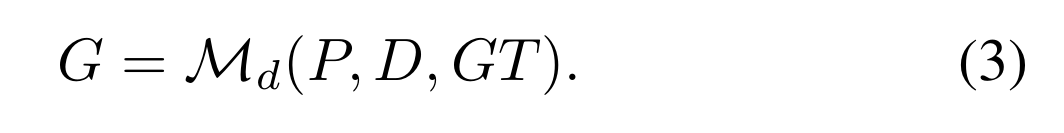
pos/neg标签分离后,损失函数可归纳为两部分: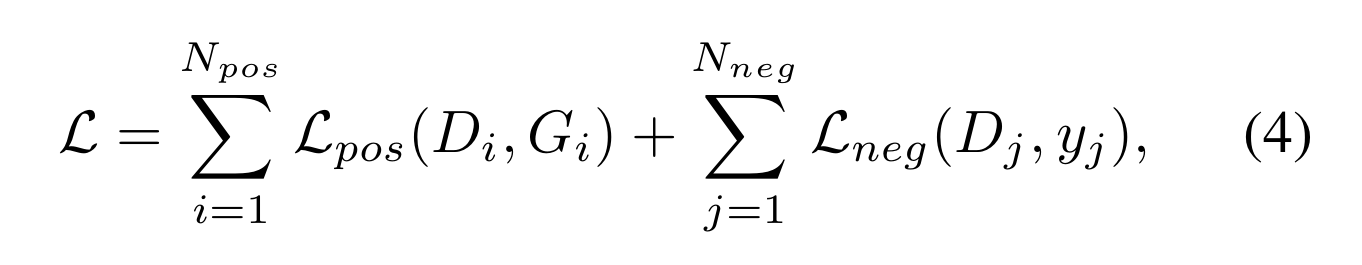
Npos、Nneg分别为正负样本数,yj为负标签
动态重表述
在这项工作中,我们以动态的方式对先验、标签分配和gt表示进行建模,以减轻不匹配问题。首先,动态先验被重新表述为(~表示动态项):
DNN p是一个可学习的块,包含在检测头中,用于更新先验。
然后,将匹配函数重新表述为一个从粗到精的范式: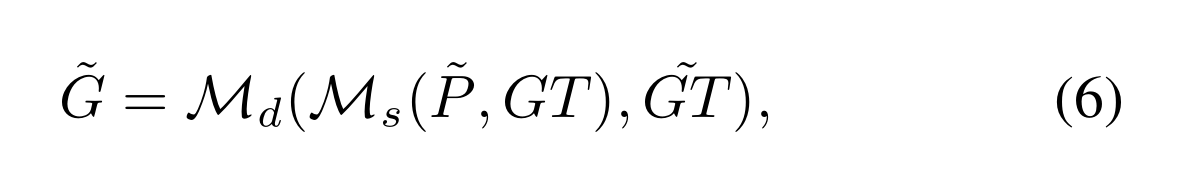
~GT是使用动态高斯混合模型(DGMM)更好地表示目标的方法。
简而言之,我们的最终损失模型为: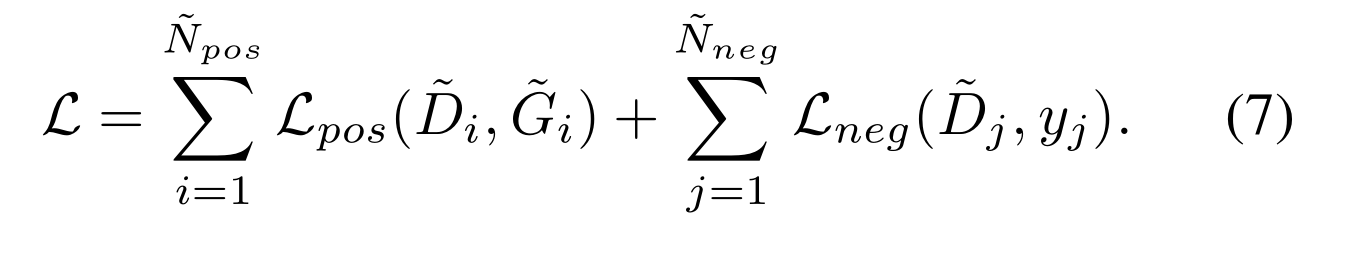
Dynamic Prior
受DETR[4]和Sparse R-CNN[48]中提议更新的纯可学习范式的启发,我们建议在先验中引入更多的灵活性来缓解不匹配问题。此外,我们保留了先验的物理意义,其中每个先验代表一个特征点,继承了密集检测器的快速收敛能力。所提出的先验捕获块(PCB)的结构如图3所示,其中部署扩展卷积来考虑周围信息,然后利用可变形卷积网络(Deformable convolution Network, DCN)[9]来捕获动态先验。此外,我们利用从回归分支中学习到的偏移量来指导分类分支的特征提取,从而使两个任务更好地对齐。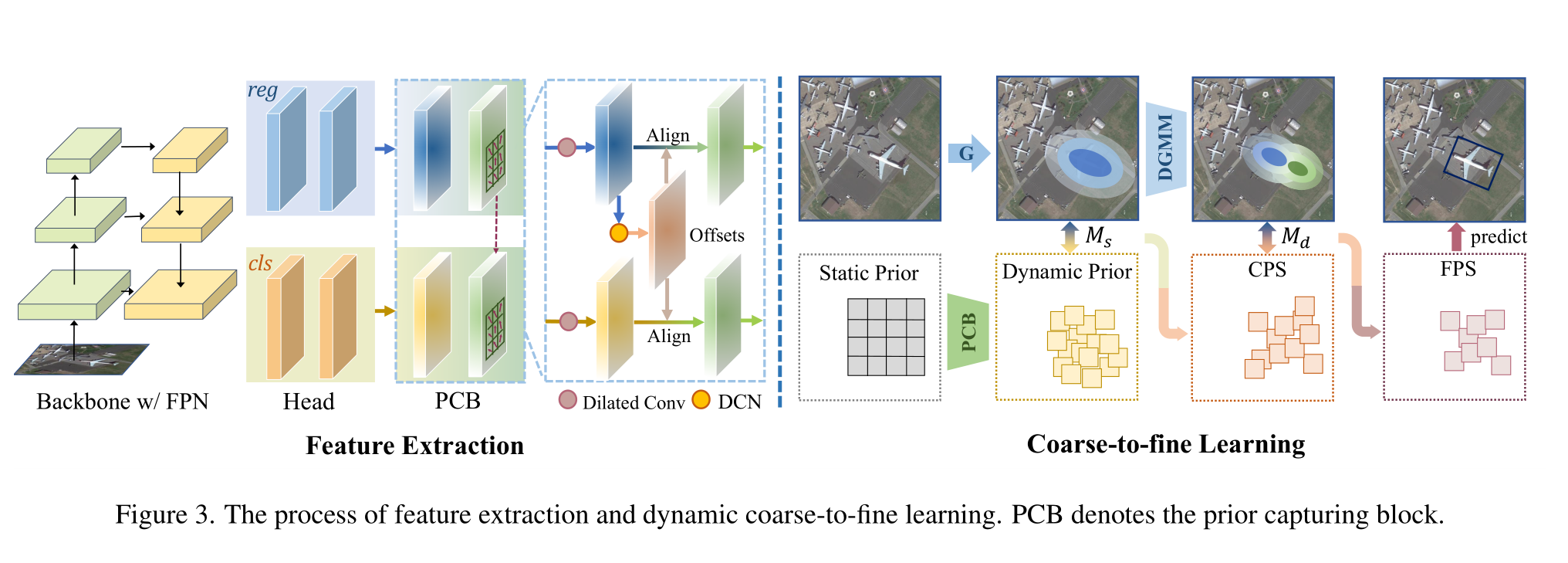
动态先验捕获过程如下。首先,我们通过每个特征点的空间位置s(重新映射到图像)初始化每个先验位置p(x,y)。在每次迭代中,我们转发网络以捕获每个先验位置∆o的偏移集。因此,可以通过以下方式更新先前的空间位置: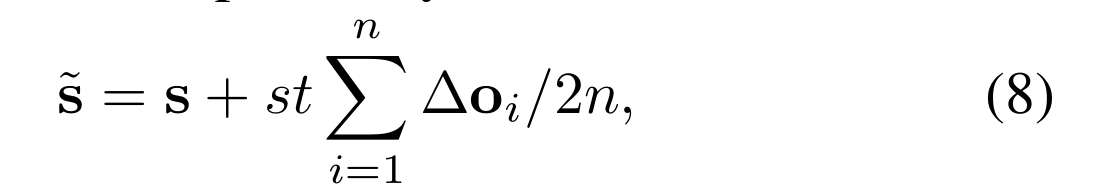
其中st为特征映射的步幅,n为偏移量。最后,我们利用二维高斯分布np(µp,Σ p)来拟合先验空间位置,该分布被证明有利于小物体[58,61]和定向物体[61,63]。具体地说,动态的~ s作为高斯的平均向量µp。我们在每个特征点上预设一个与RetinaNet[30]中一样的方形先验(w,h,θ),然后通过[64]计算协方差矩阵Σ p: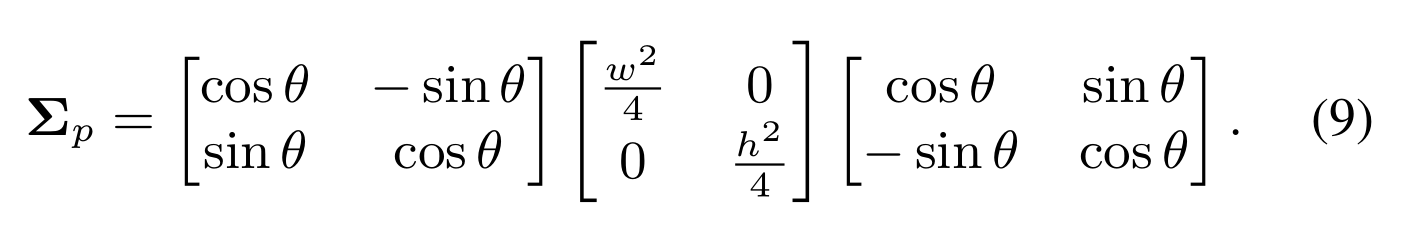
Coarse Prior Matching
给定一组先验,一个基本的分配规则是为特定的gt指定候选真实预测样本的范围。一些自适应策略将给定gt的候选对象限制在单个FPN层内[14,23,68],而一些作品将所有层作为候选对象释放[67,71]。然而,对于有取向的微小对象,前者严格的启发式规则可能导致次优的层选择,后者宽松的启发式规则会导致缓慢的收敛问题[32]。
因此,我们提出了跨FPN层的粗正样本(CPS)候选,与全FPN层的方式相比,它缩小了样本范围,同时丢弃了单层启发式。在CPS中,我们将候选范围略微扩大到gt附近的空间位置和相邻的FPN层,与单层启发式相比,保证了相对多样化和充足的候选,并缓解了数量不平衡问题。
具体来说,构建CPS的相似性度量是通过Jensen-Shannon散度(JSD)实现的[13],它继承了Kullback-Leibler散度(KLD)[63]的尺度不变性,可以度量gt与附近无重叠先验的相似性[58,63]。此外,它还克服了KLD不对称的缺点。然而,高斯分布之间的JSD的闭形式解是不可用的[39],因此,我们使用广义Jensen-Shannon Diver- ence (GJSD)[39],产生一个作为替代的闭形式解。
例如,两个高斯分布N p(µp,Σ p)和N g(µg,Σ g)之间的GJSD定义为:
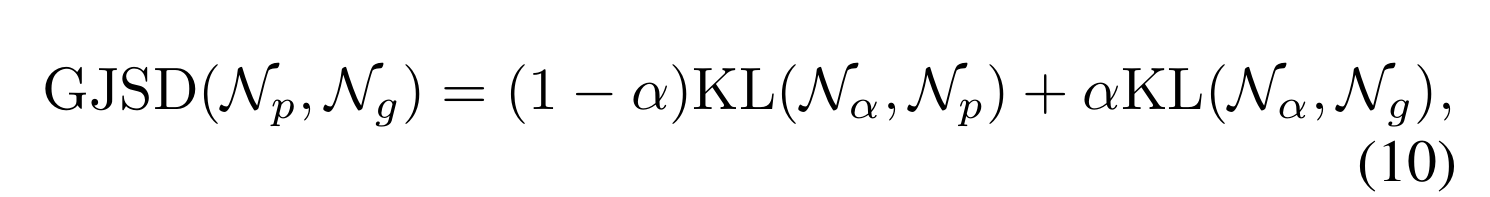
KL为KLD, N α(µα,Σ α)由式给出: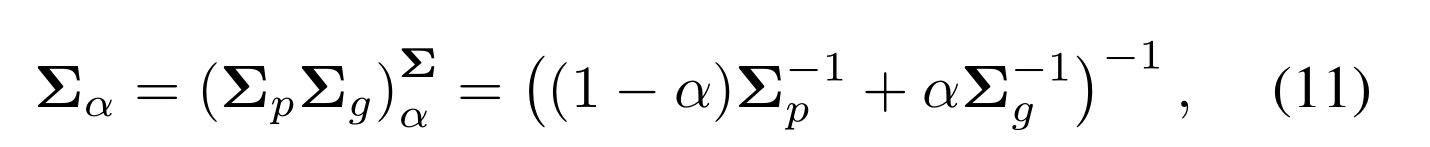

注意,在相似性度量中,α是控制两个分布权重的参数[39]。在我们的工作中,N p和N g的贡献相等,因此α设为0.5。
最终,对于每个gt,我们选择K个GJSD得分最高的先验作为粗糙正样本(CPS),其余先验作为负样本,这种粗糙匹配作为Eq. 6中的M s。排序方式与GJSD测量一起构建跨FPN层CPS,消除了MaxIou匹配异常角度和尺度所带来的不平衡问题
Finer Dynamic Posterior Matching
基于粗阳性样本(CPS)候选,我们设计了一个动态后验(预测)匹配规则M d来过滤掉低质量的样本。该模型包括两个关键部分,即后验重新排序策略和动态高斯混合模型(DGMM)约束。
我们根据他们的预测分数在CPS中重新排列样本候选人。也就是说,我们通过其成为真实预测的可能性(PT)来进一步完善阳性样本[14],PT是预测的分类得分和位置得分与gt的线性组合。我们将第i个样本Di的PT定义为: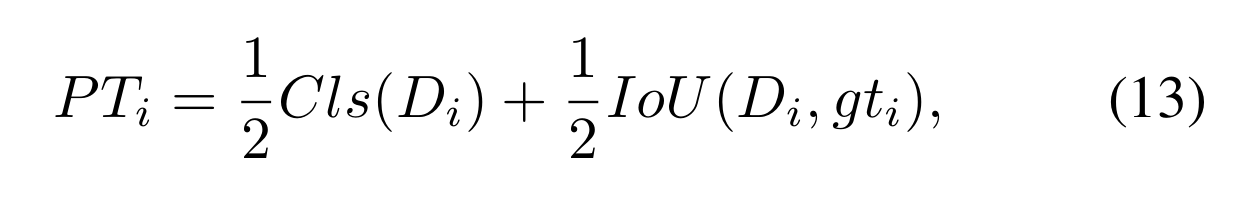
Cls为预测的分类置信度,IoU为预测位置与其对应的gt位置之间的旋转IoU。我们选择Q最高PT的候选者作为中等阳性样本(MPS)候选者。
接下来,我们用更精细的实例表示过滤掉那些离gts太远的样本,得到更精细的正样本(FPS)。与以前使用中心概率图[53]或单高斯[23,64]作为实例表示的工作不同,我们使用更精细的DGMM来表示实例。它由两个部分组成:一个以对象的几何中心为中心,另一个以对象的语义中心为中心。具体而言,对于特定实例gt i,几何中心(cxi,cy i)作为第一个高斯的平均向量µi,1,语义中心(sxi,sy i)作为µi,2,这是通过平均MPS中样本的位置推导出来的。也就是说,我们将实例参数化为: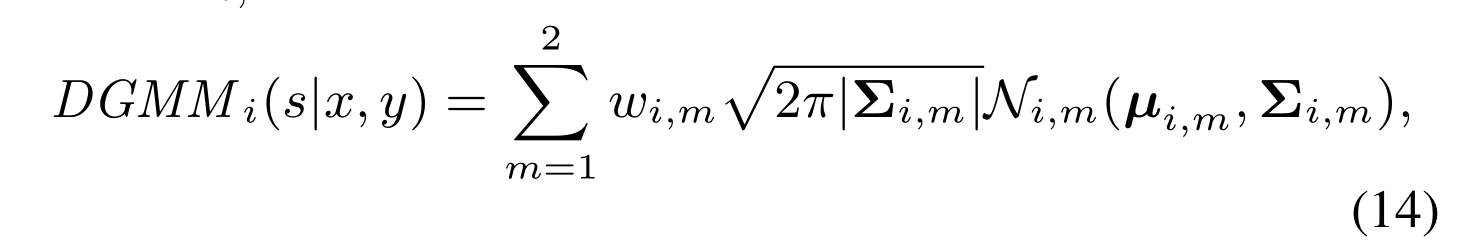
其中wi,m是每个高斯函数的权值1,Σ i,m等于gt的Σ g。MPS中的每个样本都有DGMM评分DGMM(s|MPS),我们对DGMM(s|MPS) < e - g的样品设置负掩模,gt, g是任意可调的。
Experiments
Datasets
实验在六个数据集上进行,即DOTA- v1.0 [55]/v1.5/v2.0[11]、DIOR-R[7]、VisDrone[12]和MS COCO[31]。在烧蚀研究和分析中,我们选择大规模的DOTA-v2.0训练集进行训练,val集进行评估,其中包含了大量的微小物体。为了与其他方法进行比较,我们使用DOTA-v1.0、DOTA- v1.5、DOTA-v2.0和DIOR-R的训练集进行训练,并使用它们的测试集进行测试,我们选择了VisDrone2019、MS COCO训练集、val集进行训练和测试。
Implementation Details
我们所有的实验都是在一台NVIDIA RTX 3090 GPU的计算机上进行的,批处理大小设置为4。使用PyTorch[41]基于MMDetection[6]和MMRotate[70]构建模型。ImageNet[45]预训练模型被用作主干。随机梯度下降(SGD)优化器用于学习率为0.005,动量为0.9,权衰减为0.0001的训练。如果没有指定,带FPN[29]的ResNet-50[20]是缺省骨干网。我们使用Focal loss[30]进行分类,IoU loss[66]进行回归。我们只使用随机翻转作为所有实验的数据增强。
Main Results
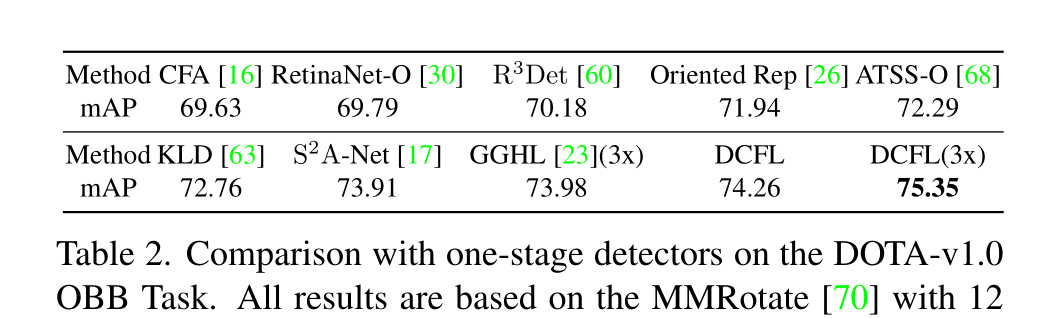
Results on DOTA series
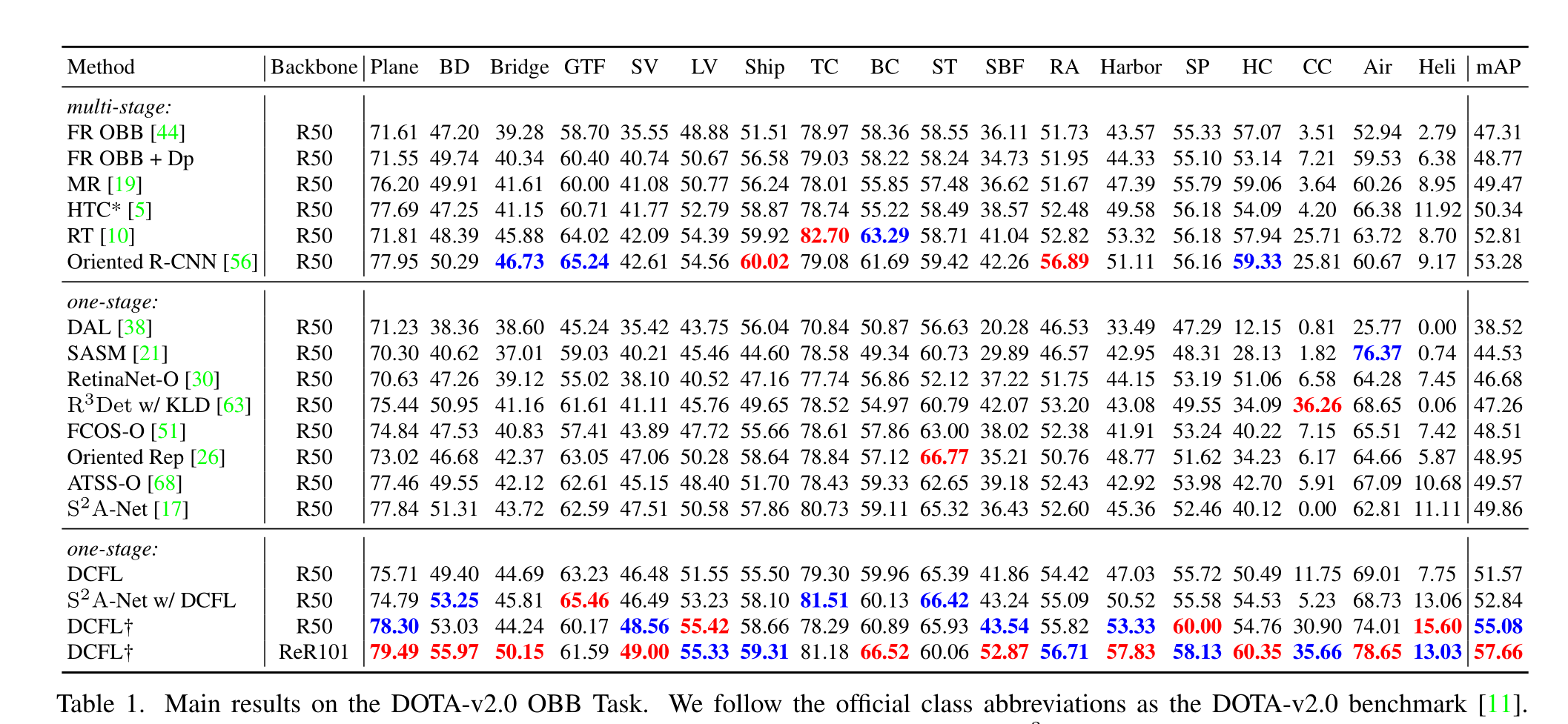
†表示训练40 epoch,红色和蓝色的结果表示每个列的最佳和次佳性能
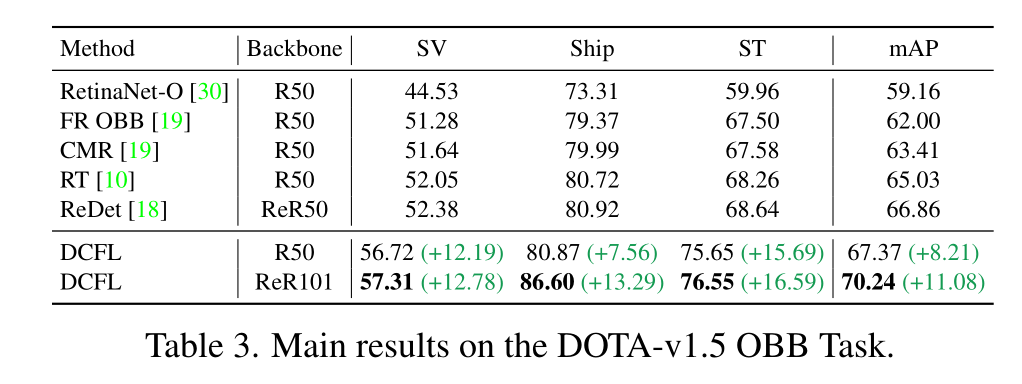
Results on DIOR-R


Resultson HBBDatasets

消融实验

表7给出了个体策略、不同的CPS、固定先验和动态先验、PCB的详细设计以及参数对性能的影响
Analysis
调和不平衡问题
为了深入研究失衡问题,我们计算了持有不同角度和不同尺度(绝对尺寸)的gt的平均预测IoU和平均正样本数。结果如图6所示,这是模型的最后一个训练epoch。本文总结了RetinaNet网络的两种不平衡问题(数量和质量不平衡):(1)分配给每个实例的正样本数量随其角度和尺度的周期性变化,而形状(尺度、角度)不同于预定义先验的对象将持有更少的正样本。(2)预测欠条的尺度周期性变化,但角度保持不变。相比之下,DCFL显著地纠正了这种不平衡:(1)更多的阳性样本被补偿到先前的异常角度和尺度。(2)样品的质量(预测欠条)也可以在各个角度和尺度上得到改善和平衡。以上结果是动态从粗到精学习的理想行为。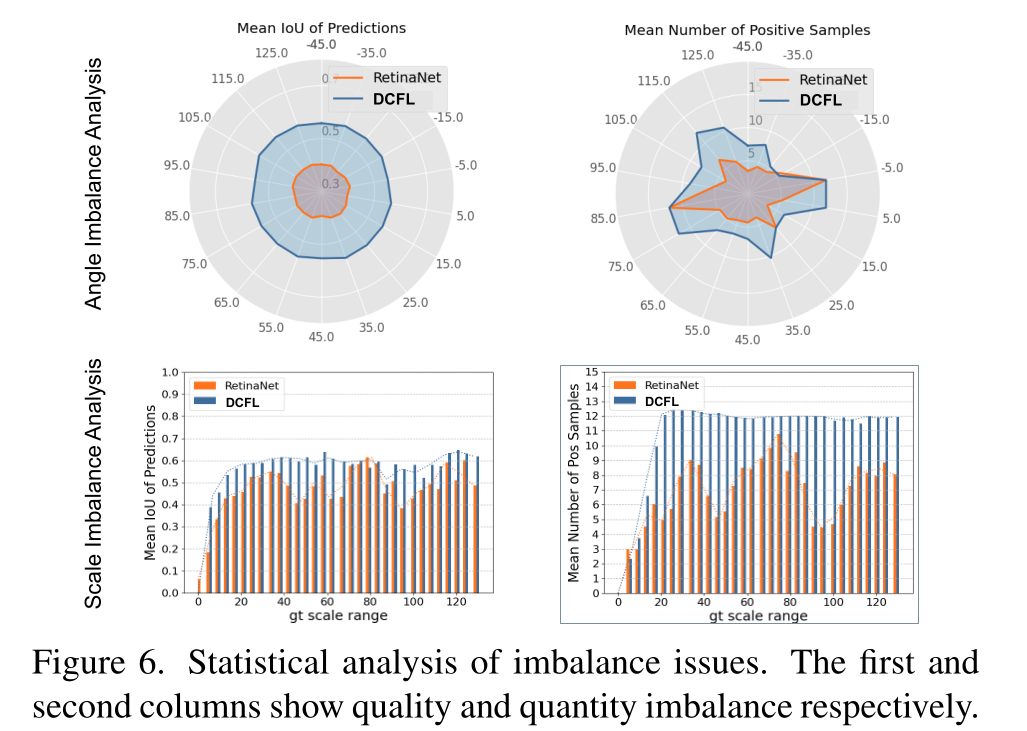
可视化
我们在图5和图7中可视化预测结果和阳性样本。我们可以看到,DCFL显著地消除了假阴性和假阳性预测,特别是对于极端形状的定向微小物体。从图7可以看出,本文提出的策略能够动态生成和采样更适合实例主体的先验,验证了本文动态建模和错配缓解的主张。

第一行是RetinaNet-OBB的结果,第二行是DCFL的结果。TP、FN和FP预测分别用绿色、红色和蓝色标记

速度

Conclusion
本文提出了一种用于定向微小物体检测的DCFL方案。我们发现特征先验不匹配和正样本不平衡是阻碍定向微小物体标签分配的两个障碍。为了解决这些问题,我们提出了一个动态先验来缓解不匹配问题,并提出了一个从粗到细的分配器来缓解不平衡问题,其中先验、标签分配和ground truth表示都以动态方式重新制定。
)


 求解并行机器调度的程序)







之 线程生命周期管理join() 与 detach())
)






)