udf:一对一的关系
udtf:一对多的关系
udaf:多对一的关系
使用Java实现步骤
自定义编写UDF函数注意:
1.需要继承org.apache.hadoop.hive.ql.exec.UDF
2.需要实现evaluete函数
编写UDTF函数注意:
1.需要继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
2.实现 initialize, process, close三个方法
1.自定义实现一个大小写转换的函数(UDF)
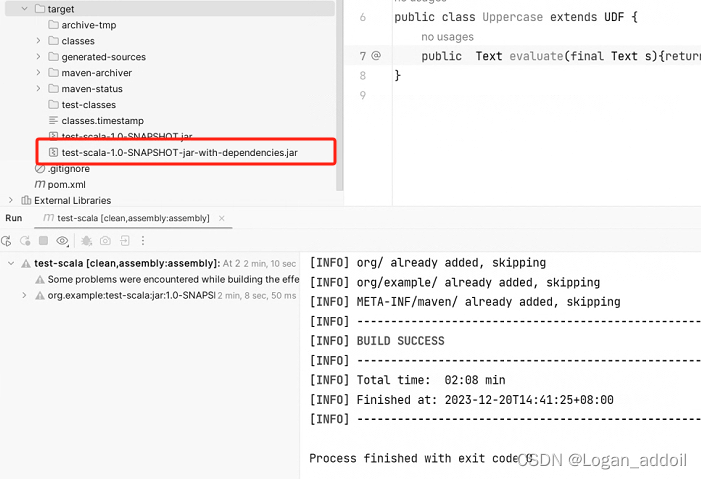
执行mvn命令
将jar包上传到服务器上
上传之后,进入hive,添加jar包
add jar ///xxx.jar(jar包全路径)
创建临时函数
create temporary function upper_func as ‘org.example.Uppercase’;

之后,可以直接在查询中使用

transform方式
hive中除了使用Java编写udf,还可以使用transform,支持多种语言
例如: 将表第一列与第二列用 _ (下划线) 连接
1.Linux中的 awk
创建一个transform.awk
内容
{print $1"_"$2
}
在hive中使用add file 添加 transform.awk
然后就可以调用函数了
select transform(col1,col2) using “awk -f transform.awk” as (uu) from test_table limit 10;
2.使用python
在hive中使用 add file 添加 transform.py
使用命令调用函数
select transform(col1,col2) using “python transform.py” as (uu) from test_table limit 10;
3.基于python实现wordcount
整个过程模拟map 和 reduce
add file 上传 mapper.py 和 reduce.py
创建一张表,保存结果
create table word_cnt(
word string ,
cnt int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
WITH map_cnt as (
select transform(line) using "python mapper.py" as word , cnt
from docs
cluster by word ),insert overwrite table word_cnt
select transform(word,cnt) using "python reduce.py" as w, c
from map_cnt





STM32 NVIC 中断、优先级管理及 AFIO 时钟的开启)

——卷积自编码器(Convolutional Autoencoder))

)




❀)
:评价方法计算实例:计算BLEU-N得分【理论到程序】)
)
Snap)

