一、前言
在mysql一主两从架构的前提下,引入读写分离组件,可以极大的提高mysql性能,proxysql可以在高可用mysql架构发生主从故障时,进行自动的主从读写节点切换,即当mysql其他从节点当选新的主节点时,proxysql会自动识别,6033端口为mysql命令调用端口,6032端口为proxysql的管理端口
二、部署
需要先部署mysql主从架构或者mysql高可用架构,mysql主从架构没有高可用功能,mysql高可用架构拥有高可用功能,使用主从架构发生故障没有主从切换功能,所有proxysql也不会进行故障切换
主从参考:mysql一主两从读写分离搭建_mysql 一主两从搭建-CSDN博客
高可用参考: mysql mha高可用-CSDN博客
在github上下载proxysql rpm安装包
参考: Releases · sysown/proxysql · GitHub
我这里使用的是 2.4.0版本的安装包,太新版本的配置了读写组后会出现mysql_servers库的组id不会自动更改识别,但是proxysql的读写分离和故障切换功能都是正常的,并没有影响
创建proxysql安装包存放目录
mkdir /opt/proxysql && cd /opt/proxysql
ls

安装proxysql
yum -y install proxysql-2.4.0-1-centos7.x86_64.rpm
在mysql创建监控用户
mysql -u root -p
grant select on *.* to 'monitor'@'%' identified by '12345678';
flush privileges;
登陆proxysql配置读写分离
mysql -u admin -padmin -h 127.0.0.1 -P6032 --prompt='Admin>'插入后端mysql信息
#组id都配置都无所谓,后面通过配置了识别read_only分配读写分离组,id会自动变更到对应组
INSERT INTO mysql_servers(hostgroup_id,hostname,port) VALUES (1,'10.1.60.113',3306);
INSERT INTO mysql_servers(hostgroup_id,hostname,port) VALUES (1,'10.1.60.114',3306);
INSERT INTO mysql_servers(hostgroup_id,hostname,port) VALUES (1,'10.1.60.115',3306);查看插入的mysql信息
select * from mysql_servers
 配置后端mysql的监控用户
配置后端mysql的监控用户
UPDATE global_variables SET variable_value='monitor' WHERE variable_name='mysql-monitor_username';
UPDATE global_variables SET variable_value='12345678' WHERE variable_name='mysql-monitor_password';
update global_variables set variable_value='2000' where variable_name in ('mysql-monitor_connect_interval','mysql-monitor_ping_interval','mysql-monitor_read_only_interval');查看修改后的配置
SELECT * FROM global_variables WHERE variable_name LIKE 'mysql-monitor_%';

使配置生效与保存配置
load mysql servers to runtime;
save mysql servers to disk;查看对后端的健康检查结果
SELECT * FROM monitor.mysql_server_connect_log ORDER BY time_start_us DESC LIMIT 3;
SELECT * FROM monitor.mysql_server_ping_log ORDER BY time_start_us DESC LIMIT 3;
配置主从切换的自动检测即检测read_only状态分配到读组或写组
INSERT INTO mysql_replication_hostgroups (writer_hostgroup,reader_hostgroup,comment) VALUES (1,2,'cluster1');使配置生效
LOAD MYSQL SERVERS TO RUNTIME;检查是否生效
SELECT * FROM monitor.mysql_server_read_only_log ORDER BY time_start_us DESC LIMIT 3;
可以看到已经识别到后端不同mysql节点的read_only状态
现在查看mysql_servers表也会发现之前配置的相同的id也自动更改为根据主从节点分配的读写组id

配置读写分离规则
#注意规则配置的顺序代表匹配的顺序,前面的匹配不到才会匹配后面的
#select命令中这有一条特殊的加锁命令,是需要写操作的,所以第一条规则是匹配到写id组
#第二条规则匹配所有读命令,匹配到读id组,这两条规则就可以实现读写分离
insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)values(1,1,'^SELECT.*FOR UPDATE$',1,1);
insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)values(2,1,'^SELECT',2,1);查看配置的读写分离规则
SELECT match_digest,destination_hostgroup FROM mysql_query_rules WHERE active=1;
在proxysql中配置mysql存在的用户
INSERT INTO mysql_users(username,password,default_hostgroup) VALUES ('root','12345678',1);
INSERT INTO mysql_users(username,password,default_hostgroup) VALUES ('deploy','12345678',1);查看配置的用户
SELECT * FROM mysql_users;
保存与使配置生效
LOAD MYSQL QUERY RULES TO RUNTIME;
save mysql servers to disk;使用以上配置的用户在其他mysql中调用proxysql端口执行命令验证读写分离
mysql -u root -p -h10.1.60.115 -P6033 -e "select * from mysql.user"
查找执行命令表查询命令在哪台主机执行
SELECT * FROM stats.stats_mysql_connection_pool;
可以每执行一条就查询一次就可以看出读写分离的效果了
也可以通过以下命令直接查询命令在哪个组执行了来验证是否进行了读写分离
SELECT hostgroup hg, sum_time, count_star, digest_text FROM stats_mysql_query_digest ORDER BY sum_time DESC; 可以看到读操作都分配在了组id为2的读组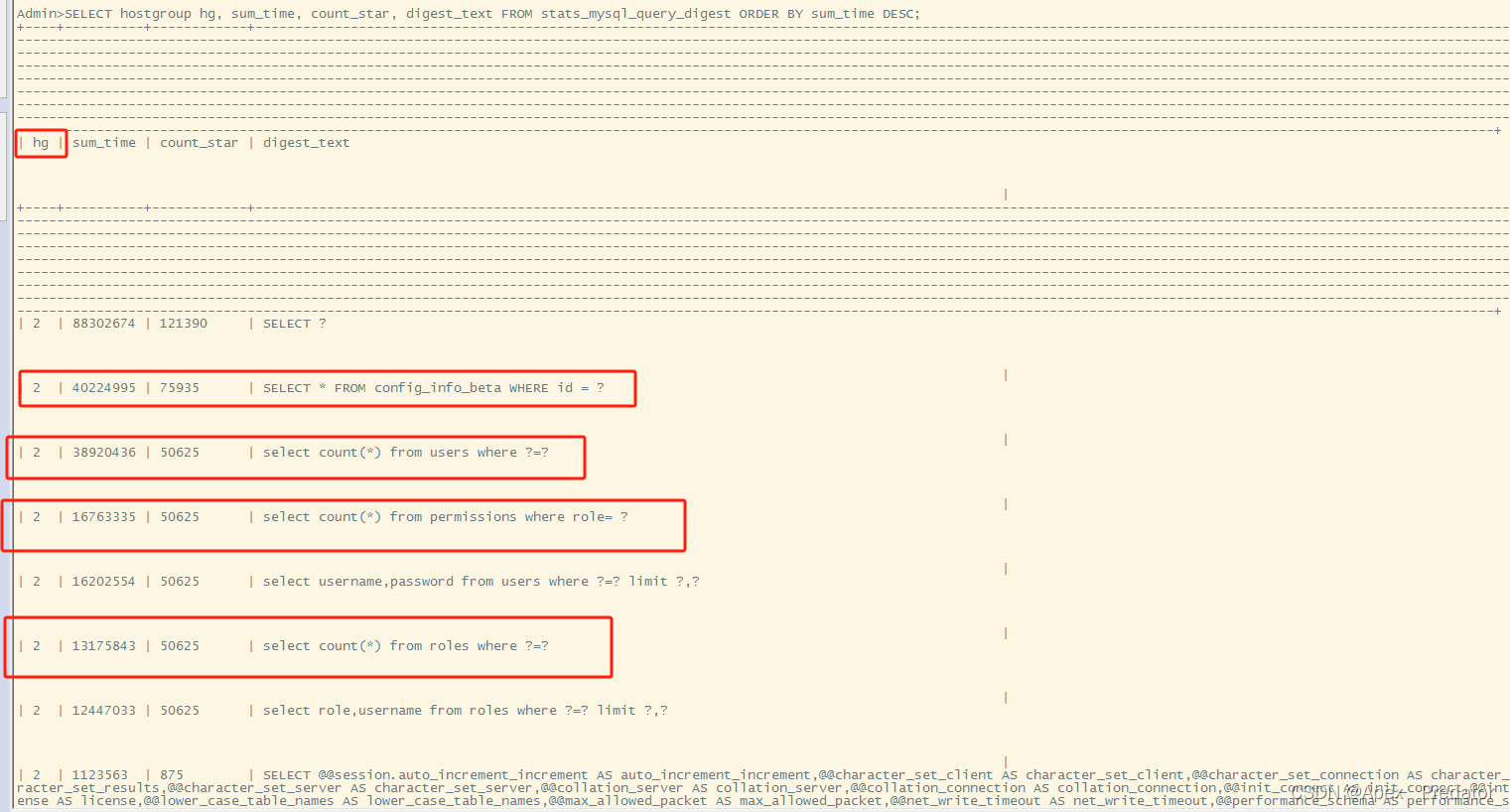
至此proxysql 读写分离配置完成,关于主从的故障切换可以通过mysql高可用架构自行验证,当mysql的主节点挂掉,先由高可用组件实现主从的故障切换,选出新的主节点,然后proxysql根据每个mysql节点的read_only变化去变更mysql节点所在的读写组实现读写节点的切换
关于proxysql的高可用可以通过keepalived组件实现,即再部署一个proxysql,在两个proxysql上部署keepalived高可用组件实现














)

)


