文章目录
- 1.源程序比较其性能影响
- 2.内存分配
- (1)静态存储区(static):
- (2)栈区(stack):
- (3)堆区(heap):
- (4)文字常量区:
- (5)程序代码区:
- 举例:
- 注意字符串“abc”与“123”的区别:
- 3.程序执行时间
- (1)`time( )`
- (2)`clock( )`
- (3)`QueryPerformanceCounter( )`
- (4)`GetTickCount( )`
- (5)`RDTSC指令`
- 上述计时方法的比较:
- 源程序和执行结果分析:
- 源程序和执行结果
- 1. 给出源程序(文本文件)和执行结果。
- 2.对实验结果进行分析,说明局部数据块大小、数组访问顺序等和执行时间之间的关系。
- (3)分析说明数组a分配在静态存储区、堆区和栈区,对for循环段的执行效率有没有影响。
- 总结
通过实际程序的执行结果,了解程序访问的局部性对带有cache的计算机系统性能的影响。
1.源程序比较其性能影响
在以下程序中,修改或添加必要的语句(如添加计时函数等),以计算和打印主体程序段(即for循环段)的执行时间。分别以M=10、N=100000;M=1000、N=1000;M=100000、N=10;执行程序A和程序B,以比较两种for循环段执行时间的长短。
下列程序中给出的数组a是局部临时变量,分配在栈中,也可改用静态全局变量,或在堆中动态申请空间。
- 程序段A:
void assign_array_rows( )
{int i, j;short a[M][N];for(i= 0; i<M; i++)for(j= 0; j<N; j++)a[i][j]=0;
}
- 程序段B:
void assign_array_cols( )
{int i, j;short a[M][N];for(j= 0; j<N; j++)for(i=0; i<M; i++)a[i][j]=0;
}
2.内存分配
可编程内存基本上分为:静态存储区、堆区和栈区等。它们的功能不同,使用方式也不同。
(1)静态存储区(static):
在程序编译的时候就已经分配好,这块内存在程序的运行期间都存在,程序结束后由系统释放。它主要存放静态数据、全局数据和常量。
(2)栈区(stack):
由编译器自动分配、释放,无需手工控制。在执行函数时,用来存放函数内局部变量,函数执行结束时这些存储单元自动被释放。
栈区是向低地址扩展的数据结构,是一块连续的内存的区域。栈区的操作方式类似于数据结构中的栈,是一个先进后出的队列,进出一一对应,不会产生碎片。
栈内存分配运算内置于处理器的指令集中,效率很高。栈区栈顶的地址和栈的最大容量是系统预先规定好的,在 Windows下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),因此,栈区分配的内存容量较小。如果申请的空间小于栈的剩余空间,系统会为程序分配内存,如果申请的空间超过栈的剩余空间,系统会报异常,提示栈溢出overflow。
(3)堆区(heap):
由程序员分配、释放,若程序员不释放,程序结束时可能由OS回收。亦称动态内存分配,程序在运行的时候用malloc或new申请任意大小的内存,程序员自己负责在适当的时候用free或delete释放内存,容易产生memory leak(内存泄漏)。
堆区操作由C/C++函数库提供,机制很复杂,所以堆的效率比栈低很多;另外,频繁的new/delete会造成大量碎片,也会使程序效率降低。
堆区分配方式类似于链表。系统有一个记录空闲内存地址的链表,当系统收到程序申请时,遍历该链表,寻找第一个空间大于申请空间的堆结点,删除空闲结点链表中的该结点,并将该结点空间分配给程序。大多数系统会在这块内存空间首地址记录本次分配的大小,这样delete才能正确释放本内存空间;另外,系统会将多余的部分重新放入空闲链表中。堆区大小受限于计算机系统中有效的虚拟内存(32bit系统理论上是4G),所以堆的空间比较灵活,比较大。
堆是向高地址扩展的数据结构,是不连续的内存区域(因为系统是用链表来存储堆区的空闲内存地址的,自然堆区是不连续的内存区域,而链表的遍历方向是由低地址向高地址)。
(4)文字常量区:
存放常量字符串,程序结束后由系统释放。
(5)程序代码区:
存放程序的二进制代码。
举例:
#include <stdio.h>
#include <stdlib.h>
int a=0;//全局变量,存放在静态存储区
int main()
{ int b;//局部变量,存放在栈区static int c;//静态局部变量,存放在静态存储区char s[]="abc";//数组的元素属于局部变量,存放在栈区char *p="123";//字符串常量"123"存放在静态存储区,指针变量p存放在栈区char *p1=(char *)malloc(10);//指针变量p1存放在栈区,申请来得10个字节的区域在堆区
}
注意字符串“abc”与“123”的区别:
- 字符串
“abc”、“123”存放在不同的区域,因为“abc”存在于数组中,即存储于栈区,而“123”为字符串常量,存储在静态存储区。 - “abc”是在程序运行时赋值的,而“123”是在编译时就确定的。
- 假设有如下语句
①s[0]='0';
②p[0]='0';
语句①没有问题,“abc”存放于数组中,此数据存储于栈区,对它修改是没有任何问题的。
但语句②有问题,“123”为字符串常量,存储在静态存储区,虽然通过p[0]可以访问到静态存储区中的第一个数据,即字符‘l’所在的存储的单元。但是因为“123”为字符串常量,不可以改变,所以语句“p[0]='0';”在程序运行时,会报告内存错误。
3.程序执行时间
通常先调用计时函数记下当前时间tstart,然后处理一段程序,再调用计时函数记下处理后的时间tend,就可以得到程序的执行时间(t = tend - tstart)。
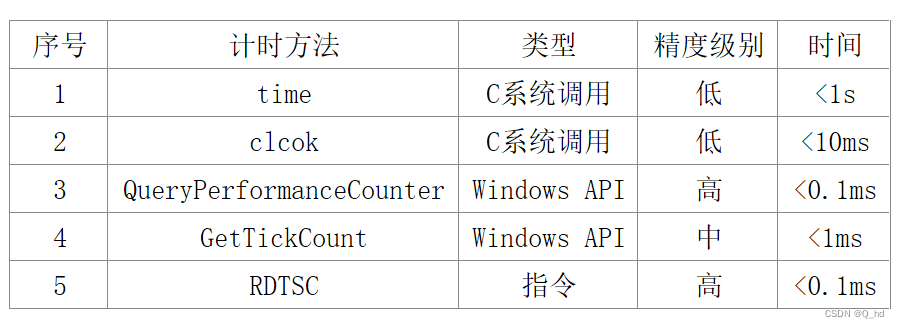
常用计时方法有:time、clcok、QueryPerformanceCounter、GetTickCount、RDTSC。
(1)time( )
获取当前的系统时间,返回的结果是一个time_t类型,其实就是一个大整数,其值表示从CUT(Coordinated Universal Time)时间1970年1月1日00:00:00(称为UNIX系统的Epoch时间)到当前时刻的秒数。
#include <stdio.h>
void fun( )
{//dosomethinglong i;for(i=0;i<1000000000;i++);}
int main()
{ time_t start,stop;//定义时间类型变量start = time(NULL);fun(); stop = time(NULL);printf("Use Time:%ld\n",(stop-start));
}
- 程序运行结果:
Use Time:1
(2)clock( )
函数返回从“开启这个程序进程”到“程序中调用clock( )函数”时之间的CPU时钟计时单元(clock tick)数,在MSDN中称之为挂钟时间(wal-clock)。常量CLOCKS_PER_SEC表示一秒钟会有多少个时钟计时单元。
#include <stdio.h>
#include <time.h>//包含头文件
void fun( )
{//dosomethinglong i;for(i=0;i<1000000000;i++);}
int main()
{ double dur;clock_t start,end;//定义时钟类型变量start = clock();fun(); end = clock();dur = (double)(end - start);printf("Use Time:%f\n",(dur/CLOCKS_PER_SEC));//时钟个数除以时钟频率即为所花时间
}
- 程序运行结果:
Use Time:1.980000
(3)QueryPerformanceCounter( )
函数返回高精确度性能计数器的值,它可以以微妙为单位计时。但是QueryPerformanceCounter()确切的精确计时的最小单位是与系统有关的,所以,必须要查询系统以得到QueryPerformanceCounter()返回的嘀哒声的频率。QueryPerformanceFrequency()提供了这个频率值,返回每秒嘀哒声的个数。
#include <stdio.h>
#include <windows.h>//包含头文件
void fun( )
{//dosomethinglong i;for(i=0;i<1000000000;i++);
}
int main()
{ LARGE_INTEGER t1,t2,tc;QueryPerformanceFrequency(&tc);QueryPerformanceCounter(&t1);fun();QueryPerformanceCounter(&t2);printf("Use Time:%f\n",(t2.QuadPart - t1.QuadPart)*1.0/tc.QuadPart);//前后滴答数之差除以1秒钟的滴答数,即得时间秒数
}
- 程序运行结果:
Use Time:1.821330
(4)GetTickCount( )
函数返回从操作系统启动到现在所经过的毫秒数,它的返回值是DWORD。
#include <stdio.h>
#include <windows.h>//包含头文件
void fun( )
{//dosomethinglong i;for(i=0;i<1000000000;i++);
}
int main()
{ DWORD t1,t2;t1 = GetTickCount();fun();//dosomethingt2 = GetTickCount();printf("Use Time:%f\n",(t2-t1)*1.0/1000);//将毫秒值转成秒值
}
- 程序运行结果:
Use Time:1.937000
(5)RDTSC指令
rdtsc 指令是 x86 架构下的一条汇编指令,全称 “Read Time-Stamp Counter”,用于读取时间戳计数器(TSC),CPU 的每个时钟周期会对其(TSC)进行加一操作。通过rdtsc指令读取这个计数器,可以测量程序某段代码的执行时间。
时间戳计数器(TSC)是一个64位的寄存器,低32位存储在EAX寄存器(在 64 位架构下为RAX寄存器),高32位存储在EDX寄存器(在 64 位架构下为RDX寄存器)。通常使用内联汇编“__asm__ volatile("rdtsc" : "=a"(low), "=d"(high));”将高32位和低32位组合成一个64位无符号整数,作为rdtsc( )函数的返回值。
#include <stdio.h>
#include <stdint.h>//包含头文件
#define FREQUENCY (3.2*1e9)
//3.2GHz,需要事先查看自己电脑的CPU工作频率,定义成符号常量
void fun( )
{//dosomethinglong i;for(i=0;i<1000000000;i++);
}
static inline uint64_t rdtsc()
{uint32_t low, high;__asm__ volatile("rdtsc" : "=a"(low), "=d"(high));return (uint64_t)high << 32 | low;
}
int main()
{ uint64_t t1,t2;t1 = rdtsc();fun();t2 = rdtsc();printf("Use Time:%f\n",(t2 - t1)*1.0/FREQUENCY);//FREQUENCY为CPU的频率
}
- 程序运行结果:
Use Time:1.788094
上述计时方法的比较:
源程序和执行结果分析:
源程序和执行结果
1. 给出源程序(文本文件)和执行结果。
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>#define M 10
#define N 100000 // 静态存储区数组
static short staticArray[M][N];void assign_array_rows_static() {int i, j;for (i = 0; i < M; i++)for (j = 0; j < N; j++)staticArray[i][j] = 0;
}void assign_array_cols_static() {int i, j;for (j = 0; j < N; j++)for (i = 0; i < M; i++)staticArray[i][j] = 0;
}void assign_array_rows_stack() {int i, j;short stackArray[M][N]; // 栈区数组for (i = 0; i < M; i++)for (j = 0; j < N; j++)stackArray[i][j] = 0;
}void assign_array_cols_stack() {int i, j;short stackArray[M][N]; // 栈区数组for (j = 0; j < N; j++)for (i = 0; i < M; i++)stackArray[i][j] = 0;
}void assign_array_rows_heap() {int i, j;short(*heapArray)[N] = (short(*)[N])malloc(M * sizeof(short[N])); // 堆区数组for (i = 0; i < M; i++)for (j = 0; j < N; j++)heapArray[i][j] = 0;free(heapArray);
}void assign_array_cols_heap() {int i, j;short(*heapArray)[N] = (short(*)[N])malloc(M * sizeof(short[N])); // 堆区数组for (j = 0; j < N; j++)for (i = 0; i < M; i++)heapArray[i][j] = 0;free(heapArray);
}double getElapsedTime(LARGE_INTEGER start, LARGE_INTEGER end, LARGE_INTEGER frequency) {return ((double)(end.QuadPart - start.QuadPart) / frequency.QuadPart) * 1000;
}void measure_time(void (*f)(), const char* desc) {LARGE_INTEGER start, end, frequency;double elapsed;QueryPerformanceFrequency(&frequency);QueryPerformanceCounter(&start);f();QueryPerformanceCounter(&end);elapsed = getElapsedTime(start, end, frequency);printf("%s: %f milliseconds\n", desc, elapsed);
}int main() {printf("M=%d, N=%d\n", M, N);measure_time(assign_array_rows_static, "Static - Rows");measure_time(assign_array_cols_static, "Static - Cols");measure_time(assign_array_rows_stack, "Stack - Rows");measure_time(assign_array_cols_stack, "Stack - Cols");measure_time(assign_array_rows_heap, "Heap - Rows");measure_time(assign_array_cols_heap, "Heap - Cols");return 0;
}
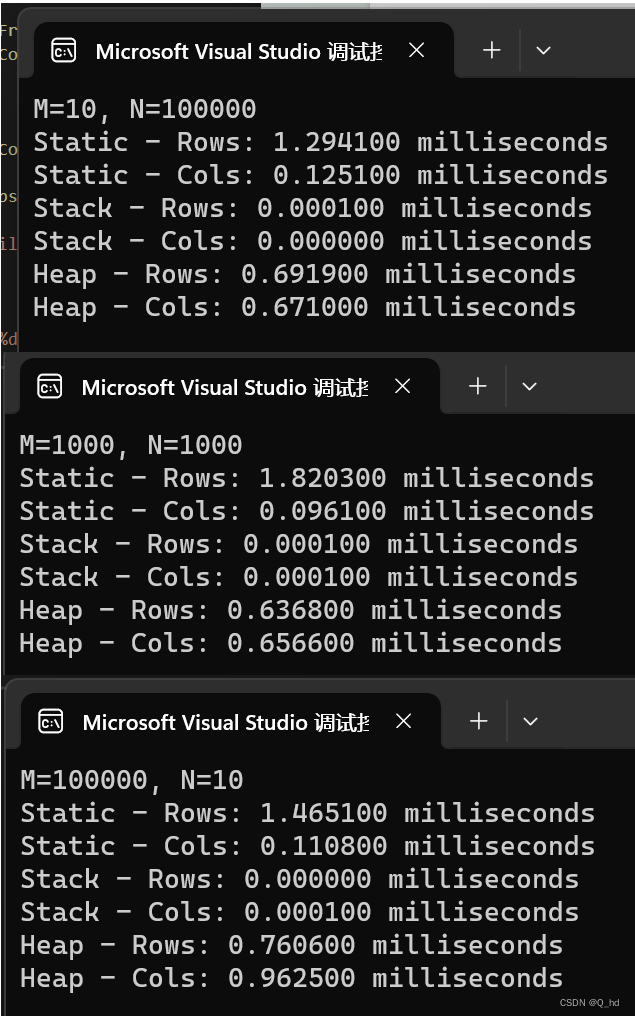
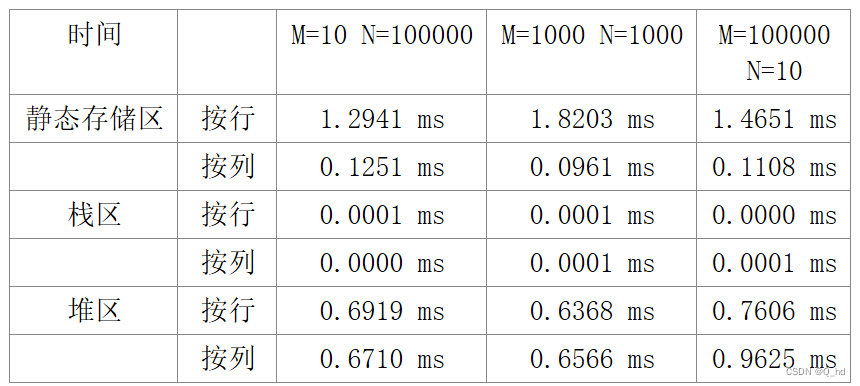
2.对实验结果进行分析,说明局部数据块大小、数组访问顺序等和执行时间之间的关系。
根据上面的数据,我们可以得出以下结论:
-
理论上:静态存储区按行访问比按列访问速度更快,这是因为静态存储区的元素是在内存中连续存储的,按行访问时可以利用CPU缓存的局部性原理,将靠近的元素一起读入缓存,提高访问速度。
但是,实际上:按列赋值的时间更短,这其中可能的原因是:
(1)编译器优化:不同的编译器可能对代码进行不同的优化。在这样的情况下,按列赋值的代码可能被编译器优化得更好,生成更高效的机器代码。
(2)缓存局部性:按列赋值可能更好地利用了缓存局部性。由于内层循环按列访问数组元素,可能更接近数组在内存中的布局方式,从而更容易利用CPU的缓存机制,减少内存访问延迟。
(3)并行计算:现代CPU通常具有多个处理单元,可以执行并行计算。按列赋值可能更容易实现并行计算,因为内层循环的迭代是独立的,可以同时进行多个迭代。 -
栈区比静态区和堆区快的原因主要有两个方面:
(1)内存分配方式:栈区采用的是先进后出的方式进行内存的分配和释放,而静态区和堆区则是通过动态内存管理进行分配和释放。由于栈区的分配和释放操作相对简单,在编译时就确定了变量的生命周期和作用域,因此执行效率更高。
(2)访问方式:栈区的数据访问是通过指针进行的,而静态区和堆区通过指针或引用进行访问。指针直接指向栈区的数据,访问速度更快;而静态区和堆区的数据需要通过指针或引用来间接访问,多了一层间接寻址的过程,相对较慢。
需要注意的是,栈区虽然速度较快,但是其空间有限,内存分配和释放都是自动完成的,不适合存储大量的数据或者需要动态调整大小的数据结构。而静态区和堆区可以用于存储较大的数据或者需要动态管理的数据结构,但是其分配和释放操作相对复杂,效率相对较低。因此,在选择数据存储区域时,需要根据具体的需求综合考虑。 -
理论上:在堆区中,按行访问速度比按列访问速度稍快,这可能是因为堆区内存的分配方式导致元素不是完全连续存储的,按行访问可以利用CPU缓存的预取原理,将下一个元素提前读入缓存,避免了cache miss的情况。
但是,实际上:按行与按列访问的速度差不多,这可能是因为编译器的优化。 -
在结合cache局部数据块大小、数组访问顺序等方面考虑,我们可以通过一些技巧来优化数组的访问效率,例如按照列访问时,可以将数组转置,使得元素在内存中更加连续,从而利用CPU缓存的局部性原理;另外,还可以利用循环展开、向量化等技术,使得CPU可以一次处理多个元素,提高访问速度。
(3)分析说明数组a分配在静态存储区、堆区和栈区,对for循环段的执行效率有没有影响。
根据上面的实验结果,我们可以看出:
- 静态存储区按列访问的时间最短,按行访问的时间稍长。说明数组在静态存储区按列存储时,访问效率较高。
- 栈区访问的时间最短,几乎可以忽略不计。说明数组在栈区分配时,访问效率最高。
- 堆区按行和按列访问的时间相差不大,但都比栈区慢,并且比静态存储区略慢一些。说明数组在堆区分配时,访问效率较低。
因此,从执行效率的角度考虑,数组在栈区分配时最优,其次是在静态存储区按列存储,最劣的是在堆区分配。但需要注意的是,数组的分配位置还应该考虑内存空间的大小和使用需求等因素,而不仅仅只考虑执行效率。
总结
通过对比不同存储区域(静态存储区、堆区和栈区)中数组的访问效率,分析了局部数据块大小、数组访问顺序等与执行时间之间的关系。实验结果表明,静态存储区按列访问最快,栈区访问速度最快,堆区访问相对较慢;同时,不同编译器、缓存机制等因素也会影响访问效率。因此,在选择存储区域时需要综合考虑执行效率、内存空间大小和使用需求等因素。

)
)

![力扣第13题-罗马数字转整数[简单]](http://pic.xiahunao.cn/力扣第13题-罗马数字转整数[简单])










![[C语言]大小端及整形输出问题](http://pic.xiahunao.cn/[C语言]大小端及整形输出问题)



