在实际应用中,数据的类型多种多样,比如文本、音频、图像、视频等。不同类型的数据,其原始特征的空间也不相同。比如一张灰度图像(像素数量为 𝐷)的特征空间为 [0, 255]𝐷,一个自然语言句子(长度为 𝐿)的特征空间为|𝒱|𝐿,其中𝒱 为词表集合。而很多机器学习算法要求输入的样本特征是数学上可计算的,因此在机器学习之前我们需要将这些不同类型的数据转换为向量表示。
图像特征 :在手写体数字识别任务中,样本 𝑥 为待识别的图像.为了识别 𝑥 是什么数字,我们可以从图像中抽取一些特征。如果图像是一张大小为𝑀 × 𝑁 的图像,其特征向量可以简单地表示为 𝑀 × 𝑁 维的向量,每一维的值为图像中对应像素的灰度值。为了提高模型准确率,也会经常加入一个额外的特征,比如直方图、宽高比、笔画数、纹理特征、边缘特征等.假设我们总共抽取了 𝐷 个特征,这些特征可以表示为一个向量𝒙 ∈ ℝ𝐷。
文本特征 在文本情感分类任务中,样本 𝑥 为自然语言文本,类别 𝑦 ∈ {+1, −1}分别表示正面或负面的评价。为了将样本𝑥 从文本形式转为向量形式,一种简单的方式是使用词袋(Bag-of-Words,BoW)模型。假设训练集合中的词都来自一个词表𝒱,大小为|𝒱|,则每个样本可以表示为一个|𝒱|维的向量𝒙 ∈ ℝ|𝒱|。向量𝒙中第𝑖 维的值表示词表中的第𝑖 个词是否在𝑥中出现。如果出现,值为1,否则为0。
比如两个文本“我 喜欢 读书”和“我 讨厌 读书”中共有“我”“喜欢”“讨厌”“读书”四个词,它们的BoW表示分别为:

词袋模型将文本看作词的集合,不考虑词序信息,不能精确地表示文本信息。一种改进方式是使用N元特征(N-Gram Feature),即每𝑁 个连续词构成一个基本单元,然后再用词袋模型进行表示。
以最简单的二元特征(即两个词的组合特征)为例,上面的两个文本中共有“$ 我”“我喜欢”“我讨厌”“喜欢读书”“讨厌读书”“读书#”六个特征单元,它们的二元特征BoW表示分别为:
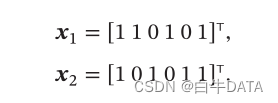
随着 𝑁 的增长,N 元特征的数量会指数上升,上限为 |𝒱|𝑁.因此,在实际应用中,文本特征维数通常在十万或百万级别以上.
表示学习 如果直接用数据的原始特征来进行预测,对机器学习模型的能力要求比较高。这些原始特征可能存在以下几种不足:
1)特征比较单一,需要进行(非线性的)组合才能发挥其作用;
2)特征之间冗余度比较高;
3)并不是所有的特征都对预测有用;
4)很多特征通常是易变的;
5)特征中往往存在一些噪声。
为了提高机器学习算法的能力,我们需要抽取有效、稳定的特征。传统的特征提取是通过人工方式进行的,需要大量的人工和专家知识。一个成功的机器学习系统通常需要尝试大量的特征,称为特征工程。但即使这样,人工设计的特征在很多任务上也不能满足需要。因此,如何让机器自动地学习出有效的特征也成为机器学习中的一项重要研究内容,称为特征学习(Feature Learning),也叫表示学习。
特征学习在一定程度上也可以减少模型复杂性、缩短训练时间、提高模型泛化能力、避免过拟合等。
传统的特征学习
传统的特征学习一般是通过人为地设计一些准则,然后根据这些准则来选取有效的特征,具体又可以分为两种:特征选择和特征抽取。
特征选择
特征选择是选取原始特征集合的一个有效子集,使得基于这个特征子集训练出来的模型准确率最高。简单地说,特征选择就是保留有用特征,移除冗余或无关的特征。
子集搜索 一种直接的特征选择方法为子集搜索。假设原始特征数为 𝐷,则共有 2𝐷 个候选子集.特征选择的目标是选择一个最优的候选子集.最暴力的做法是测试每个特征子集,看机器学习模型哪个子集上的准确率最高。但是这种方式效率太低.常用的方法是采用贪心的策略:由空集合开始,每一轮添加该轮最优的特征,称为前向搜索;或者从原始特征集合开始,每次删除最无用的特征,称为反向搜索。
子集搜索方法可以分为过滤式方法和包裹式方法。
(1)过滤式方法(Filter Method)是不依赖具体机器学习模型的特征选择方法。每次增加最有信息量的特征,或删除最没有信息量的特征。特征的信息量可以通过信息增益来衡量,即引入特征后条件分布𝑝𝜃(𝑦|𝒙)的不确定性(熵)的减少程度。
(2)包裹式方法(Wrapper Method)是使用后续机器学习模型的准确率作为评价来选择一个特征子集的方法。每次增加对后续机器学习模型最有用的特征,或删除对后续机器学习任务最无用的特征。这种方法是将机器学习模型包裹到特征选择过程的内部。
ℓ1 正则化 此外,我们还可以通过 ℓ1 正则化来实现特征选择.由于 ℓ1 正则化会导致稀疏特征,因此间接实现了特征选择。
特征抽取
特征抽取是构造一个新的特征空间,并将原始特征投影在新的空间中得到新的表示。以线性投影为例,令𝒙 ∈ ℝ𝐷 为原始特征向量,𝒙′ ∈ ℝ𝐾 为经过线性投影后得到的在新空间中的特征向量,有

其中𝑾 ∈ ℝ𝐾×𝐷 为映射矩阵。
特征抽取又可以分为监督和无监督的方法。监督的特征学习的目标是抽取对一个特定的预测任务最有用的特征,比如线性判别分析。而无监督的特征学习和具体任务无关,其目标通常是减少冗余信息和噪声,比如主成分分析和自编码器。
表2.2列出了一些传统的特征选择和特征抽取方法:

特征选择和特征抽取的优点是可以用较少的特征来表示原始特征中的大部分相关信息,去掉噪声信息,并进而提高计算效率和减小维度灾难。对于很多没有正则化的模型,特征选择和特征抽取非常必要.经过特征选择或特征抽取后,特征的数量一般会减少,因此特征选择和特征抽取也经常称为维数约减或降维。
深度学习方法
传统的特征抽取一般是和预测模型的学习分离的。我们会先通过主成分分析或线性判别分析等方法抽取出有效的特征,然后再基于这些特征来训练一个具体的机器学习模型。
如果我们将特征的表示学习和机器学习的预测学习有机地统一到一个模型中,建立一个端到端的学习算法,就可以有效地避免它们之间准则的不一致性.这种表示学习方法称为深度学习(Deep Learning,DL)。深度学习方法的难点是如何评价表示学习对最终系统输出结果的贡献或影响,即贡献度分配问题。目前比较有效的模型是神经网络,即将最后的输出层作为预测学习,其他层作为表示学习。
)



)


模式)

![[MySQL]数据库概述](http://pic.xiahunao.cn/[MySQL]数据库概述)



)
)




