目录
一、线性回归关键思想
1、线性模型
2、基础优化算法
二、线性回归的从零开始实现
1、生成数据集
2、读取数据集
3、初始化模型参数
4、定义模型
5、定义损失函数
6、定义优化算法
7、训练
三、线性回归的简洁实现
1、生成数据集
2、读取数据集
3、定义模型
4、初始化模型参数
5、定义损失函数
6、定义优化算法
7、训练
一、线性回归关键思想
1、线性模型

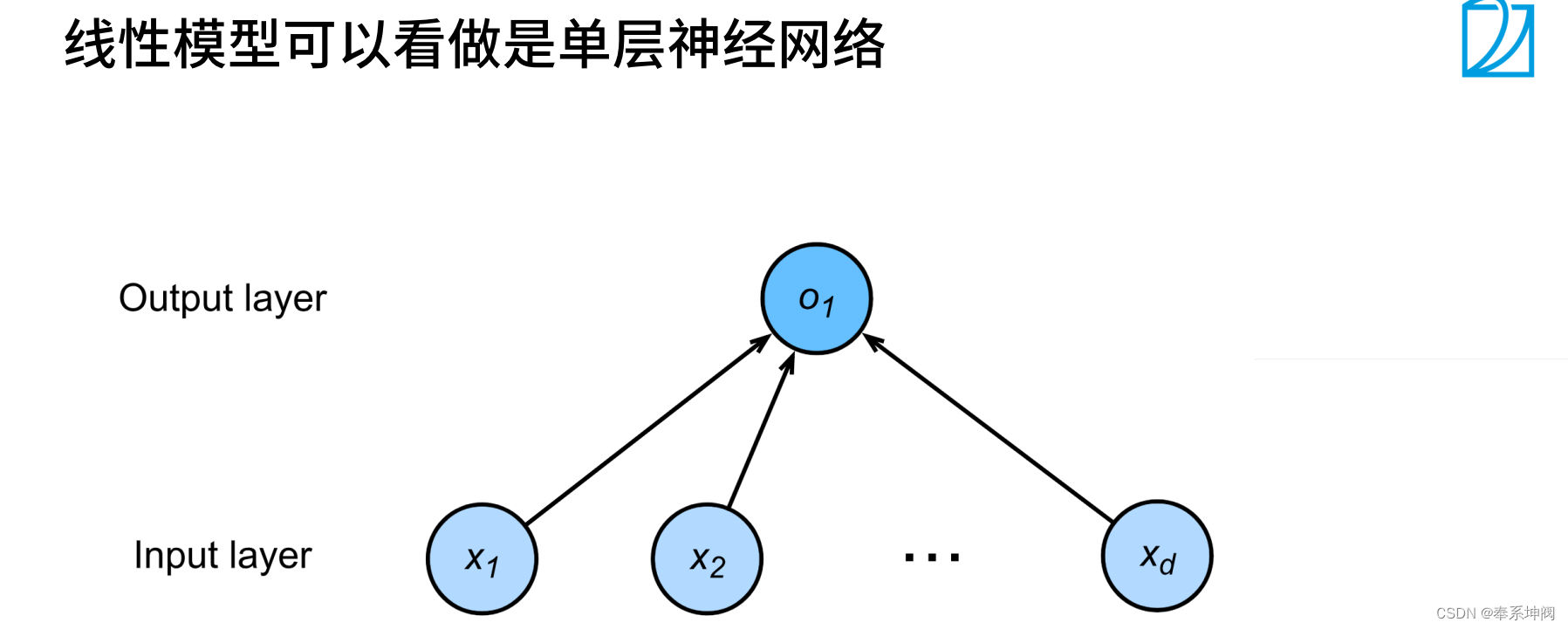
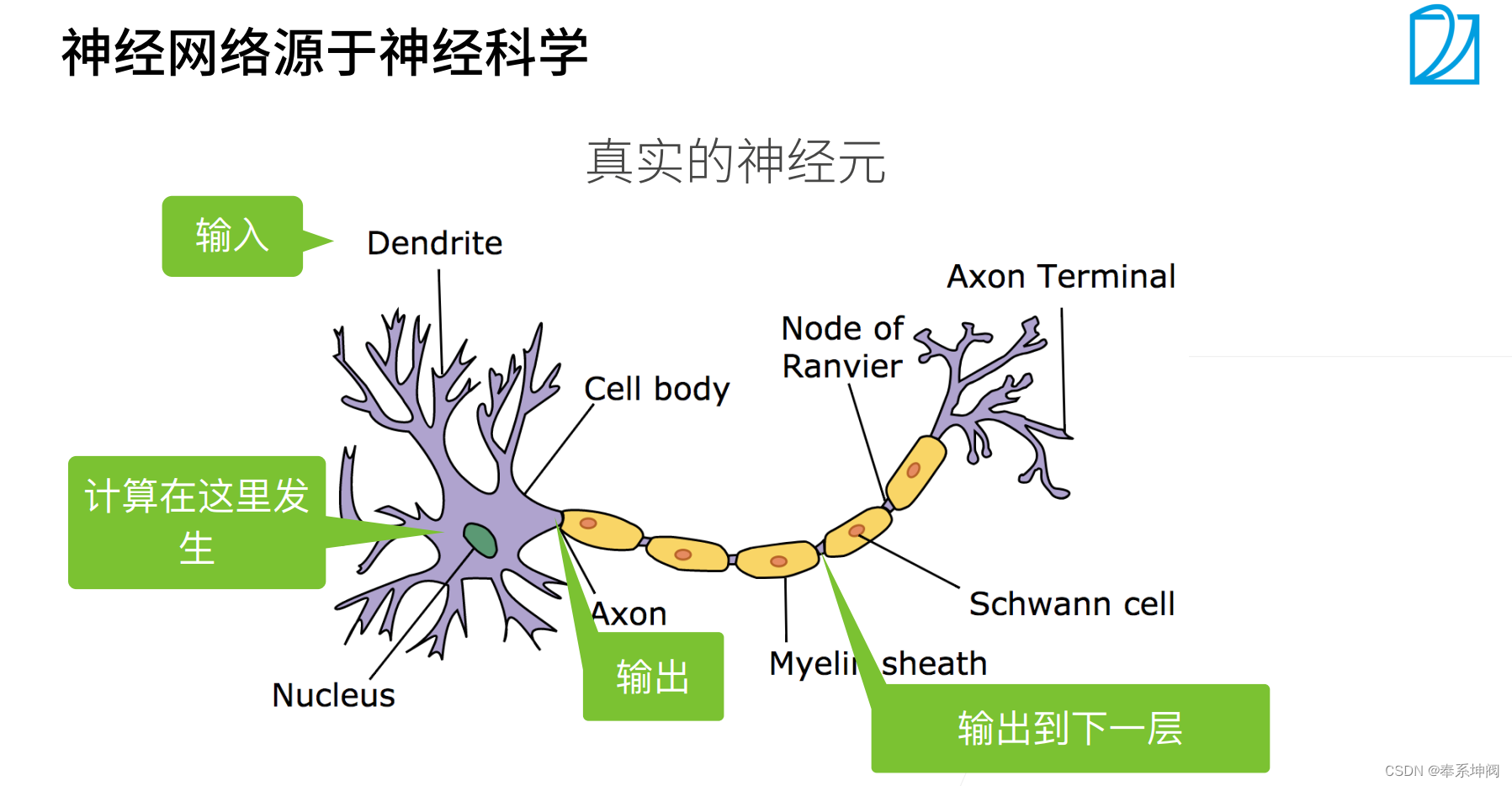





2、基础优化算法




二、线性回归的从零开始实现
在了解线性回归的关键思想之后,我们可以开始通过代码来动手实现线性回归了。在这一节中,我们将从零开始实现整个方法,包括数据流水线、模型、损失函数和小批量随机梯度下降优化器。虽然现代的深度学习框架几乎可以自动化地进行所有这些工作,但从零开始实现可以确保我们真正知道自己在做什么。同时,了解更细致的工作原理将方便我们自定义模型、自定义层或自定义损失函数。在这一节中,我们将只使用张量和自动求导。在之后的章节中,我们会充分利用深度学习框架的优势,介绍更简洁的实现方式。
import random
import torch
from d2l import torch as d2l1、生成数据集
为了简单起见,我们将根据带有噪声的线性模型构造一个人造数据集。我们的任务是使用这个有限样本的数据集来恢复这个模型的参数。我们将使用低维数据,这样可以很容易地将其可视化。
在下面的代码中,我们生成一个包含1000个样本的数据集,每个样本包含从标准正态分布中采样的2个特征。我们的合成数据集是一个矩阵(我们使用线性模型参数
、
和噪声项
生成数据集及其标签):
可以视为模型预测和标签时的潜在观测误差。在这里我们认为标准假设成立,即
服从均值为0的正态分布。为了简化问题,我们将标准差设为0.01。
下面的代码生成合成数据集。
def synthetic_data(w, b, num_examples): #@save"""生成y=Xw+b+噪声w:真实权重 b:真实偏差量 num_examples:生成数据数量"""X = torch.normal(0, 1, (num_examples, len(w))) # 生成元素均值为0、标准差为1的Xy = torch.matmul(X, w) + by += torch.normal(0, 0.01, y.shape) # 有偏差量的y值(偏差量均值为0、标准差为0.01)return X, y.reshape((-1, 1)) # 返回X和有偏差量的y值true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)注意,`features`中的每一行都包含一个二维数据样本,`labels`中的每一行都包含一维标签值(一个标量)。
print('features:', features[0],'\nlabel:', labels[0])features: tensor([2.0776e+00, 3.4160e-04])
label: tensor([8.3580])2、读取数据集
训练模型时要对数据集进行遍历,每次抽取一小批量样本,并使用它们来更新我们的模型。由于这个过程是训练机器学习算法的基础,所以有必要定义一个函数,该函数能打乱数据集中的样本并以小批量方式获取数据。
在下面的代码中,我们定义一个`data_iter`函数,该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为`batch_size`的小批量。每个小批量包含一组特征和标签。
def data_iter(batch_size, features, labels):num_examples = len(features)indices = list(range(num_examples))# 这些样本是随机读取的,没有特定的顺序random.shuffle(indices)for i in range(0, num_examples, batch_size):batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)]) # indices是一个列表,这里是把列表索引在区间[i: min(i + batch_size, num_examples)]的元素列表生成tensoryield features[batch_indices], labels[batch_indices] # yield用法:https://blog.csdn.net/mieleizhi0522/article/details/82142856通常,我们利用GPU并行运算的优势,处理合理大小的“小批量”。每个样本都可以并行地进行模型计算,且每个样本损失函数的梯度也可以被并行计算。GPU可以在处理几百个样本时,所花费的时间不比处理一个样本时多太多。
我们直观感受一下小批量运算:读取第一个小批量数据样本并打印。每个批量的特征维度显示批量大小和输入特征数。同样的,批量的标签形状与`batch_size`相等。
batch_size = 10for X, y in data_iter(batch_size, features, labels): # 注意下面有个break,循环只进行一轮print(X, '\n', y)breaktensor([[ 0.1776, -1.4407],[ 0.5218, 0.1639],[ 1.0650, -0.9711],[-0.1460, 1.1675],[ 0.7669, -1.7807],[ 1.0836, -0.3052],[-0.2531, 0.7157],[-1.6888, 0.1888],[-1.5185, 0.5466],[-0.9307, 1.2468]]) tensor([[ 9.4513],[ 4.6777],[ 9.6400],[-0.0656],[11.7774],[ 7.4136],[ 1.2694],[ 0.2010],[-0.7028],[-1.8955]])当我们运行迭代时,我们会连续地获得不同的小批量,直至遍历完整个数据集。上面实现的迭代对教学来说很好,但它的执行效率很低,可能会在实际问题上陷入麻烦。例如,它要求我们将所有数据加载到内存中,并执行大量的随机内存访问。在深度学习框架中实现的内置迭代器效率要高得多,它可以处理存储在文件中的数据和数据流提供的数据。
3、初始化模型参数
在我们开始用小批量随机梯度下降优化我们的模型参数之前,我们需要先有一些参数。在下面的代码中,我们通过从均值为0、标准差为0.01的正态分布中采样随机数来初始化权重,并将偏置初始化为0。
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)在初始化参数之后,我们的任务是更新这些参数,直到这些参数足够拟合我们的数据。每次更新都需要计算损失函数关于模型参数的梯度。有了这个梯度,我们就可以向减小损失的方向更新每个参数。因为手动计算梯度很枯燥而且容易出错,所以没有人会手动计算梯度。我们使用pytorch的自动微分来计算梯度。
4、定义模型
接下来,我们必须定义模型,将模型的输入和参数同模型的输出关联起来。回想一下,要计算线性模型的输出,我们只需计算输入特征和模型权重
的矩阵,向量乘法后加上偏置
。
注意,上面的是一个向量,而
是一个标量。回想一下torch中描述的广播机制:当我们用一个向量加一个标量时,标量会被加到向量的每个分量上。
def linreg(X, w, b):"""线性回归模型"""return torch.matmul(X, w) + b5、定义损失函数
因为需要计算损失函数的梯度,所以我们应该先定义损失函数。这里我们使用平方损失函数。在实现中,我们需要将真实值`y`的形状转换为和预测值`y_hat`的形状相同。
def squared_loss(y_hat, y):"""均方损失"""return (y_hat - y.reshape(y_hat.shape)) ** 2 / 26、定义优化算法
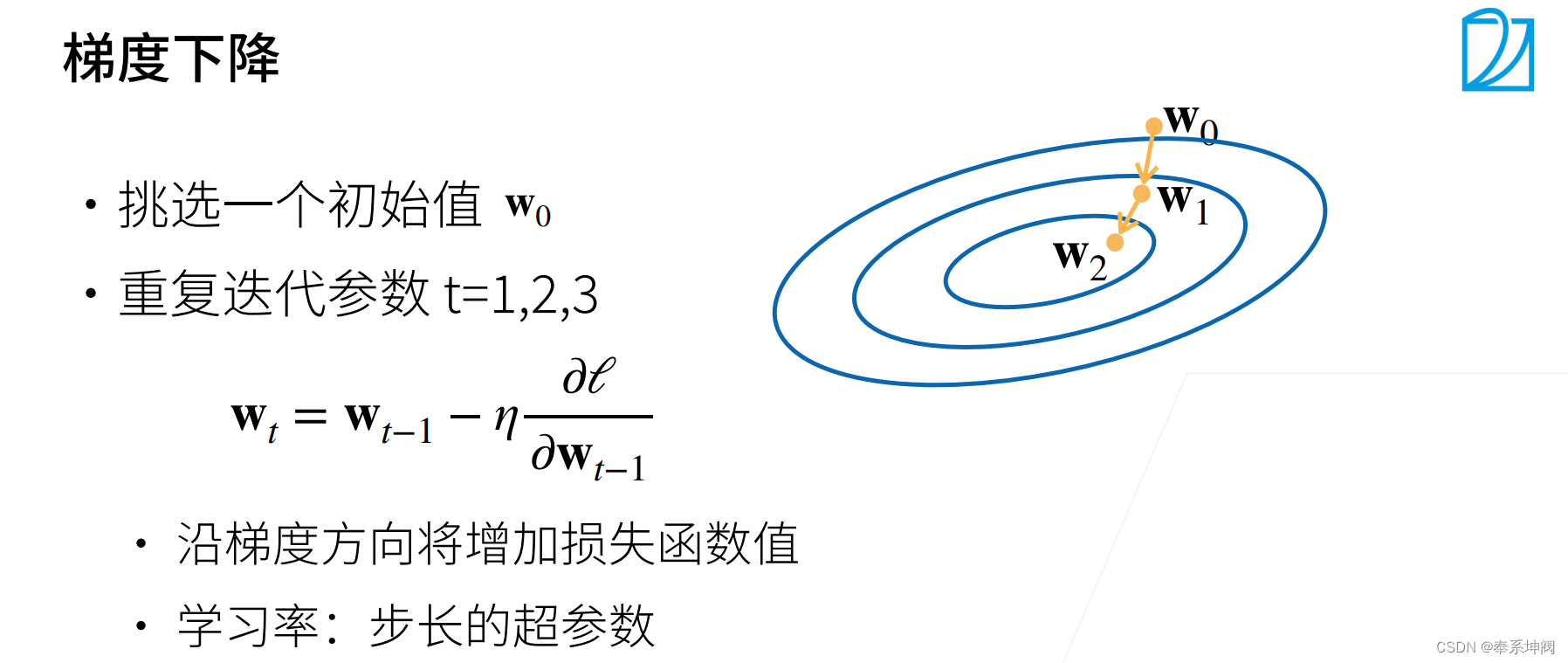
正如我们在前面讨论的,线性回归有解析解。尽管线性回归有解析解,但本书中的其他模型却没有,因此需要使用优化算法,这里我们介绍小批量随机梯度下降。
在每一步中,使用从数据集中随机抽取的一个小批量,然后根据参数计算损失的梯度。接下来,朝着减少损失的方向更新我们的参数。下面的函数实现小批量随机梯度下降更新。该函数接受模型参数集合、学习速率和批量大小作为输入。每一步更新的大小由学习速率`lr`决定。因为我们计算的损失是一个批量样本的总和,所以我们用批量大小`batch_size`来规范化步长,这样步长大小就不会取决于我们对批量大小的选择。
def sgd(params, lr, batch_size):"""小批量随机梯度下降"""with torch.no_grad(): # 模型参数更新的时候不需要进行梯度计算for param in params:param -= lr * param.grad / batch_size # 自动求导,梯度会自动存在于.grad里面,注意这里要除以batch_size,这样不管batch_size有多大,学习率其实都差不多,这样学习率更容易调,相当于少个变量param.grad.zero_() # 用完梯度参数后将梯度设0,防止Pytorch在下次计算时累积梯度7、训练
现在我们已经准备好了模型训练所有需要的要素,可以实现主要的训练过程部分了。理解这段代码至关重要,因为从事深度学习后,相同的训练过程几乎一遍又一遍地出现。
在每次迭代中,我们读取一小批量训练样本,并通过我们的模型来获得一组预测(正向传播)。计算完损失后,我们开始反向传播,存储每个参数的梯度(反向传播的作用就是根据正向传播的loss计算梯度)。最后,我们调用优化算法`sgd`来更新模型参数(优化算法的作用就是根据梯度来更新参数值)。
概括一下,我们将执行以下循环,重复以下训练,直到完成:
Ⅰ.计算梯度:
Ⅱ.更新参数:
在每个迭代周期(epoch)中,我们使用`data_iter`函数遍历整个数据集,并将训练数据集中所有样本都使用一次(假设样本数能够被批量大小整除)。这里的迭代周期个数`num_epochs`和学习率`lr`都是超参数,分别设为3和0.03。设置超参数很棘手,需要通过反复试验进行调整。我们现在忽略这些细节,以后会详细介绍。
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_lossfor epoch in range(num_epochs):for X, y in data_iter(batch_size, features, labels):l = loss(net(X, w, b), y) # X和y的小批量损失# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,# 并以此计算关于[w,b]的梯度l.sum().backward() # 每一个batch_size计算一次损失,将一个batch的损失求和后反向传播计算梯度,每次循环算一次梯度就行,后面不再需要计算梯度,sgd里面也是有‘with torch.no_grad()’的sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数,梯度用完后清零,防止累积with torch.no_grad(): # 关闭梯度运算train_l = loss(net(features, w, b), labels) # 用当前参数计算所有数据的损失print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')epoch 1, loss 0.039029
epoch 2, loss 0.000140
epoch 3, loss 0.000048因为我们使用的是自己合成的数据集,所以我们知道真正的参数是什么。因此,我们可以通过比较真实参数和通过训练学到的参数来评估训练的成功程度。事实上,真实参数和通过训练学到的参数确实非常接近。
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')w的估计误差: tensor([ 4.8280e-05, -2.8586e-04], grad_fn=<SubBackward0>)
b的估计误差: tensor([0.0010], grad_fn=<RsubBackward1>)注意,我们不应该想当然地认为我们能够完美地求解参数。在机器学习中,我们通常不太关心恢复真正的参数,而更关心如何高度准确预测参数。幸运的是,即使是在复杂的优化问题上,随机梯度下降通常也能找到非常好的解。其中一个原因是,在深度网络中存在许多参数组合能够实现高度精确的预测。
三、线性回归的简洁实现
1、生成数据集
与线性回归的从零开始实现类似,我们首先生成数据集。
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2ltrue_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)2、读取数据集
我们可以调用框架中现有的API来读取数据。我们将`features`和`labels`作为API的参数传递,并通过数据迭代器指定`batch_size`。此外,布尔值`is_train`表示是否希望数据迭代器对象在每个迭代周期内打乱数据。
def load_array(data_arrays, batch_size, is_train=True):"""构造一个PyTorch数据迭代器"""dataset = data.TensorDataset(*data_arrays)return data.DataLoader(dataset, batch_size, shuffle=is_train)batch_size = 10
data_iter = load_array((features, labels), batch_size)3、定义模型
对于标准深度学习模型,我们可以使用框架的预定义好的层。这使我们只需关注使用哪些层来构造模型,而不必关注层的实现细节。我们首先定义一个模型变量`net`,它是一个`Sequential`类的实例。`Sequential`类将多个层串联在一起。当给定输入数据时,`Sequential`实例将数据传入到第一层,然后将第一层的输出作为第二层的输入,以此类推。
在下面的例子中,我们的模型只包含一个层,因此实际上不需要`Sequential`。但是由于以后几乎所有的模型都是多层的,在这里使用`Sequential`会让你熟悉“标准的流水线”。
单层网络架构这一单层被称为全连接层(fully-connected layer),因为它的每一个输入都通过矩阵向量乘法得到它的每个输出。
在PyTorch中,全连接层在`Linear`类中定义。值得注意的是,我们将两个参数传递到`nn.Linear`中。第一个指定输入特征形状,即2,第二个指定输出特征形状,输出特征形状为单个标量,因此为1。
# nn是神经网络的缩写
from torch import nnnet = nn.Sequential(nn.Linear(2, 1))4、初始化模型参数
在使用`net`之前,我们需要初始化模型参数。如在线性回归模型中的权重和偏置。深度学习框架通常有预定义的方法来初始化参数。在这里,我们指定每个权重参数应该从均值为0、标准差为0.01的正态分布中随机采样,偏置参数将初始化为零。
正如我们在构造`nn.Linear`时指定输入和输出尺寸一样,现在我们能直接访问参数以设定它们的初始值。我们通过`net[0]`选择网络中的第一个图层,然后使用`weight.data`和`bias.data`方法访问参数。我们还可以使用替换方法`normal_`和`fill_`来重写参数值。
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)5、定义损失函数
计算均方误差使用的是`MSELoss`类,也称为平方范数。默认情况下,它返回所有样本损失的平均值。
loss = nn.MSELoss()6、定义优化算法
小批量随机梯度下降算法是一种优化神经网络的标准工具,PyTorch在`optim`模块中实现了该算法的许多变种。当我们(实例化一个`SGD`实例)时,我们要指定优化的参数(可通过`net.parameters()`从我们的模型中获得)以及优化算法所需的超参数字典。小批量随机梯度下降只需要设置`lr`值,这里设置为0.03。
trainer = torch.optim.SGD(net.parameters(), lr=0.03)7、训练
通过深度学习框架的高级API来实现我们的模型只需要相对较少的代码。我们不必单独分配参数、不必定义我们的损失函数,也不必手动实现小批量随机梯度下降。当我们需要更复杂的模型时,高级API的优势将大大增加。当我们有了所有的基本组件,训练过程代码与我们从零开始实现时所做的非常相似。
回顾一下:在每个迭代周期里,我们将完整遍历一次数据集(`train_data`),不停地从中获取一个小批量的输入和相应的标签。对于每一个小批量,我们会进行以下步骤:
* 通过调用`net(X)`生成预测并计算损失`l`(前向传播)。
* 通过进行反向传播来计算梯度。
* 通过调用优化器来更新模型参数。
为了更好的衡量训练效果,我们计算每个迭代周期后的损失,并打印它来监控训练过程。
num_epochs = 3
for epoch in range(num_epochs):for X, y in data_iter:l = loss(net(X) ,y) # 正向传播计算losstrainer.zero_grad() # 梯度清零,l.backward()会计算这次的梯度,因此要在l.backward()之前进行,不然会将上次的梯度与这次的累加l.backward() # 反向传播计算梯度trainer.step() # 用优化器进行优化l = loss(net(features), labels)print(f'epoch {epoch + 1}, loss {l:f}')epoch 1, loss 0.000248
epoch 2, loss 0.000103
epoch 3, loss 0.000103下面我们比较生成数据集的真实参数和通过有限数据训练获得的模型参数。要访问参数,我们首先从`net`访问所需的层,然后读取该层的权重和偏置。正如在从零开始实现中一样,我们估计得到的参数与生成数据的真实参数非常接近。
w = net[0].weight.data
print('w的估计误差:', true_w - w.reshape(true_w.shape))
b = net[0].bias.data
print('b的估计误差:', true_b - b)w的估计误差: tensor([-0.0010, -0.0003])
b的估计误差: tensor([-0.0003])------注:本文图片和代码均来自李沐老师的课件,另外加了一些个人注释,感谢李沐老师分享











![主流MQ [Kafka、RabbitMQ、ZeroMQ、RocketMQ 和 ActiveMQ]](http://pic.xiahunao.cn/主流MQ [Kafka、RabbitMQ、ZeroMQ、RocketMQ 和 ActiveMQ])
)






