
论文地址:https://arxiv.org/pdf/2310.12823.pdf
Github地址:https://github.com/THUDM/AgentTuning
在ChatGPT带来了大模型的蓬勃发展,开源LLM层出不穷,虽然这些开源的LLM在各自任务中表现出色,但是在真实环境下作为AI Agent仍与商业模型的效果存在较大差距,比如ChatGPT和GPT-4等。Agent把LLM当做核心控制器来完成任务规划、记忆和工具使用等功能,这既需要细粒度的Prompt方法,又需要强大的LLMs来获得满意的性能。
现有针对LLM代理能力的研究主要关注设计提示或构建框架来完成某一特定代理任务,而没有从根本上提升LLM自身的通用Agent能力。许多相关工作专注于提升LLM在特定方面的能力,这通常以牺牲其通用能力为代价,也降低了其泛化能力。针对上述问题,清华大学与智谱AI提出了AgentTuning方法。
AgentTuning是一种简单而通用的方法,既可以增强LLM的Agent能力,有可以同时保持其通用LLM能力。AgentTuning具体方法是首先构造一个包含高质量交互轨迹的轻量级指令调优数据集AgentInstruction,然后采用混合指令微调策略将AgentInstruction与来自通用领域的开源指令相结合。AgentTuning对Llama 2系列模型进行指令微调产生AgentLM。
一、AgentTuning方法介绍
对于一个代理任务,LLM代理的交互轨迹可以记录为对话历史(u1,a1,…,un,an)。考虑到现有的对话模型通常包括两个角色,用户和模型,ui表示来自用户的输入,ai表示来自的响应模型每个轨迹都有一个最终奖励r∈[0,1],反映了任务的完成状态。
二、构造AgentInstruction数据集
大语言模型的指令数据已经广泛应用于预训练好的LLM来获得更好的指令跟随能力,比如FLAN、InstructGPT模型。然而,收集Agent任务的指令要困难得多,因为它涉及Agent在复杂环境中的交互轨迹。AgentInstruction数据集构建有三个主要阶段:指令构建、轨迹交互和轨迹过滤。整个过程使用GPT-3.5(GPT-3.5-turbo-0613)和GPT4(GPT-4-0613)实现完全自动化,使该方法能够轻松扩展到新的Agent任务。
2.1 指令构建
作者使用六个现实世界场景相对容易收集指令的Agent任务来构建AgentConstruct数据集,包括AlfWorld、WebShop、Mind2Web、知识图、操作系统、数据库。具体请参考如下表所示:

任务派生
对于常见的Agent任务,可以直接从相似的数据集构造指令。对于数据库任务,我们需要从BIRD(是一个仅用于SELECT的数据库基准)中构建指令。我们运行了两种类型的任务派生。首先,作者使用问题和每个BIRD子任务中的参考SQL语句来构建轨迹。然后,我们使用参考SQL语句查询数据库来获取对应的输出,并将其作为Agent的答案。最后,让GPT-4结合上述信息的情况下补充Agent的想法。通过这种方式,可以直接从BIRD数据集中生成正确的轨迹。
然而,由于该合成过程决定了交互的轮数固定为2,然后作者又提出了另一种方法,不是直接生成轨迹,而是通过构建指令来提高多样性。作者把BIRD的问题作为Prompt向GPT-4请求,并收集其与数据库的交互轨迹。收集到轨迹后,执行参考SQL语句并将结果与来自GPT-4的结果进行比较,过滤掉错误的答案,只收集正确的轨迹。
Self-Instruct
对于操作系统任务来说,由于难以在终端执行OS命令来获得指令,因此作者采用了Self-Instruct方法构建任务。首先通过Prompt给GPT-4提出一些与操作系统相关的任务,以及任务说明、参考解决方案和评估脚本。然后,把任务作为Prompt给另一个GPT-4(求解器)并收集其轨迹。在任务完成之后,运行参考解决方案,并与使用评估脚本GPT-4(求解器)生成的结果进行比较。最后收集两者相同的轨迹数据。对于DB任务,由于BIRD只包含SELECT数据,我们需要使用Self-Instruct发光法来构造其他数据库操作类型(比如INSERT、UPDATE和DELETE)。
测试数据污染风险分析
值得注意的是,如果GPT-4输出的指令与测试集中的指令相同,或者如果测试任务是从派生的同一数据集构建的,那么这两种方法可能存在测试数据污染的风险。作者对其做了污染分析。
作者采用了基于token的污染分析方法。具体是对训练数据和测试样本进行分词,然后匹配10-gram,最多允许4个不匹配。如果10-gram在训练数据和测试数据都包括,那么这个10-gram被认为是污染了。作者将评估样本的污染率定义为该样本的token污染率。如果评估样本的污染率大于80%,我们将其定义为“dirty”,如果其污染率低于20%,则为“clean”。具体如下表所示:

2.2 交互轨迹生成
在构建了初始指令后,作者使用GPT-4(GPT-4-0613)作为轨迹交互的代理。对于Mind2Web任务,由于大量的指令和预算限制,作者部分使用ChatGPT(gpt-3.5-turbo-0613)进行相互作用。
由于代理任务对输出格式的严格要求,作者采用了1-shot评估方法。对于每项任务,针对训练数据集都生成一个完整的交互过程。
交互过程
交互过程有两个主要部分:首先,给模型一个任务描述和一个成功的1-shot实例,然后,开始实际的交互。给模型提供当前的指令和必要的信息。模型会基于这些信息和先前的反馈会形成一个想法和一个动作。然后环境提供反馈,包括可能的更改或新信息。此循环会持续到模型达到其目标或达到其令牌限制。如果模型连续三次重复相同的输出,认为这是一次反复的失败。如果模型的输出格式错误,我们使用BLEU度量进行比较所有可能的动作选择,并选择最接近的匹配项作为该步骤的模型动作。
CoT比率
思维链推理方法可以显著增强LLM逐步推理的推理能力。作者采用ReAct作为推理框架,会输出CoT每个步骤的解释(简称thought),直到完成最终的动作。因此,所收集的交互轨迹伴随着详细的轨迹细节,使模型能够学习引导行动的推理过程。对于不使用thought而使用任务推导生成的轨迹,作者使用GPT-4来补充thought,以与ReAct Prompting保持一致。
2.3 交互轨迹过滤
为了确保数据质量,需要严格过滤其相互作用轨迹。由于每个互动轨迹都会得到一个奖励r,可以基于奖励r自动选择高质量的轨迹。根据最终奖励r=1可以过滤除Mind2Web外的所有任务的轨迹。然而,由于Mind2Web任务相对较难,我们使用r≥2/3确保可以获得足够数量的轨迹。在表2中,我们展示了7B模型在过滤与不过滤轨迹上进行微调的效果对比。

经过上述步骤过滤之后,最终AgentInstruction数据集得到1866条数据。
三、指令微调
3.1 通用领域指令
最近的研究表明,使用多样化的用户Prompt训练模型可以提高模型的性能。作者从ShareGPT数据集(https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered)选择了57096个GPT-3.5会话和3670个GPT-4会话。从GPT-4回复的高质量数据中按照采样率为1:4抽取GPT-4和GPT-3.5的样本。
3.2 混合训练
从下表5可以看出,Agent任务数据和通用数据混合训练才能在agent任务和通用领域都表现良好,因此混合训练主要优化如下loss:
![]()
PS:通过调整不同的η,发现η = 0.2时held-out任务的效果是最好的。

3.3 训练设置
作者选择开源Llama 2(Llama-2-{7,13,70}b-chat)作为基础模型。参考Vicuna,作者将所有数据标准化为多轮聊天机器人风格的格式,这样可以很方便地混合不同来源的数据。作者使用Megatron-LM微调Llama 2 7B、13B和70B的模型,并且在微调过程中,只计算模型输出的损失。
- 学习率:7B和13B模型的学习率为5e-5,70B模型为1e-5;
- 批次大小:设置了批次大小为64;
- 序列长度:序列长度为4096;
- 优化器:我们使用AdamW优化器,其中余弦学习调度器具有2%的预热步骤。
为了训练高效,作者使用了tensor并行和pipeline并行。训练详细超参数见下表6所示:

四、效果评估
4.1 评估设置
Held-in/out任务:评估的任务如下表3所示:

通用任务:为了全面评估模型的总体能力,作者选择了常用的4个任务,分别是反映了模型的知识能力(MMLU),数学能力(GSM8K),编码能力(Humaneval)和人类偏好(MT Bench)。
baseline:从下图1可以看出,基于api的商业模型明显超过了开源模型在代理任务中的表现。因此,作者选择了GPT-3.5(GPT-3.5-turbo-0613)以及GPT-4(GPT-4-0613)作为Agent。因其卓越的指令跟随能力,选择评估开源的Llama 2聊天版本(Llama-2-{7,13,70}b-chat)。参考AgentBench,作者也截断了超过模型长度限制的对话历史,并且使用贪婪解码。对于WebArena,我们采用核采样,p=0.9进行探索。

总体分数计算:任务难度的差异可能导致直接计算平均分有失公允,因此对每个任务的得分进行归一化,并将其缩放到1的平均值以实现平衡基准评估。任务权重如下表3所示:
4.2 实验主要结论

从表4可以看出,AgentLM展示了Llama 2系列不同大小模型在held-in任务和held-out任务中都有显著改进,同时保持通用任务的性能。held-in任务的改进比held-out任务更明显,但是held-out任务的提升仍然达到至170%。这证明了AgentLM模型作为一般代理的潜力。在若干任务中,AgentLM的13B和70B版本甚至超过了GPT-4。
对于大多数held-in任务,Llama 2的性能几乎为零,这表明Llama 2完全无法处理这些任务。然而,AgentLM的基本错误明显较少,这表明该方法有效地激活了模型的Agent能力。值得注意的是,70BAgentLM的总体性能接近GPT-4。
在held-out任务中,70B AgentLM的性能接近GPT-3.5,70B模型和7B模型分别都有176%和76%的提升。这是因为更大的模型具有更强的泛化能力能力,在相同的训练数据上有更好的泛化性。
在通用任务上,AgentLM在四个维度(知识,数学、编码和人类偏好)上的表现与Llama 2不相上下。这充分表明,即使增强了Agent能力,AgentLM模型也能保持相同的通用能力。
4.3 错误分析
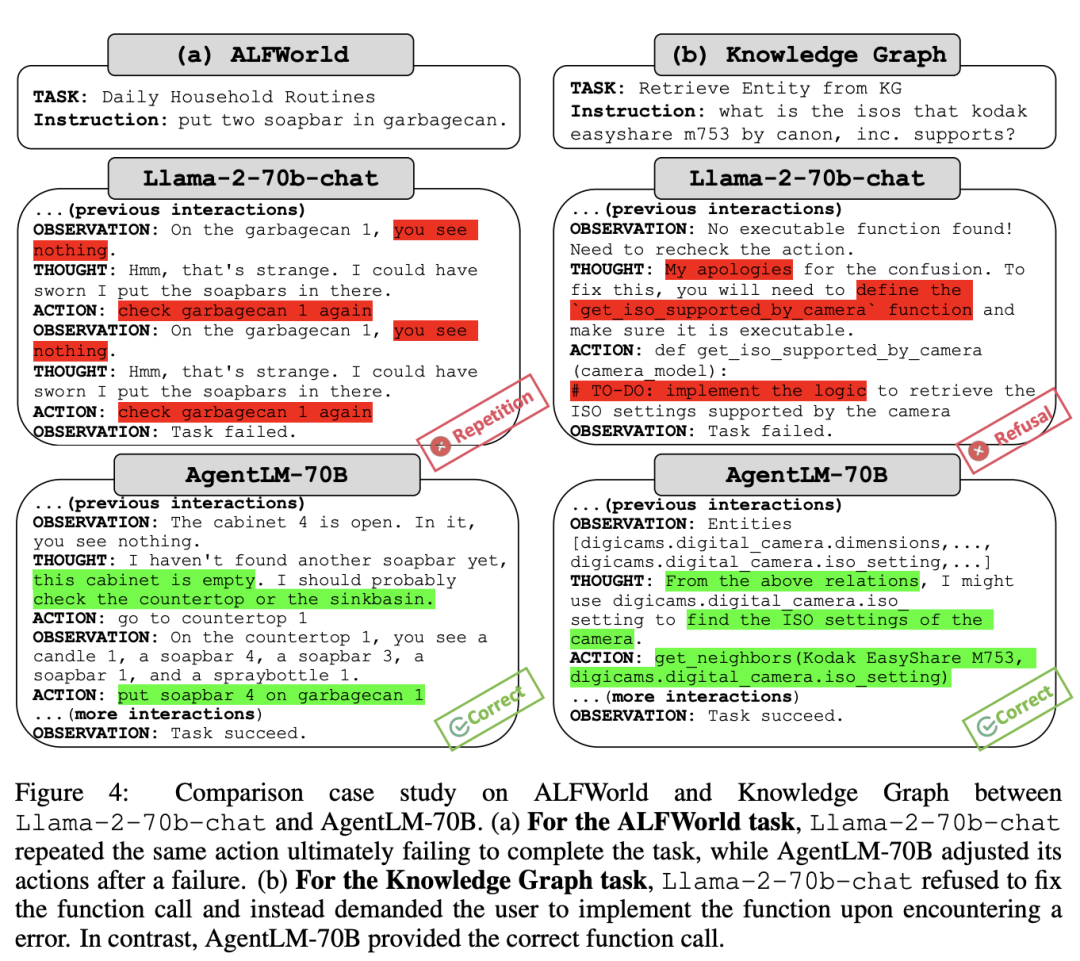
为了深入研究错误分析,作者从held-in任务集中选择了三个任务(ALFWorld、WebShop、KG),并使用基于规则的方法识别常见错误类型,例如无效动作和重复生成。结果如图3(a)所示:

总的来说,Llama2会出现如重复生成和采取无效行动的基本错误,相比之下,GPT-3.5尤其是GPT-4产生这种错误更少。然而,AgentLM显著减少了这些基本错误。作者推测,虽然Llama 2 chat模型本身具有Agent能力,但其较差,可能是由于缺乏对Agent数据对齐训练;AgentTuning有效的激活了其Agent潜力。
参考文献:
[1] https://arxiv.org/pdf/2310.12823.pdf
)













———ES6迭代器)
图片(jpg、png)、pdf、excel(xlsx)、docx)


上搭建项目部署环境)
)