Dexie查询速度慢的原因主要一个优化点是复杂查询下的count执行。
以下摘自Dexie官方文档:https://dexie.org/docs/Collection/Collection.count()
If executed on simple queries, the native IndexedDB ObjectStore
count() method will be called (fast execution). If advanced queries
are used, the implementation has to execute a query to iterate all
items and count them manually. Examples where count() will be fastdb.[table].where(index).equals(value).count() db.[table].where(index).above(value).count() db.[table].where(index).below(value).count() db.[table].where(index).between(a,b).count() db.[table].where(index).startsWith(value).count() // The reason it is fast in above samples is that they map to basic // IDBKeyRange methods only(), lowerBound(), upperBound(), and bound().// Examples where count() will have to count manually: db.[table].where(index).equalsIgnoreCase(value).count() db.[table].where(index).startsWithIgnoreCase(value).count() db.[table].where(index).anyOf(valueArray).count() db.[table].where(index).above(value).and(filterFunction).count() db.[table].where(index1).above(value1).or(index2).below(value2).count()
官方文档中也说明了count在复杂查询的情况下统计速度会变慢,至于会变慢多少呢?个人做过对比在5000条数据量的情况下,进行统计大概需要花费3秒左右,而进行同样的查询只需要几十毫秒。
因此在使用Dexie进行复杂查询且需要进行分页操作时,应该避免进行重复的count操作。其中一个解决办法就是加入筛选条件的缓存,当缓存的条件不变时不进行count操作而直接使用之前count出来的数据。
例如:
项目中的一个例子

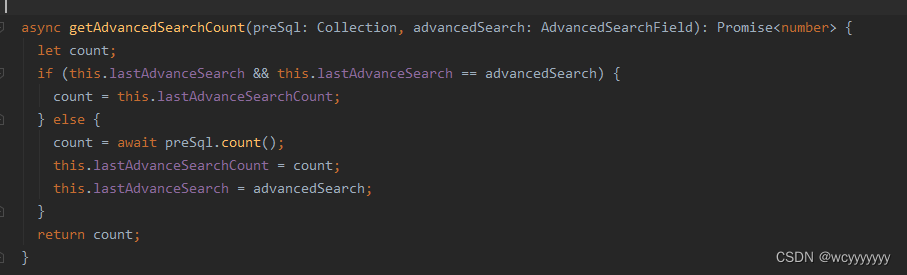
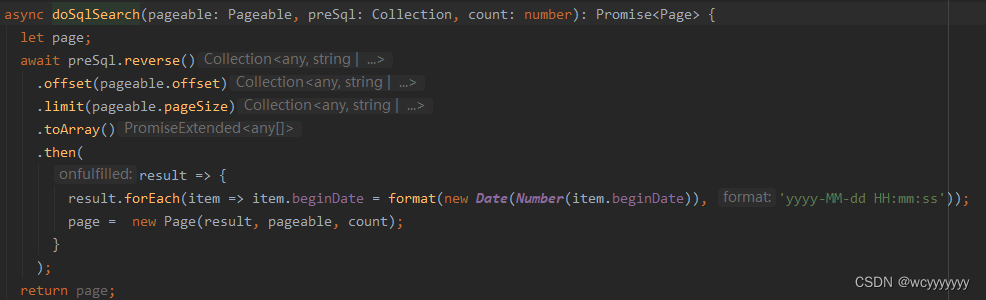
项目背景:electron + node + ng-zorro的一个项目。项目需要离线处理大量的数据,没办法加后端,只能在纯前端的项目里进行数据的加载、存储、查询等,且这个项目还要支持数据的筛选、分页。在这种情况下若直接使用Dexie进行count查询总数后再进行分页查询就会导致每次的查询都非常的慢。因此使用了缓存,每次在筛选的时候判断筛选条件是否发送变化,若发生了变化则重新进行count,若没有变化则视为进行翻页操作,仍使用之前的count。这样就只会在第一次用搜索条件进行查询的时候出现卡顿,其余时间较为流畅。

)
)


存储技术专家成长路线)













