文章目录
- 查找算法介绍
- 1. 线性查找算法
- 2. 二分查找算法
- 2.1. 思路分析
- 2.2. 代码实现
- 2.3. 功能拓展
- 3. 插值查找算法
- 3.1. 前言
- 3.2. 相关概念
- 3.3. 实例应用
- 4. 斐波那契(黄金分割法)查找算法
- 4.1. 斐波那契(黄金分割法)原理
- 4.2. 实例应用
查找算法介绍
在 java 中,我们常用的查找有四种:
① 顺序(线性)查找
② 二分查找/折半查找
③ 插值查找
④ 斐波那契查找
1. 线性查找算法
问题:
数组arr[] = {1, 9, 11, -1, 34, 89},使用线性查找方式,找出11所在的位置。
代码实现:
package search;public class SeqSearch {public static void main(String[] args) {int arr[] = { 1, 9, 11, -1, 34, 89 };// 没有顺序的数组int index = seqSearch(arr, 11);if (index == -1) {System.out.println("没有找到");} else {System.out.println("找到了,下标为:" + index);}}/*** 这里实现的线性查找是找到一个满足条件的值,就返回* * @param arr* @param value* @return*/public static int seqSearch(int[] arr, int value) {// 线性查找是逐一比对,发现有相同的值,就返回下标for (int i = 0; i < arr.length; i++) {if (arr[i] == value) {return i;}}return -1;}}
运行结果:

2. 二分查找算法
问题:
请对一个有序数组进行二分查找 {1,8, 10, 89, 1000, 1234} ,输入一个数看看该数组是否存在此数,并且求出下标,如果没有就提示"没有这个数"。
2.1. 思路分析
二分查找的思路分析
-
首先,确定该数组的中间的下标: m i d = ( l e f t + r i g h t ) / 2 mid = (left + right) / 2 mid=(left+right)/2
-
然后让需要查找的数
findVal和arr[mid]比较
2.1.findVal > arr[mid],说明你要查找的数在mid的右边, 因此需要递归的向右查找
2.2.findVal < arr[mid],说明你要查找的数在mid的左边, 因此需要递归的向左查找
2.3.findVal == arr[mid],说明找到,就返回 -
什么时候需要结束递归:
①找到就结束递归
②递归完整个数组,仍然没有找到findVal,也需要结束递归 当left > right就需要退出
2.2. 代码实现
注意:使用二分查找的前提是 该数组是有序的
package search;public class BinarySearch {public static void main(String[] args) {int arr[] = { 1, 8, 10, 89, 1000, 1234 };int resIndex = binarySearch(arr, 0, arr.length - 1, 1);System.out.println("resIndex= " + resIndex);}// 二分查找法/*** * @param arr 数组* @param left 左边的索引* @param right 右边的索引* @param findVal 要查找的值* @return 如果找到就返回下标,如果没有找到就返回-1*/public static int binarySearch(int[] arr, int left, int right, int findVal) {// 当left > right 时,说明递归整个数组,但是没有找到if (left > right) {return -1;}int mid = (left + right) / 2;int midVal = arr[mid];if (findVal > midVal) {// 向右递归return binarySearch(arr, mid + 1, right, findVal);} else if (findVal < midVal) {return binarySearch(arr, left, mid - 1, findVal);} else {return mid;}}}
运行结果:

2.3. 功能拓展
问题:
数组{1,8, 10, 89, 1000, 1000,1234}, 当一个有序数组中,有多个相同的数值时,如何将所有的数值都查找到,比如这里的 1000。
代码实现:
package search;import java.util.ArrayList;
import java.util.List;public class BinarySearch {public static void main(String[] args) {int arr[] = { 1, 8, 10, 89, 1000, 1000, 1234 };List<Integer> resIndexList = binarySearch2(arr, 0, arr.length - 1, 1000);System.out.println("resIndexList = " + resIndexList);}/** 思路分析:* 1. 在找 mid 的索引值,不要马上返回* 2. 向 mid 索引值的左边扫描,将所有满足1000的元素的下标,加入到集合ArrayList* 3. 向 mid 索引值的右边扫描,将所有满足1000的元素的下标,加入到集合ArrayList* 4. 将 ArrayList 返回*/public static List<Integer> binarySearch2(int[] arr, int left, int right, int findVal) {// 当left > right 时,说明递归整个数组,但是没有找到if (left > right) {return new ArrayList<Integer>();}int mid = (left + right) / 2;int midVal = arr[mid];if (findVal > midVal) {// 向右递归return binarySearch2(arr, mid + 1, right, findVal);} else if (findVal < midVal) {return binarySearch2(arr, left, mid - 1, findVal);} else {/** 思路分析:* 1. 在找 mid 的索引值,不要马上返回* 2. 向 mid 索引值的左边扫描,将所有满足1000的元素的下标,加入到集合ArrayList* 3. 向 mid 索引值的右边扫描,将所有满足1000的元素的下标,加入到集合ArrayList* 4. 将 ArrayList 返回*/List<Integer> resIndexlist = new ArrayList<Integer>();// 向 mid 索引值的左边扫描,将所有满足1000的元素的下标,加入到集合ArrayListint temp = mid - 1;while (true) {if (temp < 0 || arr[temp] != findVal) {// 退出break;}// 否则,就将temp放入到resIndexlistresIndexlist.add(temp);temp -= 1;// temp左移}resIndexlist.add(mid);// 向 mid 索引值的右边扫描,将所有满足1000的元素的下标,加入到集合ArrayListtemp = mid + 1;while (true) {if (temp > arr.length - 1 || arr[temp] != findVal) {// 退出break;}// 否则,就将temp放入到resIndexlistresIndexlist.add(temp);temp += 1;// temp左移}return resIndexlist;}}}
运行结果:

3. 插值查找算法
3.1. 前言
二分查找算法存在查找效率较慢的情况,因为其中的mid是从中间开始取的。假如对数组{ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 }进行查找,查找 1 所在的位置,实现代码如下:
package search;import java.util.ArrayList;
import java.util.List;public class BinarySearch {public static void main(String[] args) {int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 };List<Integer> resIndexList = binarySearch2(arr, 0, arr.length - 1, 1);System.out.println("resIndexList = " + resIndexList);}/** 思路分析:* 1. 在找 mid 的索引值,不要马上返回* 2. 向 mid 索引值的左边扫描,将所有满足1000的元素的下标,加入到集合ArrayList* 3. 向 mid 索引值的右边扫描,将所有满足1000的元素的下标,加入到集合ArrayList* 4. 将 ArrayList 返回*/public static List<Integer> binarySearch2(int[] arr, int left, int right, int findVal) {System.out.println("调用了一次");// 当left > right 时,说明递归整个数组,但是没有找到if (left > right) {return new ArrayList<Integer>();}int mid = (left + right) / 2;int midVal = arr[mid];if (findVal > midVal) {// 向右递归return binarySearch2(arr, mid + 1, right, findVal);} else if (findVal < midVal) {return binarySearch2(arr, left, mid - 1, findVal);} else {/** 思路分析:* 1. 在找 mid 的索引值,不要马上返回* 2. 向 mid 索引值的左边扫描,将所有满足1000的元素的下标,加入到集合ArrayList* 3. 向 mid 索引值的右边扫描,将所有满足1000的元素的下标,加入到集合ArrayList* 4. 将 ArrayList 返回*/List<Integer> resIndexlist = new ArrayList<Integer>();// 向 mid 索引值的左边扫描,将所有满足1000的元素的下标,加入到集合ArrayListint temp = mid - 1;while (true) {if (temp < 0 || arr[temp] != findVal) {// 退出break;}// 否则,就将temp放入到resIndexlistresIndexlist.add(temp);temp -= 1;// temp左移}resIndexlist.add(mid);// 向 mid 索引值的右边扫描,将所有满足1000的元素的下标,加入到集合ArrayListtemp = mid + 1;while (true) {if (temp > arr.length - 1 || arr[temp] != findVal) {// 退出break;}// 否则,就将temp放入到resIndexlistresIndexlist.add(temp);temp += 1;// temp左移}return resIndexlist;}}}
运行结果:
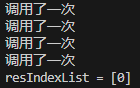
总共调用了4次才查找出1的索引值,效率较慢。通过插值查找可改善上述问题。
3.2. 相关概念
原理介绍:
插值查找算法类似于二分查找,不同的是插值查找每次从自适应 mid 处开始查找。
mid的计算公式:
对二分查找中的求 mid 索引的公式进行修改:

上图公式中:
① low 表示左边索引 left
② high 表示右边索引 right
③ key 就是前面二分查找中讲的 findVal(要查找的值)
即插值查找的 mid计算公式:
m i d = l o w + ( h i g h − l o w ) k e y − a r r [ l o w ] a r r [ h i g h ] − a r r [ l o w ] \begin{aligned} &mid = low + (high-low)\frac{key-arr[low]}{arr[high]-arr[low]} \end{aligned} mid=low+(high−low)arr[high]−arr[low]key−arr[low]
对应前面的代码公式,即:
m i d = l e f t + ( r i g h t – l e f t ) f i n d V a l – a r r [ l e f t ] a r r [ r i g h t ] – a r r [ l e f t ] \begin{aligned} &mid = left + (right – left)\frac{findVal – arr[left]}{arr[right] – arr[left]} \end{aligned} mid=left+(right–left)arr[right]–arr[left]findVal–arr[left]
举例说明:
数组 arr = [1, 2, 3, …, 100]
①假如需要查找的值是 1
(使用二分查找的话,需要多次递归,才能找到 1 的下标0)
使用插值查找算法:
m i d = l e f t + ( r i g h t – l e f t ) f i n d V a l – a r r [ l e f t ] a r r [ r i g h t ] – a r r [ l e f t ] \begin{aligned}&mid = left + (right – left)\frac{findVal – arr[left]}{arr[right] – arr[left]}\end{aligned} mid=left+(right–left)arr[right]–arr[left]findVal–arr[left]
即:
m i d = 0 + ( 99 − 0 ) 1 − 1 100 − 1 = 0 + 99 ∗ 0 99 = 0 ( 直接定位到下标 0 ) \begin{aligned}&mid = 0+(99-0)\frac{1-1}{100-1} = 0 + 99 * \frac{0}{99} = 0\ \ \ (直接定位到下标0)\end{aligned} mid=0+(99−0)100−11−1=0+99∗990=0 (直接定位到下标0)
②假如需要查找的值是 100
m i d = 0 + ( 99 − 0 ) 100 − 1 ( 100 − 1 = 0 + 99 ∗ 99 99 = 0 + 99 = 99 ( 直接定位到下标 99 ) \begin{aligned}&mid =0 + (99 - 0)\frac{100 - 1}{(100 - 1} = 0 + 99 * \frac{99}{99} = 0 + 99 = 99\ \ \ (直接定位到下标99)\end{aligned} mid=0+(99−0)(100−1100−1=0+99∗9999=0+99=99 (直接定位到下标99)
3.3. 实例应用
问题:
对数组 arr = [1, 2, 3, …, 100] ,使用插值查找算法,找到 1 的索引值(下标)
代码实现:
package search;import java.util.Arrays;public class InsertValueSearch {public static void main(String[] args) {int[] arr = new int[100];for (int i = 0; i < 100; i++) {arr[i] = i + 1;}int index = insertValueSearch(arr, 0, arr.length - 1, 1);System.out.println("index = " + index);// System.out.println(Arrays.toString(arr));}// 编写插值查找算法// 说明:插值查找算法也要求数组是有序的/*** * @param arr 数组* @param left 左边索引* @param right 右边索引* @param findVal 要查找的值* @return 如果找到,就返回对应的下标;如果没有找到,就返回-1*/public static int insertValueSearch(int[] arr, int left, int right, int findVal) {System.out.println("查找了一次");// 注意:findVal < arr[0] 和 findVal > arr[arr.length - 1] 必须需要,否则得到的mid可能越界if (left > right || findVal < arr[0] || findVal > arr[arr.length - 1]) {return -1;}// 求出 midint mid = left + (right - left) * (findVal - arr[left]) / (arr[right] - arr[left]);int midVal = arr[mid];if (findVal > midVal) {// 说明应该向右边递归return insertValueSearch(arr, mid + 1, right, findVal);} else if (findVal < midVal) {// 说明应该向左递归return insertValueSearch(arr, left, mid - 1, findVal);} else {return mid;}}}
运行结果:
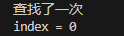
注意事项:
- 对于数据量较大,关键字分布比较均匀的查找表来说,采用插值查找, 速度较快.
- 关键字分布不均匀的情况下,该方法不一定比折半(二分)查找要好
4. 斐波那契(黄金分割法)查找算法
黄金分割点是指把一条线段分割为两部分,使其中一部分与全长之比等于另一部分与这部分之比。取其前三位数字的近似值是 0.618。由于按此比例设计的造型十分美丽,因此称为黄金分割,也称为中外比。这是一个神奇的数字,会带来意想不到的效果。
斐波那契数列 {1, 1, 2, 3, 5, 8, 13, 21, 34, 55, … … } 发现斐波那契数列的两个相邻数 的比例,无限接近 黄金分割值0.618。
4.1. 斐波那契(黄金分割法)原理
斐波那契查找原理与前两种相似,仅仅改变了中间结点(mid)的位置,mid 不再是中间或插值得到,而是位于黄金分割点附近,即 m i d = l o w + F [ k − 1 ] − 1 mid=low+F[k-1]-1 mid=low+F[k−1]−1( F F F 代表斐波那契数列),如下图所示:

对 F(k-1)-1 的理解:
- 由斐波那契数列 F [ k ] = F [ k − 1 ] + F [ k − 2 ] F[k]=F[k-1]+F[k-2] F[k]=F[k−1]+F[k−2] 的性质,可以得到 ( F [ k ] − 1 ) = ( F [ k − 1 ] − 1 ) + ( F [ k − 2 ] − 1 ) + 1 (F[k]-1)=(F[k-1]-1)+(F[k-2]-1)+1 (F[k]−1)=(F[k−1]−1)+(F[k−2]−1)+1 。该式说明:只要顺序表的长度为 F[k]-1,则可以将该表分成长度为 F [ k − 1 ] − 1 F[k-1]-1 F[k−1]−1 和 F [ k − 2 ] − 1 F[k-2]-1 F[k−2]−1 的两段,即如上图所示。从而中间位置为 m i d = l o w + F [ k − 1 ] − 1 mid=low+F[k-1]-1 mid=low+F[k−1]−1
- 类似的,每一子段也可以用相同的方式分割
- 但顺序表长度 n n n 不一定刚好等于 F [ k ] − 1 F[k]-1 F[k]−1,所以需要将原来的顺序表长度 n n n 增加至 F [ k ] − 1 F[k]-1 F[k]−1。这里的 k k k 值只要能使得 F [ k ] − 1 F[k]-1 F[k]−1 恰好大于或等于 n n n 即可,由以下代码得到,顺序表长度增加后,新增的位置(从 n + 1 n+1 n+1 到 F [ k ] − 1 F[k]-1 F[k]−1 位置),都赋为 n n n 位置的值即可。
while(n>fib(k)-1)
k++;
4.2. 实例应用
问题:
请对一个有序数组进行斐波那契查找 {1,8, 10, 89, 1000, 1234} ,输入一个数看看该数组是否存在此数,并且求出下标,如果没有就提示"没有这个数"(return = -1)。
代码实现:
package search;import java.util.Arrays;public class FibonacciSearch {public static int maxSize = 20;public static void main(String[] args) {int[] arr = { 1, 8, 10, 89, 1000, 1234 };System.out.println("index = " + fibSearch(arr, 89));}// 因为后面我们mid=low+F(k-1)-1,需要使用斐波那契数列,因此我们需要先获取到一个斐波那契数列// 非递归方法得到一个斐波那契数列public static int[] fib() {int[] f = new int[maxSize];f[0] = 1;f[1] = 1;for (int i = 2; i < maxSize; i++) {f[i] = f[i - 1] + f[i - 2];}return f;}// 编写斐波那契查找算法// 使用非递归的方式编写算法/*** * @param a 数组* @param key 需要查找的关键字(值)* @return 返回对应的下标,如果没有,就返回-1*/public static int fibSearch(int[] a, int key) {int low = 0;int high = a.length - 1;int k = 0;// 表示斐波那契分割数值的下标int mid = 0;// 存放mid值int f[] = fib();// 获取到斐波那契数列// 获取到斐波那契分割数值的下标while (high > f[k] - 1) {k++;}// 因为f[k]的值 可能大于a的长度,因此需要使用Arrays类,构造一个新的数组,并指向a[]// 不足的部分会使用0填充int[] temp = Arrays.copyOf(a, f[k]);// 实际上,需要使用a数组的最后的数填充temp// 举例:// temp = {1,8,10,89,1000,1234,0,0,0} --> {1,8,10,89,1000,1234,1234,1234,1234}for (int i = high + 1; i < temp.length; i++) {temp[i] = a[high];}// 使用while循环处理,找到keywhile (low <= high) {// 只要这个条件满足,就可以找mid = low + f[k - 1] - 1;if (key < temp[mid]) {// 继续向数组的前面查找(左边)high = mid - 1;// 为什么是k--?// 说明:// 1. 全部元素=前面的元素+后面的元素// 2. f[k] = f[k-1] + f[k-2]// 因为 前面有f[k-1]个元素,所以可以继续拆分 f[k-1] = f[k-2] + f[k-3]// 即 在f[k-1]的前面继续查找(k--)// 即 下次循环的 mid = f[k-1-1]-1k--;} else if (key > temp[mid]) {// 继续向数组的后面查找(右边)low = mid + 1;// 为什么是 k -= 2// 说明// 1. 全部元素=前面的元素+后面的元素// 2. f[k] = f[k-1] + f[k-2]// 因为 后面有f[k-2]个元素,所以可以继续拆分 f[k-2] = f[k-3] + f[k-4]// 即 在f[k-2]的后面继续查找(k-=2)// 即 下次循环的 mid = f[k-1-2]-1k -= 2;} else {// 找到// 需要确定,返回的是哪一个下标if (mid <= high) {return mid;} else {return high;}}}return -1;}}
运行结果:
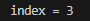



![读书笔记-《数据结构与算法》-摘要3[选择排序]](https://img-blog.csdnimg.cn/direct/a00880defd4a4a93bd54bd041ff14cdb.gif)