生成式 AI 是如何工作的
生成式 AI 是目前最热门的技术之一,ChatGPT 等应用的出现使人们对于如何在各种领域中应用生成式 AI 有了许多新的思考。
但这些领域的从业者并不都具备 AI 相关的知识背景。所以我们制作了这个教程,向无 AI 知识背景的读者介绍生成式 AI 是如何工作的。
在互联网上,已经有许多非常精彩的生成式 AI 及其背后 AI 模型的工作原理介绍,例如:
- 《The Illustrated Transformer》
- 《Illustrated Guide to Transformers- Step by Step Explanation》
但它们都花了较多篇幅相对深入地介绍了生成式 AI 背后的模型 Transformer,这对应着许多专业术语和复杂的数学逻辑。这是我们在本教程中将避免的。
如果你希望获取这部分的信息,建议阅读上述文章。
与本教程目标最相近的是 Financial Times 最新发布的一期文章,在制作本教程的过程中我们也大量参考了其内容组织思路和可视化风格。与其内容相比,本教程在内容上进行了一些增减,使其更符合我们认为易于理解的逻辑思路,但 FT 的这篇文章同样值得一看。
我们将从一些例子出发,逐步理解生成式 AI 如何实现:
- 理解词语
- 理解句子
- 进一步生成内容

图中的文本是一个典型的例子:“买了一袋很甜的苹果,和新款的苹果手机”,苹果一词出现了两次但含义不同。
目前可用的生成式 AI 都克服了这一难题,能够准确理解两次出现的苹果的不同含义,让我们一起探索这一神奇能力背后的原理吧!
AI 如何理解词语
对于 AI 模型来说,在完成生成文本等更复杂的任务之前,首先需要完成第一步:理解词语。
对于人类来说,词语是在学习一门语言时逐渐掌握的知识,基于对语言的学习与应用,加深对词语含义的理解。
AI 模型同样通过一个学习过程掌握词语的含义,而学习的素材则是对应语言的海量文本。文本越多,AI 模型的学习效果越好,对词语的理解也就更准确。
但与人类不同的是,AI 模型需要将对词语的学习结果总结为一个量化的结果,才能被计算机程序存储以及持续使用。为了得到量化的结果,AI 领域的研究人员想到了一种方法:将词语在不同维度上分类打分,来对词语归类。
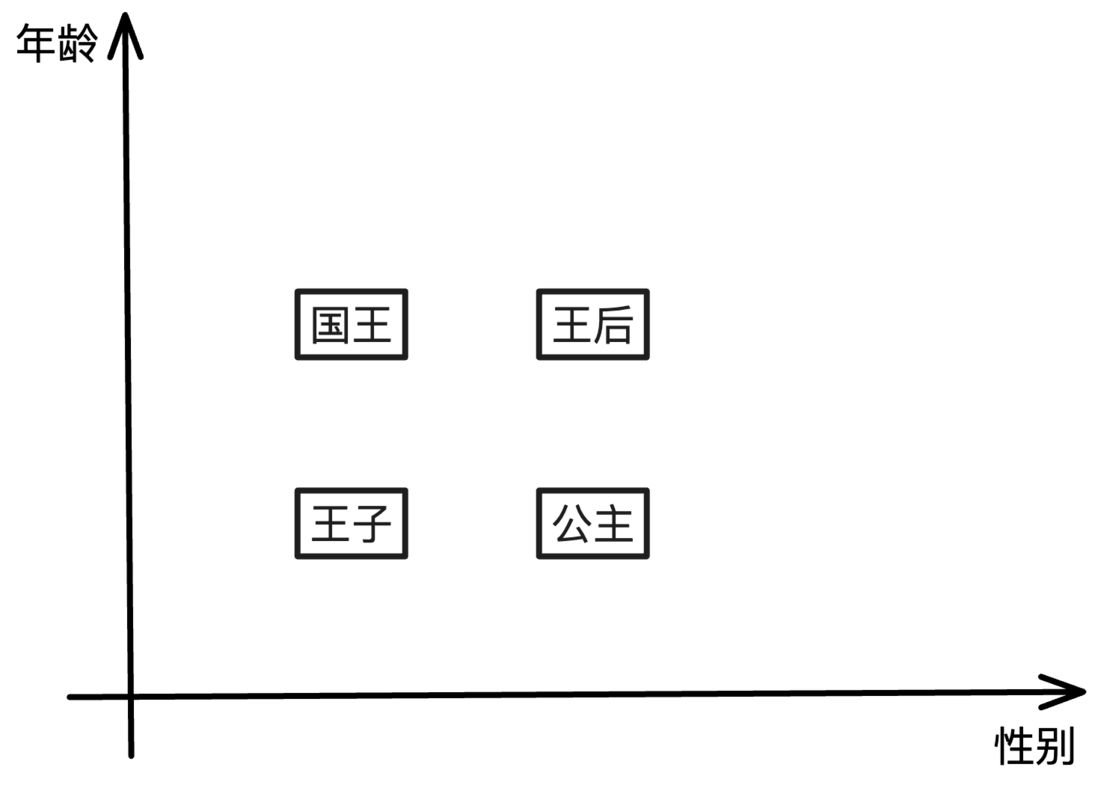
按照这个思路,我们在图中画出了两个维度:性别和年龄。再将四个词语 国王、王后、王子和公主在两个维度上打分,可以看到它们被清晰的分成了不同的类别。
在性别维度上相同的词语,说明词语在性别上的含义相同;同理,在年龄维度上相同的词语,则说明词语在年龄上的含义相同。
为了进一步量化,AI 模型会在维度上标记一些具体的分数代表不同的含义,例如性别维度上用 1 代表男性、2 代表女性,年龄维度上 1 代表少年、2 代表中年、3 代表老年。
以此类推,只要维度足够多、打分足够准确,AI 模型就可以越精准的理解一个词语的含义,而词语在 AI 模型眼中的量化结果就是一组不同维度上的分数。
对于目前较为先进的 AI 模型来说,通常维度的数量可以达到上千个。
AI 眼中的词语
在学习之后,AI 眼中每个词语的量化结果不同,但含义相似的词语在更多维度上会有相同或相近的分数。
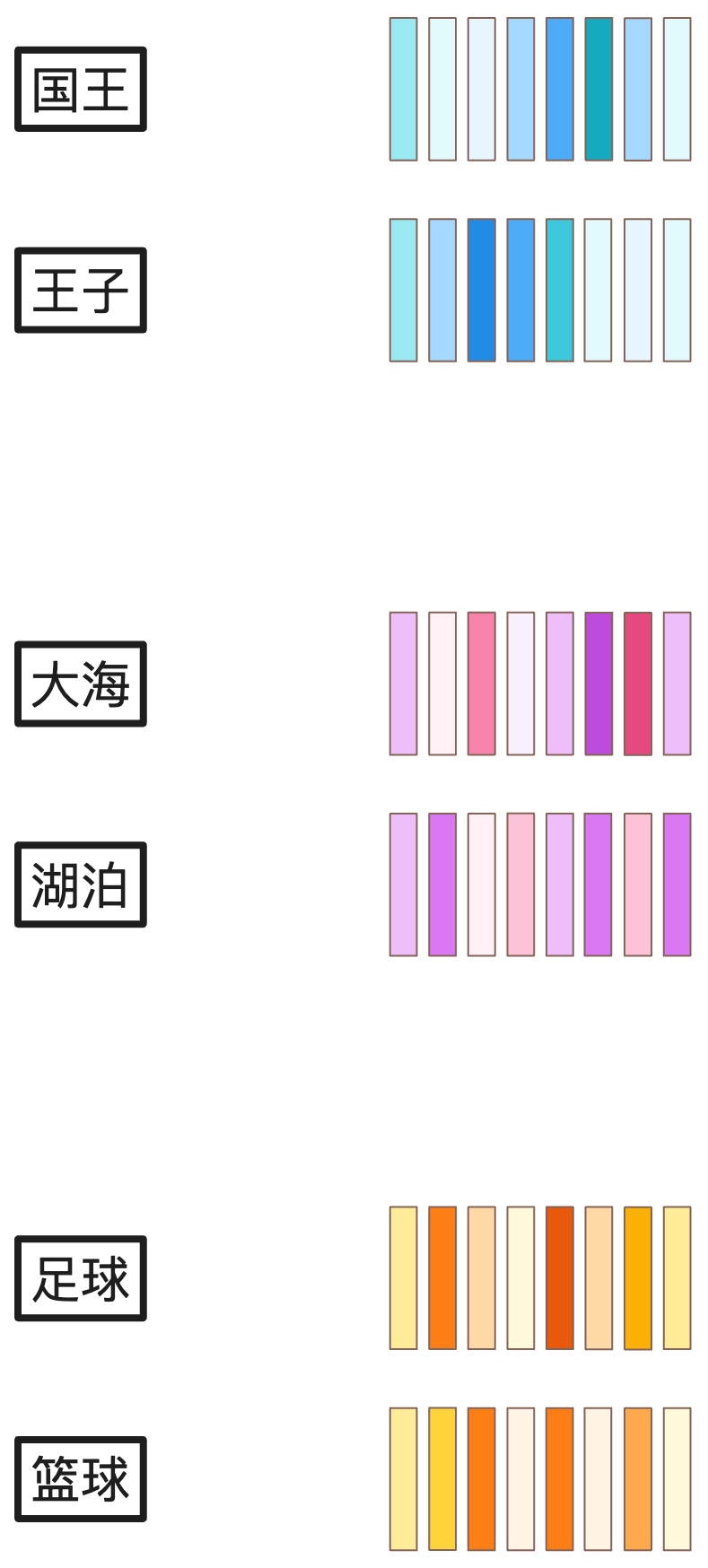
如图中所画,国王和王子两个词语并不相同,但两者之间的含义比国王与大海之间相关性更强,因此它们的量化结果就会更相近。
我们在后续的章节中也将以不同颜色的一组色块示意一个词语在 AI 眼中的量化结果。
与上文所说一致,国王与王子相关性更强,大海与湖泊相关性更强,足球与篮球相关性更强。相关性更强的词语量化结果越相近。
AI 如何理解句子
学习词语并理解为量化的结果只完成了第一步,接下来 AI 就需要进一步理解一组词语的合集:句子。
在教程的开篇,我们提到了一个句子中出现两次苹果的例子。对于同一个 AI 模型,经过学习之后,苹果这个词语就拥有了固定的量化结果,那么如何体现它在这个句子中两次出现的不同含义呢?
目前流行的生成式 AI 模型都使用了相似的技术解决这一问题,而这类技术的理论基础是 2017 年 Google 发布的论文《Attention Is All You Need》,这篇论文也被视作生成式 AI 的开端。
这篇论文提出了一种名为自注意力(Self Attention)的机制。简单来说,当 AI 理解包含了一组词语的句子时,除了理解词语本身,还应该将每个词语和句子中的其他词语相结合进行第二轮理解。单个词语和句子中其他词语之间的关联性,称之为“注意力”,由于是和同一个句子自身的词语结合理解,所以称之为“自注意力”。
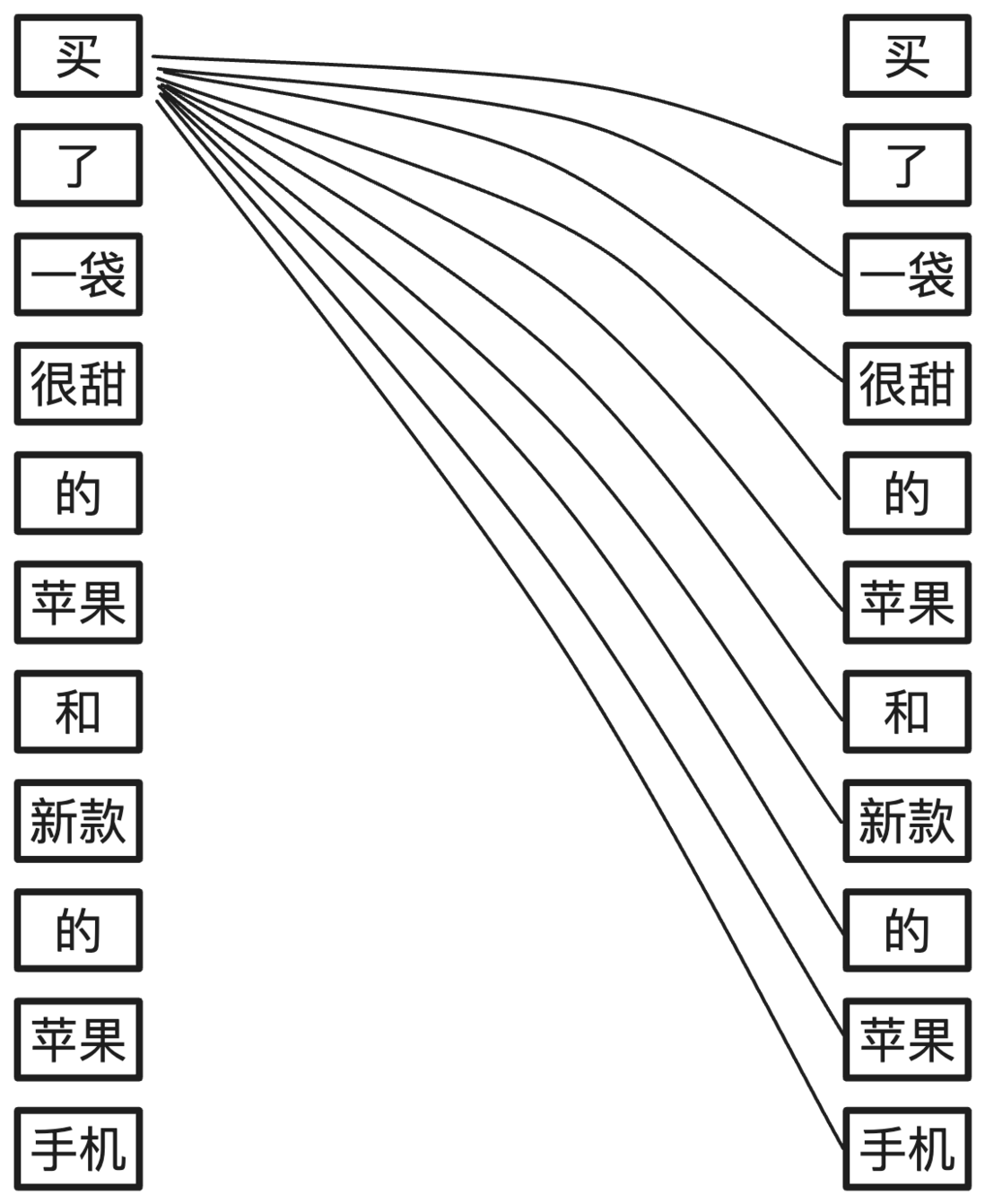
与图中所画类似,每个词语都将经历一轮与句子中其他词语的结合理解,图中所画的是第一个词语买与其他词语的结合过程,其他词语以此类推。
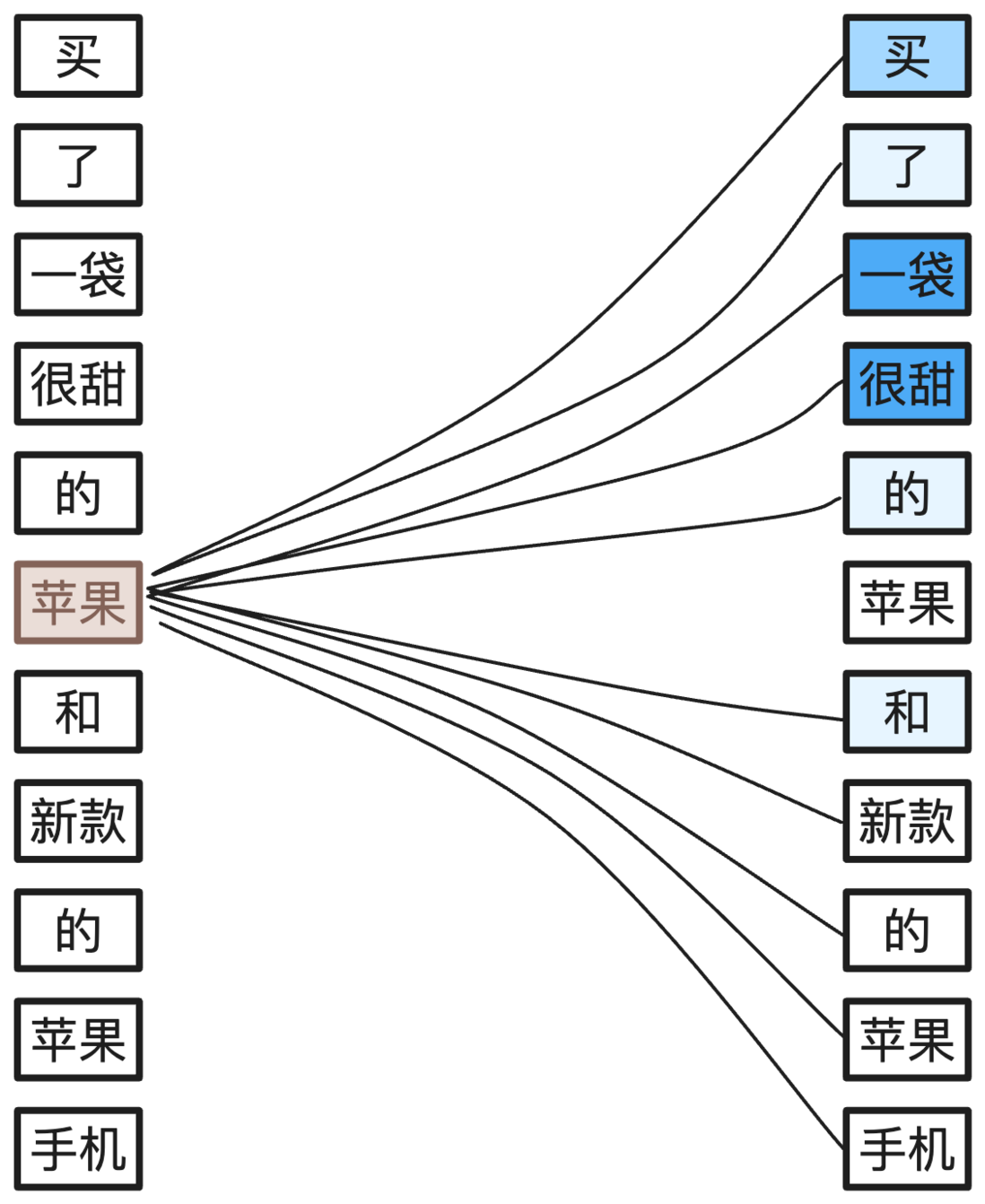
当句子中第一次出现的苹果与其他词语进行结合理解时,基于词语的位置和它自身的量化结果,AI 模型就能理解它与句子中的哪些词语关联性更强。
对于第一次出现的苹果来说,它与图中右侧标记为蓝色的词语关联性更强,蓝色越深代表关联性越强,AI 模型也就会向这些关联性强的词语投入更多的注意力。
在补充自注意力之后,AI 模型就更倾向于认为第一次出现的苹果在句子中的含义是水果,因为只有水果可以使用一袋作为量词、很甜作为形容词。

同样的在补充自注意力之后,AI 模型就更倾向于认为第二次出现的苹果在句子中的含义是一个手机品牌,因为只有手机品牌可以和新款一起形容手机。而句子中的和则让 AI 正确的进行了断句。
基于自注意力的句子理解能力对于生成式 AI 来说是至关重要的,在此基础上,AI 模型才能过避免理解错误或进一步生成错误的内容。
这样的理解能力不仅仅能够在理解“多义词”时起作用,对于其他复杂的场景同样奏效。

我们在原本句子的基础上补充了新的内容它很好用,因为最后一个词语是用,所以在理解它这个词语时,AI 就从与手机相关的词语中获得了更多的注意力,最终正确理解它的含义是新买的手机。
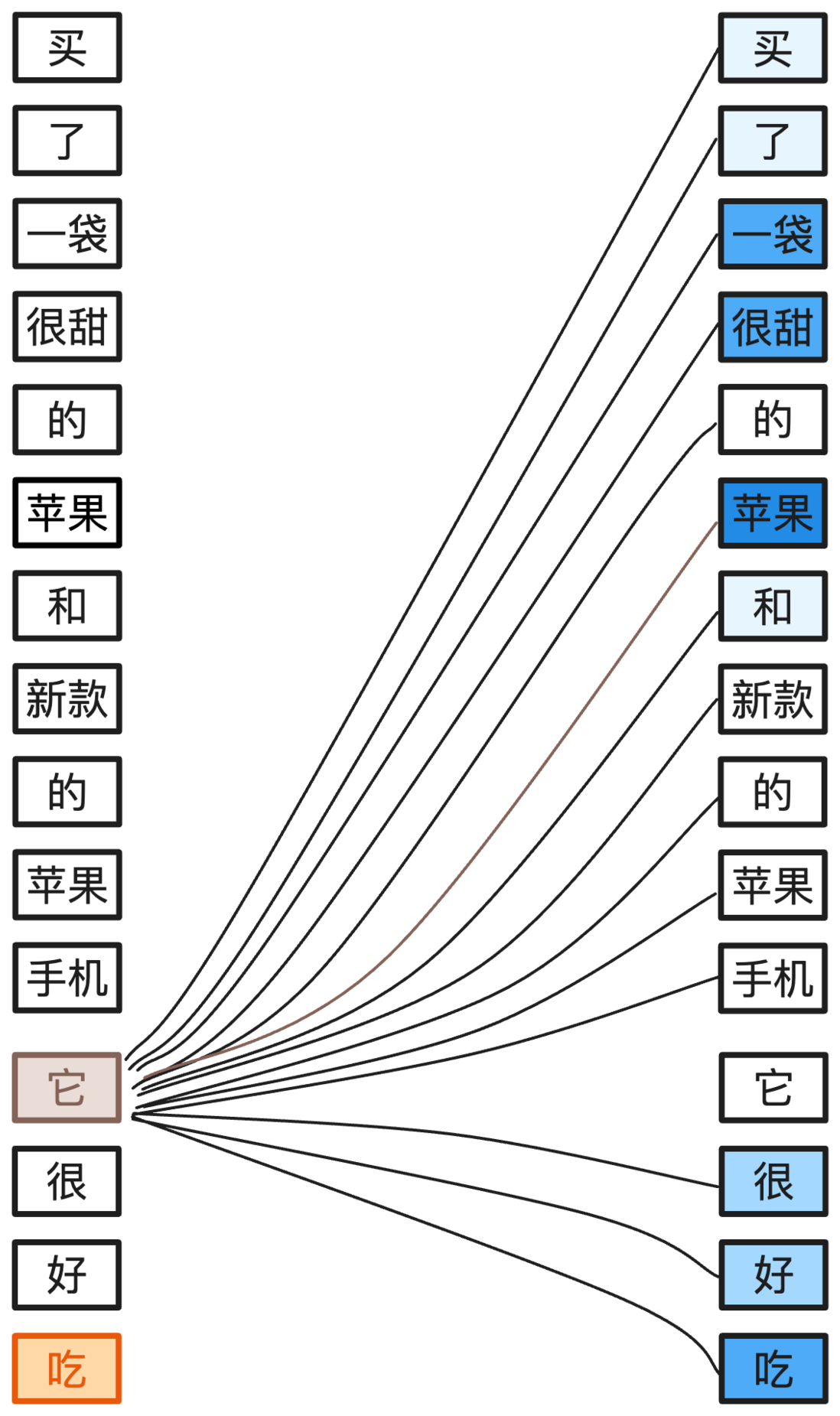
如果将最后一个词语是改为吃,那么在理解它这个词语时,AI 就会从与水果相关的词语中获得了更多的注意力,最终正确理解它的含义是新买的水果。
从这些例子中可以看出,句子中的信息越丰富,使用自注意力技术的模型对于句子中各词语的理解就会越准确,这也是这一技术的强大之处。
以此为基础,AI 模型在理解多个句子时表现的会更好,这也是 ChatGPT 等产品使用人机对话的形式使用 AI 的原因。
AI 如何生成内容
从前面的章节中我们已经知道 AI 模型在理解一个句子中的各个词语时,除了词语自身的量化结果,还会从句子中的其余词语中获取注意力。

在图中,我们以买了一袋很甜的这一不完整的句子作为基础,示意了每个词语自身的量化结果(加号左侧)和来自其余词语的注意力(加号右侧)。
由于所有的信息在 AI 模型中实际都是量化结果,所以 AI 模型可以将所有量化结果进行汇总计算,得到一组新的量化结果(虚线下方)作为它对整个句子的总体理解。
当进行生成时,AI 模型会从自己的词汇表中对比各个词语和当前句子的关联性。
对于我们的例子来说,苹果和橘子都与目前不完整的句子有很高的关联性,而西瓜因为相对较少用一袋形容,所以关联性比前两者更低,报纸的关联性就理应极低了。
在 AI 模型眼中,关联性越强的词语代表它出现在句子之后“可能性”越高,AI 模型就会选择可能性最高的词语作为生成的内容。
当可能性最高的词语被选中之后,句子也将被变为新的更长的句子,AI 模型将重复这一过程,选择下一个可能性最高的词语,从而生成更多内容。
拓展
ChatGPT基于全网的一些数据,很多数据来源于开源。ChatGPT首先肯定是一个效率提升,也会在各行各业很快开花结果但如果要开发一些小领域的应用,它的数据非常少,初期可能泛化性比较差一些。所以我觉得这一块还是另外一个风口——低代码更胜一筹。
介绍一款程序员都应该知道的软件 JNPF 快速开发平台,基于 Java/.Net 双技术引擎,专注于低代码,采用业内领先的 SpringBoot 微服务架构、支持 SpringCloud 模式,完善了平台的扩增基础,满足了系统快速开发、灵活拓展、无缝集成和高性能应用等综合能力;采用前后端分离模式,前端和后端的开发人员可分工合作负责不同板块,省事又便捷。
免费体验官网:www.jnpfsoft.com/?csdn










)








