待更新
把dog-breed-identification.zip 文件放到data文件目录下:
该文件解压之后得到如下:
遍历train中的所有文件,train_file.split(‘.’)[0]是根据.划分这个文件名,得到前缀和后缀,下标为0的是去掉后缀的文件名。
labels[图片的文件名] 得到图片的标签。

for data, targets in tqdm.tqdm(train_iter):# 把数据加载到GPU上data = data.to(device)targets = targets.to(device)
由于dataloader已经把类名和id,对应了起来,所以targets是图片对应的id

图片是 128个,3通道,224 * 224
标签是: 128个图片对应的数字标签
根据文件夹加载数据集,其中文件名是类的名字,程序已经将类的名字映射成了0,1…n
def reorg_train_valid(data_dir, labels, valid_ratio):"""Split the validation set out of the original training set.Defined in :numref:`sec_kaggle_cifar10`"""# The number of examples of the class that has the fewest examples in the# training datasetn = collections.Counter(labels.values()).most_common()[-1][1]# The number of examples per class for the validation setn_valid_per_label = max(1, math.floor(n * valid_ratio))label_count = {}for train_file in os.listdir(os.path.join(data_dir, 'train')):label = labels[train_file.split('.')[0]]fname = os.path.join(data_dir, 'train', train_file)# 文件名 data/train_valid_test/train_valie/dog , 应该是以文件的标签为文件夹,里面放属于该标签的图片copyfile(fname, os.path.join(data_dir, 'train_valid_test','train_valid', label))if label not in label_count or label_count[label] < n_valid_per_label:copyfile(fname, os.path.join(data_dir, 'train_valid_test','valid', label))label_count[label] = label_count.get(label, 0) + 1else:copyfile(fname, os.path.join(data_dir, 'train_valid_test','train', label))return n_valid_per_label

读取CSV获取图片,标签键值对
def read_csv_labels(fname):"""Read `fname` to return a filename to label dictionary.Defined in :numref:`sec_kaggle_cifar10`"""with open(fname, 'r') as f:# Skip the file header line (column name)lines = f.readlines()[1:]tokens = [l.rstrip().split(',') for l in lines]return dict(((name, label) for name, label in tokens))
label.csv文件内容
第一行是列名:图片名字,图片类别

传入该文件到read_csv_labels
labels = d2l.read_csv_labels(os.path.join(data_dir, 'labels.csv'))
labels是图片标签的键值对。
{'000bec180eb18c7604dcecc8fe0dba07': 'boston_bull', '001513dfcb2ffafc82cccf4d8bbaba97': 'dingo', '001cdf01b096e06d78e9e5112d419397': 'pekinese', '00214f311d5d2247d5dfe4fe24b2303d': 'bluetick'}
# 按照测试集比例,把测试集
d2l.reorg_train_valid(data_dir, labels, valid_ratio)
d2l.reorg_test(data_dir)
取出一部分图片,这些图片属于训练的类。但是没有参与训练。
这部分数据集的图片属于的类,没有参与训练。
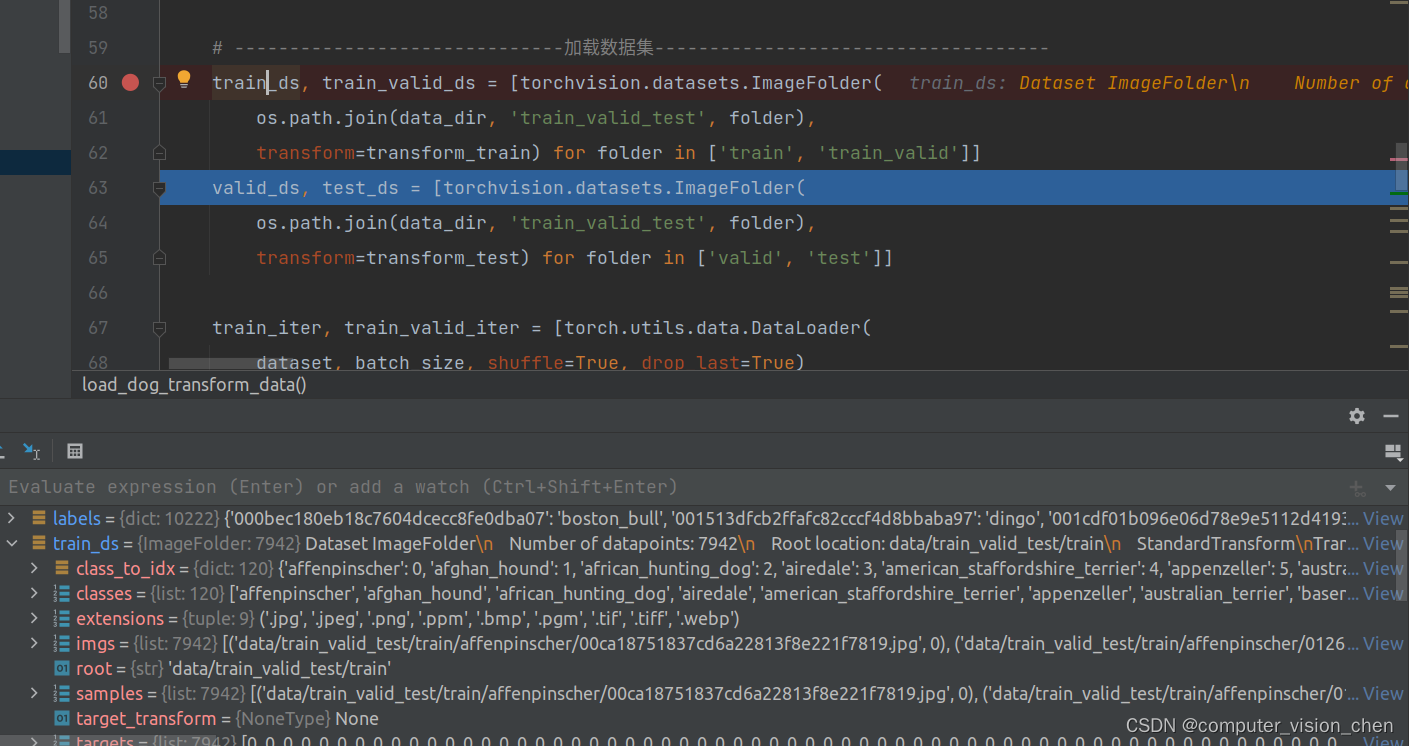
def load_dog_transform_data(valid_ratio=0.1):# ---------------------------------------下载数据-----------------------------------d2l.DATA_HUB['dog_tiny'] = (d2l.DATA_URL + 'kaggle_dog_tiny.zip','0cb91d09b814ecdc07b50f31f8dcad3e81d6a86d')# 如果使用Kaggle比赛的完整数据集,请将下面的变量更改为Falsedemo = Falseif demo:data_dir = d2l.download_extract('dog_tiny')else:data_dir = os.path.join('data', 'dog-breed-identification')# ---------------------------读取训练数据标签、拆分验证集并整理训练集-----------------------batch_size = 32 if demo else 128labels = d2l.read_csv_labels(os.path.join(data_dir, 'labels.csv'))d2l.reorg_train_valid(data_dir, labels, valid_ratio)d2l.reorg_test(data_dir)# ------------------------------定义数据增强方式------------------------------------transform_train = torchvision.transforms.Compose([# 随机裁剪图像,所得图像为原始面积的0.08〜1之间,高宽比在3/4和4/3之间。# 然后,缩放图像以创建224x224的新图像torchvision.transforms.RandomResizedCrop(224, scale=(0.08, 1.0),ratio=(3.0 / 4.0, 4.0 / 3.0)),torchvision.transforms.RandomHorizontalFlip(),# 随机更改亮度,对比度和饱和度torchvision.transforms.ColorJitter(brightness=0.4,contrast=0.4,saturation=0.4),# 添加随机噪声torchvision.transforms.ToTensor(),# 标准化图像的每个通道torchvision.transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])# 测试时, 我们只使用确定性的图像预处理操作。transform_test = torchvision.transforms.Compose([torchvision.transforms.Resize(256),# 从图像中心裁切224x224大小的图片torchvision.transforms.CenterCrop(224),torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])])# ------------------------------划分数据集------------------------------------train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train_valid_test', folder),transform=transform_train) for folder in ['train', 'train_valid']]valid_ds, test_ds = [torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train_valid_test', folder),transform=transform_test) for folder in ['valid', 'test']]train_iter, train_valid_iter = [torch.utils.data.DataLoader(dataset, batch_size, shuffle=True, drop_last=True)for dataset in (train_ds, train_valid_ds)]valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size, shuffle=False,drop_last=True)test_iter = torch.utils.data.DataLoader(test_ds, batch_size, shuffle=False, drop_last=False)return train_iter,train_valid_iter,valid_iter,test_iterdef load_best_weight(model,best_weight_path):model_para_dict_temp = torch.load(best_weight_path)model_para_dict = {}for key_i in model_para_dict_temp.keys():model_para_dict[key_i[7:]] = model_para_dict_temp[key_i] # 删除掉前7个字符'module.'del model_para_dict_tempmodel.load_state_dict(model_para_dict)return model
待更新



)





)









