大家好,我是伍六七。一个专注于输出 AI+ 编程内容的在职大厂资深程序员,全国最大 AI 付费社群破局初创合伙人,关注我一起破除 35 诅咒。
Redis 基本上是大部分技术公司都会使用的缓存框架,但是我发现很多程序员其实并不懂 Redis。
今天,阿七带大家从理论和实践的角度来了解和使用 Redis。
1 缓存基本思想
1、不同的存储介质访问延迟不一样,相同成本存储容量不一样
SSD/Disk、Memory、L3 cache、L2 cache、L1 cache 五种存储介质,访问延迟逐渐降低,但是同等成本的容量却逐渐增大。
2、时间局限性原理
被获取过一次的数据在未来会被多次获取。
3、以空间换时间
开辟一块高速独立空间,提供高速访问。
4、性能成本权衡
访问延迟性低、性能越高,等容量成本越高。
2 缓存优势
- 提升访问性能
- 降低网络拥堵
- 减轻服务负载
- 增强可扩展性
3 缓存代价
- 系统复杂性提高
- 存储和部署成本变高
- 数据一致性问题
4 缓存的三种模式
4.1 Cache Aside 旁路缓存
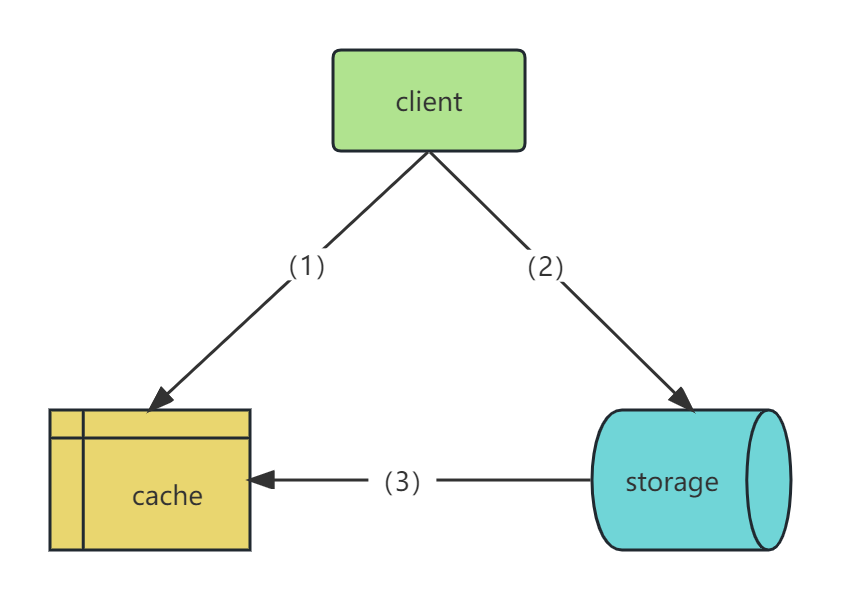
核心思想
写操作:更新 DB 之后,直接将 key 从缓存中删除;
读操作:先读缓存,如果没有,则读 DB,同时将 DB 的数据同步到缓存中。
特点
业务端处理所有数据访问细节,同时利用 lazy 懒加载思想,更新 DB 之后,直接删除缓存并通过 DB 更新,确保数据以 DB 为准,可以大幅降低缓存和 DB 之间的不一致的概率。
缺点
1、如果删除缓存失败,可能会有问题;
解决方法
失败增加监控
2、如果同时有比较高的QPS访问刚插入或者更新的数据,可能会打垮DB;
解决方法
使用多线程异步执行查询,防止这种问题。
场景:读多写少。比如用户数据,用户修改用户信息很少,但是各种业务场景用到用户数据的读场景比较多。
4.2 Read/Write Through

核心思想
读写缓存和 DB 的操作,都有一个中间的数据服务代理。
写操作:先查缓存,如果缓存不存在,则只更新 DB;如果缓存中存在,则先更新缓存,再更新 DB,然后返回;
读操作:先查缓存,如果命中则直接返回。否则从 DB 中加载,然后回种到缓存中再返回。
特点:业务端不需要关心数据细节,系统隔离性好。
4.3 write-Back 或者 Write-Behind
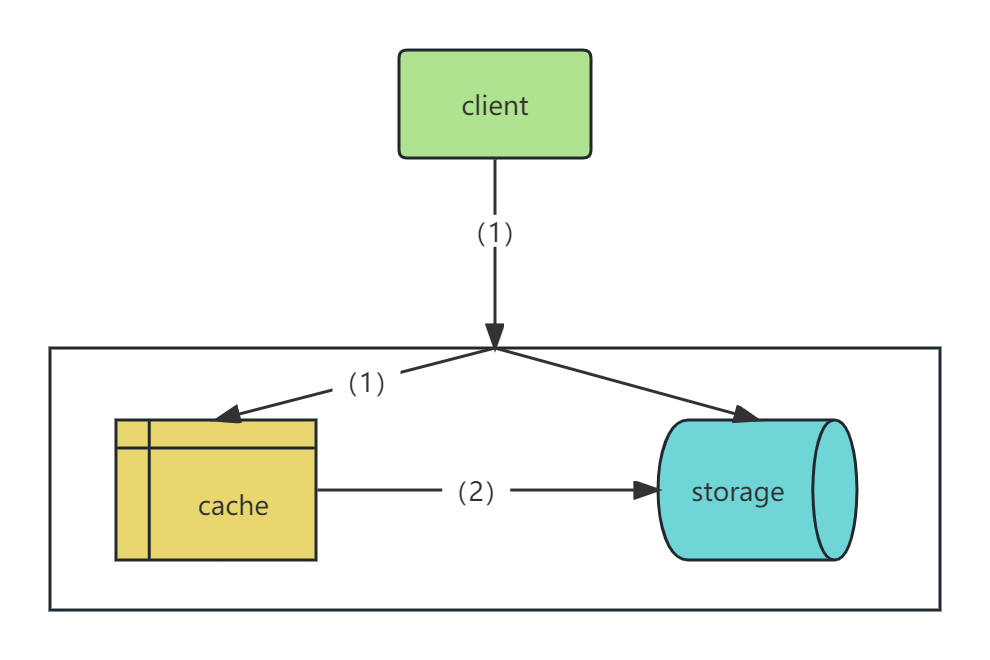
核心思想
承接 Write Through,写操作更新完缓存之后,异步回写数据到 DB 或者批量回写数据到 DB。
缺点
异步或者批量回写,可能会导致数据丢失。
特点
合并或者异步写 DB,DB 压力小。
使用场景:写频率很高,但是对于数据一致性要求不太高的业务。
5 Redis 常见面试题
5.1 Redis 雪崩
概念
大量的应用请求无法在 Redis 缓存中进行处理,紧接着,
应用将大量请求发送到数据库层,导致数据库层的压力激增。
原因
1、缓存中有大量数据同时过期,导致大量请求无法得到处理
2、Redis 缓存实例发生故障宕机了
解决方案:
针对原因 1
- 方法1:避免给大量的数据设置相同的过期时间。
- 方法2: 降级直接返回预定义信息、空值或是错误信息。
针对原因 2
- 方法1: 在业务系统中实现服务熔断或请求限流机制。
- 方法2: 服务端 限流。
事前预防:使用主从节点 构建 Redis 缓存高可靠集群
5.2 击穿
概念:1、是发生在某个热点数据失效的场景下,大量请求直接访问 DB,DB 压力骤增,业务响应延迟。
原因:热点 key 过期失效或者同时失效。
解决办法:热点 key 不设置过期时间;或者设置过期时间为基础时间+随机时间。
5.3 穿透
概念:要访问的数据既不在 Redis 缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。
原因:1、业务层误删除数据了;2、恶意攻击:专门访问数据库中没有的数据。
解决方法:
- 1、缺省值或者空值。
- 2、使用布隆过滤器快速判断数据是否存在,避免从数据库中查询数据是否存在,减轻数据库压力。
- 3、前端进行请求检测
5.4 bigKey
概念:一个缓存 key,存储数据过多。比如一个上万记录的 List;
危害:
1、造成内存分配不均匀。比如在 Redis cluster 或者 Codis 中,会造成节点的内存使用不均匀;
2、超时阻塞。因为 Redis 单线程特性,如果操作某个 bigKey 耗时比较久,则后面的请求会被阻塞。
3、网络阻塞,消耗带宽。
4、过期删除,会很慢,会阻塞 Redis。如果 Bigkey 设置了过期时间,当过期后,这个 key 会被删除,假如没有使用 Redis 4.0 的过期异步删除,
就会存在阻塞 Redis 的可能性,并且慢查询中查不到(因为这个删除是内部循环事件)。
如何发现?
Redis 命令: redis-cli --bigkeys
解决方法
- 删除 bigKey。
- Redis4.0 之后,异步删除;
- 集合类型:用 scan,读取部分数据删除;
- Hash类型,用 Hscan,读取部分数据删除
- 拆分
- String类型,拆分成多个 key
- 集合或者 Hash 类型,拆分成多个 List 或者 Hash
5.5 热 key
概念
所谓热 key 问题就是,突然有几十万的请求去访问 Redis 上的某个特定key。
那么,这样会造成流量过于集中,达到物理网卡上限,从而导致这台 Redis 的服务器宕机。
解决
1、二级缓存——本地缓存。比如利用 ehCache,或者一个- HashMap 都可以。在你发现热 key 以后,把热 key 加载到系统的 JVM 中。
针对这种热 key 请求,会直接从 jvm 中取,而不会走到 Redis 层。
2、备份热key。不要让key走到同一台redis上不就行了。我们把这个key,在多个redis上都存一份不就好了。
接下来,有热key请求进来的时候,我们就在有备份的redis上随机选取一台,进行访问取值,返回数据。
< END >
链接我,免费领取Java面试全套pdf(带答案)
)


)

![[dfs] 图案计数](http://pic.xiahunao.cn/[dfs] 图案计数)
, Netcat反弹shell)





)


)



