FPGA纯verilog实现 LZMA 数据压缩,提供工程源码和技术支持
目录
- 1、前言
- 2、我这儿已有的FPGA压缩算法方案
- 3、FPGA LZMA数据压缩功能和性能
- 4、FPGA LZMA 数据压缩设计方案
-
- 输入输出接口描述
- 数据处理流程
-
- LZ检索器
- 数据同步
- LZMA 压缩器
- 为输出LZMA压缩流添加文件头
- 5、vivado仿真
- 6、福利:工程代码的获取
1、前言
说到FPGA的应用,数据压缩算法的硬件加速器无疑是经典应用之一,用FPGA压缩图片、视频、普通数据等都具有并行执行的独特优势,关于FPGA压缩图片和视频,我之前的博客有相关设计,今天讲讲用FPGA实现对普通数据进行LZMA 压缩算法的实现;本工程源码的功能就是:基于 FPGA 的流式的 LZMA 压缩器,用于通用无损数据压缩:输入原始数据,输出标准的 LZMA 格式,LZMA 是一种常用的数据压缩算法。“.7z” 和 “.xz” 格式默认使用的算法是 LZMA。“.zip” 格式也支持 LZMA 算法。 LZMA 的压缩率通常高于 GZIP/DEFLATE 和 BZIP;
2、我这儿已有的FPGA压缩算法方案
我这里有图像的JPEG解压缩、JPEG-LS压缩、H264编解码、H265编解码以及其他方案,后续还会出更多方案,我把他们整合在一个专栏里面,会持续更新,专栏地址:
直接点击前往
3、FPGA LZMA数据压缩功能和性能
3.1:纯 RTL 设计,在各种 FPGA 型号上都可以部署;
3.2:极简的流式输入/输出接口 ,输入待压缩数据,输出LZMA压缩流。
3.3:LZMA 字典大小: 131072 字节。哈希匹配搜索引擎包含 4096个哈希值 × 8个哈希entry
3.4:压缩率高,详情如下:
使用一个 512KB data 作为待压缩数据,比较该压缩器与其它压缩方案,结果见下表。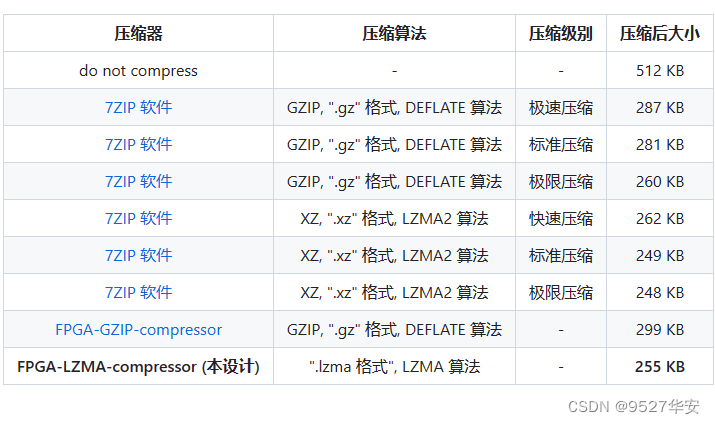
3.5:FPGA 资源占用小,具体如下:
在 Xilinx 7 系列上占 2275 LUTs 和 55 BRAM36K;
在 Altera Cyclone IV 系列上占 3484 LUTs and 1.8 Mbits BRAM;
3.6:性能如下:
3.6.1:平均输入一个字节需要 13 周期;
3.6.2:在 Xilinx Artix7 的速度最慢的FPGA (-1 速率级别) 上达到 118 MHz ,平均性能约为 118/13 = 9MB/s;
3.6.3:在 Xilinx Zynq Ultrascale+ 的速度最慢的FPGA (-1 速率级别) 上达到 250 MHz ,平均性能约为 250/13 = 19MB/s;
3.6.4:在 Altera Cyclone IV E 的速度最慢的FPGA (8 速率级别) 上达到 83 MHz ,平均性能约为 83/13 = 6.3MB/s;
3.6.5:当前版本的压缩率和FPGA资源消耗都足够好,但性能还不够让我满意 (7ZIP的LZMA快速压缩在个人计算机上使用单线程,性能约为约为5~10MB/s)。因此,当前版本可能仅适用于某些嵌入式应用。我将来会优化它的性能。
4、FPGA LZMA 数据压缩设计方案
FPGA LZMA 数据压缩设计方案框图如下: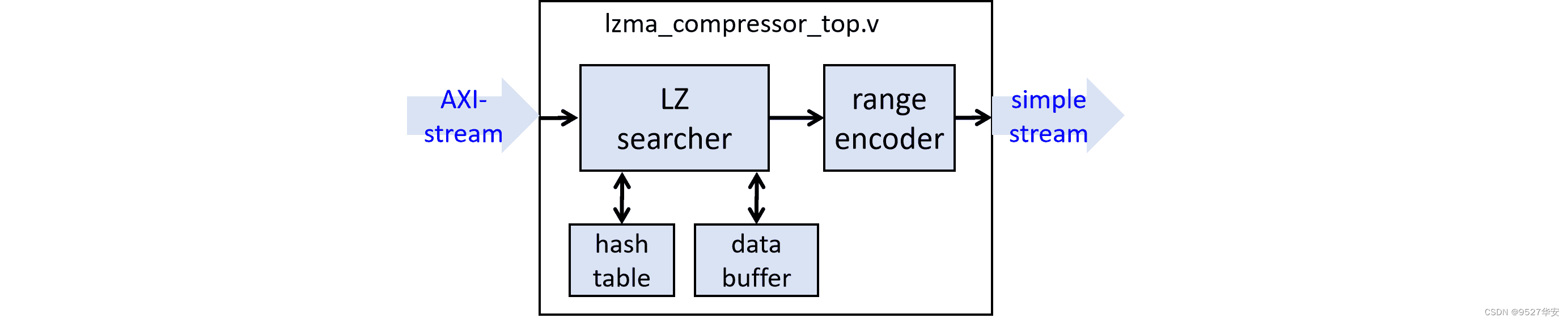
其中的哈希列表和数据缓冲buffer在模块中的位置如下:
输入输出接口描述
输出接口是精简的、无握手的、8-bit 位宽的 AXI-stream master ,用来输出 LZMA 压缩流。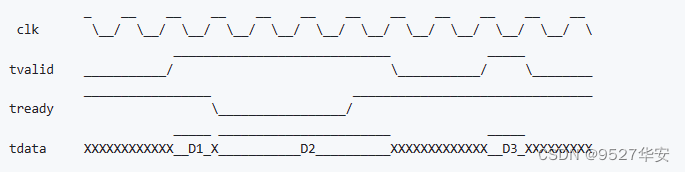
所有信号都在 clk 的上升沿改变或被采样
o_valid=1 时, o_data 有效;
o_data 是输出的 LZMA 压缩流中的一个字节;
o_last 用来界定 LZMA 压缩流的边界。当 o_valid=1 且 o_last=1 ,说明当前字节是一个LZMA压缩流的最后一个字节;
当 o_last=1 时,一定有 o_valid=1;
输出接口是精简的、无握手的、8-bit 位宽的 AXI-stream master ,用来输出 LZMA 压缩流。
所有信号都在 clk 的上升沿改变或被采样;
o_valid=1 时, o_data 有效;
o_data 是输出的 LZMA 压缩流中的一个字节;
o_last 用来界定 LZMA 压缩流的边界。当 o_valid=1 且 o_last=1 ,说明当前字节是一个LZMA压缩流的最后一个字节;
当 o_last=1 时,一定有 o_valid=1;
数据处理流程
LZ检索器
详见计方案框图;
输入数据首先给到LZ检索器进行数据处理;
LZ检索器在代码中的位置如下:可以看到,由纯verilog代码实现;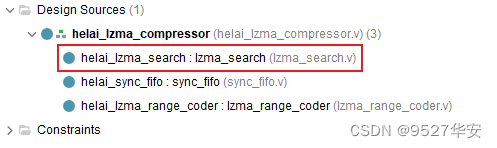
数据同步
LZ模块输出的数据需要做数据同步 处理,使用一个纯verilog编写的同步fifo实现,这个比较简单,不必多说,在代码中的位置如下:
LZMA 压缩器
LZMA 压缩器是整个代码的核心,采用标准的LZMA 算法实现,只不过将该算法用verilog代码实现了,在代码中的位置如下:
为输出LZMA压缩流添加文件头
为了让输出的LZMA流被各种解压软件识别,我们需要使用“容器格式”(即添加文件头或文件尾)。注意,“.zip”、“.xz”、“.7z” 都是容器格式。它们比较复杂,这里我们不介绍它们。
这里只介绍一种非常简单的容器格式 : “.lzma” 格式。它的格式是:
.lzma" 格式 = 13字节文件头 + LZMA压缩流
其中,13字节文件头是固定的:
0x5E, 0x00, 0x00, 0x02, 0x00, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF
当我们将完整的 “.lzma” 格式的数据 (13字节文件头+LZMA压缩流) 保存到 “.lzma” 文件后,就可以用各种官方压缩软件来解压它 。
5、vivado仿真
vivado仿真设计框图如下: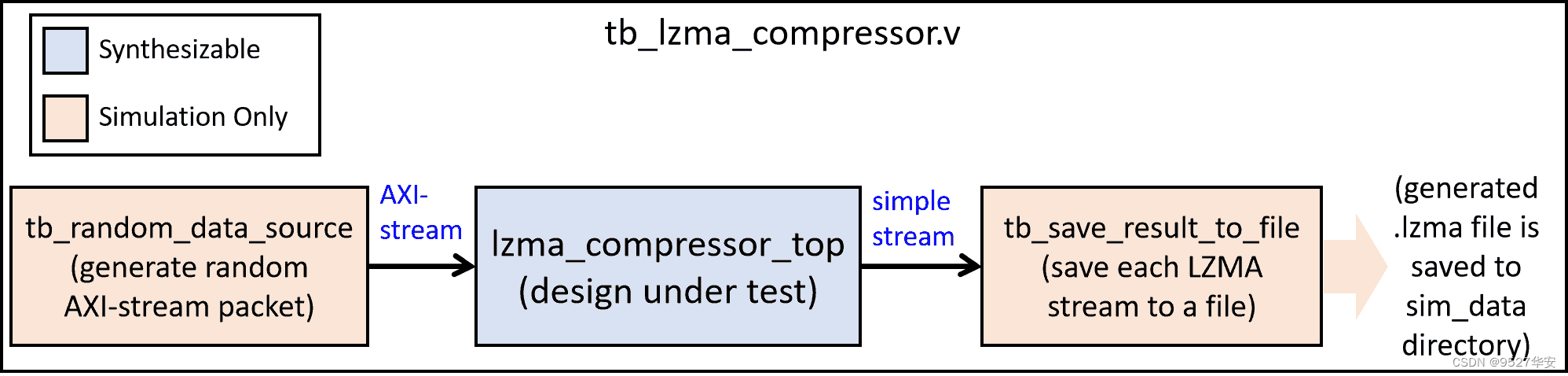
其中,随机数据包生成器 (tb_random_data_source.v) 将生成四种不同特征的数据包 (均匀分布的随机字节、非均匀分布的随意字节、随机连续变化的数据和稀疏数据) ,这些数据包将被发送到待测设计 (lzma_compressor_top) 进行压缩。
tb_save_result_to_file.v 模块将压缩后的结果存储到文件。每个 LZMA压缩流都会存储在一个独立的 “.lzma” 文件中 (该模块也负责附加13字节的文件头)。
vivado仿真代码架构如下: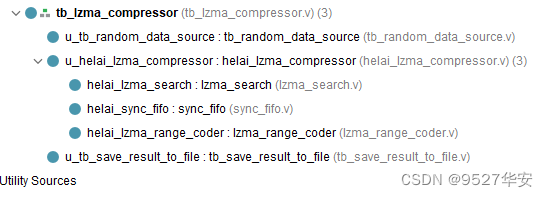
vivado仿真打印结果如下: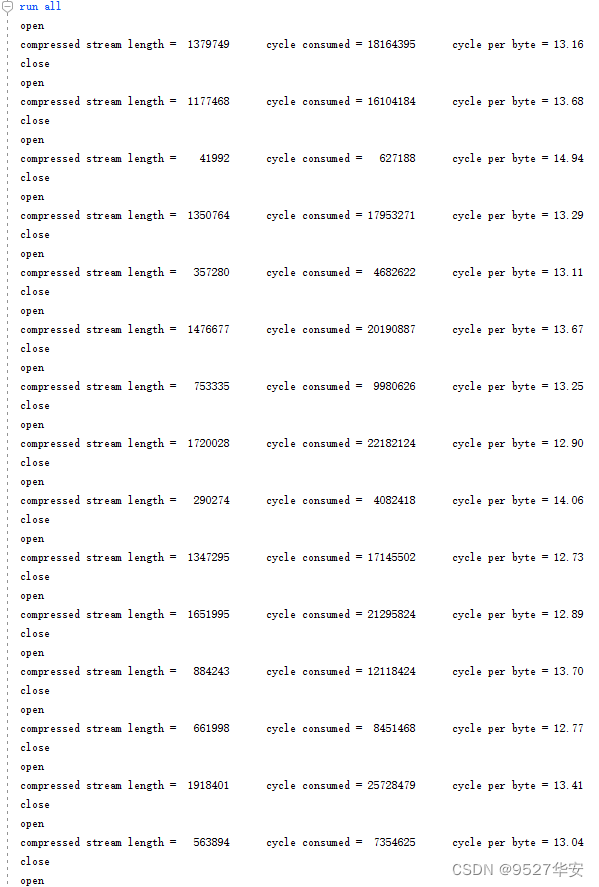
仿真波形如下: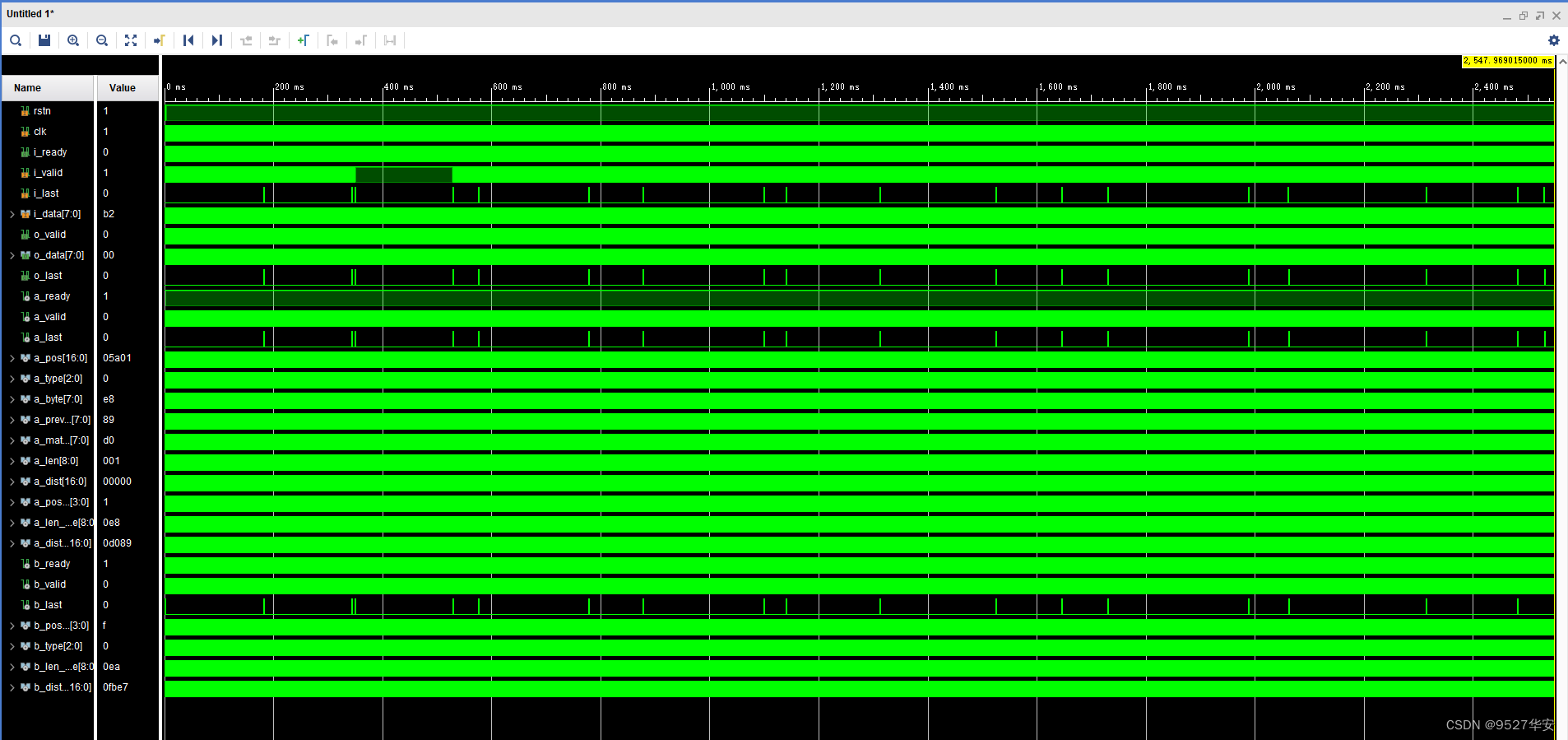
仿真后生成的zip压缩文件保存的路径如下: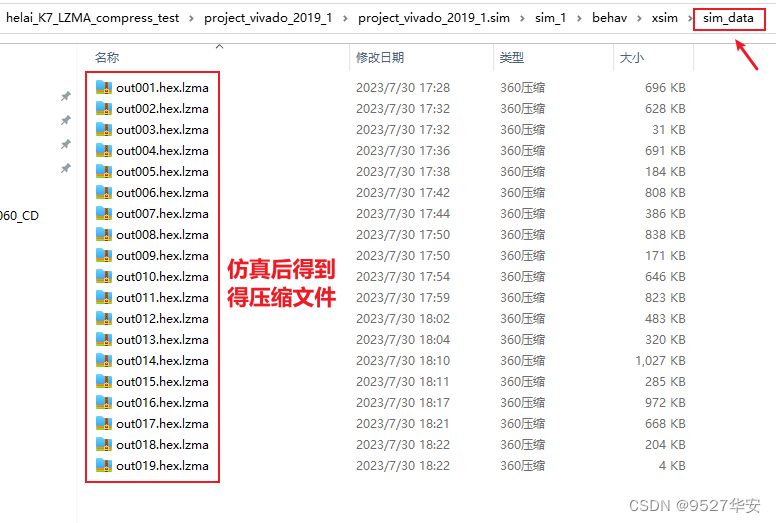
然后可以用LZMA解压软件或者Windows自带的字节软件将其解压打开看,LZMA解压软件在资料包中,如下:
如果你喜欢用iverilog平台仿真,可以直接点击上图中的bat文件仿真;
6、福利:工程代码的获取
福利:工程代码的获取
代码太大,无法邮箱发送,以某度网盘链接方式发送,
资料获取方式:文章末尾的V名片。
网盘资料如下:

519-基于ZU19EG的4路100G光纤的PCIe 加速计算卡

一、板卡概述
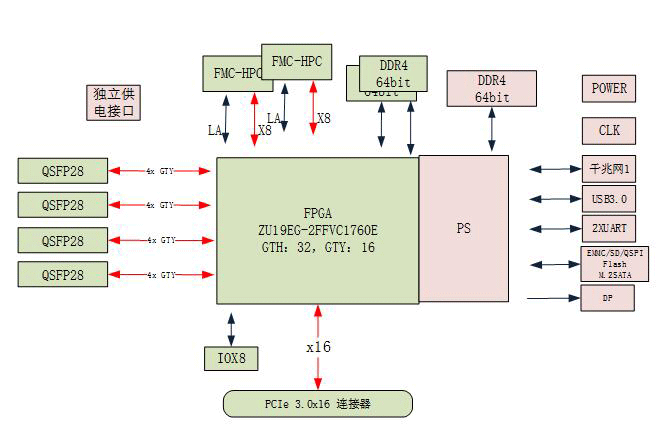
本板卡系我司自主设计研发,基于Xilinx公司Zynq UltraScale+ MPSOC系列SOC XCZU19EG-FFVC1760架构,支持PCIE Gen3x16模式。其中,ARM端搭载一组64-bit DDR4,总容量达4GB,可稳定运行在2400MT/s,PL端支持两组64-bit DDR4,每组容量均为4GB,最高运行速率支持2666MT/s;板卡具有自控上电顺序,支持多种启动模式,如Nor Flash启动,EMMC启动,SD卡启动等。板卡对外支持1路USB3.0接口、1路千兆以太网接口、1路DP输出接口、2路调试串口(RS232)、2路Can接口,另有4路QSFP28接口,支持100G数据传输速率。PL端扩展1个标准FMC HPC接口,支持8路GTH接口和LA/HA/HB全定义接口。板卡设计满足工业级要求,可用于高速信号处理、车载雷达信号处理等领域。
图 2:ZU19EG板卡原理框图
二、主要功能和性能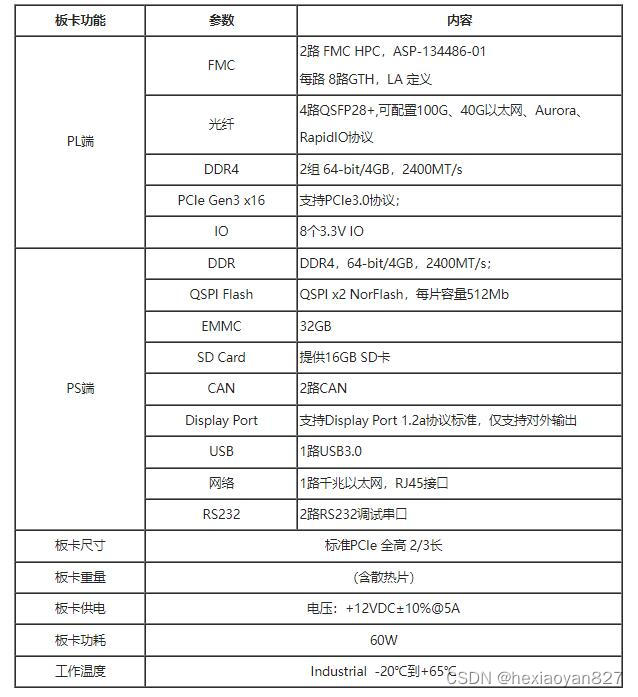
三、软件支持
● PS端QSPI加载测试代码;
● PS端EMMC加载测试代码;
● PS端SD卡加载测试代码;
● PS端DDR4读写测试代码;
● PS端千兆网口收发测试代码;
● PS端RS232接口读写测试代码;
● PS端CAN接口读写测试代码;
● PS端DisplayPort接口测试代码;
● PS端USB3.0接口读写测试代码;
● PL端SPI接口的DataFlash读写测试代码;
● PL端4组 QSFP28+接口ibert模式测试代码;
● PL端的DDR读写测试代码
● PL端PCIe Gen3 x16 XDMA接口测试软件;
● 其它GPIO信号连通性测试代码;
四、应用领域
高速信号处理, 光纤接入,加速计算


)


)










)


