文章目录
- 一 分离领域
- 二 领域对象分类
- 2.1 实体(ENTITY)
- 2.2 值对象(VALUE OBJECT)
- 2.3 服务(SERVICE)
- 2.4 模块(MODULE)
- 三 管理领域对象的生命周期
- 3.1 聚合(AGGREGATE)
- 3.2 工厂(FACTORY)
- 3.3 存储库(REPOSITORY)
了解了如何创建和运用模型之后,我们再来探讨下如何构造一个领域模型。这就需要我们对领域进行分离,了解领域对象的分类及生命周期的管理。
一 分离领域
与领域有关的代码分散在大量的其他代码之中,那么查看和分析领域代码就会变得异常困难。也难以进行领域驱动设计。所以我们首先应该对领域进行分层。
我们需要给复杂的应用程序划分层次。在每一层内分别进行设计,使其具有内聚性并且只依赖于它的下层。采用标准的架构模式,只与上层进行松散的耦合。将所有与领域模型相关的代码放在一个层中,并把它与用户界面层、应用层以及基础设施层的代码分开。领域对象应该将重点放在如何表达领域模型上,而不需要考虑自己的显示和存储问题,也无需管理应用任务等内容。这使得模型的含义足够丰富,结构足够清晰,可以捕捉到基本的业务知识,并有效地使用这些知识。
目前软件大都采用LAYERED ARCHITECTURE(分层架构)模式进行对领域进行分层,其中比较成熟的分层方式是以下4个概念层,或相应的某种变体:
用户界面层(或表示层)
负责向用户显示信息和解释用户指令。这里指的用户可以是另一个计算机系统,不一定是使用用户界面的人。
应用层
定义软件要完成的任务,并且指挥表达领域概念的对象来解决问题。这一层所负责的工作对业务来说意义重大,也是与其他系统的应用层进行交互的必要渠道应用层要尽量简单,不包含业务规则或者知识,而只为下一层中的领域对象协调任务,分配工作,使它们互相协作。它没有反映业务情况的状态,但是却可以具有另外一种状态,为用户或程序显示某个任务的进度。
领域层(或模型层)
负责表达业务概念,业务状态信息以及业务规则。尽管保存业务状态的技术细节是由基础设施层实现的,但是反映业务情况的状态是由本层控制并且使用的。领域层是业务软件的核心。
基础设施层
为上面各层提供通用的技术能力:为应用层传递消息,为领域层提供持久化机制,为用户界面层绘制屏幕组件等等。
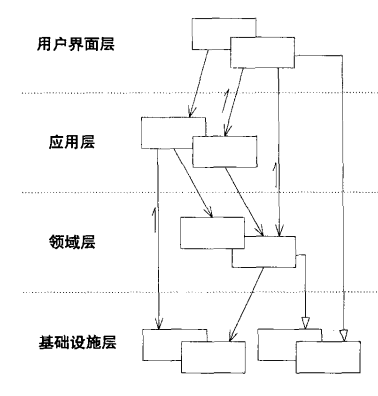
但上述这种依赖的结构已经不太适用了,这里可以通过Robert C. Martin提出的依赖倒置原则,将四层结构的依赖关系修改下:
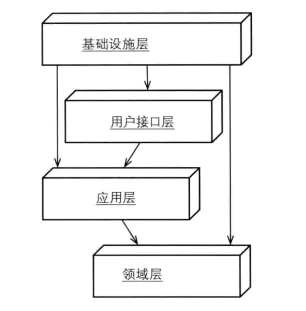
将领域层分离出来才是实现领域驱动设计的关键。也是是领域驱动设计的前提。当然如果你领域业务非常简单,也可以不进行分层。但如果你需要开发复杂的领域业务,那就必须要进行分离了。
这里引申一下,在《DCI架构:面向对象编程的新构想》一书中又提出了一些分层架构,总体上可以在上述四个分层基础上再扩充一个分层Context:
Context是环境层,以上下文为单位,将Domain层的领域对象cast成合适的role,让role交互起来完成业务逻辑。
二 领域对象分类
2.1 实体(ENTITY)
ENTITY 就是通过连续性和标识,而不是通过它们的属性进行定义的对象。ENTITY 具有生命周期,它的类定义、职责、属性和关联必须由其标识来决定,而不依赖于其所具有的属性。
对ENTITY建模,应该用于识别、查找或匹配对象的特征。只添加那些对概念至关重要的行为和这些行为所必需的属性。不要将注意力集中在属性或行为上,应该将行为和属性转移到与核心实体关联的其他对象中。
2.2 值对象(VALUE OBJECT)
VALUE OBJECT(值对象)是用于描述领域的某个方面而本身没有概念标识的对象。只关心它们是什么,而不关心它们是谁,比如颜色,某个数字等。VALUE OBJECT可以是其他对象的集合,甚至可以引用ENTITY。VALUE OBJECT经常作为参数在对象之间传递消息。
当我们只关心一个模型元素的属性时,应把它归类为VALUE OBJECT。我们应该使这个模型元素能够表示出其属性的意义,并为它提供相关功能,同时不要为它分配任何标识,而且不要把它设计成像ENTITY那么复杂。
VALUE OBJECT应当尽量遵循一条基本规则,那就是将其指定为不可变的,只可替换不可修改,这样会减少很多不必要的问题。同时我们应该尽量完全清除VALUE OBJECT之间的双向关联,如果确实存在双向关联,则需要考虑该对象是否应该被声明为VALUE OBJECT。
2.3 服务(SERVICE)
SERVICE 是指那些对象之间的操作,强调的是与其他对象的关系,它只是定义了能够为客户做什么。它不应该替代ENTITY和VALUE OBJECT的所有行为,而是应该将模型中的独立操作声明为一个SERVICE,参数和结果最好都是领域对象。
好的SERVICE有以下3个特征:
(1) 与领域概念相关的操作不是ENTITY或VALUE OBJECT的一个自然组成部分。
(2) 接口是根据领域模型的其他元素定义的。
(3) 操作是无状态的。无状态是指任何客户都可以使用某个SERVICE的任何实例,而不必关心该实例的历史状态。
当领域中的某个重要的过程或转换操作不是ENTITY或VALUE OBJECT的自然职责时,应该在模型中添加一个作为独立接口的操作,并将其声明为SERVICE。定义接口时要使用模型语言,并确保操作名称是UBIQUITOUS LANGUAGE中的术语。
SERVICE 划分
SERVICE并不只是在领域层中使用。在各层中都可以使用SERVICE,我们需要注意区分属于领域层的SERVICE和那些属于其他层的SERVICE,并划分责任,以便将它们明确地区分开。
2.4 模块(MODULE)
MODULE是一种更粗粒度的建模和设计元素,包含了一个内聚的概念集合。可采用高内聚低耦合的原则进行划分,从更大的角度描述了领域。MODULE为人们提供了两种观察模型的方式,一是可以在MODULE中查看细节,而不会被整个模型淹没,二是观察MODULE之间的关系,而不考虑其内部细节。
MODULE的名称也应该是UBIQUITOUS LANGUAGE中的术语。MODULE及其名称应反映出领域的深层知识,需要与模型的其他部分一同演变,这意味着MODULE的重构必须与模型和代码一起进行。
三 管理领域对象的生命周期
每个对象都有生命周期,如下图所示。对象自创建后,可能会经历各种不同的状态,直至最终消亡。
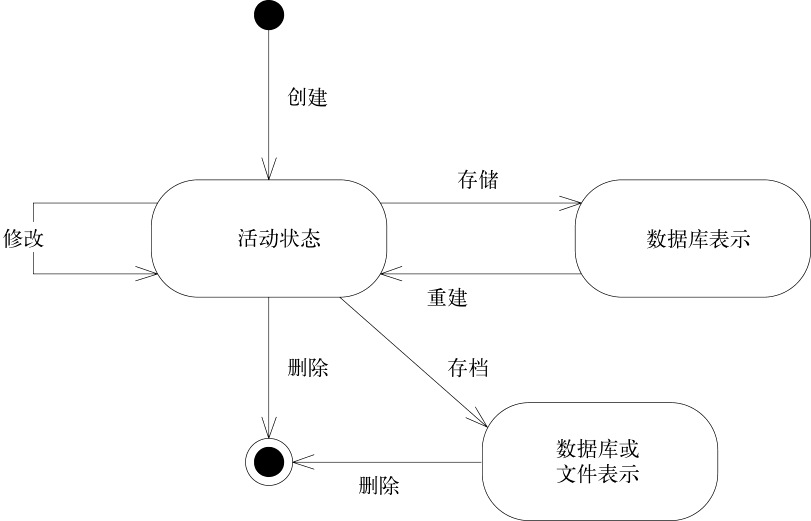
管理领域对象的生命周期主要的挑战有以下两类。
(1) 在整个生命周期中维护完整性。
(2) 防止模型陷入管理生命周期复杂性造成的困境当中。
我们将通过3种模式解决这些问题。分别是AGGREGATE(聚合),FACTORY(工厂),REPOSITORY(存储库)。
3.1 聚合(AGGREGATE)
AGGREGATE就是一组相关对象的集合,是用来封装模型中引用的一个抽象,我们把它作为数据修改的单元。每个AGGREGATE都有一个根(root)和一个边界(boundary)。边界定义了AGGREGATE的内部都有什么。根则是AGGREGATE所包含的一个特定ENTITY。对AGGREGATE而言,外部对象只可以引用根,而边界内部的对象之间则可以互相引用。除根以外的其他ENTITY都有本地标识,但这些标识只在AGGREGATE内部才需要加以区别,因为外部对象除了根ENTITY之外看不到其他对象。
比如说汽车,汽车首先有个唯一标识以便和其他汽车区分开,但同时汽车上又有非常多的零件,比如四个轮胎,每个轮胎也是需要一个内部的唯一标识。
我们应该将 ENTITY和 VALUE OBJECT分 门 别 类地 聚集 到 AGGREGATE中 , 并定 义 每 个AGGREGATE的边界。在每个AGGREGATE中,选择一个ENTITY作为根,并通过根来控制对边界内其他对象的所有访问。只允许外部对象保持对根的引用。对内部成员的临时引用可以被传递出去,但仅在一次操作中有效。由于根控制访问,因此不能绕过它来修改内部对象。这种设计有利于确保AGGREGATE中的对象满足所有固定规则,也可以确保在任何状态变化时AGGREGATE作为一个整体满足固定规则。
AGGREGATE通过定义清晰的所属关系和边界,并避免混乱、错综复杂的对象关系网来实现模型的内聚。聚合模式对于维护生命周期各个阶段的完整性具有至关重要的作用。
3.2 工厂(FACTORY)
FACTORY 就是专门承担某一个对象或者整个AGGREGATE 复杂的创建过程,避免导致客户与被创建对象的实现之间产生过于紧密的耦合。
任何好的工厂都需满足以下两个基本需求。
(1) 每个创建方法都是原子的,而且要保证被创建对象或AGGREGATE的所有固定规则。
(2) FACTORY应该被抽象为所需的类型,而不是所要创建的具体类。
FACTORY封装了对象创建和重建时的生命周期转换。但并非所有场景都需要使用Factory,如果创建过程比较简单最好是使用简单的、公共的构造函数。
3.3 存储库(REPOSITORY)
REPOSITORY就是封装所有对象的存储和访问操作,让客户始终聚焦于模型,而不用关心底层数据存储,避免破坏领域对象的封装和AGGREGATE。
FACTORY和REPOSITORY区别
FACTORY和REPOSITORY具有完全不同的职责。FACTORY负责制造新对象,而REPOSITORY负责查找已有对象。FACTORY负责处理对象生命周期的开始,而REPOSITORY帮助管理生命周期的中间和结束。我们使用FACTORY来创建和重建复杂对象和AGGREGATE,从而封装它们的内部结构。最后,在生命周期的中间和末尾使用REPOSITORY来提供查找和检索持久化对象并封装庞大基础设施的手段。
这些结构提供了易于掌握的模型对象处理方式,使MODEL-DRIVEN DESIGN更完备。使用AGGREGATE进行建模,并且在设计中结合使用FACTORY和REPOSITORY,这样我们就能够在模型对象的整个生命周期中,以有意义的单元、系统地操纵它们。AGGREGATE可以划分出一个范围,这个范围内的模型元素在生命周期各个阶段都应该维护其固定规则。FACTORY和REPOSITORY在AGGREGATE基础上进行操作,将特定生命周期转换的复杂性封装起来。
最后贴一下总的关联关系:
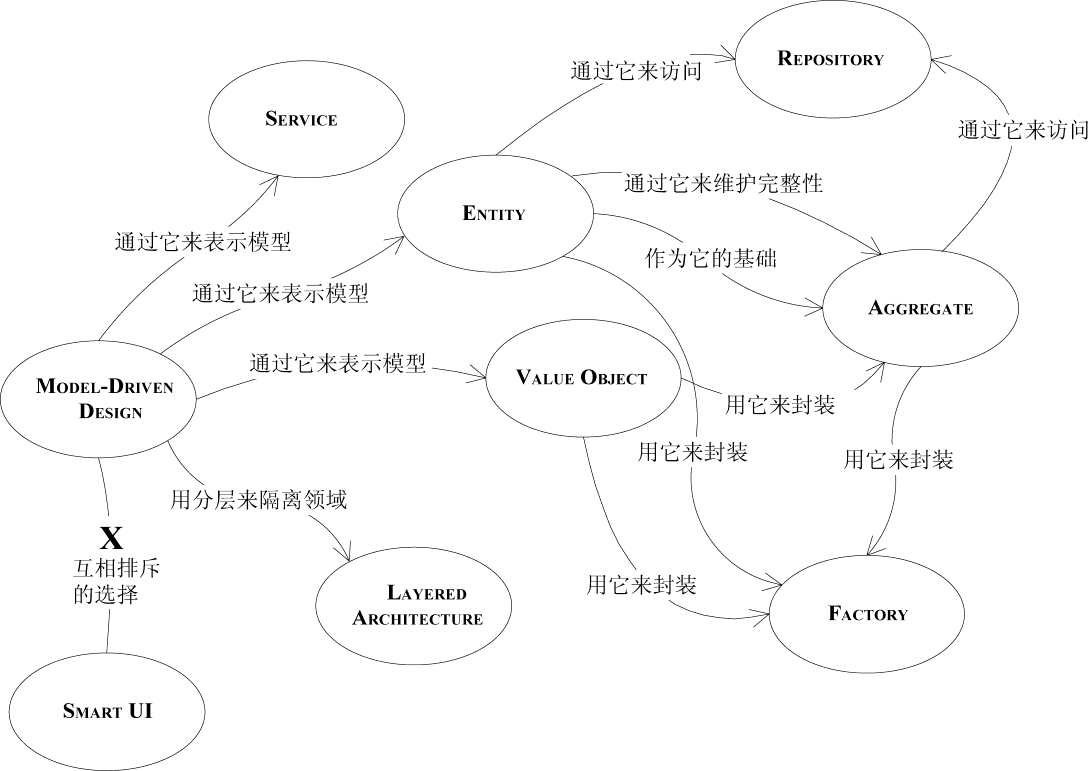




)




)









