MySQL日志
包括事务日志(redolog undolog)慢查询日志,通用查询日志,二进制日志(binlog)
最为重要的就是binlog(归档日志)事务日志redolog(重做日志)undolog回滚日志
聊聊REDOLOG
为什么需要redolog?
那redolog主要是为了保证数据的持久化,我们知道innodb存储引擎中数据是以页为单位进行存储,每一个页中有很多行记录来存储数据,我们的数据最终是要持久化到硬盘中,那如果我们每进行一次数据的更新都进行一次磁盘的IO来更新数据页,那这样频繁的磁盘IO说我们承受不起的,所以我们引入了buffer poll,当我们查询一条记录时会把一整页的数据加载出来放到buffer poll中,后续的查找只需要查找buffer poll中有没有数据,有则更新buffer poll中的数据再进行刷盘操作完成数据持久化,与内存进行IO的效率明显远高于磁盘IO,虽然效率是提高了但我们也发现如果我们的MySQL实例挂了或者宕机,内存中数据丢失,我们更新buffer poll中的数据尚未刷盘到磁盘就会造成数据的丢失。所以们需要redolog日志来保证事务的持久性
redolog是如何保证事务持久性的?
我们先来看一下一个更新操作的流程图
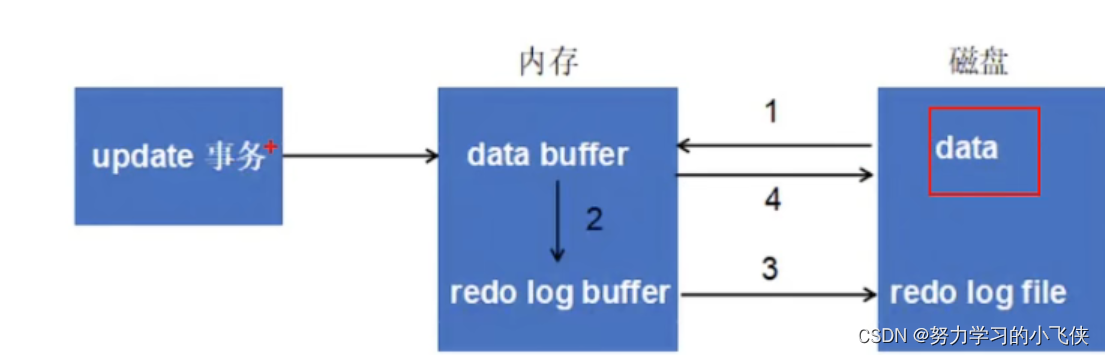
第一步,先将需要更新的记录从磁盘中读入到内存中,修改数据的内存拷贝
第二步,生成一条重做日志记录到redo log buffer中,记录的是数据修改后的值
第三步,事务提交后,通过一定的刷盘时机将redo log buffer中的内容刷新到redo log file中
第四步,将内存中的数据刷新到磁盘
redo log的组成(redo log buffer和redo log file )
redo log buffer是由一块块redo log block组成,我们将一组组日志记录写入redo log block中,只有redo log block满了才会把redo log block写入到page cache中,再通过调用fsync刷盘到redo log file,我们的redo log写入block是从第一个顺序写入的,一个redo log block写满后再写入写一个,要是redo log buffer中所有的redo log block都满了就会强制把redo log block刷入到磁盘,本质上也就是把512字节的redo log block追加进redo log file中
redo log buffer的刷盘时机
innodb中通过innodb_flush_log_at_trx_commit控制
为0时:延迟写。提交事务时不会将redo log写入os buffer,而是每隔1秒将redo log写入os buffer并调用fsync()刷入磁盘。系统崩溃会丢失一秒钟的数据。
为1时:实时写,实时刷。每次提交事务都将redo log写入os buffer并调用fsync()刷入磁盘。这种方式系统奔溃不会丢失数据,因每次提交事务都写入磁盘,性能比较差
为2时:实时写,延时刷。每次提交事务都将redo log写入os buffer,但并不会马上调用fsync()刷如磁盘,而是间隔1秒调fsync()刷盘。相对于每次提交都写盘和每隔1秒写盘,实时写os buffer延时刷盘是一个数据一致性与性能的之间的这种方案。
redo log file
磁盘上的redo log日志不止一个而是以日志文件组的形式出现,这些文件以ib_logfile[数字](数字可以是0、1、2…)的形式进行命名,每个的Redo日志文件大小都是一样的。
我们可以想到写入redo log写入日志文件组的时候从ib_logfile0开始写,写满后写ib_logfile1…如果写到最后一个还写满了怎么办呢?我们接着ib_logfile0写,这些ib_logfile以环形数组形式构成,从头开始写,写到末尾回到头循环写,如下图所示:
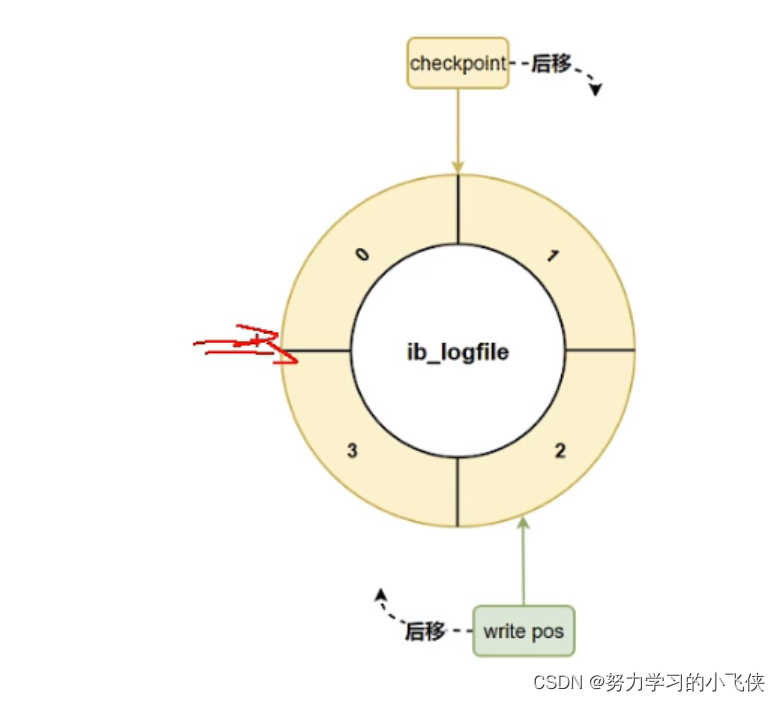
可以看到其中有两个重要的属性:
write pos:记录当前位置,一边写一边后移
checkpoint:记录当前要擦除的位置也往后移
流程:每次redo log刷盘到日志文件组时write pos后移,每次MySQL加载日志文件组恢复数据时,清空恢复的redo log并把checkpoint后移,write pos和checkpoint之间空着的部分用来记录新的redo kig,如果write pos追上了checkpoint表示日志文件组满了,这时候不能再写入新的redo log记录,MySQL得停下来,清空一些记录,把checkpoint推荐一下。
至此我们就清楚了重做日志的执行流程
聊聊BINLOG
binlog记录什么?
MySQL server中所有的搜索引擎发生了更新(DDL和DML)都会产生binlog日志,记录的是语句的原始逻辑
为什么需要binlog?
binlog主要有两个应用场景,一是数据复制,在MySQL主从复制的场景下我们通过master来写binlog,slaver
读取master的binlog来完成数据一致性。二是数据恢复,通过mysqlbinlog工具来恢复数据,通过确定start-position和end-position来执行
binlog的记录格式
statement
设置为statement记录的是语句SQL语句原文,同步数据时会执行记录的SQL语句,但是有一些语句直接执行会和原语句不同,比如(UUID,update_time = now()等)所以这种简单的记录形式无法保证数据的一致性,我们有row格式
row
row格式记录的是修改的具体数据,这样保证了数据库恢复和复制的数据的可靠性,但是这种格式需要占用大量的容量来记录,并且恢复和同步更消耗IO资源。所以又有了一种折中方案,设置为mixed,记录的内容是前两者的混合。
mixed
MySQL会判断这条SQL语句是否会引起数据不一致,如果是就用row格式,否则就用statement`格式。
binlog的写入机制
一个事务的binlog不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一块内存作为binlog cache。可以通过binlog_cache_size参数控制单线程binlog_cache大小,如果存储内容超过了这个参数,就要暂存到磁盘。
binlog的写入时机是事务执行中,在执行事务中第一个dml语句时会分配空间binlog cache,将日志写到binlog cache,事务提交的时候再把binlog cache写到binlog文件中同时释放binlog cache
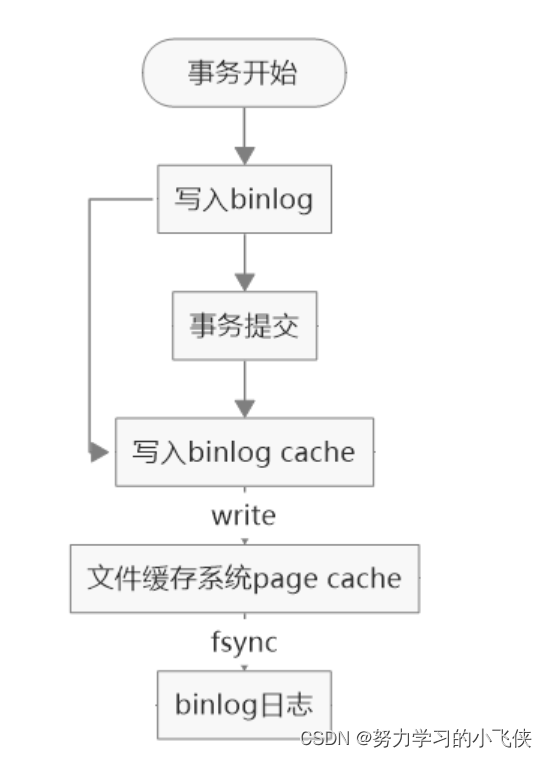
write是指将日志写入到系统的page cache
fsync是将日志刷新到binlog日志文件中完成持久化
write和fsync的时机可以由参数sync_binlog控制,可以配置成0、1、N(N>1)。
- 设置成0时:表示每次提交事务都只会
write,由系统自行判断什么时候执行fsync。 - 设置成1时:表示每次提交事务都会执行
fsync,就和redo log日志刷盘流程一样。 - 设置成N时:表示每次提交事务都会
write,但是积累N个事务后才fsync。
什么是两阶段提交?
在执行更新语句时,会记录到redo log和binlog两块日志,以基本事务为单位,redo log在事务的执行过程中能够不断写入,binlog只能在事务提交的时候写入
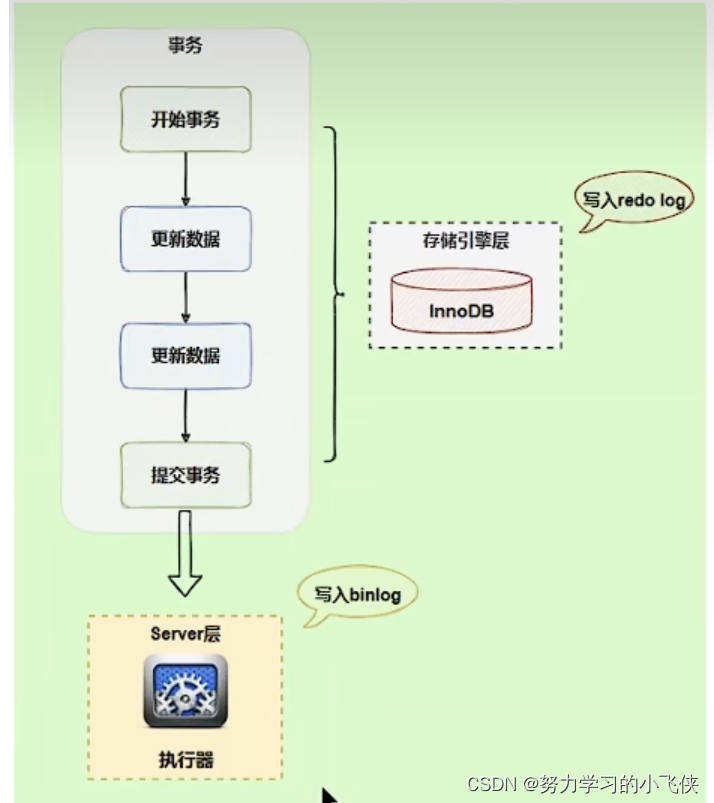
为了解决两份日志之间逻辑一致问题,innodb存储引擎采用了两阶段提交方案,将redo log写入拆成了prepare和commit两个阶段,这就是两阶段提交
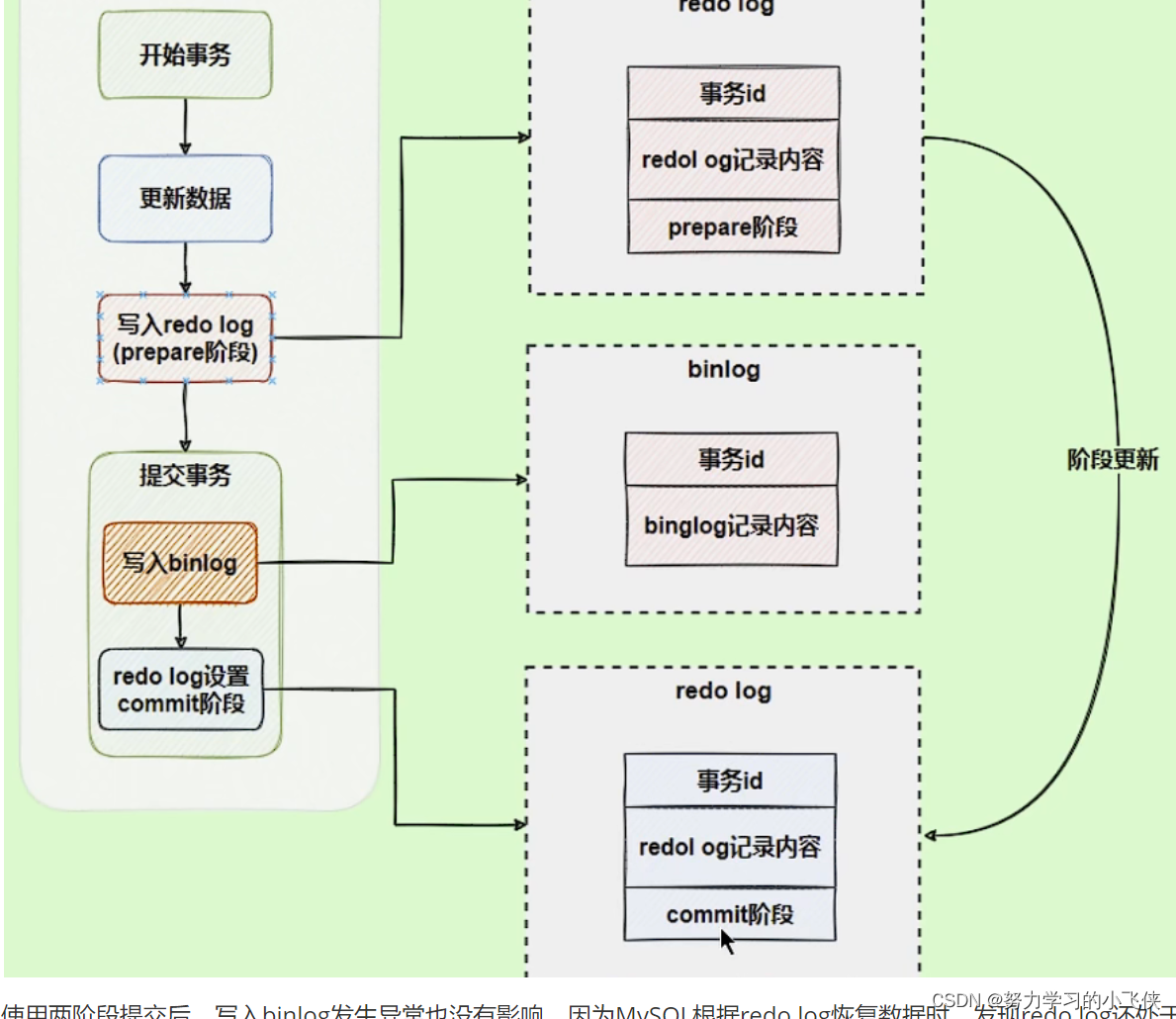
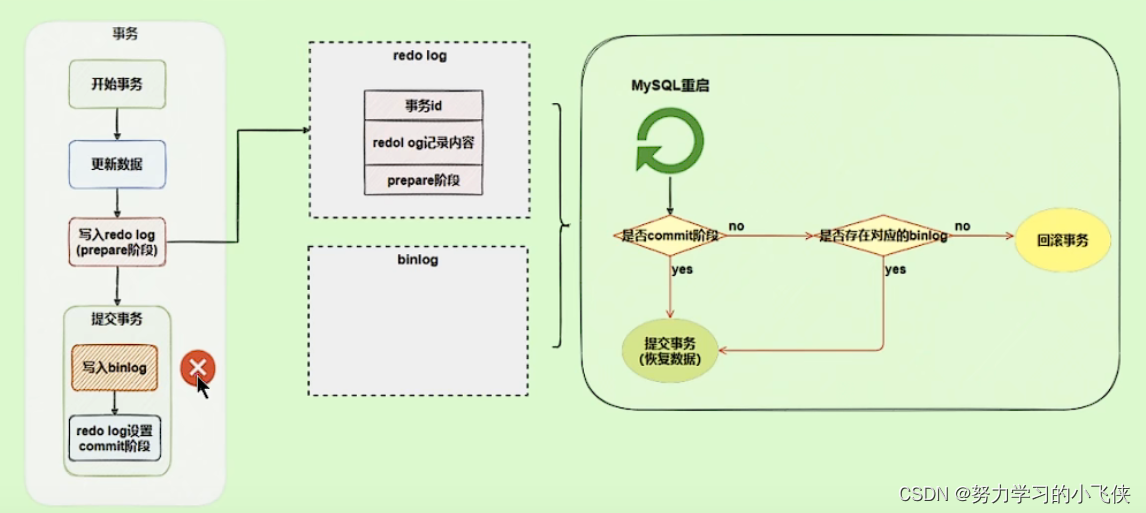
使用两阶段提交后,写入binlog发生异常也没有影响,因为MySQL根据redo log恢复数据时,发现redo log还处于prepare阶段,没有对应的binlog日志,则回滚事务
binlog和redo log的区别
binlog是逻辑日志,记录的是原始语句,属于MySQL server层,所有存储引擎有更新操作都会记录;redo log是物理日志,记录的是在某个数据页上做的修改,属于innodb存储引擎层
虽然它们都是持久化的保证但侧重点有所不同:
redo log使innodb有了崩溃后恢复的能力
binlog保证了集群架构下数据一致性
聊聊undo log
什么是undo log
undo log(回滚事务),在事务没有提交前,MySQL将记录更新操作的反向操作到undo log日志中,以便进行回退保证事务的原子性
undo log的作用
1.提供回滚操作
我们在进行数据更新操作的时候,不仅会记录redo log,还会记录undo log,如果因为某些原因导致事务回滚,那么这个时候MySQL就要执行回滚(rollback)操作,利用undo log将数据恢复到事务开始之前的状态。
2、提供多版本控制(MVCC)
在InnoDB中MVCC的实现是通过undo log来完成。当用户读取一行记录时,若该记录已经被其他事务占用,当前事务可以通过undo log读取之前的行版本信息,以此实现非锁定读取。
undo的存储结构
1.回滚段和undo页
innodb对undo log采用段的方式进行管理,每个回滚段记录1024个undo log segment,在每个undo log segment进行undo页的申请
2.回滚段和事务
1.每一个事务只能有一个回滚段,一个回滚段可以同时服务于多个事务
2.当事务提交时,innodb会做两件事:
- 将
undo log放入列表中,以供之后的purge操作; - 判断
undo log所在的页是否可以重用,若可以分配给下个事务使用。
回滚段中的数据分类
1、未提交的回滚数据:该回滚数据关联的事务尚未提交,要用于实现MVCC,所以不能被删除和覆盖;
2、已提交但未过期的回滚数据:该回滚数据关联的事务已提交,但仍然受到undo retention参数的影响继续保留;
3、事务已提交并过期的数据:该回滚数据属于过期数据,当回滚段满之后,会被优先覆盖掉。
undo log的类型
在InnoDB中,undo log分为两种:
insert undo log:是指在insert操作中产生的undo log。因为insert操作的记录,只对当前事务本身可见,对其他事务不可见(这是事务隔离性的要求),因此这种undo log可以在事务提交后直接删除。不需要进行purge操作。undate undo log:是对delete和update操作产生的undo log。该undo log可能需要提供MVCC机制使用,因此不能在事务提交时就进行删除,提交时放入undo log链表,等待purge线程进行最后的删除。
详细生成过程
对于InnoDB来说,每条记录不仅包括了自身的数据,还包含了几个隐藏列:
DB_ROW_ID:InnoDB为没有主键和唯一索引的表自动添加的隐藏主键;DB_TRX_ID:更改当前记录的事务id;DB_ROLL_PTR:回滚指针,指向undo log的指针。

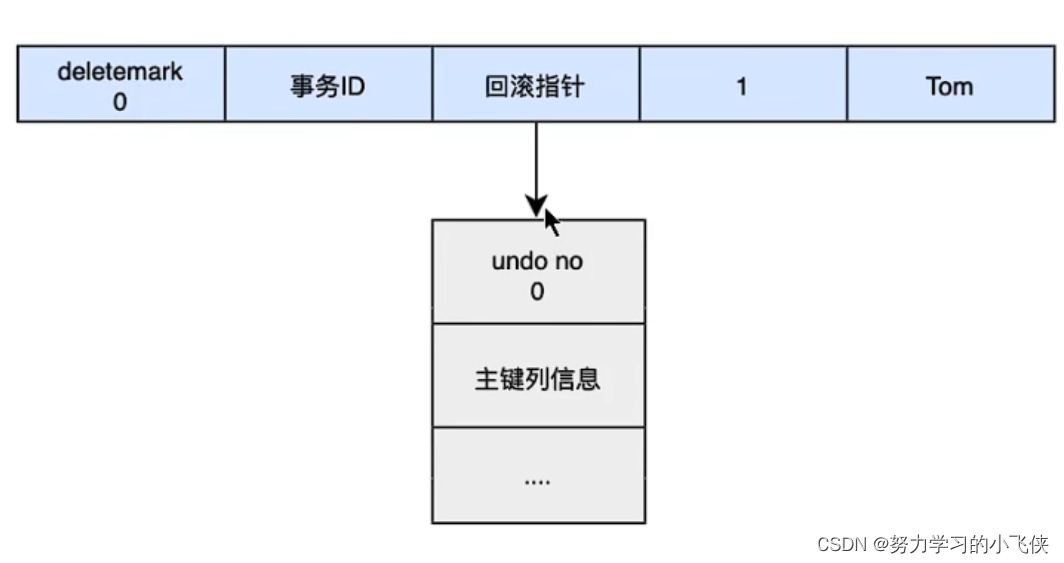
新增操作的undo log
start transaction;
insert into user(name) values('Tom');
commit;
此时行记录deletemark标记为0,表示该记录并未删除,回滚指针指向了回滚编号为0的回滚日志,回滚日志记录了主键信息,说明若要回滚操作可以通过执行delete这个主键实现。
不更新主键的undo log
start transaction;
update user set name = 'Sun' where id = 1;
commit;
此时执行了更新操作,并且更新的字段不是主键。此时记录的回滚指针指向了新生成的回滚编号为1的undo log,编号为0的undo log连接在编号为1的后面,当年记录回滚时也是先通过编号1的undo log恢复到name为'Tom',再通过编号0的undo log删除记录。
更新主键的undo log
start transaction;
update user set id = 2 where id = 1;
commit;
对于更新主键的操作,会先把原来的数据deletemark标识标记为1,这时并没有真正的删除数据,真正的删除会交给purge清理线程去判断,然后在后面插入一条新的记录,新的记录也会产生undo log,并且undo log的序号会递增。
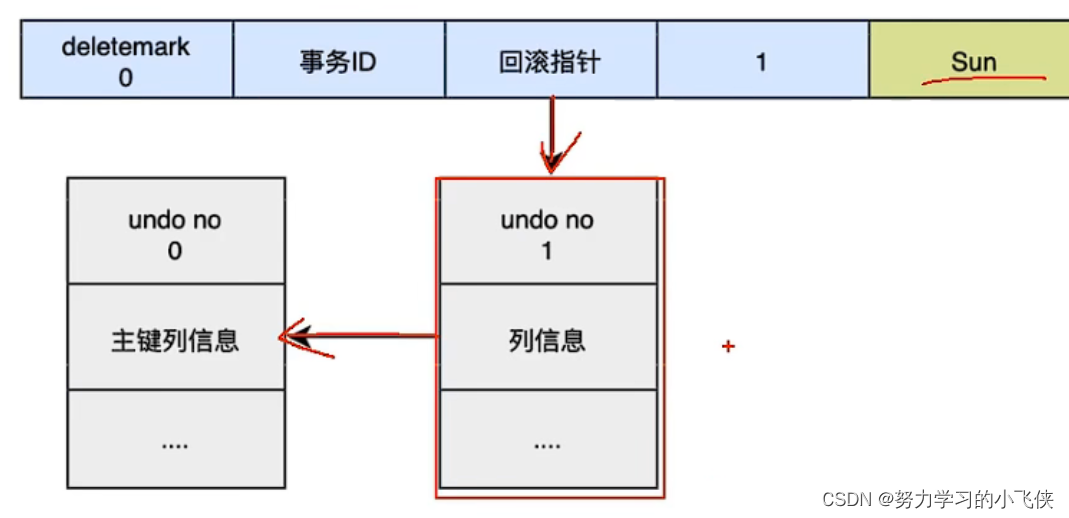
此时的事务如何回滚?
- 通过
undo no=3的日志把id=2的数据删除; - 通过
undo no=2的日志把id=1的数据的deletemark还原成0; - 通过undo no=1的日志把
id=1的数据的name还原成Tom; - 通过
undo no=0的日志把id=1的数据删除。
删除操作的undo log
记录的删除操作分为两个阶段:
- 将记录的
deletemark标示位设置为1,其他的不做修改(实际会修改记录的trx_id,roll_pointer等隐藏列的信息)。 - 当该删除语句所在的事务提交之后,
undo purge线程来真正的把记录删除掉。就是把记录从正常记录链表移除,加入到垃圾连表中。
删除操的undo log只需要考虑对删除操作在阶段1所做的影响进行回滚,需要把该记录的trx_id和roll_pointer的隐藏列旧值都记到对应的undo log中的trx_id和roll_pointer属性中。可以通过删除操作的undo log的roll_pointer的属性找到上一次对该记录改动产生的undo log,以此来实现回滚。
purage线程的作用
清理undo页和清除page里带有Delete_Bit标识的记录。在InnoDB中,事务中的delete操作并不会立刻将数据删除,而是先进行Delete Mark标记,给记录标识上Delete_bit,真正的清除工作是由purge线程在后台完成的
属性中。可以通过删除操作的undo log的roll_pointer的属性找到上一次对该记录改动产生的undo log`,以此来实现回滚。
purage线程的作用
清理undo页和清除page里带有Delete_Bit标识的记录。在InnoDB中,事务中的delete操作并不会立刻将数据删除,而是先进行Delete Mark标记,给记录标识上Delete_bit,真正的清除工作是由purge线程在后台完成的
)
。Javaee项目,ssm vue前后端分离项目。)






)



一站打包- day01)


)
)


