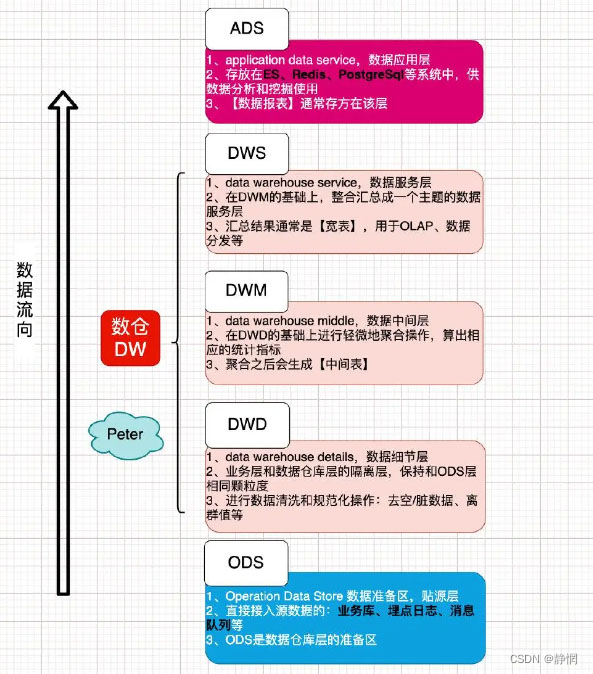
1、ods是什么?
ods层最好理解,基本上就是数据从源表拉过来,进行etl,比如MySQL映射到Hive,那么到了Hive里面就是ods层。ods全称是Operational Data Store,操作数据存储——“面向主题的”,数据运营层,也叫ods层,是最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的ETL之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分类方式而分类的。但是,这一层面的数据却不等同于原始数据。在源数据装入这一层时,要进行诸如去噪(例如有一条数据中人的年龄是 300 岁,这种属于异常数据,就需要提前做一些处理)、去重(例如在个人资料表中,同一ID却有两条重复数据,在接入的时候需要做一步去重)、字段命名规范等一系列操作。
2、数据仓库层dw
数据仓库层(dw),是数据仓库的主体.在这里,从 ods层中获得的数据按照主题建立各种数据模型。这一层和维度建模会有比较深的联系。
- 数据明细层:
DWD(Data Warehouse Detail); - 数据中间层:
DWM(Data WareHouse Middle); - 数据服务层:
DWS(Data WareHouse Service)。
2.1、dwd明细层
明细层 (ods:Operational Data Store,dwd:data warehouse detail)
- 概念: 是数据仓库的细节数据层,是对
STAGE层数据进行沉淀,减少了抽取的复杂性,同时ods/dwd的信息模型组织主要遵循企业业务事务处理的形式,将各个专业数据进行集中,明细层跟stage层的粒度一致,属于分析的公共资源 - 数据生成方式: 部分数据直接来自
kafka,部分数据为接口层数据与历史数据合成。 - 这个
stage层不是很清晰
2.2、dwm 轻度汇总层( MID 或 dwb , data warehouse basis)
- 概念: 轻度汇总层数据仓库中
dwd层和dm层之间的一个过渡层次,是对dwd层的生产数据进行轻度综合和汇总统计(可以把复杂的清洗,处理包含,如根据PV日志生成的会话数据)。轻度综合层与dwd的主要区别在于二者的应用领域不同,dwd的数据来源于生产型系统,并未满意一些不可预见的需求而进行沉淀;轻度综合层则面向分析型应用进行细粒度的统计和沉淀 - 数据生成方式: 由明细层按照一定的业务需求生成轻度汇总表。明细层需要复杂清洗的数据和需要MR处理的数据也经过处理后接入到轻度汇总层。
- 日志存储方式: 内表,
parquet文件格式。 - 日志删除方式: 长久存储。
- 表
schema: 一般按天创建分区,没有时间概念的按具体业务选择分区字段。 - 库与表命名。库名:
dwb,表名:初步考虑格式为:dwb日期业务表名,待定。 - 旧数据更新方式: 直接覆盖。
2.3、dws主题层( dm , data market 或dws, data warehouse service )
- 概念: 又称数据集市或宽表。按照业务划分,如流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,
OLAP分析,数据分发等。 - 数据生成方式: 由轻度汇总层和明细层数据计算生成。
- 日志存储方式: 使用
impala内表,parquet文件格式。 - 日志删除方式: 长久存储。
- 表
schema: 一般按天创建分区,没有时间概念的按具体业务选择分区字段。 - 库与表命名。库名:
dm,表名:初步考虑格式为:dm日期业务表名,待定。 - 旧数据更新方式: 直接覆盖。
3、ads层
数据产品层(ads),这一层是提供为数据产品使用的结果数据。
主要是提供给数据产品和数据分析使用的数据,一般会存放在
ES、MySQL等系统中供线上系统使用,也可能会存在Hive或者Druid中供数据分析和数据挖掘使用。如我们经常说的报表数据,或者说那种大宽表,一般就放在这里。
应用层
- 概念: 应用层是根据业务需要,由前面三层数据统计而出的结果,可以直接提供查询展现,或导入至
MySQL中使用。 - 数据生成方式: 由明细层、轻度汇总层,数据集市层生成,一般要求数据主要来源于集市层。
- 日志存储方式: 使用
impala内表,parquet文件格式。 - 日志删除方式: 长久存储。
- 表
schema: 一般按天创建分区,没有时间概念的按具体业务选择分区字段。 - 库与表命名。库名:暂定
apl,另外根据业务不同,不限定一定要一个库。(其实就叫app_)就好了 - 旧数据更新方式: 直接覆盖。
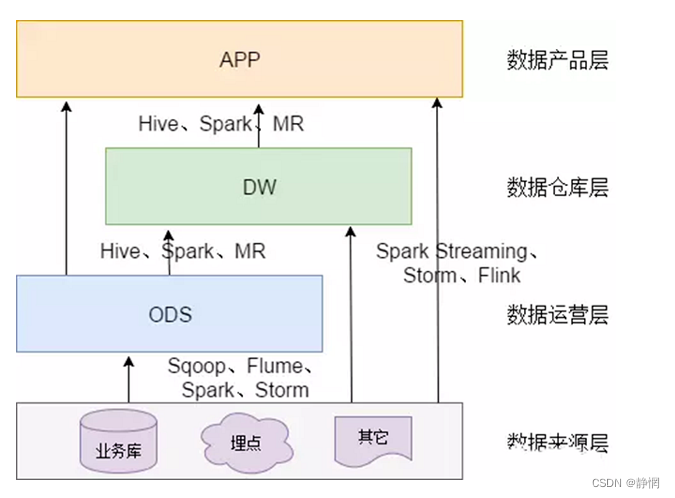
4、数据来源
数据主要会有两个大的来源:
业务库,这里经常会使用 Sqoop 来抽取
我们业务库用的是databus来进行接收,处理kafka就好了。
在实时方面,可以考虑用Canal 监听 MySQL 的 Binlog,实时接入即可。(有机会补一下这个canal)
埋点日志,线上系统会打入各种日志,这些日志一般以文件的形式保存,我们可以选择用 Flume 定时抽取,也可以用用 Spark Streaming 或者 Storm来实时接入,当然,Kafka也会是一个关键的角色。
还有使用filebeat收集日志,打到kafka,然后处理日志
在这层,理应不是简单的数据接入,而是要考虑一定的数据清洗,比如异常字段的处理、字段命名规范化、时间字段的统一等,一般这些很容易会被忽略,但是却至关重要。特别是后期我们做各种特征自动生成的时候,会十分有用。
5、ods、dw、 dim ⇒ App 层
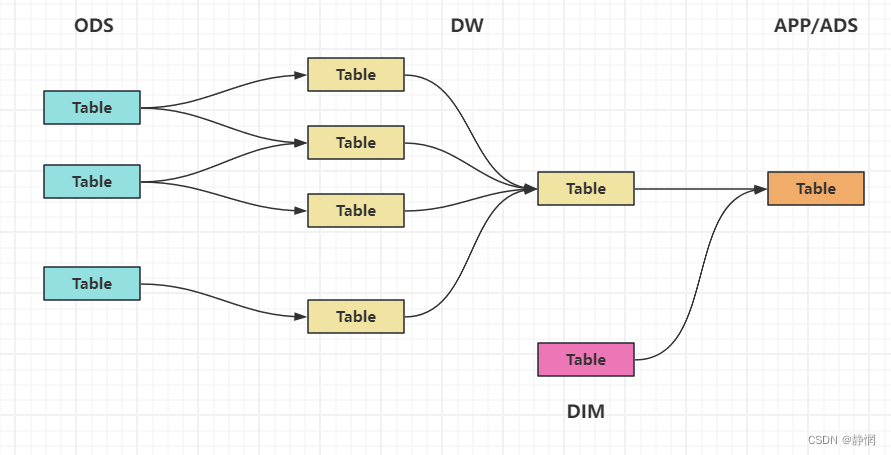
- 每日定时任务型: 比如我们典型的日计算任务,每天凌晨算前一天的数据,早上起来看报表。 这种任务经常使用
Hive、Spark或者生撸MR程序来计算,最终结果写入Hive、Hbase、MySQL、Es或者Redis中。 - 实时数据: 这部分主要是各种实时的系统使用,比如我们的实时推荐、实时用户画像,一般我们会用
Spark Streaming、Storm或者Flink来计算,最后会落入Es、Hbase或者Redis中。
6、维表层dim
维表层主要包含两部分数据:
- 高基数维度数据:一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
- 低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维表。 数据量可能是个位数或者几千几万。
7、层级的简单分层图
见下图,对dwd层在进行加工的话,就是DWM层(MID层)(我们的数仓还是有很多dwm层的)。
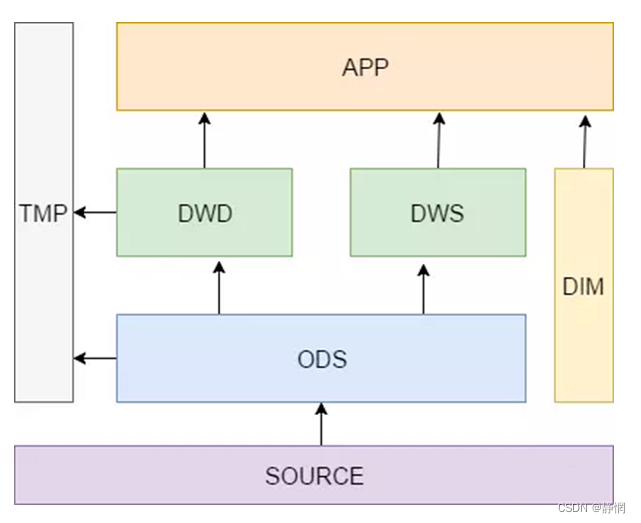
dws、dwd、dim和tmp的作用
dws: 轻度汇总层,从ods层中对用户的行为做一个初步的汇总,抽象出来一些通用的维度:时间、ip、id,并根据这些维度做一些统计值,比如用户每个时间段在不同登录ip购买的商品数等。这里做一层轻度的汇总会让计算更加的高效,在此基础上如果计算仅7天、30天、90天的行为的话会快很多。我们希望80%的业务都能通过我们的dws层计算,而不是ods。dwd: 这一层主要解决一些数据质量问题和数据的完整度问题。比如用户的资料信息来自于很多不同表,而且经常出现延迟丢数据等问题,为了方便各个使用方更好的使用数据,我们可以在这一层做一个屏蔽。(汇总多个表)dim: 这一层比较单纯,举个例子就明白,比如国家代码和国家名、地理位置、中文名、国旗图片等信息就存在dim层中。tmp: 每一层的计算都会有很多临时表,专设一个DWTMP层来存储我们数据仓库的临时表。
8、主题
主题(Subject)是在较高层次上将企业信息系统中的数据进行综合、归类和分析利用的一个抽象概念,每一个主题基本对应一个宏观的分析领域。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象。例如“销售分析”就是一个分析领域,因此这个数据仓库应用的主题就是“销售分析”。
9、dws和dwd的关系
9.1、dws 和dwd 是并行而不是先后顺序?
答:dws和dwd是并行的,都是数据dw层。
9.2、那其实对于同一个数据,这两个过程是串行的
答:dws 会做汇总,dwd 和 ods 的粒度相同,但是这两层之间也没有依赖的关系。
9.3、 dws 里面的汇总没有经过数据质量和完整度的处理,或者单独做了这种质量相关的处理,为什么不在 dwd 之上再做汇总呢?我的疑问其实就是,dws的轻度汇总数据结果,有没有做数据质量的处理?
答:ods 直接到 dws 就好,没必要过dwd,我举个例子,你的浏览商品行为,我做一层轻度汇总,就直接放在 dws了。但是你的资料表,要从好多表凑成一份,我们从四五份个人资料表中凑出来了一份完整的资料表放在了 dwd 中。然后在 app 层,我们要出一张画像表,包含用户资料和用户近一年的行为,我们就直接从dwd中拿资料, 然后再在 dws 的基础上做一层统计,就成一个app表了。当然,这不是绝对,dws 和 dwd 有没有依赖关系主要看有没有这种需求。
10、ods 与 dwd 区别,有了 ods 层后感觉 dwd 没有什么用了?
答: 嗯,我是这样理解的,站在一个理想的角度来讲,如果 ods 层的数据就非常规整,基本能满足我们绝大部分的需求,这当然是好的,这时候 dwd 层其实也没太大必要。 但是现实中接触的情况是 ods 层的数据很难保证质量,毕竟数据的来源多种多样,推送方也会有自己的推送逻辑,在这种情况下,我们就需要通过额外的一层 dwd来屏蔽一些底层的差异。
dwd主要是对ods层做一些数据清洗和规范化的操作,dws主要是对ods层数据做一些轻度的汇总。
11、app/ads层的作用
11.1、感觉数据集市层是不是没地方放了,各个业务的数据集市表是应该在dwd 还是在 app
答: 主要就是明确一下数据集市层是干什么的,如果数据集市层放的就是一些可以供业务方使用的宽表表,放在 app 层就行。如果数据集市层是一个比较泛一点的概念,那么其实 dws、dwd、app 这些合起来都算是数据集市的内容。
11.2、存到 Redis、ES 中的数据算是 app层吗?
答: 是的,因为app 层主要存放一些相对成熟的表,能供业务侧使用的。这些表可以在 Hive 中,也可以是从 Hive 导入 Redis 或者 ES 这种查询性能比较好的系统中。
12、图解分层


command)






》第2章-计算机系统基础知识-01-计算机硬件)





)
)

)

