npm域级包
随着npm包越来越多,而且包名也只能是唯一的,如果一个名字被别人占了,那你就不能再使用这个名字;假设我想要开发一个utils包,但是张三已经发布了一个utils包,那我的包名就不能叫utils了;此时我们可以加一些连接符或者其他的字符进行区分,但是这样就会让包名不具备可读性。
在npm的包管理系统中,有一种scoped packages机制,用于将一些npm包以@scope/package的命名形式集中在一个命名空间下面,实现域级的包管理。
域级包不仅不用担心会和别人的包名重复,同时也能对功能类似的包进行统一的划分和管理;比如我们用vue脚手架搭建的项目,里面就有@vue/cli-plugin-babel、@vue/cli-plugin-eslint等等域级包。
我们在初始化项目时可以使用命令行来添加scope:
npm init --scope=username //直接修改package.json 的name 为@username/package 也行
相同域级范围内的包会被安装在相同的文件路径下,比如node_modules/@username/,可以包含任意数量的作用域包;安装域级包也需要指明其作用域范围:
npm install @username/package
在代码中引入时同样也需要作用域范围:
require("@username/package")
workspace:
Workspaces是一个通用术语:这些功能支持在一个顶级根包中管理本地文件系统中的多个包(可以自动link本地依赖,无需手动link)。 这组功能弥补了处理来自本地文件系统的链接包的更精简的工作流程。在npm安装过程中自动链接,避免手动使用 npm link 来引用需要符号链接到当前node_modules文件夹中的包。
1.learn + yarn workspace
使用 yarn 来处理依赖问题,使用 lerna 来处理测试和发布问题。lerna 只负责创建 package 以及 package 的版本控制和拓扑构建(–sort build),开发过程中涉及到安装依赖或者删除依赖等都使用 yarn 的命令。
learn.json配置使用 Yarn 并启用 workspaces:
{
"npmClient": "yarn",
"useWorkspaces": "true",
}
在根目录的 package.json 中配置 workspaces,此时 lerna.json 中的 packages 设置会失效,yarn 就会以 monorepo 的方式管理 packages:
{
"name": "root",
"workspaces": [
"packages/*"
],
}
这样就相当于依赖管理全部交由 Yarn 来管理了:
依赖初始化和提升:yarn install
给某个 package 安装依赖,比如给 pkgA 安装依赖:yarn workspace pkgA add xxx。不同于lerna add,Yarn 就是正常的包管理器,可以一次装多个依赖
给某个 package 移除依赖,比如移除 pkgA 包的 xxx 依赖yarn workspace pkgA remove xxx
- yarn workspaces run [add|remove] xxx 给所有 package 中安装或删除依赖,会安装到每个子 package 的 package.json
yarn add -W -D typescript 给 root 安装依赖,会安装到 根目录 package.json -W workspace根目录 -D devDepencies
清理依赖
lerna clean # 清理所有packages的node_modules目录,不能删除根目录的node_modules
yarn workspaces run clean # 执行所有package的clean脚本(需自行写脚本) lerna clean && rm -rf ./node_modules 清除安装的依赖
lerna 在安装依赖时也提供了--hoist选项,相同的依赖,会「提升」到 repo 根目录下安装,但……太鸡肋了,lerna 直接以字符串对比 dependency 的版本号,完全相同才提升,semver 约定在这并不起作用。
yarn 突出的是对依赖的管理,包括 packages 的相互依赖、packages 对第三方的依赖,yarn 会以 semver 约定来分析 dependencies 的版本,安装依赖时更快、占用体积更小(可以semver模糊匹配版本);
通过使用 workspace,yarn install 会自动的帮忙解决安装和 link 问题,yarn install # 等价于 lerna bootstrap --npm-client yarn --use-workspaces
它与 lerna bootstarp 不同的是:
- yarn install 会将 package 下的依赖统一安装到根目录之下。这有利于提升依赖的安装效率和不同 package 间的版本复用(有些包是需要私有依赖的,而私有依赖会被多个包安装多次,而提升依赖可以解决这一问题)。
- yarn install 会自动帮助解决安装(包括根目录下的安装)和 packages link 问题(若link不上可手动执行lerna link生成)
内部packages项目间相互依赖时是通过link软链来实现的(yarn install/learn link):
- package添加依赖:"dependencies": {"@my-breeze/tools": "^0.0.1"} 使用:require("@my-breeze/tools")
yarn workspace会在父项目的node_modules目录中创建packages/tools的软连接。子项目相互依赖时不再生成到子项目的node_modules里,向上从父node_modules中查找此软链依赖。
若yarn install报错:error Workspaces can only be enabled in private projects. package.json增加"private": true
build构建
各个 package 之间存在相互依赖,如 packageB 只有在 packageA 构建完之后才能进行构建,否则就会出错,诸如此类,这实际上要求我们以一种顺序规则进行构建。
lerna 提供了一种方法,可以按照拓扑排序进行顺序执行各 package 下某个 npm script(一般是 build)。
lerna 如何进行这样的拓扑排序呢?在 lerna 中,我们不会明确定义所谓的拓扑排序,我们通过在 package 中引入其他 package 作为依赖来指定拓扑结构。
举例来说,如果 package1 必须在 package2 build 之后才能被 build,那么我们就要将 package1 作为依赖添加到 package2 的 package.json 中。至于选择添加到 dependencies 还是 devDependencies 都可以,取决于具体需求场景,但两者都是可以被 lerna 正确解析的拓扑结构。
最后当拓扑结构都配置好后,我们就通过 lerna 提供的一个 --sort 参数告诉 lerna 要以拓扑顺序的方式执行每一个 package 的某个脚本:
lerna run --sort build
发布
Build后进行npm发布,因为 lerna 会根据 git 动态发布,所以先要确保项目中有 git。更改 package.json 追加 private: true 这一项,这表示当前这个根目录所在的区域是不应该被 npm 发布的。
如果我们使用了类似 @mjz-test/lerna-package-3 这种 scope package 还需要手动给, package 所在目录的 package.json 设置如下信息 "access": "public"。
如果全局的 registry 与我们要发布的 registry 不是一个,那么我们还需要给每一个 package 设置 registry:"registry": "https://registry.npmjs.org/"
git commit -m "second commit"
lerna publish [param]
结果报错, 原因是我们用了 scope package 与 普通 package 不同的是,scope package 需要到 npm 官网创建 scope 命名空间,(实际就是进入npm orgization 来创建一个组织,组织就叫做 mjz-test
如果当前最大版本是修订版本(0.0.x)那么即使只有一个 package 改动也会导致所有的 packages 都升一级版本即
上一次 publish 后版本
@mjz-test/lerna-package-1@0.0.1
@mjz-test/lerna-package-2@0.0.1
@mjz-test/lerna-package-3@0.0.1
更新 lerna-package-2 后版本
@mjz-test/lerna-package-1@0.0.2
@mjz-test/lerna-package-2@0.0.2
@mjz-test/lerna-package-3@0.0.2
如果当前最大版本是小版本或者大版本,那么只有改动的这个 package 会升级
上一次 publish 后版本
@mjz-test/lerna-package-1@0.1.0
@mjz-test/lerna-package-2@0.1.0
@mjz-test/lerna-package-3@0.1.0
更新 lerna-package-2 后版本
@mjz-test/lerna-package-1@0.1.0
@mjz-test/lerna-package-2@0.1.1
@mjz-test/lerna-package-3@0.1.0
另外,不需要担心被内部引用 package 的版本如何处理,实际上 lerna publish 会在执行时会将依赖更新过的 package 的 包中的依赖版本号更新
fixed集中版本号与independent独立版本号
集中版本号(fixed)是默认的模式,其表现是 所有 package 的版本变更都是依据当前 lerna.json 中的 version 来改动的,即:依照上边的例子,第三次在对 lerna-package-1 进行改动,publish 后 lerna-package-1 的版本号会直接从 v0.1.0 升到 v0.1.2 ,这种版本号升级方式有点不利于语义化
独立版本号(independent)可以解决语义化的问题,即每次升级都会逐个询问需要升级的版本号,其基准为自身的 package.json, 配置独立版本号只需更改 lerna.json 的 version: independent 即可
安装learn到项目中
为了项目可以多人协同,lerna 安在全局会比较麻烦,所以首先会将 lerna 安装到workspace的根目录,并将常用的工作流命令存在 scripts 中
yarn add -D -W lerna
"scripts": {# /package.json 中增加如下 脚本
"lerna:create": "lerna create",
"lerna:build": "lerna run --stream --sort build",
"lerna:publish": "lerna publish",
"lerna": "lerna",
"clean": "lerna clean && rm -rf ./node_modules"
},
# clone 下代码后执行安装依赖
yarn install # 等价于 lerna bootstrap --npm-client yarn --use-workspaces
# 开发完成后执行编译
yarn lerna:build
# commit 更改
git commit -am "xxx commit"
# 提交到代码库与 npm
yarn lerna:publish
# 关于提交到版本库的版本,我们假设当前版本为 0.3.3
yarn lerna:publish major # 0.3.3 => 1.0.0
yarn lerna:publish minor # 0.3.3 => 0.4.0
yarn lerna:publish patch # 0.3.3 => 0.3.4
yarn lerna:publish premajor # 0.3.3 => 1.0.0-alpha.0
yarn lerna:publish preminor # 0.3.3 => 0.4.0-alpha.0
yarn lerna:publish prepatch # 0.3.3 => 0.3.4-alpha.0
yarn lerna:publish 1.2.3 # 0.3.3 => 1.2.3 # 也可以是具体的版本号
yarn lerna:publish # 如果什么都不传,则在没有开启 conventionalCommits 的时候弹出命令行提示选择要升级的版本,如果开启了 conventionalCommits 则会根据 commit 信息的 type 做简单的判断输出一个合适的版本
2.learn + npm workspace
amis使用的是learn + npm workspace
NPM 在 7.x 及以上版本中也支持了 Workspace 特性,能力与 Yarn Workspace 基本类似,只是语法不同,同样先更改 lerna.json 开启 workspaces:
{
"useWorkspaces": "true", //默认就是npm
}
根目录的 package.json 中配置 workspaces:
{
"name": "root",
"workspaces": [
"packages/*"
],
}
同样learn 只负责创建 package 以及 package 的版本控制和拓扑构建(--sort build),开发过程中涉及到 安装依赖或者删除依赖等都使用 npm 的命令
依赖初始化和提升:npm install
安装依赖,比如给 pkgA 安装依赖:npm install xxx -w pkgA
移除依赖,比如移除 pkgA 包的 xxx 依赖:npm uninstall xxx -w pkgA
3.pnpm + changesets(发布版本控制)
pnpm 推荐了两个开源的版本控制工具:changesets、rush
为什么要使用pnpm,而不是最常见的 lerna + yarn workspace 呢?
pnpm 比 npm 和 yarn 更快。pnpm 支持像 nvm 这样的 Node 版本管理功能。
相比其他主流包管理器,pnpm 更轻量、更小。有时候我们并不需要那么多功能。
lerna + yarn 的配置有时过于复杂。就 monorepo 实践而言,pnpm 天生具备这种能力(多包管理),而 lerna + yarn 只是借用了一些能力实现了类似功能。
首先要先裝 pnpm
npm install -g pnpm
初始化项目
pnpm init
monorepo 类型的项目,pnpm 提供了 workspace 来支持,而且比yarn workspace配置更简单,只需在项目根目录下创建一个 pnpm-workspace.yaml 文件:
packages:
- 'packages/**' # 所有在 packages 子目录下的 package
- '!**/test/**' # 不包括在 test 文件夹下的 package
依赖管理全部交由 pnpm 来管理了:
pnpm add <package_name> --filter <workspace_name> // 安装某个特定属性 在root项目目录下:pnpm install -D @sicons/fluent --filter @ecdesigner/xstate
pnpm i // 全局安装
pnpm i <package_name> --filter <workspace_name> // 安装某个特定属性
删除全局和每个workspace的node_modules
pnpm clean
pnpm -r exec rm -rf node_modules
pnpm rimraf **/node_modules
在 monorepo 项目中,每个模块或包通常会有一些公用的依赖项。如果你使用的是 React 技术栈,每个项目都要安装 React 是否会显得繁琐且占用时间和空间?
在使用 yarn + lerna 时,一种方案是配置自动提升(hoisting),如前面所提到的。这种方案存在依赖滥用的问题,因为一旦提升到顶层,没有任何限制,一个依赖可能被加载到任何顶层 node_modules 中存在的依赖,而不受它是否真正依赖该包以及该包的版本的影响。但在 pnpm 中,无论是否被提升,存在默认隔离的策略,所有这一切都是安全的。
所以建议移除每个子项目的共同依赖,例如 React、lodash 等,并统一将它们放入顶层的 package.json 内
pnpm add -w lodash // -w(--workspace) 添加到workspace的根目录的依赖,它将在所有工作区子包中共享
pnpm add -D -w typescript
启动项目命令集成
当有多个项目在packages的时候,可能需要在每个项目中寻找项目启动的命令,所以可以集成在根目录下面的package.json里面
"scripts": {
"dev:app1": "pnpm start --filter \"@mono/app1\"",
"dev:app2": "pnpm start --filter \"@mono/app2\""
},
packages中的项目内部互相使用(pnpm install安装依赖,workspace:* 指明这是工作区的依赖,防止自动去 npm 上寻找导致混乱):
"dependencies": { "@mono/app2": "workspace:*" }
限制只允许使用pnpm安装(只需在 package.json 中加入一行代码来限制):
"scripts": { "preinstall": "npx only-allow pnpm" } //preinstall 是包安装工具的 钩子函数,在上例中作为 install 之前的拦截判断 (执行顺序:preinstall install postinstall)
创建新项目 & build构建
在这个模板中新添加一个包,操作流程如下:
cd ./packages
mkdir ecdesigner-main && cd ecdesigner-main
pnpm create vite ecdesigner-main --template vue // 基于vite脚手架 创建 vue3项目
pnpm exec //在项目范围内执行 shell 命令
pnpm -r, --recursive // 在工作区的每个项目中运行命令。如果您希望即使在运行脚本时也包含根项目,请将include-workspace-root设置设置为true。(.npmrc里的include-workspace-root属性设为true即可,默认为false)
pnpm -r install
pnpm -r run build //pnpm默认按拓扑执行
pnpm exec -r rm -rf node_modules

charset版本控制 & 发布版本:
pnpm add @changesets/cli -w
npx changeset init
npx changeset add //添加一个changeset,按照提示进行操作即可
Which packages would you like to include? · @xinchen/test1, @xinchen/test2
Which packages should have a major bump? …
all packages
@xinchen/test1@0.0.2
@xinchen/test2@0.0.2
Are you sure you want to release the first major version of @xinchen/test1? (Y/n) › true
Please enter a summary for this change (this will be in the changelogs).
(submit empty line to open external editor)
Summary · 测试更改日志
npx changeset version //生成最终的 CHANGELOG.md 还有更新版本信息
npx changeset publish //发布
monorepo 是在一个项目中管理多个包的项目组织形式。它能解决很多问题:工程化配置重复、link 麻烦、执行命令麻烦、版本更新麻烦等。
lerna 在文档中说它解决了 3 个 monorepo 最大的问题:
不同包的自动 link
命令的按顺序执行
版本更新、自动 tag、发布
这三个问题是 monorepo 解决的核心问题。
第一个问题用 pmpm workspace、npm workspace、yarn workspace 都可以解决(install时会自动帮你完成内部link,支持workspace协议声明依赖)。
第二个问题用 pnpm exec 也可以保证按照拓扑顺序执行(pnpm 默认就是--sort按拓扑排序),用 npm和 yarn 不支持拓扑顺序执行(需借助learn拓扑执行lerna run --sort build)。
第三个问题用 changesets 也可以做到。
lerna 在功能上和 pnpm workspace + changesets 并没有大的差别,主要是它做了命令缓存、分布式执行任务等性能的优化。
总之,monorepo 工具的核心就是解决这三个问题。
npm link 的流程实际上是这样的:npm 包先 link 到全局,再 link 到另一个项目的 node_modules。
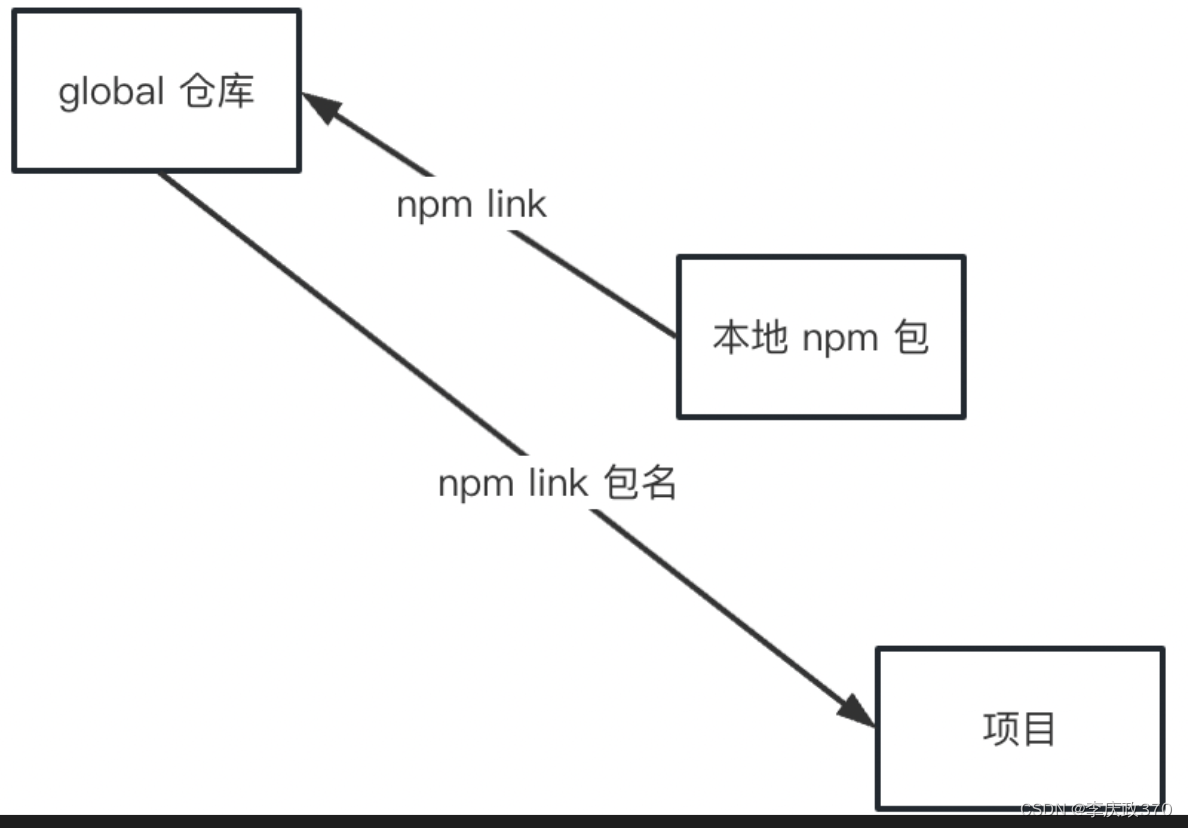
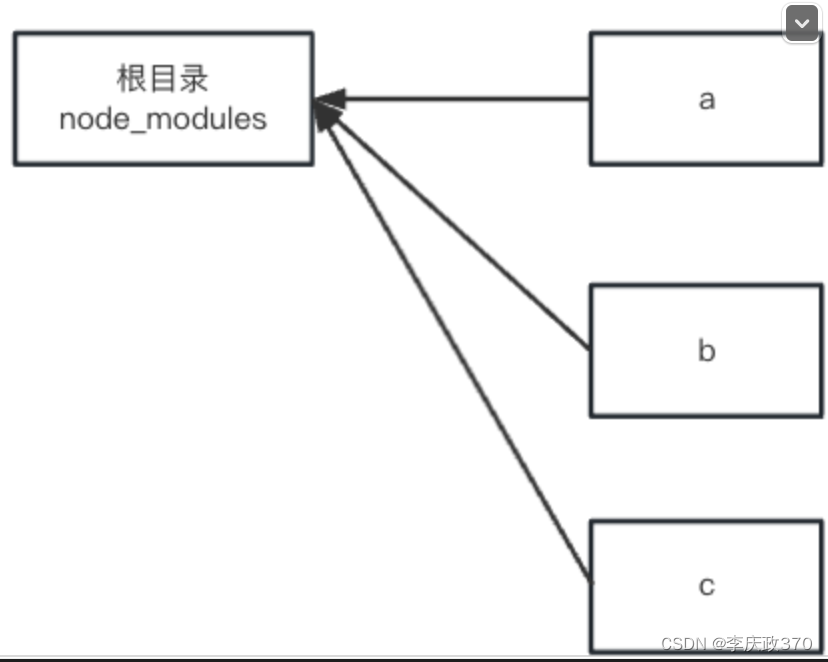
而 monorepo 工具都是这样做的:
比如一个 monorepo 项目下有 a、b、c 三个包,那么 monorepo 工具会把它们 link 到父级目录的 node_modules。
node 查找模块的时候,一层层往上查找,就都能找到彼此了,就完成了 a、b、c 的相互依赖。


应用开发——应用程序入口UIAbility(题目答案))

使用benchmark分析项目)














