资源导入优化
随着项目越来越大,资源越来越多,有一套资源导入自动化设置很有必要,它不但可以减少你的工作量,也能更好的统一管理资源,保证资源的导入设置最优,还不会出错。
AssetPostprocessor
在Unity中除了引擎自己创建的资源,更多的是外部导入进来的,像贴图纹理、模型动画、音效视频,这些导入的外部资源都会经过Unity引擎转换成一种Unity内部格式的资源,存储在Library下。
AssetPostProcessor是一个编辑器类,用来管理资源导入,当资源导入之前和之后都会发送通知,可以根据不同的资源类型,在导入之前和之后做不同的处理,来修改Untiy内部格式资源。一般我们通过这个类中OnPreprocess和OnPostprocess消息处理函数来修改资源数据和设置,这两者的区别可以简单理解为:
- OnPreprocess用来改变资源报错在meta中的序列化信息,也就是说大部分是Inspector视图可见的选项。
- OnPostprocess为导入过程中的一些处理,结果保存在最终的Library,是和序列化无关的。
AssetPostprocessor 常用API介绍:
using UnityEngine;
using UnityEditor;public class MyAssetPostprocessor : AssetPostprocessor
{//模型导入之前调用public void OnPreprocessModel() { }//模型导入之后调用public void OnPostprocessModel(GameObject go) { }//Texture导入之前调用,针对Texture进行设置public void OnPreprocessTexture() { }//Texture导入之后调用,针对Texture进行设置public void OnPostprocessTexture(Texture2D tex) { }//导入Audio后操作public void OnPostprocessAudio(AudioClip clip) { }//导入Audio前操作public void OnPreprocessAudio() { }//所有的资源的导入,删除,移动,都会调用此方法,注意,这个方法是static的public static void OnPostprocessAllAssets(string[] importedAsset, string[] deletedAssets, string[] movedAssets, string[] movedFromAssetPaths){foreach (string filePath in importedAsset){Debug.Log("importedAsset:" + filePath);}foreach (string filePath in deletedAssets){Debug.Log("deletedAssets:" + filePath);}foreach (string filePath in movedAssets){Debug.Log("movedAssets:" + filePath);}foreach (string filePath in movedFromAssetPaths){Debug.Log("movedFromAssetPaths:" + filePath);}}
}纹理导入设置示例:
public void OnPreprocessTexture()
{//获得importer实例TextureImporter textureImporter = assetImporter as TextureImporter;Debug.Log("OnPreprocessTexture: " + textureImporter.assetPath);//设置Read/Write Enabled开关,不勾选textureImporter.isReadable = false;if (textureImporter.assetPath.StartsWith("Assets/UI")){//设置UI纹理Generate MipmapstextureImporter.mipmapEnabled = false;//设置UI纹理WrapModetextureImporter.wrapMode = TextureWrapMode.Clamp;}
}也可以使用OnPostprocessAllAssets,导入音效设置示例:
public static void OnPostprocessAllAssets(string[] importedAsset, string[] deletedAssets, string[] movedAssets, string[] movedFromAssetPaths)
{foreach (string filePath in importedAsset){if (filePath.EndsWith(".wav") || filePath.EndsWith(".mp3")){var Importer = AssetImporter.GetAtPath(filePath);if (Importer != null && Importer.GetType() == typeof(AudioImporter)){var mImporter = Importer as AudioImporter;mImporter.forceToMono = true;var set = mImporter.defaultSampleSettings;if (set.sampleRateOverride != 22050){set.sampleRateSetting = AudioSampleRateSetting.OverrideSampleRate;set.sampleRateOverride = 22050;mImporter.defaultSampleSettings = set;}}}}
}Preset Manager
除了AssetPostprocessor,Unity还提供了Preset Manager,也可以对Unity的资源设置进行统一管理。Preset Manager通过创建Preset(预设),保存对象的属性信息,以此为模板可应用到新创建的组件或新导入的资源中,使它们有相同的属性设置。
Preset Manager: 是允许管理在将组件添加到游戏对象或将新资源添加到项目时创建的自定义预设以指定默认属性。您定义的默认预设会覆盖Unity的默认设置。 注意:不能为项目设置、首选项设置或原生资源(Materials, Animations, or SpriteAtlas)设置默认属性。 除了在创建component和导入资源时使用默认Presets外,在Inspecrot窗口中使用 Reset 按钮时,Unity还会应用默认Presets设置.
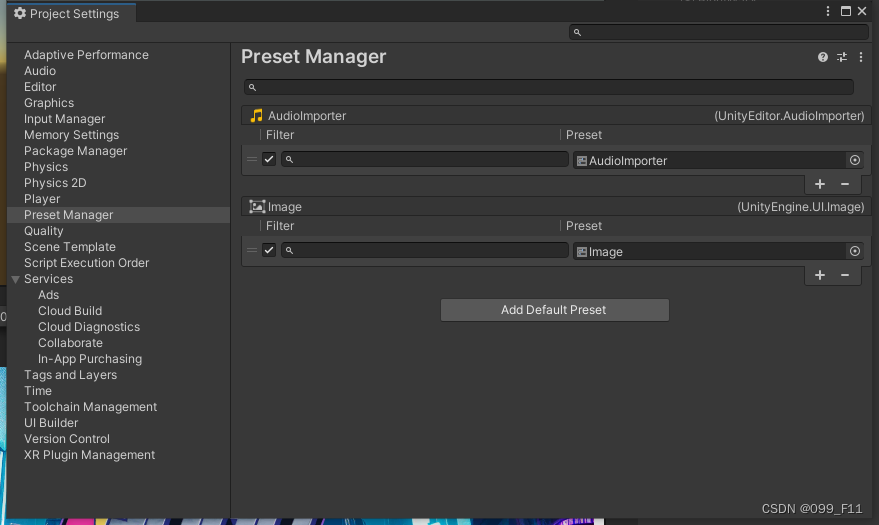
- Filter 使用 Filter 字段来定义预设应用于哪些组件或导入器。
- Preset 使用 Preset 字段设置要使用的预设。默认情况下,预设会在您创建后应用于该预设类型的所有组件或资源导入器。如果您只想将其应用于特定组件或资源类型,请使用 Filter 字段来定义何时应用预设。
- Add Default Preset 选择此按钮选择要为其添加预设的导入器、组件或者 ScriptableObject 。如果您选择导入器或者组件,选择要为其创建预设的资源导入器或组件的类型。
创建Preset
以音效为例,当你有一个音效文件,导入Unity并设置好你理想的属性,在Inspector栏点击保存预设的按钮,然后点击SaveCurrentTo,保存为一个新的Preset。
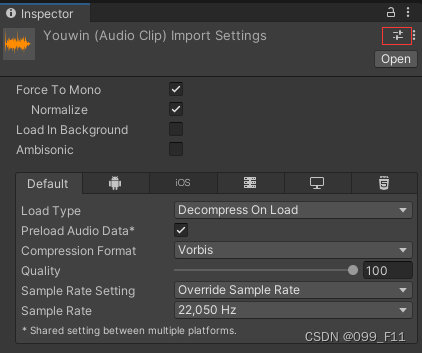
你可以创建三种类型的Preset,导入器、组件、ScriptableObject
创建好Preset后,在Preset Manager窗口点击Add Default Preset,则可为默认设置指定预设。
你可以添加各种各样的Preset,同一种组件,同一种导入器还可以有多个Preset,可以使用Filter(过滤器)规则来定义何时应用预设,可以按文件名、目录和文件扩展名进行过滤。
Preset Manager 虽然方便,但灵活性有所欠缺。以音效为例,如果要区分长音效短音效应用不同的设置,Preset Manager则无法满足,但AssetPostprocessor则可以。
纹理优化
纹理可以说是Unity中最常用的资源了,也是资源占比最多的,纹理使用不当将给项目带来严重的性能问题。
纹理压缩格式的选择
纹理压缩是一种图像压缩,用于在保持视觉质量的同时减小纹理数据大小。我们平时看到的纹理都是png、jpg、tga等格式,但在Unity中所说的纹理压缩和这些格式几乎没有关系,纹理导入Unity后,会生成Unity能识别的Texture类型资源。
Unity 支持许多常见的图像格式作为导入纹理的源文件(例如 JPG、PNG、PSD 和 TGA)。但是,3D 图形硬件(例如显卡或移动设备)在实时渲染期间不会使用这些格式。这种硬件要求纹理以专门格式进行压缩,这些格式针对快速纹理采样进行了优化。不同的平台和设备分别都有自己的专有格式。
为什么需要纹理压缩呢
主要考虑内存+带宽,尤其在移动设备上,内存带宽有限。假如我们直接使用RGB 16、RGBA 32 这些未经压缩的纹理格式,如一张512*512的纹理贴图,一个像素占4Byte,512x512x4B=1048576B=1M,但如果使用ETC2,只有256KB,相差4倍。内存是一方面,另一个重要的是数据传输时的带宽,带宽是发热的元凶,特别在移动设备上。
因此我们需要一种内存占用既小又能被GPU读取的格式——压缩纹理格式。纹理压缩对应的算法是以某种形式的固定速率有损向量量化将固定大小的像素块编码进固定大小的字节块中。
为什么不直接使用png、jpg、tga这类常见的压缩格式?
尽管png、jpg、tga的压缩率很高,但并不适合纹理,主要问题是不支持像素的随机访问,这对GPU相当不友好,GPU渲染时只使用需要的纹理部分,我们总不能为了访问某个像素去解码整张纹理吧?不知道顺序,也不确定相邻的三角形是否在纹理上采样也相邻,很难有优化。这类格式更适合下载传输以及减少磁盘空间而使用,平时我们能在图像软件浏览这些格式的图片,是经过CPU解压后,再传给GPU渲染的。
移动平台纹理压缩格式选择
ASTC
ASTC是在OpenGL ES3.0出现后在2012年中产生的一种业界领先的纹理压缩格式,它的压缩分块从4x4到12x12最终可以压缩到每个像素占用1bit以下,压缩比例有多种可选。ASTC格式支持RGBA,且适用于2的幂次方长宽等比尺寸和无尺寸要求的NPOT(非2的幂次方)纹理。
ASTC在Android、IOS、WebGL都支持,在压缩质量和容量上有很大的优势。如一张512*512的纹理贴图,ASTC 6x6 block压缩格式,内存占用为115.6KB,只有ETC2的一半,但质量和ETC2相差无几。
不管Android、IOS都首推ASTC,都2023年了,国产Android手机基本都支持了,IOS在iphone6以上的设备都支持。
Android RGBA Compressed ETC2
如果你的项目考虑到兼容老旧设备,或者海外手机的情况下,Android RGBA Compressed ETC2是首选
Android RGBA Crunched ETC2
Crunch 压缩是一种基于 DXT 或 ETC 纹理压缩的有损压缩格式(压缩过程中会丢失部分数据)。在运行时,纹理在 CPU 上解压缩为 DXT 或 ETC,然后上传到 GPU。Crunch 压缩有助于纹理在磁盘上使用尽可能少的空间,但对于运行时内存使用量没有影响。Crunch 纹理可能需要很长时间进行压缩,但在运行时的解压缩速度非常快。
RGBA Crunched ETC2,虽然质量方面有些丢失,但包体小很多,对包体有要求或者网络下载有要求都可考虑。
IOS RGBA Compressed PVRTC 4
如果你的项目考虑到兼容iphone5s以及之前的设备,只能选择RGBA Compressed PVRTC 4了,PVRTC压缩质量一般会比较差,可以考虑拆分贴图,另外PVRTC要求纹理的长宽相等并且要是2的整次幂。
选择纹理压缩格式需要在文件大小、质量和压缩时间之间取得平衡。
除了纹理压缩,还有如下纹理优化要点:
- 纹理大小,需要合理控制纹理的大小,减小需要较少细节的纹理的大小有助于减少带宽。需要特别留意大于1024*1024的纹理,角色模型纹理、场景物件纹理可限制最大512*512,特效纹理可限制最大256*256,UI图集可限制最大1024*1024。可以通过设置Max Size限制纹理最大尺寸,而不用管它导入时的尺寸。
- 纹理图集,使用图集可以更好进行批处理,减少DrawCall。 虽然Unity的SpriteAtlas可以自动生成图集,但还是建议自己生成图集,更加可控。图集大小不宜过大,同一UI界面尽量使用更少的图集,最好就使用一个,图集不宜有过多的透明空白,图集里不宜有过大的贴图,要平衡好这些条件,图集的使用也是一门艺术。
- Mipmap,Mipmap是以逐渐降低的分辨率保存的纹理副本,使用MipMap的纹理,内存约增加原来的1/3。渲染具有 Mipmap 的纹理时,将根据像素片元在屏幕空间中占据的纹理空间大小选择适当的级别进行采样。当对象离摄像机较远时,将应用较低分辨率的纹理。当对象离摄像机较近时,将应用较高分辨率的纹理。由于开启Mipmap的纹理增加内存,因此要留意哪些纹理需要开启。如Sprite纹理,UI界面相关纹理,UI特效纹理,都不需要开启Mipmap。
- 过滤模式(Filter Mode),纹理过滤通常可提高场景中的纹理质量。如果不进行纹理过滤,锯齿等瑕疵会导致纹理看起来呈块状。纹理过滤通常用于锐化纹理和消除锯齿。
Unity提供了三种过滤模式:
- Point(no filter)--最近/点过滤,使用最近点采样的方法,这是最简单、计算量最小的纹理过滤形式,但在近距离观察时,最近/点过滤会使纹理看起来呈块状。
- Bilinear--双线性过滤模式,它会对相邻纹素进行采样和均值化处理,以此对纹理中的像素进行着色。与最近过滤不同,双线性过滤可让像素平滑渐变,从而减少块状像素。双线性过滤的副作用是,当近距离观察时,纹理会变模糊。
- Trilinear--双线性过滤模式,类似于双线性过滤,但在 Mipmap 级别之间增加了混合。三线性过滤通过平滑过渡来消除 Mipmap 之间的明显变化。
一般的纹理使用双线性过滤(Bilinear)即可,减少Trilinear的使用,Trilinear模式对表现效果的提升,是以GPU的额外开销为代价的。同等条件下,三线性过滤的GPU占用是最高的。
- 各向异性过滤(Aniso Level),以大角度查看纹理时提高纹理质量,各向异性过滤可改善纹理在倾斜角度下的视觉效果(如远处地面模糊),因此非常适合用于地表纹理。Aniso Level值越高,它提供的好处越多,但性能成本也越高,一般情况下不要开启它,除非确定开启有效果。
- Read/Write,开启纹理的Read/Write选项后,就可以从脚本来访问纹理数据。内存中会产生一份纹理数据的副本,以便于对纹理进行实施的编辑和修改,以此来达成某些动态的纹理效果。如果纹理不涉及读写的操作,不要开启。
- 无效透明通道的纹理,当一张纹理完全不透明(Alpha值全为1),可去除相应纹理的Alpha通道,设置纹理Alpha Source为None。
- 纯色纹理,通常情况下不需用用到纯色的纹理,可以使用其他方式代替材质属性。如必须使用,也要尽可能使用小尺寸的,如16*16。
- 纹理资源大小2的幂次,要使用纹理压缩,通常都要求纹理资源大小为2的幂次,如ETC1,ETC2,ASTC,PVRTC,PVRTC甚至要长宽相等,如果纹理原始大小为非2的幂次的纹理资源,Unity导入纹理默认设置 Non-Power of 2 为最近的伸缩大小,可能由于伸缩导致贴图质量问题,因此应尽量使用原始大小为2的幂次的纹理资源。
UI性能优化
优化UGUI应从哪些方面入手?
可以从CPU和GPU两方面考虑,CPU方面,避免触发或减少Canvas的Rebuild和Rebatch,减少Drawcall,减少CPU处理顶点的时间;GPU方面,降低Overdraw,缩小纹理大小。
Canvas的Batch构建过程(The Batch building process),简称Rebatch
Batch 构建过程是指Canvas通过结合网格绘制它所承载的UI元素,生成适当的渲染命令发送给Unity图形流水线。Batch的结果被缓存复用,直到这个Canvas被标为dirty,当Canvas中某一个构成的网格改变的时候就会标记为dirty,这个Dirty就会触发Rebatch。
Rebatch不仅有批处理排序,还有网格合并之类的。Canvas的网格从那些Canvas下的CnavasRenderer组件中获取,但不包含任何子Canvas。
所以对于UGUI的性能分析,要分开两点
- Canvas的批处理过程 Rebatch
- Graphic 和Layout的 Rebuild
这两点,都会影响性能。但是Rebatch是有多线程的加持的,而Rebuild是在主线程的。
- Rebuild自身会有性能消耗,同时Rebuild会触发Rebatch。
- Rebatch除了被Rebuild触发,还会被其他情况触发。
- Rebatch的性能上的问题,在电脑上比较难看的出来,因为有多线程加持。
Rebuild过程
Rebuild 过程是指Layout和UGUI的C#的Graphic组件的网格被重新计算,这是在CanvasUpdateRegistry类中执行的。这是一个C#类,打开UI的源码,它里面的一个函数,叫做PerformUpdate,当一个Canvas组件触发它的WillRenderCanvases事件时,这个方法就会被执行。这个事件每帧调用一次,这也是为什么我们看Profile的时候,出现性能高峰的总是会看到WillRenderCanvases的原因了。
PerformUpdate的运行过程分3步:
- 按顺序遍历调用Dirty的Layout组件的Rebuild函数
- 要求任何已注册的裁剪组件(例如Mask),剔除所有裁剪的组件。这是通过ClippingRegistry.Cull完成的。
- 按顺序遍历调用Dirty的Graphic组件的Rebuild函数
Rebuild分为 Layout Rebuild 和 Graphic Rebuild
Layout Rebuild
要重新计算一个或多个Layout组件中包含的组件的适当位置(和可能的大小),必须按其适当的层次结构顺序应用Layouts。在GameObject层次结构中靠近根部的布局可能会更改嵌套在其中的任何布局的位置和大小,因此必须首先进行计算。
为此,UGUI根据层次结构中的深度对dirty的Layout组件列表进行排序。层次结构中较高的Layout(即,父节点较少)将被移到列表的前面。
然后,排序好的Layout组件的列表将被rebuild,在这个步骤Layout组件控制的UI元素的位置和大小将被实际改变。
Graphic Rebuild
当Graphic组件被rebuild的时候,UGUI会将控制权传递给ICanvasElement接口的Rebuild方法。Graphic执行了这一步,并在rebuild过程中的PreRender阶段运行了两个不同的rebuild步骤:
- 如果顶点数据已标记为Dirty(例如,当组件的RectTransform的大小更改时),则将重新构建网格。
- 如果将材质数据标记为Dirty(例如,当更改组件的材质或纹理时),则将更新附加的Canvas Renderer的材质。
Graphic的Rebuild不会按照Graphic组件的特殊顺序进行,并且不需要任何排序操作。
Rebatch和Rebuild的触发条件总结
触发Rebatch的条件:
- 当Canvas下有Mesh发生改变时,如:
- SetActive
- Transform属性变化
- Graphic的Color属性变化(改Mesh顶点色)
- Text文本内容变化
- Depth发生变化
触发Rebuild的条件:
- Layout修改RectTransform部分影响布局的属性
- Graphic的Mesh或Material发生变化
- Mask裁剪内容变化
减少Canvas的Rebuild和Rebatch
基于以上Canvas的Rebuild和Rebatch原理,我们可以做以下优化:
- 使用尽可能少的UI元素;在制作UI时,一定要仔细查检UI层级,删除不必要的层级,这样可以减少深度排序的时间以及Rebuild的时间
- 减少Rebuild的频率,将动态UI元素(频繁改变例如顶点、alpha、坐标和大小等的元素)与静态UI元素分离出来,放到特定的Canvas中,即动静分离。
- 避免频繁使用SetActive(true)/(false)显示或者隐藏UI,可考虑其它优化方案:1,在C#层(或Lua层)设置变量来标识相应的Go处于Active还是非Active状态,避免对Active的对象进行SetActive(true),避免对非Active的对象进行SetActive(false)。2,将要频繁变化的UI元素与不频繁变化的UI元素放在不同的Canvas中,减少UI元素变化时的耗时。3,通过将UI元素的坐标移动到Canvas的范围之外的方法来显示与隐藏,避免SetActive的耗时以及SendWillRenderCanvases的耗时。4,通过添加CanvasGroup组件设置透明度的方式来进行显示与隐藏。
- 慎用自带组件Outline和Shaow,都是通过重复绘制多个Mesh实现的,其中Showdow绘制为原文本Mesh的2倍,而Outline为5倍,对渲染面数、顶点数,BuildBatch和SendWillRenderCanvases的耗时,Overdraw都有影响。如经常用,可考虑其它方式,如TextMeshPro,或把阴影和描边做到字体里。
- 谨慎使用Text的Best Fit选项,虽然这个选项可以动态的调整字体大小以适应UI布局而不会超框,但其代价是很高的,一方面是适配本身在调整文本框大小时有CPU耗时开销,另一方面每个字号下新生成的字都会在Font Texture上占用一个字的大小,容易导致Font Texture过大(这个类似图集,当Font Texture当前大小放不下时才会占用更多内存)。这个特定问题已在 Unity 5.4 中得到纠正,Best Fit 不会不必要地扩展字体的纹理图集,但仍然比静态大小的文本慢得多。
- 谨慎使用Canvas的Pixel Perfect选项,该选项会使得ui元素在发生位置变化时,造成layout Rebuild。(比如ScrollRect滚动时,如果开启了Canvas的pixel Perfect,会使得Canvas.SendWillRenderCanvas消耗较高)
- 不要使用Layout组件,Layout组件性能消耗相对昂贵,会大大地增加Canvas.SendWillRenderCanvases函数耗时,利用好RectTransform同样可实现简单布局。
- 对于血条、飘字、小地图标记等频繁更新位置的UI,可尽量减低更新频率,如隔帧更新,并设定更新阈值,当位移大于一定数值时再赋值(一方面是位移小时可能表现上看不出位移,另一方面是就算是没有实际位移,重复赋相同的值,也会SetDirty触发重建),可减少BuildBatch耗时。
- 禁用Canvas,在UGUI中,Batch是以Canvas为单位的,当隐藏UI界面时,通常是禁用Canvas所属的GameObject,这也会导致Canvas放弃其VBO数据,当显示UI界面时,重新启用Canvas将需要运行重建和重新批处理过程。如果这种情况经常发生,则CPU使用率增加会导致应用程序的帧速率停顿。因此,可考虑直接禁用Canvas组件,而不是禁用GameObject,这将导致不绘制UI的网格,但它们将保持驻留在内存中,并保留其原始批处理。
减少Drawcall
UGUI 合批原理
UGUI的合批规则是进行重叠检测,然后分层合并。
- 先获得一个按Hierarchy的顺序的列表,从上而下进行
- 计算每个UI元素的深度:如果有一个UI元素,它所占的矩形范围内,如果没有任何UI在它的底下,那么它的深度就是0(最底下);如果有一个UI在其底下且该UI可以和它Batch,那它的深度与底下的UI深度一样;如果有一个UI在其底下但是无法与它Batch,那它的深度为底下的UI的深度+1;如果有多个UI都在其下面,那么按前两种方式遍历计算所有的深度,其中最大的那个作为自己的深度。
- 排序:按照深度->材质->贴图->Hierarchy层级顺序优先级进行排序。
- 合批:对排序后的列表,从头开始一个一个检测是否能与前面的物体合批。合批条件:无独占批次(只判断isCanvasInjectionIndex)+材质相同+贴图相同+裁剪开关和裁剪矩形相同+贴图A8格式一致(kTexFormatAlpha8),非SubBatch只判断前两个条件,一般情况下UI的材质都一样
基于UGUI合批原理,我们可以做以下优化:
- 使用图集,同一Canvas下使用同一图集的Image,在渲染过程中可以进行合批,从而减少Drawcall,同一Canvas下使用的图集数量越少越有利于合批,理想情况下只用到一个图集当然最好了。
- 减少重叠,重叠容易造成深度不同,尤其不同图集之间交叉重叠,极易影响合批。
- 少用Mask,Mask会额外多出两个Draw Call。Mask不利于层级合并,Mask下的UI元素无法与外界UI元素合批,导致增加更多的Drawcall
降低Overdraw
可在Scene界面以Overdraw模式查看,颜色越亮(橙色)Overdraw越大。
- 设计上减少UI元素重叠,尤其注意透明部分的重叠,主要做的是在摆UI预设体的时候,Recttransform的大小控制在【够用就好】的情况。
- 禁用不可见的UI,比如当打开一个界面时如果完全挡住了另外一个界面,则可以将被遮挡住的系统禁用。
- 不要使用空的Image,如使用alpha为0的Image触发接收点击事件。
- 避免使用自带组件Outlien和Shaow等效果,Outlien会产生5倍overdraw、Shaow会产生2倍overdraw
RectMask2D与Mask
Mask依赖Image组件,占用两个Batch,多一倍Overdraw,可以裁剪任意形状。
RectMask2D不依赖Image组件,不占用Batch,没有Overdraw,只能裁剪规则形状。
因此,一般情况下,规则的裁剪尽量用RectMask2D代替Mask,特别是在使用ScrollRect时。
RectMask2D一定比Mask好吗?并不是,Mask间是可以合批的,而RectMask2D间不行,因此当要使用多Mask时,如背包界面中的道具格子,每个格子有裁剪需求时,尽量用Mask,Mask可合批,而RectMask2D会导致合批被打断。
因此:
- 当一个界面只有一个Mask,那么RectMask2D优于Mask;
- 当有两个Mask,那么两者差不多;
- 当大于两个Mask,那么Mask优于RectMask2D。
Graphic Raycaster
射线检测遍历所有将'Raycast Target'设置为true的Graphic组件。每一个Raycast Target都会被进行测试。如果一个Raycast Target通过了所有的测试,那么它就会被添加到“被命中”列表中。
每个Graphic Raycaster都将遍历 Transform层次结构一直到根,此操作的成本与层次结构的深度成比例线性增长。因此进行射线检测的元素越多,层级越深,消耗越高。
鉴于所有射线检测目标都必须由Graphic Raycaster进行测试,因此最好的做法是仅在必须接收点击事件的UI组件上启用'Raycast Target'设置。检测目标列表越少,遍历的层级越浅,每次射线检测的速度越快。
粒子特效优化
- 特效运行时包含的ParticleSystem组件数量不宜过多,建议不超过2个
- 特效运行时最大粒子数量不宜过多,建议少于60
- 粒子特效的网格发射数不宜过多,粒子的渲染模式可分为两大类:2D的Billboard(公告牌)图形模式和Mesh模式,Mesh性能开销较高,建议不超过5个,且Mash的面片数也要尽量少,建议不越过500。
- 粒子特效引用的纹理数不宜过多,建议不超过5个,且纹理的大小也不宜过大,不越过256*256。
- 特效运行时DrawCall峰值不宜过高,建议控制在10以下。
- 特效运行时平均Overdraw率不宜过高,陪数控制在3倍以下,在Overdraw模式下不出红色最好。(Overdraw对性能影响最大,需特别留意)
- Prewarm,粒子系统的Prewarm操作会在使用时的第一帧中造成相对集中的CPU耗时,很可能会造成运行时局部卡顿。如没必要建议关闭
音效优化
音效的优化一般可从三方面考虑:
- 资源导入后占用包体的大小
- 运行时占用的内存大小
- 运行的时候占用CPU的时间
Unity支持很多音频格式,WAV、MP3、OGG等,建议原始音频资源尽量采用未压缩的WAV格式,背景音乐也可考虑MP3格式。
音效的设置
- Force to Mono:对音乐音效统一采用单通道设置,移动平台建议开启,内容不丢失的情况下可以减少它的使用内存和大小。特别是在移动平台下几乎听不出任何区别。
- Normalize:当ForceToMono开启后选项可用,开启后音频将在ForceToMono的混合过程中被单位化。
- LoadInBackground:后台加载,默认关闭。如果启用此选项这个音频将在一个单独的线程中延迟加载而不会阻塞主线程。
- Ambisonic:是否是环绕声,对于360度视频和XR应用程序非常有效。如果AudioFile包含三维编码音频,则开启此项其余情况可关闭。
- Load Type(加载类型):
- DeCompressOnLoad 加载后解压缩(适合小音效),音频文件将在加载后立即解压缩,对较小的音效使用此选项可避免动态解压缩的性能开销。请注意在加载后解压缩Vorbis编码的声音,会使用它压缩时大约10倍的内存,ADPCM编码大约是3.5倍。所以请不要降此选项用于大文件。
- CompressedInMemory 压缩在内存中(适合较大文件音效),将声音压缩在内存中,在播放是解压缩。这个选项有轻微的性能开销(尤其是对于ogg/Vorbis压缩文件)所以只能用于大文件音效,因为在加载时解压缩会使用大量的内存。可在Profiler窗口的音频面板中的“DSP CPU”部分监视。
- Streaming 流(适合大文件), 动态解码声音,此方法是使用最最小量的内存来缓冲从磁盘逐渐读取并在运行中解码的压缩数据。解压缩发生在单独的流线程上,请注意解压缩发生在Profiler窗口的音频面板中的"Streaming CPU" 部分中可监视其CPU使用率的单独流式线程上,即使没有加载任何饮品数据,流式片段也会有200KB的过载。
因此建议,简短音效导入后小于200kb,采用Decompress on Load模式,对于复杂音效,大小大于200kb,长度超过5秒的音效采用Compressed In Memory模式,对于长度较长的音效或背景音乐则采用Streaming模式,虽然会有CPU额外开销,但节省内存并且加载不卡顿。
- Preload Audio Data:预加载音频数据。如果启用音频剪辑将在场景加载时预先加载,也就是当场景开始播放时,所有的AudioClips已经完成了加载。如果没有开启,音频数据也会在第一次调用AudioSource.Play(),AudioSource.PlayOneShot()执行时被加载,或者也可以通过AudioSource.LoadAudioData(),AudioSource.UnLoadAudioData()再次加载时被加载。
- Compression Format 压缩格式:
- PCM,这个选项提供了以更大的文件大小和代价提供了更高的质量,所以非常适合使用在很短的音效上面。
- ADPCM,这个格式适用于需要大量使用的音效上面,比如脚步 爆破和子弹发射,他比PCM小3.5倍但是CPU适用于远低于Vorbis,所以适合多次调用的短音效。
- Vorbis,比PCM小但是质量比PCM低,比ADPCM消耗更多而CPU。这种格式最适合中等长度的音效和音乐,这个选择多了个Quality可以调节质量改变文件大小1-100。
因此建议,移动平台大多数声音尽量采用Vorbis压缩设置,IOS平台或不打算循环的声音可以选择MP3格式,对于简短、常用的音效,可以采用解码速度快的ADPCM格式(PCM为未压缩格式)
- SampleRateSetting:
- OptimizeSampleRate,该设置根据分析的最高频率内容自动优化采样率。
- PreserveSampleRate,该设置保持比率未修改(默认)
- OverrrideSampleRate,该设置允许手动覆盖采样率,优先选择22050HZ,如果音质不能接受就选择44100HZ,但是不允许高于44100HZ。
一般移动平台音频采样率经验数据建议设置为22050Hz,较高的采样率听不出区别,只会徒增文件大小和内存占用。
另外,当实现静音功能时,不要简单的将音量设置为0,应销毁音频(AudioSource)组件,将音频从内存中卸载。
延迟问题
Unity在移动平台上音频播放有延迟,特别在Android上,感觉很明显。这是正常的,可在ProjectSettings的Audio中的DSP Buffer Size设置为Best latency。
也可以尝试使用一些三方插件,Wwise是一款不错的音频引擎,不少大厂都在用,https://github.com/monkrythree/Unity_Wwise
移动平台高低端机区分优化
现在的移动设备五花八门,性能高低不同,如想让不同机型的设备都能流畅的运行我们的app,就得针对性地优化。一种通用的方式就是区分高中低机型,根据级别使用不同的画质、贴图质量、阴影、模型特效等。
要区分设备的高中低级别,可根据设备的内存、CPU、GPU等相关数据为标准进行划分。
如下是android手机的代码实现:
package com.unity3d.player;import android.annotation.TargetApi;
import android.app.ActivityManager;
import android.content.Context;
import android.os.Build;
import android.util.Log;import java.io.BufferedReader;
import java.io.File;
import java.io.FileFilter;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;public class Themis {/*** 根据内存和CUP级别,获取设备高中低级别* @param context - Context object.* @return*/public static int judgeDeviceLevel(Context context) {int level = 0;int ramLevel = judgeMemory(context);int cpuLevel = judgeCPU();level = Math.min(ramLevel, cpuLevel);Log.i("Themis", "ramLevel:" + ramLevel + ", cpuLevel:" + cpuLevel + ", level:" + level);return level;}/*** 评定内存的等级.* @return*/private static int judgeMemory(Context context) {long ramMB = getTotalMemory(context) / (1024 * 1024);Log.i("Themis", "total memory:" + ramMB);int level = 0;if (ramMB <= 2000) { //2G或以下的最低档level = 1;} else if (ramMB <= 3000) { //2-3Glevel = 2;} else if (ramMB <= 4000) { //4G档 2018主流中端机level = 3;} else if (ramMB <= 6000) { //6G档 高端机level = 4;} else { //6G以上 旗舰机配置level = 5;}return level;}/*** 评定CPU等级.(按频率和厂商型号综合判断)* @return*/private static int judgeCPU() {int level = 0;int freqMHz = getCPUMaxFreqKHz() / 1000;Log.i("Themis", "cup freqMHz:" + freqMHz);if (freqMHz <= 1600) { //1.5G 低端level = 1;} else if (freqMHz <= 2000) { //2GHz 低中端level = 2;} else if (freqMHz <= 2500) { //2.2 2.3g 中高端level = 3;} else if (freqMHz <= 3000) { //3g 高端level = 4;} else { //旗舰机配置level = 5;}return level;}/*** The default return value of any method in this class when an* error occurs or when processing fails (Currently set to -1). Use this to check if* the information about the device in question was successfully obtained.*/public static final int DEVICEINFO_UNKNOWN = -1;private static final FileFilter CPU_FILTER = new FileFilter() {@Overridepublic boolean accept(File pathname) {String path = pathname.getName();//regex is slow, so checking char by char.if (path.startsWith("cpu")) {for (int i = 3; i < path.length(); i++) {if (!Character.isDigit(path.charAt(i))) {return false;}}return true;}return false;}};/*** Calculates the total RAM of the device through Android API or /proc/meminfo.** @param c - Context object for current running activity.* @return Total RAM that the device has, or DEVICEINFO_UNKNOWN = -1 in the event of an error.*/@TargetApi(Build.VERSION_CODES.JELLY_BEAN)public static long getTotalMemory(Context c) {// memInfo.totalMem not supported in pre-Jelly Bean APIs.if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.JELLY_BEAN) {ActivityManager.MemoryInfo memInfo = new ActivityManager.MemoryInfo();ActivityManager am = (ActivityManager) c.getSystemService(Context.ACTIVITY_SERVICE);am.getMemoryInfo(memInfo);if (memInfo != null) {return memInfo.totalMem;} else {return DEVICEINFO_UNKNOWN;}} else {long totalMem = DEVICEINFO_UNKNOWN;try {FileInputStream stream = new FileInputStream("/proc/meminfo");try {totalMem = parseFileForValue("MemTotal", stream);totalMem *= 1024;} finally {stream.close();}} catch (IOException e) {e.printStackTrace();}return totalMem;}}/*** Method for reading the clock speed of a CPU core on the device. Will read from either* {@code /sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_max_freq} or {@code /proc/cpuinfo}.** @return Clock speed of a core on the device, or -1 in the event of an error.*/public static int getCPUMaxFreqKHz() {int maxFreq = DEVICEINFO_UNKNOWN;try {for (int i = 0; i < getNumberOfCPUCores(); i++) {String filename ="/sys/devices/system/cpu/cpu" + i + "/cpufreq/cpuinfo_max_freq";File cpuInfoMaxFreqFile = new File(filename);if (cpuInfoMaxFreqFile.exists() && cpuInfoMaxFreqFile.canRead()) {byte[] buffer = new byte[128];FileInputStream stream = new FileInputStream(cpuInfoMaxFreqFile);try {stream.read(buffer);int endIndex = 0;//Trim the first number out of the byte buffer.while (Character.isDigit(buffer[endIndex]) && endIndex < buffer.length) {endIndex++;}String str = new String(buffer, 0, endIndex);Integer freqBound = Integer.parseInt(str);if (freqBound > maxFreq) {maxFreq = freqBound;}} catch (NumberFormatException e) {//Fall through and use /proc/cpuinfo.} finally {stream.close();}}}if (maxFreq == DEVICEINFO_UNKNOWN) {FileInputStream stream = new FileInputStream("/proc/cpuinfo");try {int freqBound = parseFileForValue("cpu MHz", stream);freqBound *= 1000; //MHz -> kHzif (freqBound > maxFreq) maxFreq = freqBound;} finally {stream.close();}}} catch (IOException e) {maxFreq = DEVICEINFO_UNKNOWN; //Fall through and return unknown.}return maxFreq;}/*** Reads the number of CPU cores from the first available information from* {@code /sys/devices/system/cpu/possible}, {@code /sys/devices/system/cpu/present},* then {@code /sys/devices/system/cpu/}.** @return Number of CPU cores in the phone, or DEVICEINFO_UKNOWN = -1 in the event of an error.*/public static int getNumberOfCPUCores() {if (Build.VERSION.SDK_INT <= Build.VERSION_CODES.GINGERBREAD_MR1) {// Gingerbread doesn't support giving a single application access to both cores, but a// handful of devices (Atrix 4G and Droid X2 for example) were released with a dual-core// chipset and Gingerbread; that can let an app in the background run without impacting// the foreground application. But for our purposes, it makes them single core.return 1;}int cores;try {cores = getCoresFromFileInfo("/sys/devices/system/cpu/possible");if (cores == DEVICEINFO_UNKNOWN) {cores = getCoresFromFileInfo("/sys/devices/system/cpu/present");}if (cores == DEVICEINFO_UNKNOWN) {cores = new File("/sys/devices/system/cpu/").listFiles(CPU_FILTER).length;;}} catch (SecurityException e) {cores = DEVICEINFO_UNKNOWN;} catch (NullPointerException e) {cores = DEVICEINFO_UNKNOWN;}return cores;}/*** Tries to read file contents from the file location to determine the number of cores on device.* @param fileLocation The location of the file with CPU information* @return Number of CPU cores in the phone, or DEVICEINFO_UKNOWN = -1 in the event of an error.*/private static int getCoresFromFileInfo(String fileLocation) {InputStream is = null;try {is = new FileInputStream(fileLocation);BufferedReader buf = new BufferedReader(new InputStreamReader(is));String fileContents = buf.readLine();buf.close();return getCoresFromFileString(fileContents);} catch (IOException e) {return DEVICEINFO_UNKNOWN;} finally {if (is != null) {try {is.close();} catch (IOException e) {// Do nothing.}}}}/*** Converts from a CPU core information format to number of cores.* @param str The CPU core information string, in the format of "0-N"* @return The number of cores represented by this string*/private static int getCoresFromFileString(String str) {if (str == null || !str.matches("0-[\\d]+$")) {return DEVICEINFO_UNKNOWN;}return Integer.valueOf(str.substring(2)) + 1;}/*** Helper method for reading values from system files, using a minimised buffer.** @param textToMatch - Text in the system files to read for.* @param stream - FileInputStream of the system file being read from.* @return A numerical value following textToMatch in specified the system file.* -1 in the event of a failure.*/private static int parseFileForValue(String textToMatch, FileInputStream stream) {byte[] buffer = new byte[1024];try {int length = stream.read(buffer);for (int i = 0; i < length; i++) {if (buffer[i] == '\n' || i == 0) {if (buffer[i] == '\n') i++;for (int j = i; j < length; j++) {int textIndex = j - i;//Text doesn't match query at some point.if (buffer[j] != textToMatch.charAt(textIndex)) {break;}//Text matches query here.if (textIndex == textToMatch.length() - 1) {return extractValue(buffer, j);}}}}} catch (IOException e) {//Ignore any exceptions and fall through to return unknown value.} catch (NumberFormatException e) {}return DEVICEINFO_UNKNOWN;}/*** Helper method used by {@link #parseFileForValue(String, FileInputStream) parseFileForValue}. Parses* the next available number after the match in the file being read and returns it as an integer.* @param index - The index in the buffer array to begin looking.* @return The next number on that line in the buffer, returned as an int. Returns* DEVICEINFO_UNKNOWN = -1 in the event that no more numbers exist on the same line.*/private static int extractValue(byte[] buffer, int index) {while (index < buffer.length && buffer[index] != '\n') {if (Character.isDigit(buffer[index])) {int start = index;index++;while (index < buffer.length && Character.isDigit(buffer[index])) {index++;}String str = new String(buffer, 0, start, index - start);return Integer.parseInt(str);}index++;}return DEVICEINFO_UNKNOWN;}
}judgeDeviceLevel,划分为5个级别,对应Unity Quality的级别,可根据设备的高中低级别,设置 QualitySettings.SetQualityLevel 。
ios的机型有限,可直接根据机型来划分。
修改分辨率优化游戏性能
通常直接修改屏幕的分辨率,可以有效地优化游戏的性能,当然要在画质和性能之间平衡好关系,可根据设备高中低级别修改屏幕的分辨率。
代码示例如下:
// 设置屏幕分辨率缩放, 根据设备配置级别(1:低,2:中低,3:中,4:高,5:极高)
public void SetScreenResolution(int deviceLevel)
{float scale = 1.0f;if (deviceLevel == 1){scale = 0.8f;} else if(deviceLevel == 2){scale = 0.9f;}else{int deviceHeight = Mathf.Min(Screen.width, Screen.height);// 针对中低级别的大屏设备if (deviceHeight > 1200){scale = Math.Min(scale, 0.8f);}else if (deviceHeight > 1080){scale = Math.Min(scale, 0.9f);}}if (scale < 1){Screen.SetResolution((int)(Screen.width * scale), (int)(Screen.height * scale), true);}
}由于Screen.SetResolution是直接修改整个屏幕的分辨率,可能造成UI的画质模糊,可调整缩放系数scale,更理想的方式是3D场景与UI界面区分开来,只降3D相机,不降UI相机。
- 一种方式是将3D场景渲染到RT里面,再将RT作为RawImage的Texture渲染到UI里面,这样可以通过控制RT的分辨率来控制场景的渲染分辨率。参考:https://gwb.tencent.com/community/detail/110360
- 使用ScalableBufferManager.ResizeBuffers(float widthScale, float heightScale)设置动态分辨率,参考:https://www.xuanyusong.com/archives/4693
- 如果使用URP,可以通过修改URP管线实现,参考:https://github.com/killop/URP-12-GammaUIAndSplitResolution
包体大小优化
- 初始化资源,Resources文件夹的资源能少则少,只需要包含Unity启动必须的资源即可,例如启动检测资源更新界面。
- 插件整理,Packages目录没用到的包删除,Plugins或导入的三方插件,不需要的删除,或者打包后用不到的,可移至Editor下。
- 代码裁剪,Player Settting 里Managed Stripping Level设置为High,最高级别代码裁剪,可最大程序剥离用不到的代码,如如出现程序运行错误,需要排查,可能需要在link.xml中加入一些class,保证它们不被strip。
- 排除所有冗余资源,可找一款能检测AssetBundle冗余资源的插件,如UWA的AssetBundle检测,https://www.uwa4d.com/ ,UWA也有本地资源检测,可检测重复的纹理贴图,Unity UPR也可检测,https://upr.unity.cn/
- 纹理的优化:
- 使用合理的压缩格式,如ASTC,如特别在意包体大小,android可考虑Crunched ETC2,打包AB后小很多
- 使用合理的纹理大小,使用POT纹理,减小Max Size,使用能生成视觉上可接受的结果的最低设置
- 禁用不必要的 Mipmap,Mipmap本身是会增加1/3的内存,如纹理不需要根据摄像机的距离变化而变化,如UI,部分特效,可关闭。
- 合理规划图集,尽量少留大量空白,可以挪一下从而把尺寸降一个级别。
- 音效,开启Force To Mono,内存小很多,压缩格式使用Vorbis,采样率设置22050Hz,都有效减小内存。
- 模型,导入时开启Mesh Compression 可以减少模型占用包体大小,但可能会出现一些变形和UV精度丢失等,调节压缩到可接受的等级即可。开启 OptimizeMesh 选项,Tangent、Normal、Color、UV2等属性如果没用到不要导入。
- 动画,导入时开启Anim.Compression可以减少动画占用包体大小,同样可能出现动画变形等,调节到合适参数即可,一般选择Optimal。
- Shader,使用变体少的Shader,不要使用Unity本身的Standard Shader,Standard Shader可能生成非常多的变体。
- AssetBundle,使用LZ4压缩,可考虑DisableWriteTypeTree(去除版本类型信息),可以减小AssetBundle包体的大小,同时也可以减小内存。
- 首包大小,可在首包StreamingAssets里只包含部分AssetBundle等资源,甚至不0资源,其余资源使用热更新的方式下载更新,可有效减小首包包体大小,只是会牺部分用户体验。
- AotuStreaming,这是Unity官方推出的一个全新的流式资源加载方案,使得开发者可以在不修改代码的情况下加载云端资源,从而减少游戏包体大小,提升加载速度,在不损失质量的前提下,为用户带来了即时游戏的体验。

 MCGS触摸屏在野0day利用,强制卡死锁屏)


)











(含题库教师学生账号))


