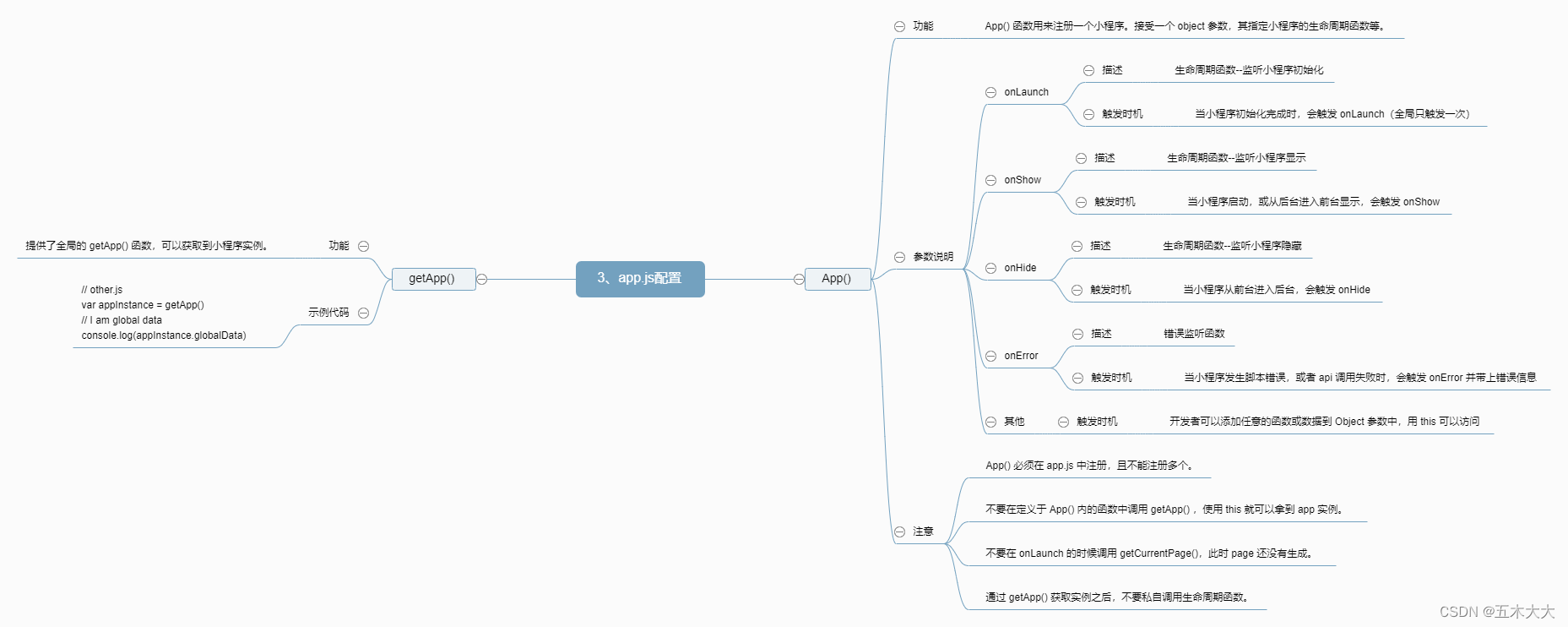
我们可以把语言模型分为两类:
- 自动回归式语言模型:自动回归式语言模型在本质上是单向的,也就是说,它只沿着一个方向阅读句子。正向(从左到右)预测;反向(从右到左)预测。
- 自动编码式语言模型:自动编码式语言模型同时利用了正向预测和反向预测的优势。在进行预测时,它会同时从两个方向阅读句子,所以自动编码式语言模型是双向的。
本文将结合具体模型和论文,探讨这两种模型的损失函数。
一、自动编码式语言模型
提到自动编码式语言模型,那最经典的非BERT莫属了。
1.1 BERT
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的自然语言处理模型。它由Google于2018年提出,以解决语境相关性和双向理解的问题。BERT采用双向训练方式,能够同时考虑文本左右两侧的上下文信息,有效捕获语境含义。
BERT的损失函数由两部分组成,第一部分是来自 Mask-LM 的单词级别分类任务,另一部分是句子级别的分类任务。通过这两个任务的联合学习,可以使得 BERT 学习到的表征既有 token 级别信息,同时也包含了句子级别的语义信息。
在第一部分的损失函数中,如果被 mask 的词集合为 M(即计算BERT的MLM loss时会忽略没被mask的token),因为它是一个词典大小 |V| 上的多分类问题,那么具体说来有:
在句子预测任务中,也是一个分类问题的损失函数:
这两个损失函数也很容易理解:
- 多分类问题,类别的数量等于词表的大小,第
个词被正确预测的概率越大,相应的损失越小
- 二分类问题,第
个句子的类别被正确预测的概率越大,相应的损失越小
因此,两个任务联合学习的损失函数是:
二、自动回归式语言模型
BERT一度引领了NLP领域。但是随着OpenAI-GPT系列模型的爆火,自回归式模型被更为广泛的采用。本章详细解析GLM大模型、LoRA微调方法、Prefix tuning这三篇论文中的损失函数。以期找到这些损失函数的共性。
2.1 GLM系列大模型
清华大学提出的GLM大模型预训练框架采用了自回归的空白填充方法,在自然语言理解、无条件生成、有条件生成等NLP任务上取得了显著成果。其中,GLM-130B是最大的模型,拥有1300亿参数,支持中英文双语,旨在训练出开源开放的高精度千亿中英双语语言模型。该模型采用了量化技术,可在4块3090(24G)或8块2080Ti(11G)上推理。
输入向量为,抽样出文本段
,每个文本段
都代表了一系列连续的token吗,可以写做
,每个文本段
都用[MASK]代表,从而形成了
。
表示抽样文本段的数量,
表示每个抽样文本段的长度。预训练目标可以用下式表示:
需要对所有的抽样文本段进行随机打乱, 是
被打乱后,所有可能性的集合,
又可以写作
。在预测缺失的文本段
时(每个
都包含多个单词,所以需要用集合S表示,
作为下标),模型可以访问到被破坏的文本
,以及
前面所有的抽样文本段。
那每个中token的预测概率应该如何表示呢?如下:
很简单,把所有token的概率乘起来就可以了。
需要注意的是,这边要弄清楚和
的区别:
代表第
- 由于
有很多种打乱方式,
表示其中某一个打乱方式的第
2.2 LoRA
以上是针对GLM这系列特殊的模型。那么对于一般的自回归式模型,有没有更普遍的一种表达方式呢?我们以LoRA这篇文章为例。
每一个下游任务都能用 内容-目标对来表示:,
和
都是token序列。例如在自然语言->sql语句任务中,
是自然语言查询,
是其相应的SQL命令。对于概括任务而言,
是文章的内容,
是其相应的概述内容。预训练的自回归语言模型可以用
来表示。那么微调就是要找到一组参数
,使得下式最大:
即用前的所有样本来预测第
个样本。
三、参考文献
[1] Devlin J , Chang M W , Lee K ,et al.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.
[2] Du Z , Qian Y , Liu X ,et al.GLM: General Language Model Pretraining with Autoregressive Blank Infilling[J]. 2021.DOI:10.48550/arXiv.2103.10360.
[3] Zeng, Aohan, et al. "Glm-130b: An open bilingual pre-trained model." arXiv preprint arXiv:2210.02414 (2022).
[4] Hu E J , Shen Y , Wallis P ,et al.LoRA: Low-Rank Adaptation of Large Language Models[J]. 2021.DOI:10.48550/arXiv.2106.09685.