基于 U-Net 的视网膜血管分割是一种应用深度学习的方法,特别是 U-Net 结构,用于从眼底图像中分割出视网膜血管。U-Net 是一种全卷积神经网络(FCN),通常用于图像分割任务。以下是基于 U-Net 的视网膜血管分割的内容:
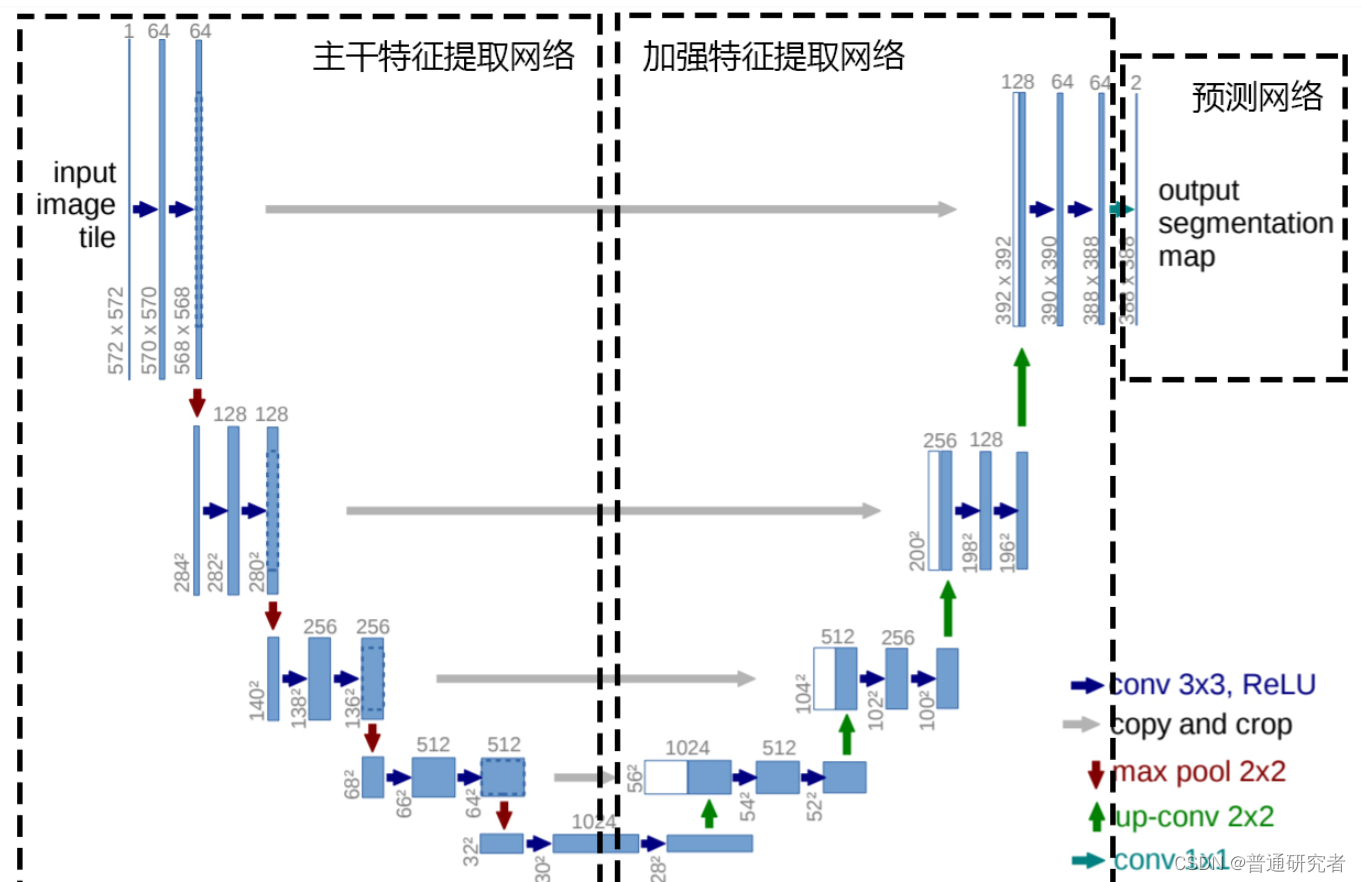
框架结构:
代码结构:
U-Net分割代码:
unet_model.py
import torch.nn.functional as F
from .unet_parts import *
class UNet(nn.Module):def __init__(self, n_channels, n_classes, bilinear=True):super(UNet, self).__init__()self.n_channels = n_channelsself.n_classes = n_classesself.bilinear = bilinearself.inc = DoubleConv(n_channels, 64)self.down1 = Down(64, 128)self.down2 = Down(128, 256)self.down3 = Down(256, 512)self.down4 = Down(512, 512)self.up1 = Up(1024, 256, bilinear)self.up2 = Up(512, 128, bilinear)self.up3 = Up(256, 64, bilinear)self.up4 = Up(128, 64, bilinear)self.outc = OutConv(64, n_classes)def forward(self, x):x1 = self.inc(x)# 在编码器下采样过程加空间注意力# x2 = self.down1(self.sp1(x1))# x3 = self.down2(self.sp2(x2))# x4 = self.down3(self.sp3(x3))# x5 = self.down4(self.sp4(x4))x2 = self.down1(x1)x3 = self.down2(x2)x4 = self.down3(x3)x5 = self.down4(x4)x = self.up1(x5, x4)x = self.up2(x, x3)x = self.up3(x, x2)x = self.up4(x, x1)logits = self.outc(x)return logitsif __name__ == '__main__':net = UNet(n_channels=3, n_classes=1)print(net)
unet_parts.py
import torch
import torch.nn as nn
import torch.nn.functional as Fclass DoubleConv(nn.Module):"""(convolution => [BN] => ReLU) * 2"""def __init__(self, in_channels, out_channels):super().__init__()self.double_conv = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.constant_(m.bias, 0)def forward(self, x):return self.double_conv(x)class Down(nn.Module):"""Downscaling with maxpool then double conv"""def __init__(self, in_channels, out_channels):super().__init__()self.maxpool_conv = nn.Sequential(nn.MaxPool2d(2),DoubleConv(in_channels, out_channels))def forward(self, x):return self.maxpool_conv(x)class Up(nn.Module):"""Upscaling then double conv"""def __init__(self, in_channels, out_channels, bilinear=True):super().__init__()# if bilinear, use the normal convolutions to reduce the number of channelsif bilinear:self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)else:self.up = nn.ConvTranspose2d(in_channels // 2, in_channels // 2, kernel_size=2, stride=2)self.conv = DoubleConv(in_channels, out_channels)def forward(self, x1, x2):x1 = self.up(x1)# input is CHWdiffY = torch.tensor([x2.size()[2] - x1.size()[2]])diffX = torch.tensor([x2.size()[3] - x1.size()[3]])x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,diffY // 2, diffY - diffY // 2])x = torch.cat([x2, x1], dim=1)return self.conv(x)class OutConv(nn.Module):def __init__(self, in_channels, out_channels):super(OutConv, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.constant_(m.bias, 0)def forward(self, x):return self.conv(x)
trainval.py
from model.unet_model import UNet
from utils.dataset import FundusSeg_Loaderfrom torch import optim
import torch.nn as nn
import torch
import sys
import matplotlib.pyplot as plt
from tqdm import tqdm
import timetrain_data_path = "DRIVE/drive_train/"
valid_data_path = "DRIVE/drive_test/"
# hyperparameter-settings
N_epochs = 500
Init_lr = 0.00001def train_net(net, device, epochs=N_epochs, batch_size=1, lr=Init_lr):# 加载训练集train_dataset = FundusSeg_Loader(train_data_path, 1)valid_dataset = FundusSeg_Loader(valid_data_path, 0)train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)valid_loader = torch.utils.data.DataLoader(dataset=valid_dataset, batch_size=batch_size, shuffle=False)print('Traing images: %s' % len(train_loader))print('Valid images: %s' % len(valid_loader))# 定义RMSprop算法optimizer = optim.RMSprop(net.parameters(), lr=lr, weight_decay=1e-8, momentum=0.9)# 定义Loss算法# BCEWithLogitsLoss会对predict进行sigmoid处理# criterion 常被用来定义损失函数,方便调换损失函数criterion = nn.BCEWithLogitsLoss()# 训练epochs次# 求最小值,所以初始化为正无穷best_loss = float('inf')train_loss_list = []val_loss_list = []for epoch in range(epochs):# 训练模式net.train()train_loss = 0print(f'Epoch {epoch + 1}/{epochs}')# SGD# train_loss_list = []# val_loss_list = []with tqdm(total=train_loader.__len__()) as pbar:for i, (image, label, filename) in enumerate(train_loader):optimizer.zero_grad()# 将数据拷贝到device中image = image.to(device=device, dtype=torch.float32)label = label.to(device=device, dtype=torch.float32)# 使用网络参数,输出预测结果pred = net(image)# print(pred)# 计算lossloss = criterion(pred, label)# print(loss)train_loss = train_loss + loss.item()loss.backward()optimizer.step()pbar.set_postfix(loss=float(loss.cpu()), epoch=epoch)pbar.update(1)train_loss_list.append(train_loss / i)print('Loss/train', train_loss / i)# Validationnet.eval()val_loss = 0for i, (image, label, filename) in tqdm(enumerate(valid_loader), total=len(valid_loader)):image = image.to(device=device, dtype=torch.float32)label = label.to(device=device, dtype=torch.float32)pred = net(image)loss = criterion(pred, label)val_loss = val_loss + loss.item()# net.state_dict()就是用来保存模型参数的if val_loss < best_loss:best_loss = val_losstorch.save(net.state_dict(), 'best_model.pth')print('saving model............................................')val_loss_list.append(val_loss / i)print('Loss/valid', val_loss / i)sys.stdout.flush()return val_loss_list, train_loss_listif __name__ == "__main__":# 选择设备cudadevice = torch.device('cuda')# 加载网络,图片单通道1,分类为1。net = UNet(n_channels=3, n_classes=1)# 将网络拷贝到deivce中net.to(device=device)# 开始训练val_loss_list, train_loss_list = train_net(net, device)# 保存loss值到txt文件fileObject1 = open('train_loss.txt', 'w')for train_loss in train_loss_list:fileObject1.write(str(train_loss))fileObject1.write('\n')fileObject1.close()fileObject2 = open('val_loss.txt', 'w')for val_loss in val_loss_list:fileObject2.write(str(val_loss))fileObject2.write('\n')fileObject2.close()# 我这里迭代了5次,所以x的取值范围为(0,5),然后再将每次相对应的5损失率附在x上x = range(0, N_epochs)y1 = val_loss_listy2 = train_loss_list# 两行一列第一个plt.subplot(1, 1, 1)plt.plot(x, y1, 'r.-', label=u'val_loss')plt.plot(x, y2, 'g.-', label =u'train_loss')plt.title('loss')plt.xlabel('epochs')plt.ylabel('loss')plt.savefig("accuracy_loss.jpg")plt.show()
predict.py
import numpy as np
import torch
import cv2
from model.unet_model import UNetfrom utils.dataset import FundusSeg_Loader
import copy
from sklearn.metrics import roc_auc_scoremodel_path='./best_model.pth'
test_data_path = "DRIVE/drive_test/"
save_path='./results/'if __name__ == "__main__":test_dataset = FundusSeg_Loader(test_data_path,0)test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=1, shuffle=False)print('Testing images: %s' %len(test_loader))# 选择设备CUDAdevice = torch.device('cuda')# 加载网络,图片单通道,分类为1。net = UNet(n_channels=3, n_classes=1)# 将网络拷贝到deivce中net.to(device=device)# 加载模型参数print(f'Loading model {model_path}')net.load_state_dict(torch.load(model_path, map_location=device))# 测试模式net.eval()tp = 0tn = 0fp = 0fn = 0pred_list = []label_list = []for image, label, filename in test_loader:image = image.to(device=device, dtype=torch.float32)pred = net(image)# Normalize to [0, 1]pred = torch.sigmoid(pred)pred = np.array(pred.data.cpu()[0])[0]pred_list.append(pred)# ConfusionMAtrixpred_bin = copy.deepcopy(pred)label = np.array(label.data.cpu()[0])[0]label_list.append(label)pred_bin[pred_bin >= 0.5] = 1pred_bin[pred_bin < 0.5] = 0tp += ((pred_bin == 1) & (label == 1)).sum()tn += ((pred_bin == 0) & (label == 0)).sum()fn += ((pred_bin == 0) & (label == 1)).sum()fp += ((pred_bin == 1) & (label == 0)).sum()# 保存图片pred = pred * 255save_filename = save_path + filename[0] + '.png'cv2.imwrite(save_filename, pred)print(f'{save_filename} done!')# Evaluaiton Indicatorsprecision = tp / (tp + fp) # 预测为真并且正确/预测正确样本总和sen = tp / (tp + fn) # 预测为真并且正确/正样本总和spe = tn / (tn + fp)acc = (tp + tn) / (tp + tn + fp + fn)f1score = 2 * precision * sen / (precision + sen)# auc computingpred_auc = np.stack(pred_list, axis=0)label_auc = np.stack(label_list, axis=0)auc = roc_auc_score(label_auc.reshape(-1), pred_auc.reshape(-1))print(f'Precision: {precision} Sen: {sen} Spe:{spe} F1-score: {f1score} Acc: {acc} AUC: {auc}')
dataset.py
import torch
import cv2
import os
import glob
from torch.utils.data import Dataset# import random
# from PIL import Image
# import numpy as npclass FundusSeg_Loader(Dataset):def __init__(self, data_path, is_train):# 初始化函数,读取所有data_path下的图片self.data_path = data_pathself.imgs_path = glob.glob(os.path.join(data_path, 'image/*.tif'))self.labels_path = glob.glob(os.path.join(data_path, 'label/*.tif'))self.is_train = is_trainprint(self.imgs_path)print(self.labels_path)def __getitem__(self, index):# 根据index读取图片image_path = self.imgs_path[index]if self.is_train == 1:label_path = image_path.replace('image', 'label')label_path = label_path.replace('training', 'manual1')else:label_path = image_path.replace('image', 'label')label_path = label_path.replace('test.tif', 'manual1.tif')# 读取训练图片和标签图片image = cv2.imread(image_path)label = cv2.imread(label_path)# image = np.array(image)# label = np.array(label)# label = cv2.imread(label_path)# image = cv2.resize(image, (600,400))# label = cv2.resize(label, (600,400))# 转为单通道的图片# image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)label = cv2.cvtColor(label, cv2.COLOR_BGR2GRAY)# label = Image.fromarray(label)# label = label.convert("1")# reshape()函数可以改变数组的形状,并且原始数据不发生变化。image = image.transpose(2, 0, 1)# image = image.reshape(1, label.shape[0], label.shape[1])label = label.reshape(1, label.shape[0], label.shape[1])# 处理标签,将像素值为255的改为1if label.max() > 1:label[label > 1] = 1return image, label, image_path[len(image_path)-12:len(image_path)-4]def __len__(self):# 返回训练集大小return len(self.imgs_path)
visual.py
import numpy as np
import matplotlib.pyplot as plt
import pylab as plfrom mpl_toolkits.axes_grid1.inset_locator import inset_axes
data1_loss =np.loadtxt("E:\\code\\UNet_lr00001\\train_loss.txt",dtype=str )
data2_loss = np.loadtxt("E:\\code\\UNet_lr00001\\val_loss.txt",dtype=str)
x = range(0,10)
y = data1_loss[:, 0]
x1 = range(0,10)
y1 = data2_loss[:, 0]
fig = plt.figure(figsize = (7,5)) #figsize是图片的大小`
ax1 = fig.add_subplot(1, 1, 1) # ax1是子图的名字`
pl.plot(x,y,'g-',label=u'Dense_Unet(block layer=5)')
# ‘'g‘'代表“green”,表示画出的曲线是绿色,“-”代表画的曲线是实线,可自行选择,label代表的是图例的名称,一般要在名称前面加一个u,如果名称是中文,会显示不出来,目前还不知道怎么解决。
p2 = pl.plot(x, y,'r-', label = u'train_loss')
pl.legend()
#显示图例
p3 = pl.plot(x1,y1, 'b-', label = u'val_loss')
pl.legend()
pl.xlabel(u'epoch')
pl.ylabel(u'loss')
plt.title('Compare loss for different models in training')
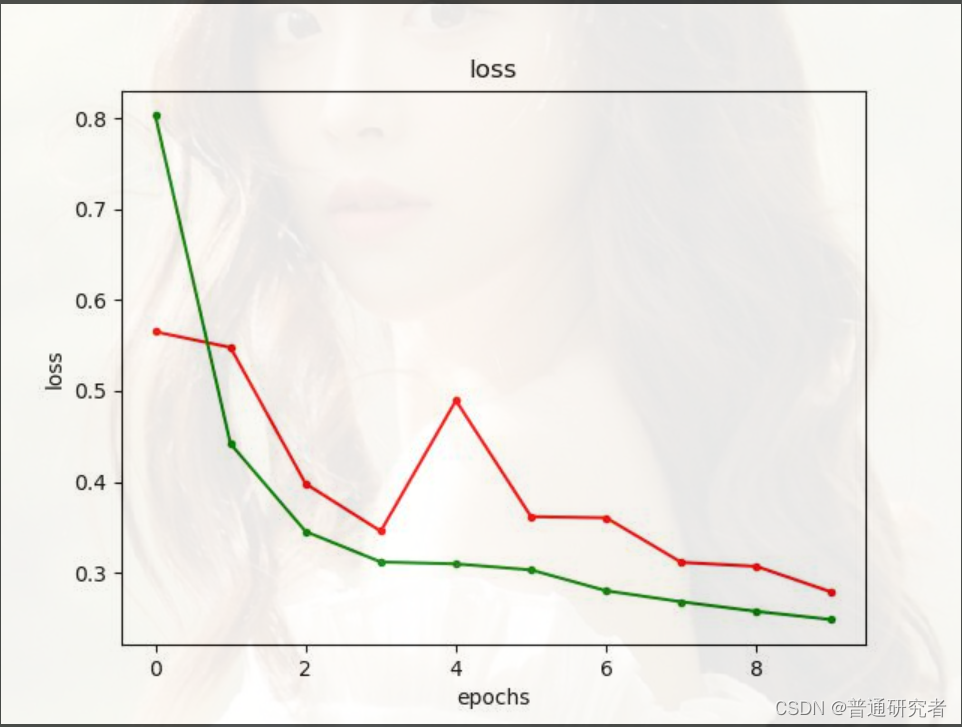
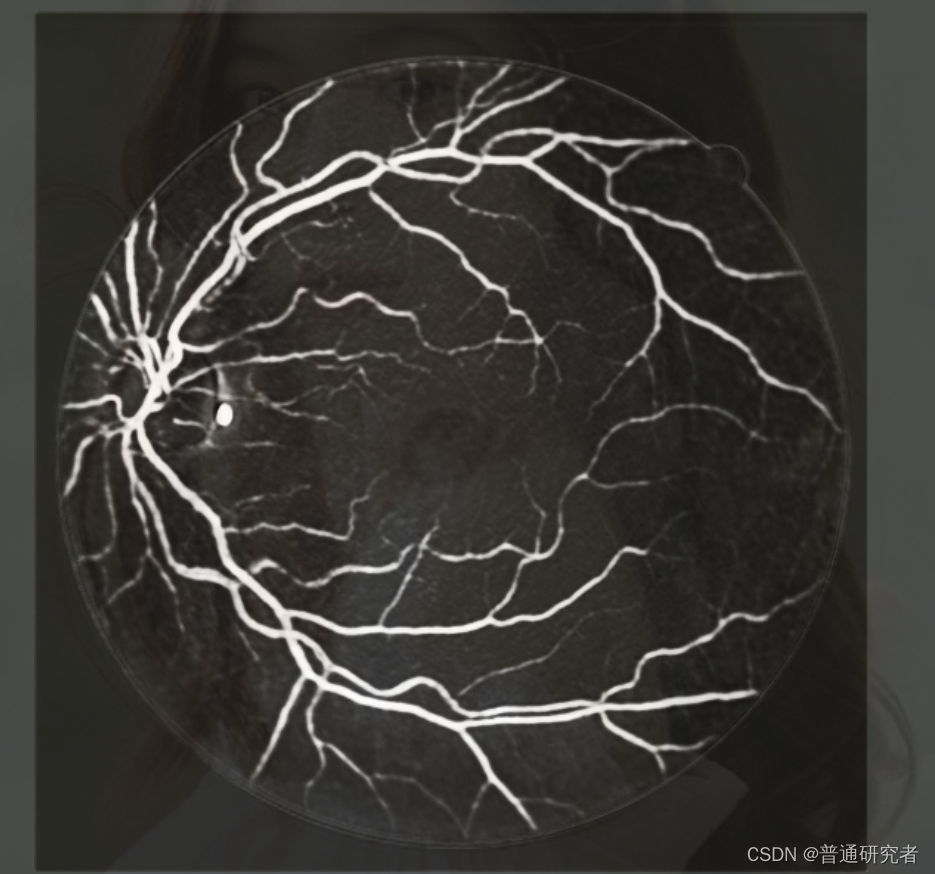
这种基于 U-Net 的方法已在医学图像分割领域取得了一些成功,特别是在视网膜图像处理中。通过深度学习的方法,这种技术能够更准确地提取视网膜血管,为眼科医生提供辅助诊断和治疗的信息。
如有疑问,请评论。

)




:树搜索指定数据域的结点(算法FindTarget))



)

-ipcz系统代码实现-同Node通信)
)


通过MQTT连接华为云)


