
论文地址:官方论文地址
代码地址:官方代码地址

一、本文介绍
在这篇文章中,我们将讲解如何将LSKAttention大核注意力机制应用于YOLOv8,以实现显著的性能提升。首先,我们介绍LSKAttention机制的基本原理,它主要通过将深度卷积层的2D卷积核分解为水平和垂直1D卷积核,减少了计算复杂性和内存占用。接着,我们介绍将这一机制整合到YOLOv8的方法,以及它如何帮助提高处理大型数据集和复杂视觉任务的效率和准确性。本文还将提供代码实现细节和使用方法,展示这种改进对目标检测、语义分割等方面的积极影响。通过实验YOLOv8在整合LSKAttention机制后,实现了检测精度提升(下面会附上改进LSKAttention机制和基础版本的结果对比图)。
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
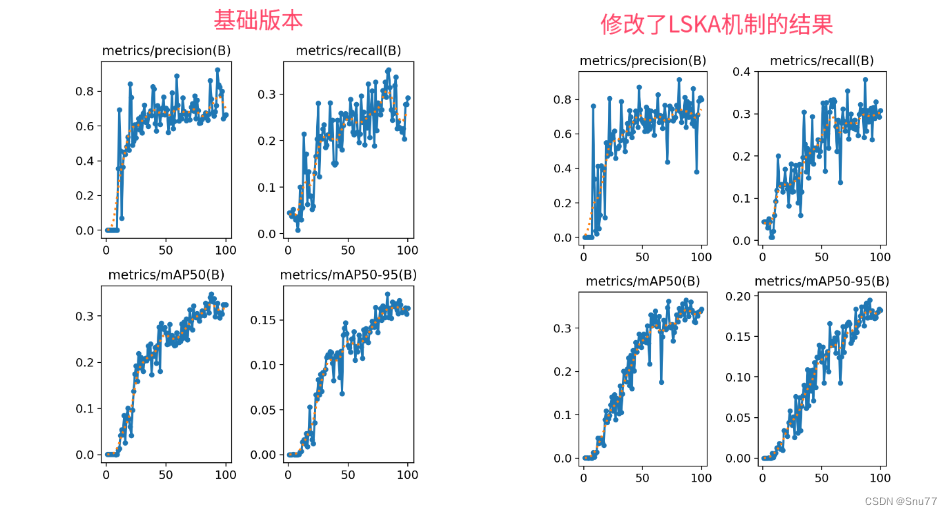
实验效果图如下所示->
本次实验我只用了一百张图片检测的是安全帽训练了一百个epoch,该结果只能展示出该机制有效,但是并不能产生决定性结果,因为具体的效果还要看你的数据集和实验环境所影响。
目录
一、本文介绍
二、LSKAttention的机制原理
三、LSKAttention的代码
四、手把手教你将LSKAttention添加到你的网络结构中
4.1 LSKAttention的添加教程
4.2 LSKAttention的yaml文件和训练截图
4.2.1 LSKAttention的yaml文件
4.2.2 LSKAttention的训练过程截图
五、LSKAttention可添加的位置
5.1 推荐LSKAttention可添加的位置
5.2图示LSKAttention可添加的位置
六、本文总结
二、LSKAttention的机制原理
《Large Separable Kernel Attention》这篇论文提出的LSKAttention的机制原理是针对传统大核注意力(Large Kernel Attention,LKA)模块在视觉注意网络(Visual Attention Networks,VAN)中的应用问题进行的改进。LKA模块在处理大尺寸卷积核时面临着高计算和内存需求的挑战。LSKAttention通过以下几个关键步骤和原理来解决这些问题:
-
核分解:LSKAttention的核心创新是将传统的2D卷积核分解为两个1D卷积核。首先,它将一个大的2D核分解成水平(横向)和垂直(纵向)的两个1D核。这样的分解大幅降低了参数数量和计算复杂度。
-
串联卷积操作:在进行卷积操作时,LSKAttention首先使用一个1D核对输入进行水平方向上的卷积,然后使用另一个1D核进行垂直方向上的卷积。这两步卷积操作串联执行,从而实现了与原始大尺寸2D核相似的效果。
-
计算效率提升:由于分解后的1D卷积核大大减少了参数的数量,LSKAttention在执行时的计算效率得到显著提升。这种方法特别适用于处理大尺寸的卷积核,能够有效降低内存占用和计算成本。
-
保持效果:虽然采用了分解和串联的策略,LSKAttention仍然能够保持类似于原始LKA的性能。这意味着在处理图像的关键特征(如边缘、纹理和形状)时,LSKAttention能够有效地捕捉到重要信息。
-
适用于多种任务:LSKAttention不仅在图像分类任务中表现出色,还能够在目标检测、语义分割等多种计算机视觉任务中有效应用,显示出其广泛的适用性。
总结:LSKAttention通过创新的核分解和串联卷积策略,在降低计算和内存成本的同时,保持了高效的图像处理能力,这在处理大尺寸核和复杂图像数据时特别有价值。
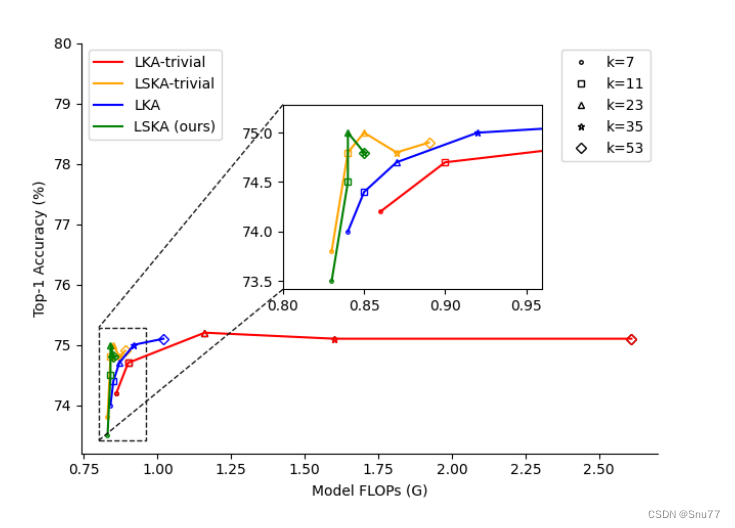
上图展示了在不同大核分解方法和核大小下的速度-精度权衡。在这个比较中,使用了不同的标记来代表不同的核大小,并且以VAN-Tiny作为对比的模型。从图中可以看出,LKA的朴素设计(LKA-trivial)以及在VAN中的实际设计,在核大小增加时会导致更高的GFLOPs(十亿浮点运算次数)。相比之下,论文提出的LSKA(Large Separable Kernel Attention)-trivial和VAN中的LSKA在核大小增加时显著降低了GFLOPs,同时没有降低性能

上图展示了大核注意力模块不同设计的比较,具体包括:
- LKA-trivial:朴素的2D大核深度卷积(DW-Conv)与1×1卷积结合(图a)。
- LSKA-trivial:串联的水平和垂直1D大核深度卷积与1×1卷积结合(图b)。
- 原始LKA设计:在VAN中包括标准深度卷积(DW-Conv)、扩张深度卷积(DW-D-Conv)和1×1卷积(图c)。
- 提出的LSKA设计:将LKA的前两层分解为四层,每层由两个1D卷积层组成(图d)。其中,N代表Hadamard乘积,k代表最大感受野,d代表扩张率。
个人总结:提出了一种创新的大型可分离核注意力(LSKA)模块,用于改进卷积神经网络(CNN)。这种模块通过将2D卷积核分解为串联的1D核,有效降低了计算复杂度和内存需求。LSKA模块在保持与标准大核注意力(LKA)模块相当的性能的同时,显示出更高的计算效率和更小的内存占用。
三、LSKAttention的代码
将下面的代码在"ultralytics/nn/modules" 目录下创建一个py文件复制粘贴进去然后按照章节四进行添加即可(需要按照有参数的注意力机制添加)。
import torch
import torch.nn as nnclass LSKA(nn.Module):def __init__(self, dim, k_size):super().__init__()self.k_size = k_sizeif k_size == 7:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,(3-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=((3-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,2), groups=dim, dilation=2)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=(2,0), groups=dim, dilation=2)elif k_size == 11:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 3), stride=(1,1), padding=(0,(3-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(3, 1), stride=(1,1), padding=((3-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,4), groups=dim, dilation=2)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=(4,0), groups=dim, dilation=2)elif k_size == 23:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 7), stride=(1,1), padding=(0,9), groups=dim, dilation=3)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(7, 1), stride=(1,1), padding=(9,0), groups=dim, dilation=3)elif k_size == 35:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 11), stride=(1,1), padding=(0,15), groups=dim, dilation=3)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(11, 1), stride=(1,1), padding=(15,0), groups=dim, dilation=3)elif k_size == 41:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 13), stride=(1,1), padding=(0,18), groups=dim, dilation=3)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(13, 1), stride=(1,1), padding=(18,0), groups=dim, dilation=3)elif k_size == 53:self.conv0h = nn.Conv2d(dim, dim, kernel_size=(1, 5), stride=(1,1), padding=(0,(5-1)//2), groups=dim)self.conv0v = nn.Conv2d(dim, dim, kernel_size=(5, 1), stride=(1,1), padding=((5-1)//2,0), groups=dim)self.conv_spatial_h = nn.Conv2d(dim, dim, kernel_size=(1, 17), stride=(1,1), padding=(0,24), groups=dim, dilation=3)self.conv_spatial_v = nn.Conv2d(dim, dim, kernel_size=(17, 1), stride=(1,1), padding=(24,0), groups=dim, dilation=3)self.conv1 = nn.Conv2d(dim, dim, 1)def forward(self, x):u = x.clone()attn = self.conv0h(x)attn = self.conv0v(attn)attn = self.conv_spatial_h(attn)attn = self.conv_spatial_v(attn)attn = self.conv1(attn)return u * attn
四、手把手教你将LSKAttention添加到你的网络结构中
4.1 LSKAttention的添加教程
添加教程这里不再重复介绍、因为专栏内容有许多,添加过程又需要截特别图片会导致文章大家读者也不通顺如果你已经会添加注意力机制了,可以跳过本章节,如果你还不会,大家可以看我下面的文章,里面详细的介绍了拿到一个任意机制(C2f、Conv、Bottleneck、Loss、DetectHead)如何添加到你的网络结构中去。
添加教程->YOLOv8改进 | 如何在网络结构中添加注意力机制、C2f、卷积、Neck、检测头
需要注意的是本文的task.py配置的代码如下(你现在不知道其是干什么用的可以看添加教程)->
elif m in {LSKA}:args = [ch[f], *args]
4.2 LSKAttention的yaml文件和训练截图
4.2.1 LSKAttention的yaml文件
参数位置可以填写的有7、11、23、35、41、53(代表卷积核的大小),具体哪个效果好可能要大家自己进行一定的尝试才可以,需要注意的是这里卷积核越大计算量就会变得越大。
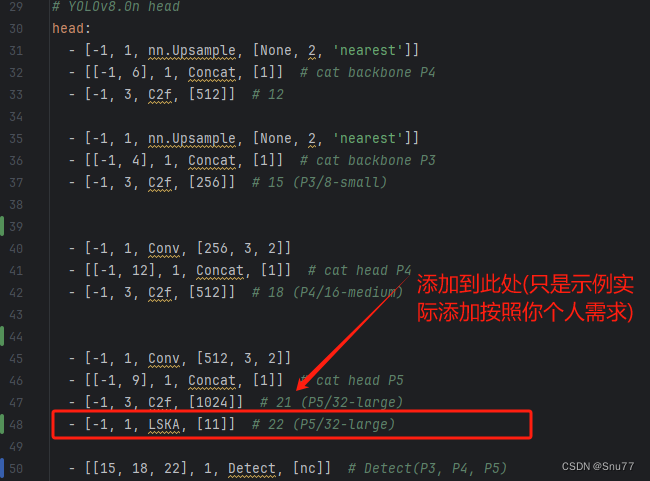
4.2.2 LSKAttention的训练过程截图
下面是我添加了LSKAttention的训练截图。
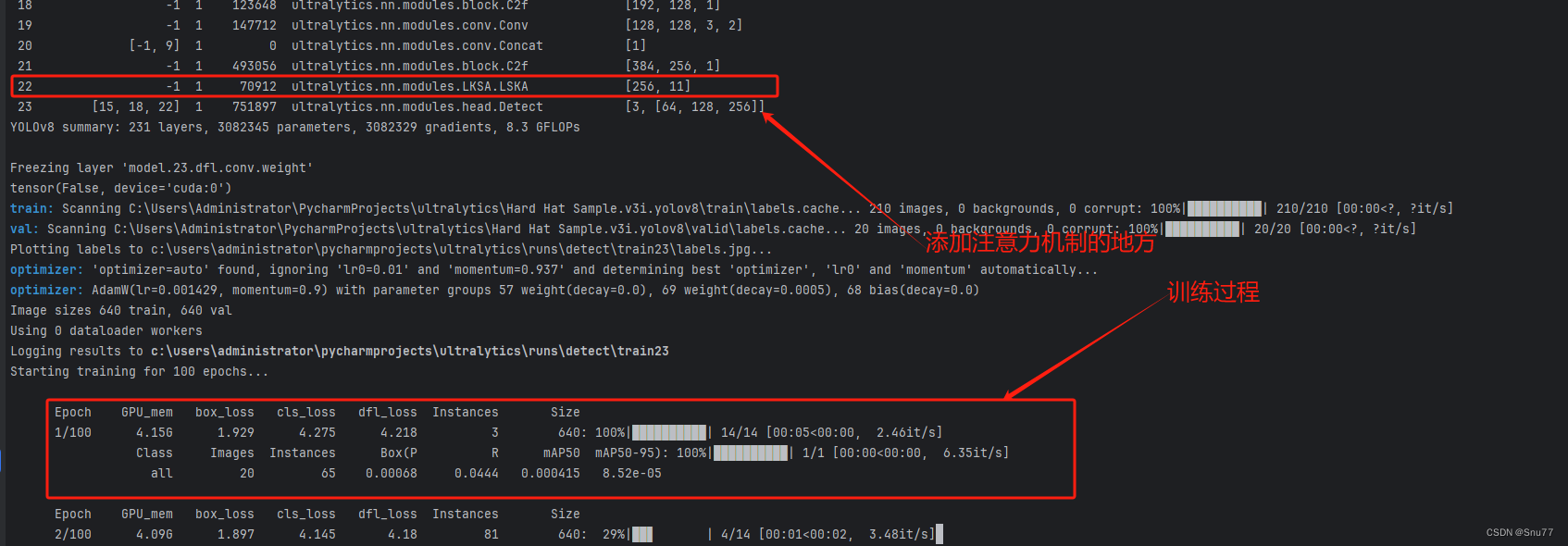
五、LSKAttention可添加的位置
5.1 推荐LSKAttention可添加的位置
LSKAttention可以是一种即插即用的注意力机制,其可以添加的位置有很多,添加的位置不同效果也不同,所以我下面推荐几个添加的位,置大家可以进行参考,当然不一定要按照我推荐的地方添加。
残差连接中:在残差网络的残差连接中加入注意力机制(这个位置我推荐的原因是因为DCN放在残差里面效果挺好的大家可以尝试)
特征金字塔(SPPF):在特征金字塔网络之前,可以帮助模型更好地融合不同尺度的特征。
Neck部分:YOLOv8的Neck部分负责特征融合,这里添加注意力机制可以帮助模型更有效地融合不同层次的特征。
输出层前:在最终的输出层前加入注意力机制可以使模型在做出最终预测之前,更加集中注意力于最关键的特征。
大家可能看我描述不太懂,大家可以看下面的网络结构图中我进行了标注。
5.2图示LSKAttention可添加的位置

六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备








)

)









