导读:本文是“数据拾光者”专栏的第六十六篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇主要介绍使用chatgpt类LLM进行数据标注任务并蒸馏到生产小模型,对于希望使用chatgpt类LLM进行打标并部署到生产任务中的小伙伴可能有帮助。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
摘要:本篇主要介绍使用chatgpt类LLM进行数据标注任务并蒸馏到生产小模型。首先介绍了背景,通过知识蒸馏技术可以利用LLM模型来标注数据,再将标注数据应用到生产模型中,不仅可以提升效果,而且还能保持线上生产模型的性能;然后重点介绍了论文中提出的蒸馏方法,包括论文摘要、技术架构、用LLM标注的原因、基于LLM进行上下文学习、实验设置以及结果分析。对于希望使用chatgpt类LLM进行打标并部署到生产任务中的小伙伴可能有帮助。
下面主要按照如下思维导图进行学习分享:
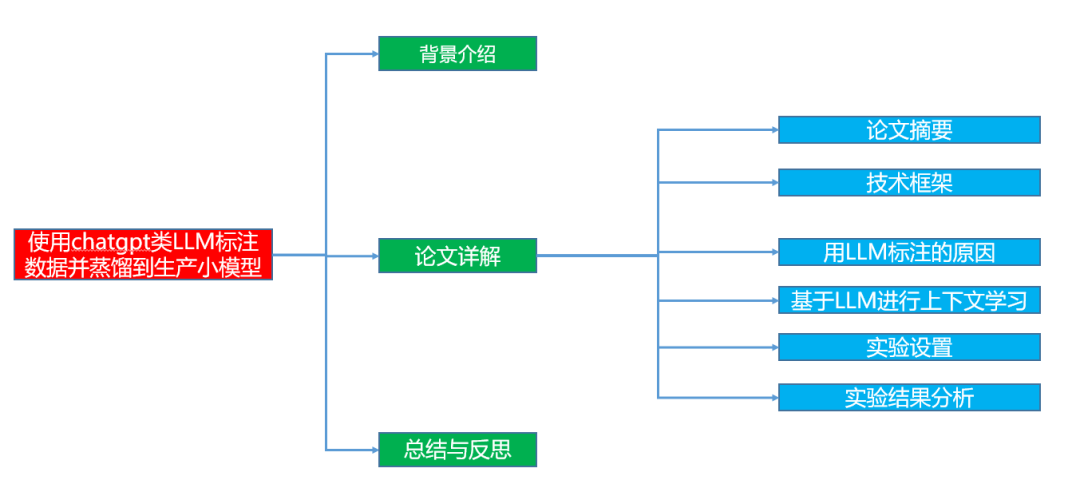
1.背景介绍
随着chatgpt大火,这一类大语言模型LLM因为效果好和应用范围广在学术界和工业界受到越来越多的关注。我们团队也打算将chatgpt应用到实际的业务场景中,其中一个很有价值的方向就是数据标注。比如像文本分类、关键词抽取等任务,构建模型时都依赖人工标注数据,而标注数据数量的多少和质量的好坏会直接影响模型的效果。我们之前主要是在线上采样一些数据提交给专门的标注团队进行标注,现在chatgpt出来之后我们希望能将打标这个任务交给LLM来做,这样就可以用极少的成本来打标数据。
有些小伙伴可能会想,既然chatgpt在文本分类和关键词任抽取任务上已经效果很好了,为啥不直接应用到线上任务呢?一个原因是对于一些线上性能要求很高的场景,chatgpt这一类大语言模型可能很难满足线上延时要求;还有一个很重要的原因是请求chatgpt接口是根据token付费的,直接接入业务成本太高了。所以一个比较靠谱的方案是,用chatgpt帮我们打标数据,然后用打标的数据使用常规的方法比如BERT、fasttext来训练模型。这样对于线上任务来说并不会有太大的影响,还能利用chatgpt的能力来帮助我们提升效果。
2.论文详解
本篇主要介绍WWW 2023论文《What do LLMs Know about Financial Markets? A Case Study on Reddit Market Sentiment Analysis》[1]中提出通过LLM模型来标注数据从而将知识蒸馏到生产中的小模型上。
2.1 论文摘要
在金融市场情感分析任务中,由于需要了解金融市场和相关行业术语,对于人工标注要求极高,获取高质量的标注样本是一项很有挑战的任务。而高质量的标注数据会直接影响金融市场情感模型效果的好坏。在这种情况下作者提出利用chatgpt这一类LLM模型涌现的知识能力来标注数据,然后将标注的数据使用到生产中的小模型上。通过manual few-shot COT+ self-consistency的prompt组合技来获取弱标签数据,然后通过蒸馏的方式将LLM模型学习到的知识迁移到生产中用到的小模型,可以提升分类效果,同时保持现有生产模型的性能。
2.2 技术框架
论文整体框架如下图所示:
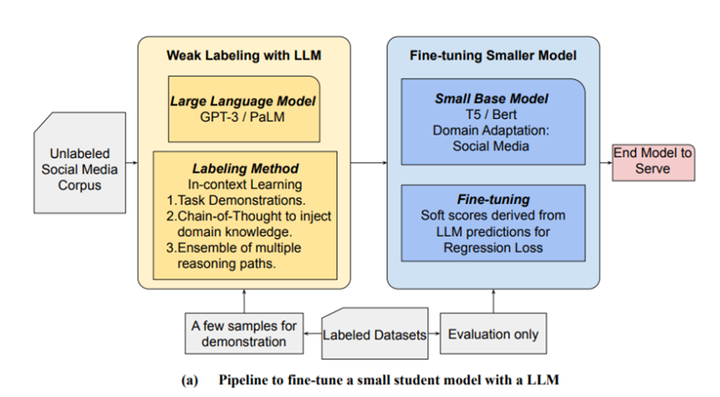
第一步:利用LLM打标数据获得弱标签数据weakly labeled data。
论文中LLM模型使用的是GPT-3或者PaLM模型。随着LLM模型效果越来越好,可以使用效果更好chatgpt、gpt4或者其他更好的LLM模型。使用基于上下文学习的打标方法,主要包括以下几部分:
任务描述;
使用思维链COT注入领域知识;
通过多次生成得到不同推理路径的打标结果。
第二步:在弱标签数据上使用生产小模型训练分类器。
使用LLM对多次打标的样本数据获取弱标签得到标注数据集,通过知识蒸馏技术将知识迁移到BERT和T5这一类小模型上训练分类器。
第三步:线上构建端到端模型应用到生产任务中。
2.3 用LLM标注的原因
因为社交媒体中的金融情感分析任务使用有监督学习模型需要一定数量的标注数据,而这些标注数据需要了解金融市场和相关行业术语,所以对人工标注要求极高,获取高质量的标注样本是一项很有挑战的任务。为了降低标注难度,节约标注人力,希望利用LLM模型涌现的知识能力来打标数据,通过知识蒸馏技术将LLM模型学习到的知识迁移到生产中的小模型,从而提升线上效果的同时,还能保持生产的性能。
2.4 基于LLM进行上下文学习
论文作者经过优化实践,提出了一套prompt组合技:manual few-shot COT + self-consistency相结合:
(1)manual few-shot COT
在prompt工程中,通过few-shot方法,对于每类标签人工采样一些示例,使用思维链COT技术。COT最初的设计目的是通过显式指示模型生成中间推理步骤来提高LLM的多步推理能力,使用 COT 使 LLM 总结金融相关论点 ,从而隐含地迫使模型回忆相关的金融领域知识。即总结对股票涨跌的观点,然后再给出最终答案。prompt设计如下所示:
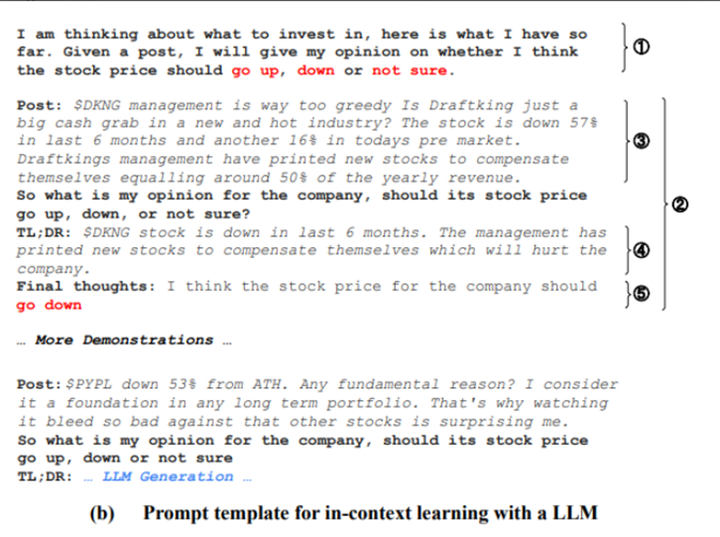
上图中各部分介绍:
[1]任务描述:模拟任务设置并使LLM模型熟悉目标领域。比如:我正在考虑投资点什么,下面是我所拥有的信息。输入一条信息,我会对股价上涨、下跌和不确定发表看法;
[2]一个完整的示例:通过一个或多个输入输出示例说明任务
-
[3]输入文本信息。比如:$DKNG 管理层太贪婪了,Draftking 只是在一个新的热门行业中攫取大量现金吗?该股在过去 6 个月内下跌了 57%,今天盘前又下跌了 16%。Draftkings 管理层印制了新股票来补偿自己,相当于年收入的 50% 左右。
[4]推理流程。比如:$DKNG 股票在过去 6 个月中下跌。管理层印制新股票来补偿自己,这将损害公司。
[5]结论。比如:我认为公司的股价应该下跌
-
(2)self-consistency
因为LLM在生成打标结果时存在一定的随机性,同时用户经常在帖子中引用多个可能相互冲突的论点,可能产生不同的推理路径,所以论文会对样本进行多次重复打标得到弱标签数据。
2.5 实验设置
论文作者对金融主体的情感分析任务进行了一定的改造,转化成了预测股票涨跌的任务。如果情绪是积极的,则股票要涨;如果情绪是消极的,则股票要跌;如果情绪是中立的,则股票涨跌不确定。对任务的改造主要原因是让任务更加具体可理解一些,这样更有利于设计prompt。
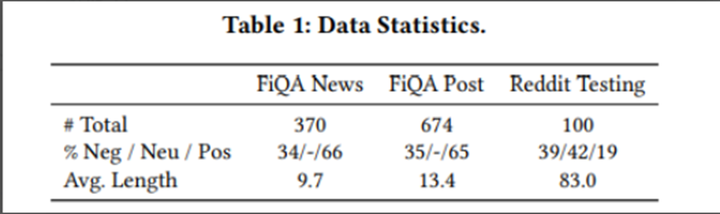
数据集方面主要有三个:
FiQA News:带有新闻标题的FiQA-News
FiQA Post:带有 Twitter和 Stocktwits 微博的 FiQA-Post
Reddit:使用由专有主题分类器标记为与金融相关的 Reddit 帖子
数据集相关信息如下图所示:
对照组baseline模型主要有两类:
· 第一类是字符集的T5模型Charformer (CF),分别使用FiQA News和FiQA Post数据集进行微调;
· 第二类是两种广泛使用的现有市场情绪模型:FinBERT-HKUST 和 FinBERTProsusAI。
实验组有两个:
第一个是PaLM × 8,使用大语言模型PaLM-540B,使用思维链COT,8代表self-consistency中sample的次数,也就是重复预测8次;
第二个是CF - Distilled PaLM,将PaLM作为老师模型蒸馏到学生模型CF中。
2.6 实验结果分析
2.6.1 整体实验
下面是整体实验结果:
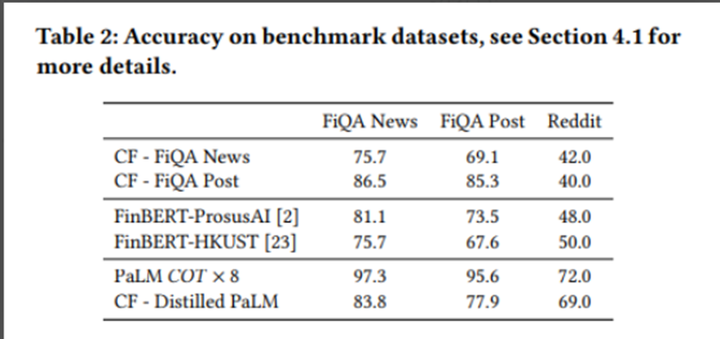
从上面的实验结果可以看出:
(1)在三个数据集上PaLM × 8效果是最好的,也论证了大语言模型PaLM不仅效果好,而且应用范围也很广;
(2)使用CF在FiQA Post数据集进行微调之后的模型在FiQA News和FiQA Post两个数据集上效果很好,说明用业务相关数据集微调预训练模型是有效的。但是在Reddit上效果很差,不具有迁移性;
(3)CF - Distilled PaLM整体来看虽然不如PaLM × 8,但相比于对照组也提升很多。使用Reddit数据集蒸馏模型,在FiQA News和FiQA Post两个数据集上效果也不错,说明可以很好的迁移。
2.6.2 大语言模型上下文学习消融实验
论文还对大语言模型上下文学习进行了消融实验,下图对比了COT、self-consistency中sample的次数和PaLM大语言模型参数量对效果的影响:
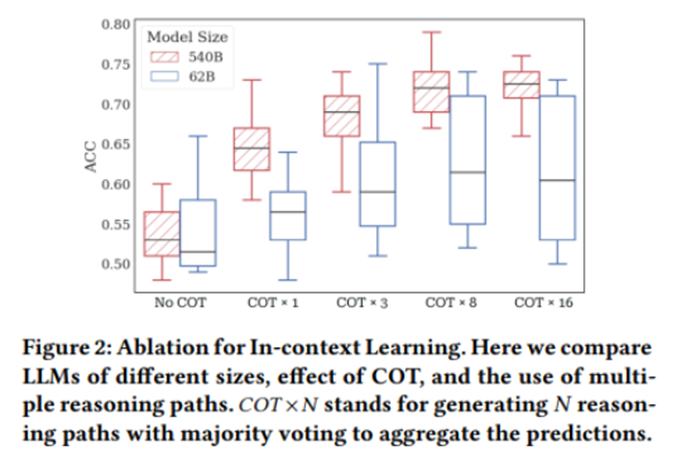
从上图中可以看出:首先,使用COT技术可以明显提升分类效果;然后,使用参数量更大的PaLM模型明显可以提升分类效果;最后,随着self-consistency中sample的次数不断增加,分类效果提升明显,但是增加到一定次数之后(论文中是8)模型效果不会一直提升,相反可能还会有轻微下降。
2.6.3 蒸馏方式实验
论文中作者将PaLM蒸馏到CF模型上时使用了两种蒸馏方式获取弱标签:
classification(CLS):通过投票法将每个样本出现次数最多的标签作为hard label;
regression(RGR) loss:每个样本会sample多次,将多次打标结果的标签分布作为soft label,通过regression loss(MSE)来学习。比如对于一条样本来说,重复生成8次分类结果,其中positive为5,negtive为1,neural为2,那么将5/8、1/8、2/8作为soft label去训练模型。
作者使用PaLM模型生成打标结果时会重复生成8次,实验对比了一致性大于等于5的样本时使用两种不同的蒸馏方式对分类效果的影响:
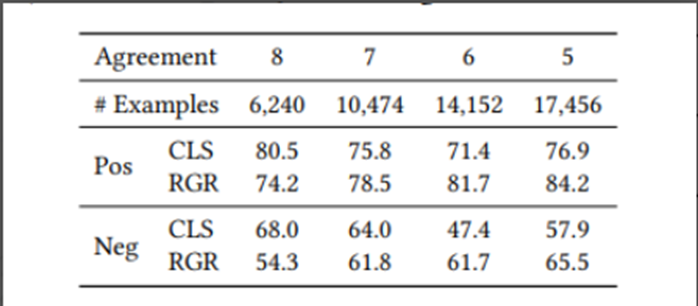
从上图中可以发现:
一致性越高,可以使用的样本越少。当设置一致性阈值为8时,可使用的样本仅为6240;而设置一致性阈值为5时可以使用的样本为17456;
使用CLS方式时,一致性越高的样本分类效果越好,使用8次预测一致的样本分类效果最好;
使用RGR方式时,一致性越低,可以使用更多的样本,分类效果最好,使用5次预测一致的样本分类效果最好。
下面画出了两种蒸馏方式效果最好时CLS-8和RGR-5的PR曲线(CLS使用一致性为8、RGR使用一致性为5):
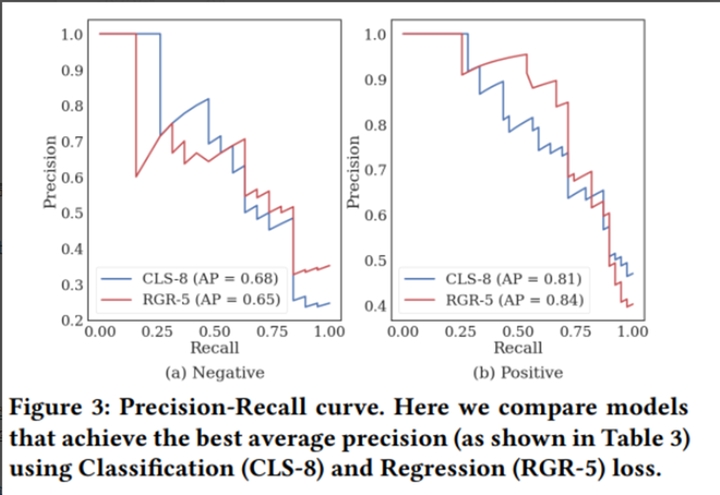
论文作者最后选择使用RGR方式进行蒸馏,主要原因是RGR可以使用更多更难的数据用于训练模型,可以提升模型的泛化能力。还有个原因就是RGR的PR曲线更加平滑一些。线上部署时可以根据p来选择r,这个也比较适合咱们的业务场景,比如模型评估是根据p为0.8时设置阈值来查看r。
2.6.4 错误分析
论文作者使用CF-Distilled PaLM在Reddit数据集上绘制了混淆矩阵:
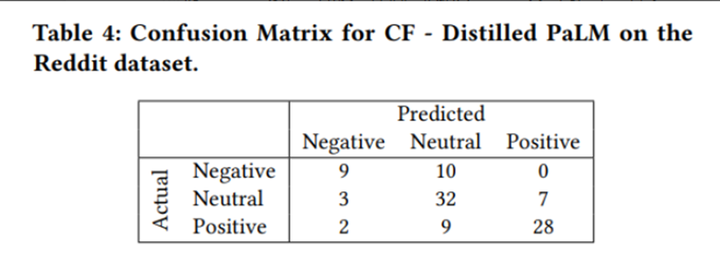
从混淆矩阵中可以看出模型对于Negative和Positive两个标签之间识别效果较好,主要容易将这两个标签和Neutral进行混淆。
03 总结与反思
本篇主要介绍使用chatgpt类LLM进行数据标注任务并蒸馏到生产小模型。首先介绍了背景,通过知识蒸馏技术可以利用LLM模型来标注数据,再将标注数据应用到生产模型中,不仅可以提升效果,而且还能保持线上生产模型的性能;然后重点介绍了论文中提出的蒸馏方法,包括论文摘要、技术架构、用LLM标注的原因、基于LLM进行上下文学习、实验设置以及结果分析。对于希望使用chatgpt类LLM进行打标并部署到生产任务中的小伙伴可能有帮助。
参考资料
【1】What do LLMs Know about Financial Markets? A Case Study on Reddit Market Sentiment Analysis: https://arxiv.org/pdf/2212.11311.pdf
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。
码字不易,欢迎小伙伴们点赞和分享。

)





)


)


)

-deque介绍)
![[原创]解决老款AMD CPU在Win10/Win11无故重启的问题.](http://pic.xiahunao.cn/[原创]解决老款AMD CPU在Win10/Win11无故重启的问题.)


