🎄欢迎来到@边境矢梦°的csdn博文🎄
🎄本文主要梳理 Java 框架 中 SpringMVC的知识点和值得注意的地方 🎄
🌈我是边境矢梦°,一个正在为秋招和算法竞赛做准备的学生🌈
🎆喜欢的朋友可以关注一下🫰🫰🫰,下次更新不迷路🎆
目录
- MyBatis是什么
- MyBatis和Hibernateの区别
- **自己实现** MyBatis 底层机制
- 了解MyBatis
- 源码的debug
- MyBatis注解
- 动态SQL
- 映射关系
- MyBatis执行SQL的两种方式
- 执行器随记
- 缓存
- 两个缓存的事
- Ehcache

MyBatis是什么
开源
轻量级(相比于Hibernate)
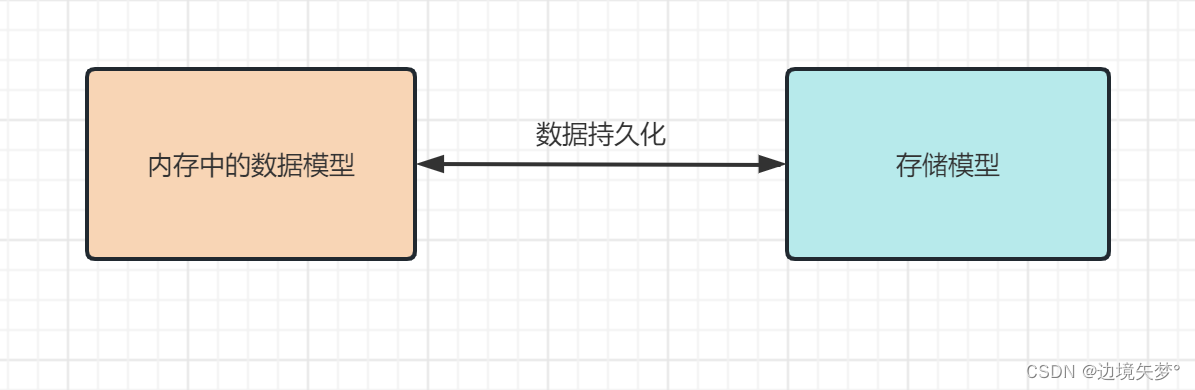
数据持久化框架
简化了JDBC(加载驱动, 创建连接, 创建statement)
 MyBatis 支持定制化 SQL、存储过程以及高级映射,可以在实体类和 SQL 语句之间建立映射关系,是一种半自动化的 ORM 实现。其封装性低于 Hibernate,但性能优秀、小巧、简单易学、应用广泛。
MyBatis 支持定制化 SQL、存储过程以及高级映射,可以在实体类和 SQL 语句之间建立映射关系,是一种半自动化的 ORM 实现。其封装性低于 Hibernate,但性能优秀、小巧、简单易学、应用广泛。
ORM(Object Relational Mapping,对象关系映射)是一种数据持久化技术,它在对象模型和关系型数据库之间建立起对应关系,并且提供了一种机制,通过 JavaBean 对象去操作数据库表中的数据。
MyBatis 的主要思想是将程序中的大量 SQL 语句剥离出来,使用 XML 文件或注解的方式实现 SQL 的灵活配置,将 SQL 语句与程序代码分离,在不修改程序代码的情况下,直接在配置文件中修改 SQL 语句。
MyBatis 与其它持久性框架最大的不同是,MyBatis 强调使用 SQL,而其它框架(例如 Hibernate)通常使用自定义查询语言,即 HQL(Hibernate查询语言)或 EJB QL(Enterprise JavaBeans查询语言)。
优点
- MyBatis 是免费且开源的。
- 与 JDBC 相比,减少了 50% 以上的代码量。
- MyBatis 是最简单的持久化框架,小巧并且简单易学。
- MyBatis 相当灵活,不会对应用程序或者数据库的现有设计强加任何影响,SQL 写在 XML 中,和程序逻辑代码分离,降低耦合度,便于同一管理和优化,提高了代码的可重用性。
- 提供 XML 标签,支持编写动态 SQL 语句。
- 提供映射标签,支持对象与数据库的 ORM 字段关系映射。
- 支持存储过程。MyBatis 以存储过程的形式封装 SQL,可以将业务逻辑保留在数据库之外,增强应用程序的可移植性、更易于部署和测试。
缺点
- 编写 SQL 语句工作量较大,对开发人员编写 SQL 语句的功底有一定要求。
- SQL 语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。
MyBatis和Hibernateの区别
Hibernate 和 MyBatis 都是目前业界中主流的对象关系映射(ORM)框架,它们的主要区别如下。
1)sql 优化方面
- Hibernate 使用 HQL(Hibernate Query Language)语句,独立于数据库。不需要编写大量的 SQL,就可以完全映射,但会多消耗性能,且开发人员不能自主的进行 SQL 性能优化。提供了日志、缓存、级联(级联比 MyBatis 强大)等特性。
- MyBatis 需要手动编写 SQL,所以灵活多变。支持动态 SQL、处理列表、动态生成表名、支持存储过程。工作量相对较大。
2)开发方面
- MyBatis 是一个半自动映射的框架,因为 MyBatis 需要手动匹配 POJO 和 SQL 的映射关系。
- Hibernate 是一个全表映射的框架,只需提供 POJO 和映射关系即可。

- 3)缓存机制比较
Hibernate 的二级缓存配置在 SessionFactory 生成的配置文件中进行详细配置,然后再在具体的表-对象映射中配置缓存。
MyBatis 的二级缓存配置在每个具体的表-对象映射中进行详细配置,这样针对不同的表可以自定义不同的缓存机制。并且 Mybatis 可以在命名空间中共享相同的缓存配置和实例,通过 Cache-ref 来实现。
Hibernate 对查询对象有着良好的管理机制,用户无需关心 SQL。所以在使用二级缓存时如果出现脏数据,系统会报出错误并提示。而 MyBatis 在这一方面,使用二级缓存时需要特别小心。如果不能完全确定数据更新操作的波及范围,避免 Cache 的盲目使用。否则脏数据的出现会给系统的正常运行带来很大的隐患。
4)Hibernate 优势
- Hibernate 的 DAO 层开发比 MyBatis 简单,Mybatis 需要维护 SQL 和结果映射。
- Hibernate 对对象的维护和缓存要比 MyBatis 好,对增删改查的对象的维护要方便。
- Hibernate 数据库移植性很好,MyBatis 的数据库移植性不好,不同的数据库需要写不同 SQL。
- Hibernate 有更好的二级缓存机制,可以使用第三方缓存。MyBatis 本身提供的缓存机制不佳。
5)Mybatis优势
- MyBatis 可以进行更为细致的 SQL 优化,可以减少查询字段。
- MyBatis 容易掌握,而 Hibernate 门槛较高。
6)应用场景
MyBatis 适合需求多变的互联网项目,例如电商项目、金融类型、旅游类、售票类项目等。
Hibernate 适合需求明确、业务固定的项目,例如 OA 项目、ERP 项目和 CRM 项目等。
总结
总的来说,MyBatis 是一个小巧、方便、高效、简单、直接、半自动化的持久层框架,Hibernate 是一个强大、方便、高效、复杂、间接、全自动化的持久层框架。
对于性能要求不太苛刻的系统,比如管理系统、ERP 等推荐使用 Hibernate,而对于性能要求高、响应快、灵活的系统则推荐使用 MyBatis。
自己实现 MyBatis 底层机制
了解MyBatis
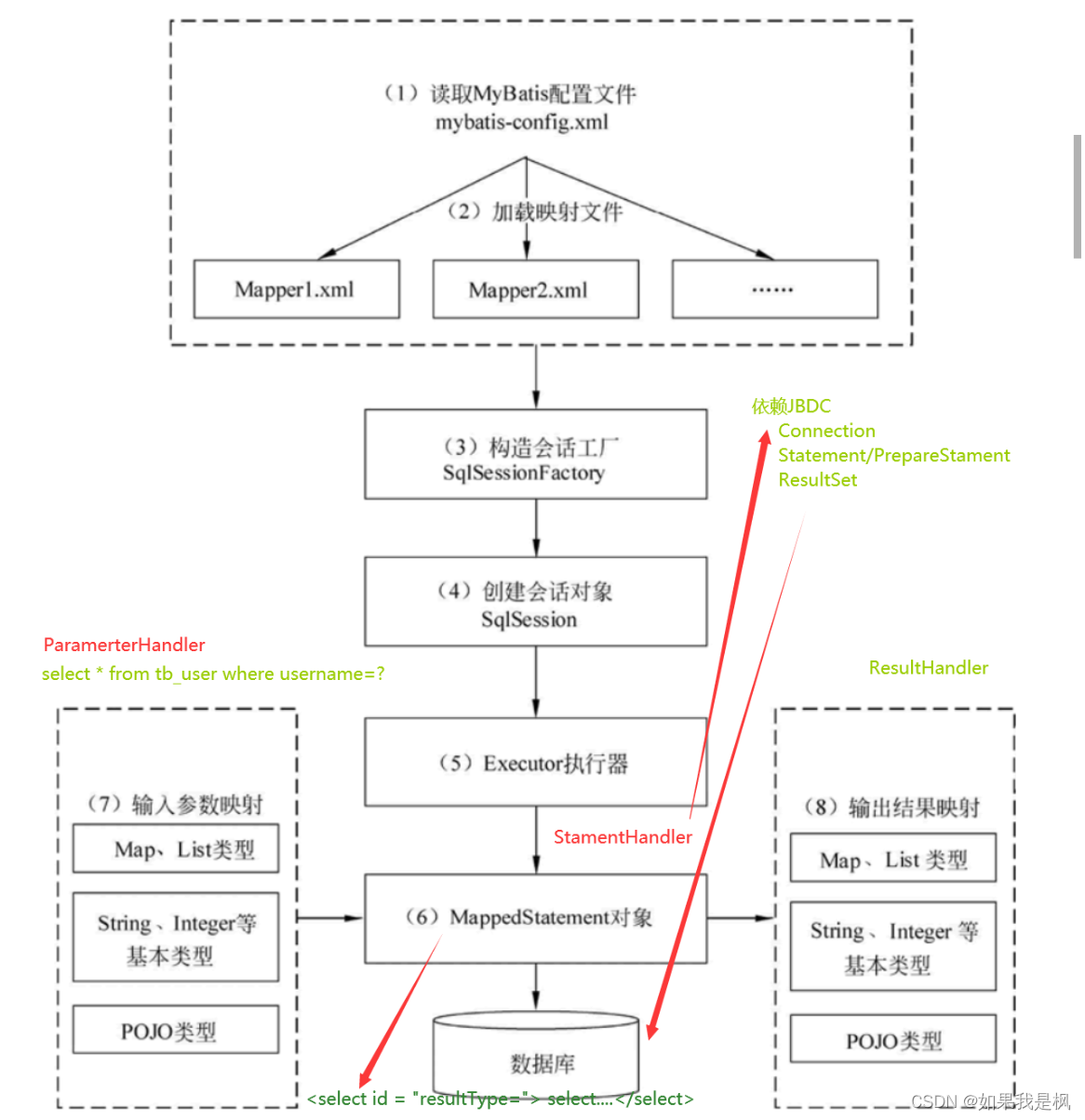
MyBatis(以前称为iBATIS)是一个Java持久性框架,它提供了一种将SQL查询与Java对象映射起来的方式,使数据库访问更加方便。MyBatis的底层原理涉及到以下几个重要方面:
SQL映射文件(XML配置文件):MyBatis的配置是通过XML文件进行的,其中包括SQL语句的定义、参数映射、结果集映射等信息。SQL映射文件描述了如何将Java对象与数据库表之间进行映射,以及如何执行SQL语句。SqlSessionFactory:SqlSessionFactory是MyBatis的核心接口,它负责创建SqlSession对象。SqlSessionFactory的实现通常是通过XML配置文件或Java代码来配置的,它包含了数据库连接池信息、事务管理器等信息。SqlSession:SqlSession是MyBatis的工作单元,它负责执行SQL语句并管理数据库连接。每个线程通常都会有一个SqlSession对象,它可以用来执行SQL语句、提交事务、关闭连接等操作。Mapper接口:Mapper接口是Java接口,它定义了与数据库交互的方法,这些方法与SQL语句相关联。Mapper接口的实现通常由MyBatis动态代理生成,它会将接口方法与SQL语句进行绑定,使得在调用接口方法时可以执行相应的SQL语句。TypeHandler:TypeHandler负责将Java对象和数据库中的数据类型进行转换。MyBatis提供了一些默认的TypeHandler,同时也可以自定义TypeHandler以处理特定的数据类型转换。缓存:MyBatis支持两种类型的缓存:一级缓存和二级缓存。一级缓存是SqlSession级别的缓存,它可以减少数据库访问次数。二级缓存是全局的,多个SqlSession可以共享二级缓存中的数据,以减轻数据库压力。
MyBatis的工作流程通常如下:
- 通过SqlSessionFactory创建SqlSession对象。
- 调用SqlSession的Mapper方法,执行SQL语句。
- MyBatis将SQL语句与Mapper接口方法进行映射,生成真正的SQL语句,并执行数据库操作。
- 结果数据经过TypeHandler进行转换,并返回给调用者。
- 如果启用了缓存,MyBatis会在缓存中查找结果,如果缓存中有数据,就直接返回,否则将数据存入缓存。
- 最后,SqlSession需要关闭,关闭时会提交事务或回滚事务,同时释放数据库连接。
总的来说,MyBatis的底层原理涉及了SQL语句映射、数据库连接管理、事务管理、数据类型转换等方面,它提供了一种灵活而强大的方式来进行数据库访问,并且可以通过XML配置文件或Java代码来定制化配置。
Executor与XxxMapper.xml
MyBatis中的Executor和XxxxMapper.xml(通常是指XML配置文件,比如UserMapper.xml)之间有密切的关系,它们共同协作来执行SQL语句和映射结果。下面我会详细解释它们之间的关系:
-
XxxxMapper.xml文件:这是MyBatis中用于定义SQL语句和映射的XML配置文件,其中包含了SQL语句的定义、参数映射、结果集映射等信息。这些XML文件中定义了与数据库交互的具体SQL操作,如SELECT、INSERT、UPDATE、DELETE等。XxxxMapper.xml文件通常定义了一个或多个Mapper接口对应的SQL操作。举例来说,如果你有一个
UserMapper.java接口,那么相应的UserMapper.xml文件可能包含了与用户数据相关的SQL操作。 -
Executor:Executor是MyBatis中的一个关键组件,它负责执行SQL语句。Executor的主要任务是接收XxxxMapper.xml文件中定义的SQL语句,执行这些SQL语句,处理结果集,并将结果返回给调用者。在MyBatis中,有两种主要类型的
Executor:- SimpleExecutor:它简单地执行SQL语句,不支持高级功能如缓存和批处理。
- ReuseExecutor:它支持SQL语句的重用,可以在同一个SqlSession中多次执行相同的SQL语句,提高了性能。
Executor与XxxxMapper.xml之间的关系可以总结如下:
- 当你在Java代码中调用
XxxxMapper接口的方法时,MyBatis会根据XxxxMapper.xml文件中的配置来构建SQL语句。 - 这个SQL语句将由
Executor执行,Executor负责将SQL语句发送到数据库,获取结果集,并将结果映射成Java对象(如果有相应的结果映射配置)。 Executor在执行SQL语句之前还会负责一些事务管理和连接管理的工作,确保数据库操作的一致性和可靠性。- 最后,
Executor将执行结果返回给XxxxMapper接口的方法调用者。
总之,Executor是MyBatis中用于执行SQL语句的核心组件,而XxxxMapper.xml文件用于定义SQL语句和结果映射的配置。它们一起工作,使得你可以通过Mapper接口的方法来执行数据库操作,而无需编写大量的SQL语句和繁琐的结果映射代码。
MyBatis 是一个开源的持久层框架,它的底层具体原理主要包括以下几个方面:
SQL 解析与执行:MyBatis 使用 SQL 解析器来解析 XML 配置文件中定义的 SQL 语句,将其转换为对应的数据结构,包括 SQL 语句类型、参数、返回类型等。通过 JDBC 驱动程序执行对应的 SQL 语句,并处理结果集的映射。映射器(Mapper):MyBatis 使用映射器来处理与数据库交互的逻辑。映射器是一个接口,在 Java 代码中定义数据库操作的方法。MyBatis 通过映射器将方法与 XML 配置文件中的 SQL 语句进行关联,并处理 SQL 语句的执行和结果的映射。对象关系映射(ORM):MyBatis 提供了对象关系映射的功能,将数据库表的记录映射为 Java 对象,并将 Java 对象的属性映射为数据库表的字段。通过映射器和映射配置,可以实现对象与表之间的转换,提供方便的 CRUD 操作。缓存管理:MyBatis 的缓存机制可以提高查询性能。它会缓存查询结果,避免重复查询数据库。MyBatis 通过缓存管理器来管理缓存,可以配置不同级别的缓存策略,如一级缓存(本地缓存)和二级缓存(分布式缓存),以及全局缓存。事务管理:MyBatis 可以与事务管理器进行集成,进行事务的提交、回滚和回滚点的设置。它可以与各种事务管理器进行配合,如 JDBC 事务、Spring 事务等。
总的来说,MyBatis 的底层原理包括 SQL 解析与执行、映射器、对象关系映射(ORM)、缓存管理以及事务管理等。通过这些机制,MyBatis 实现了方便灵活的数据库交互和持久化操作,同时提供了缓存和事务管理等功能,以便于开发者能够更高效地进行数据库操作。
源码的debug
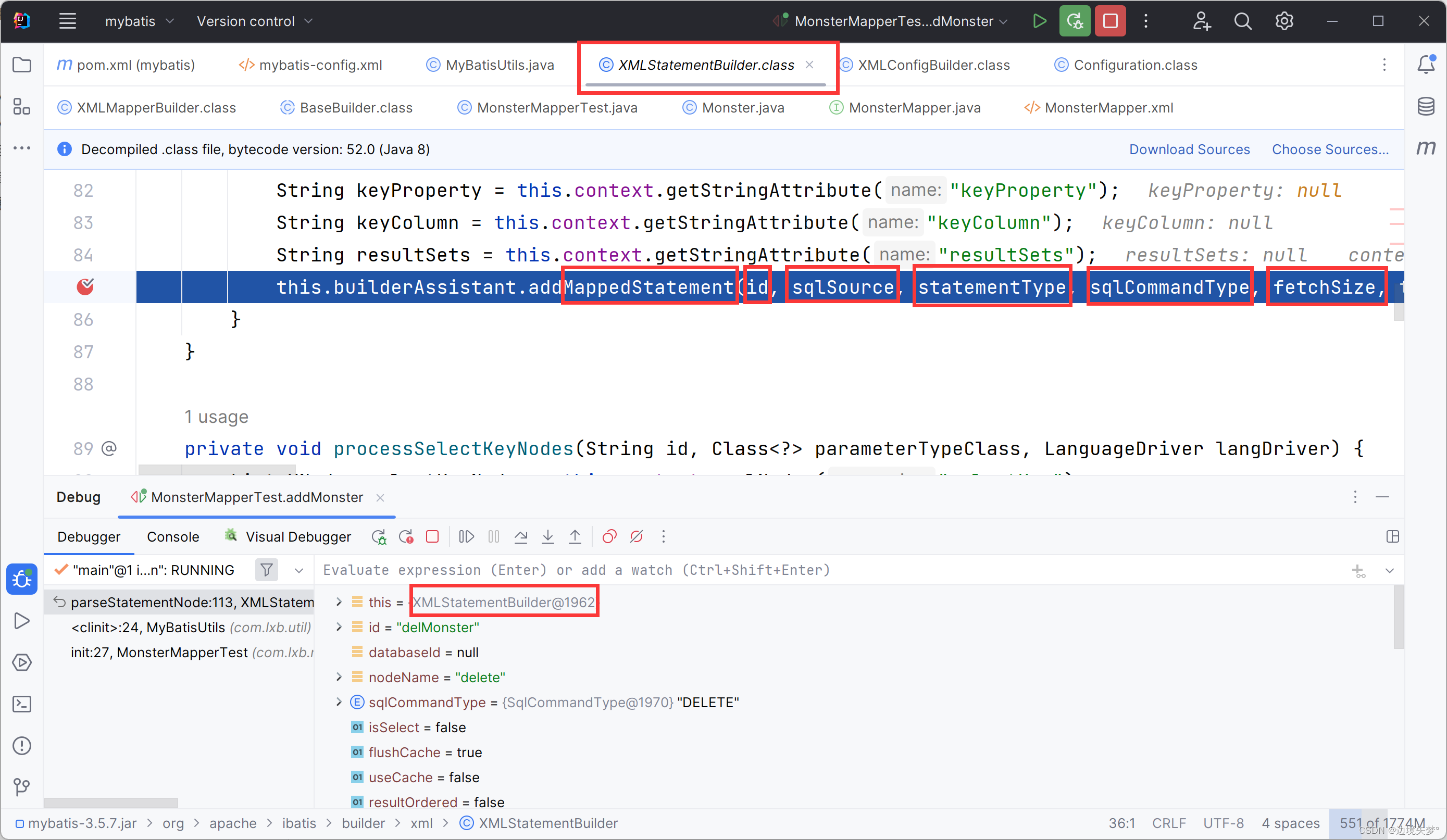
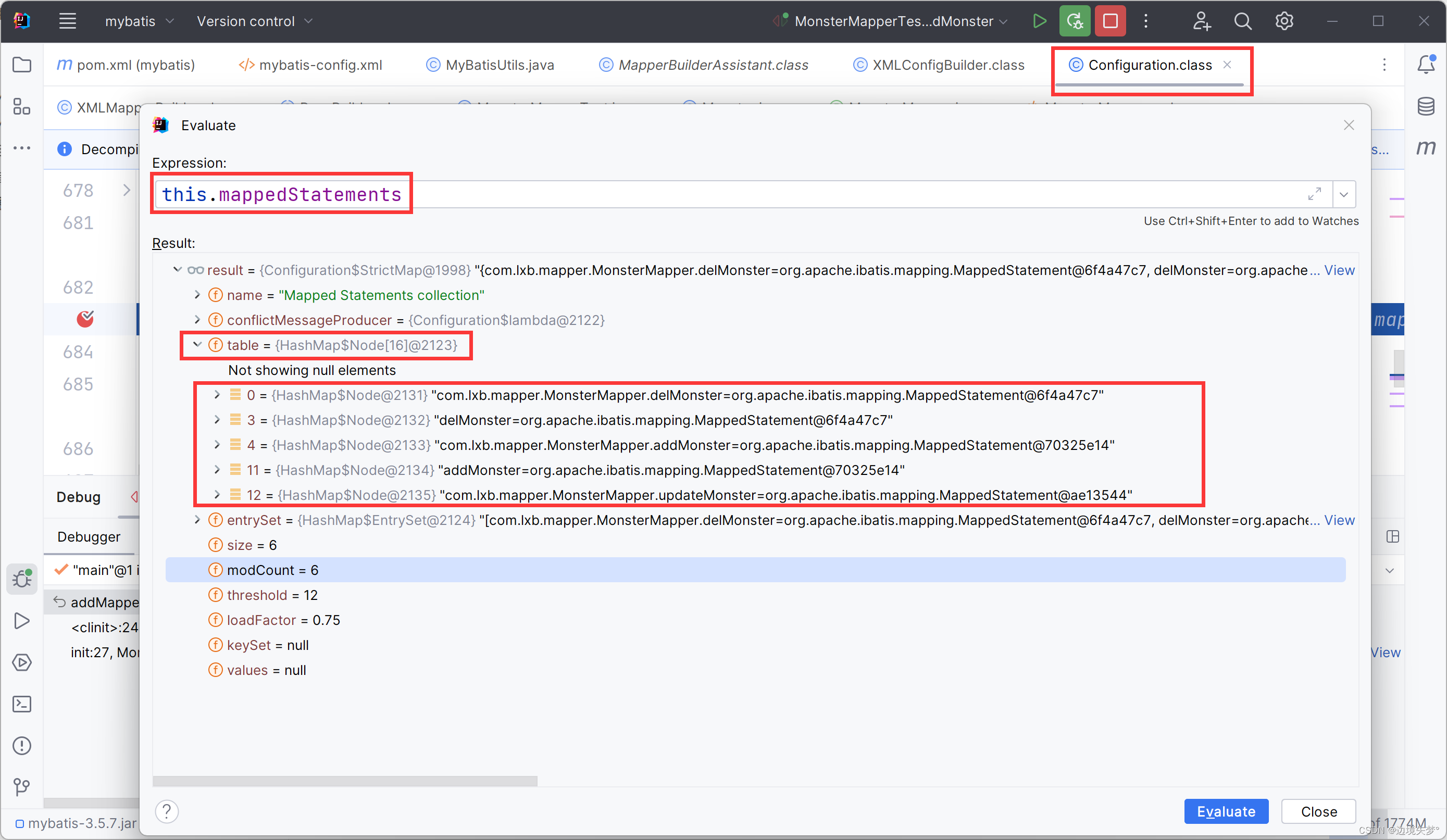
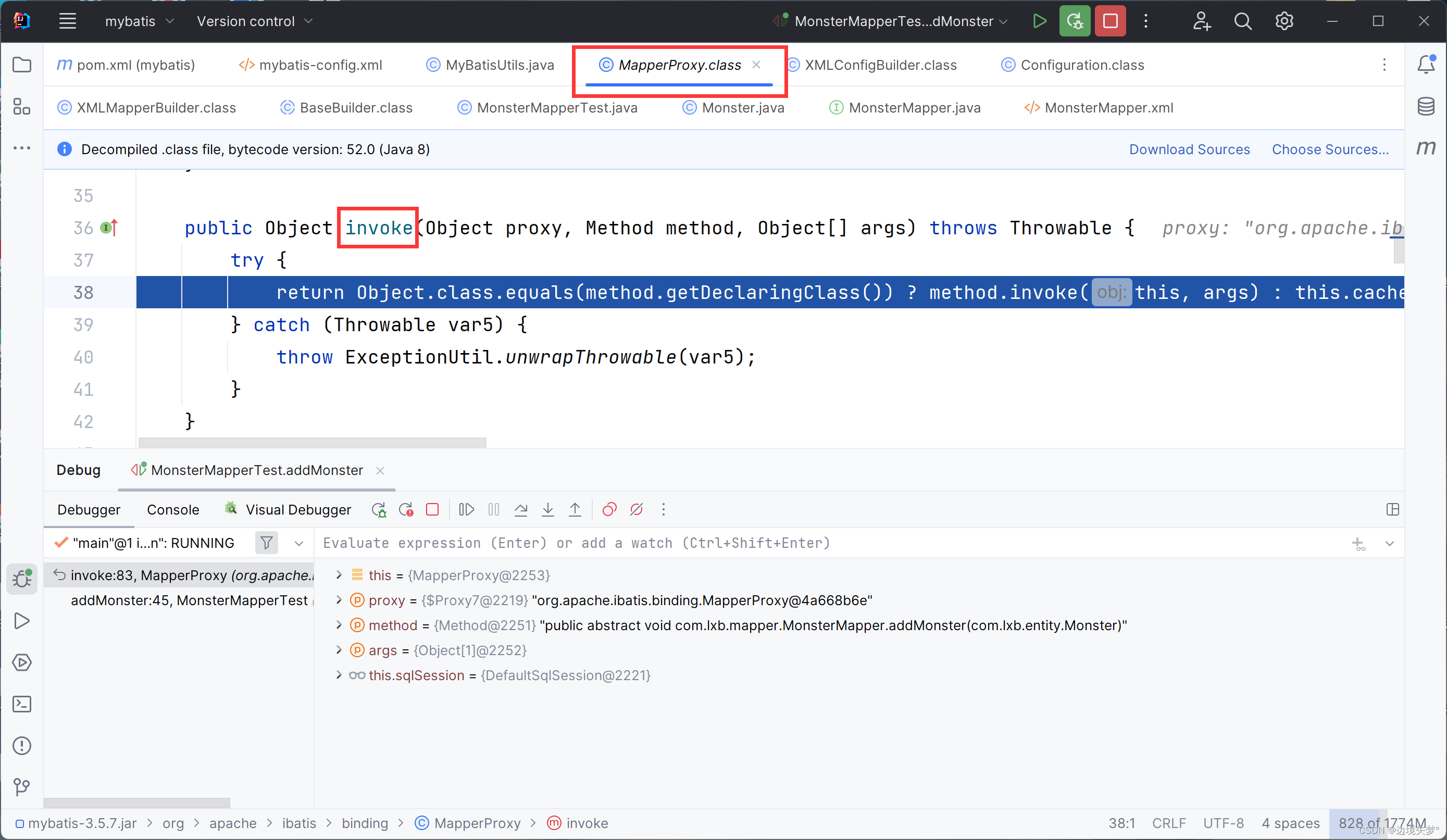
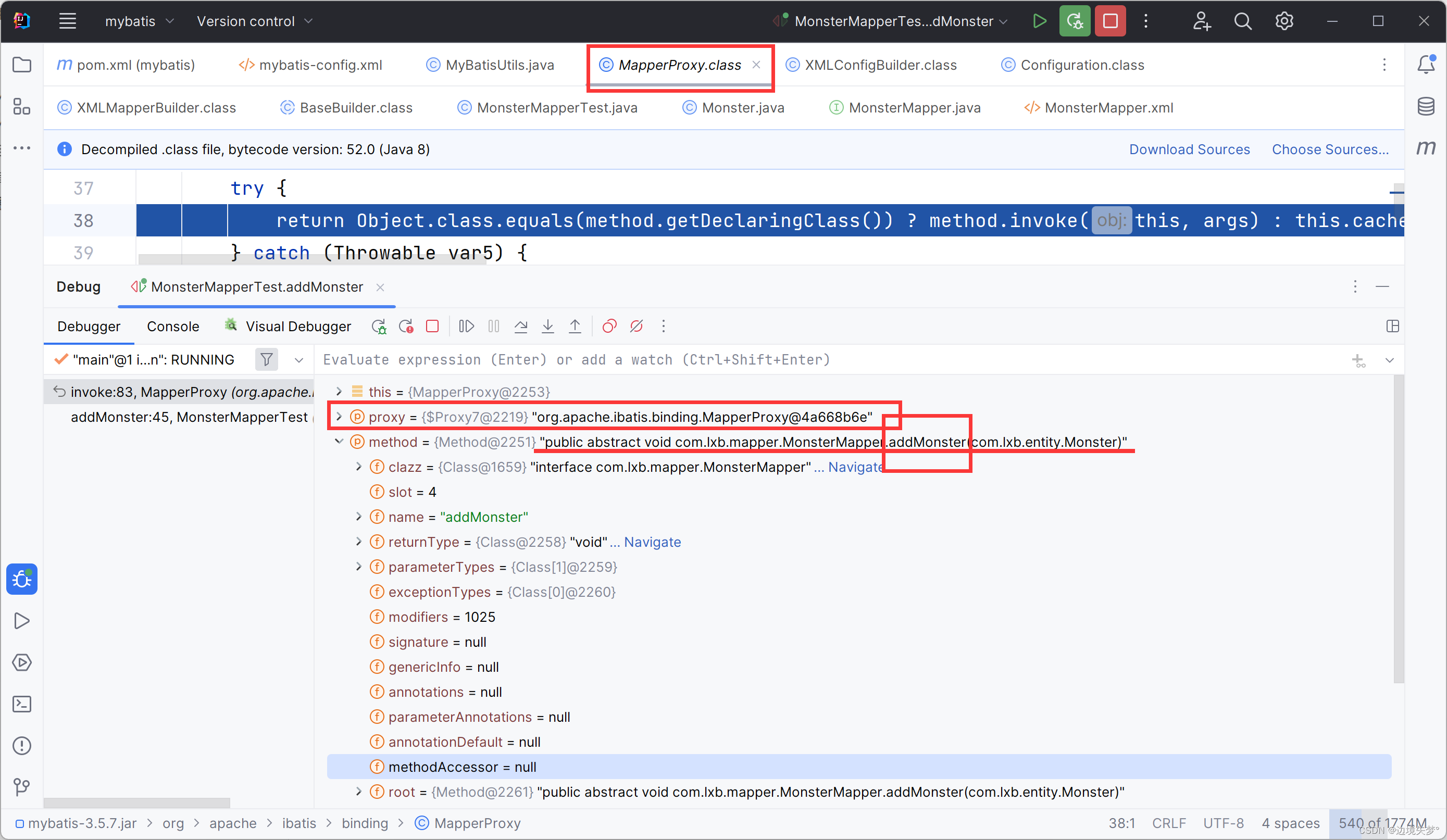
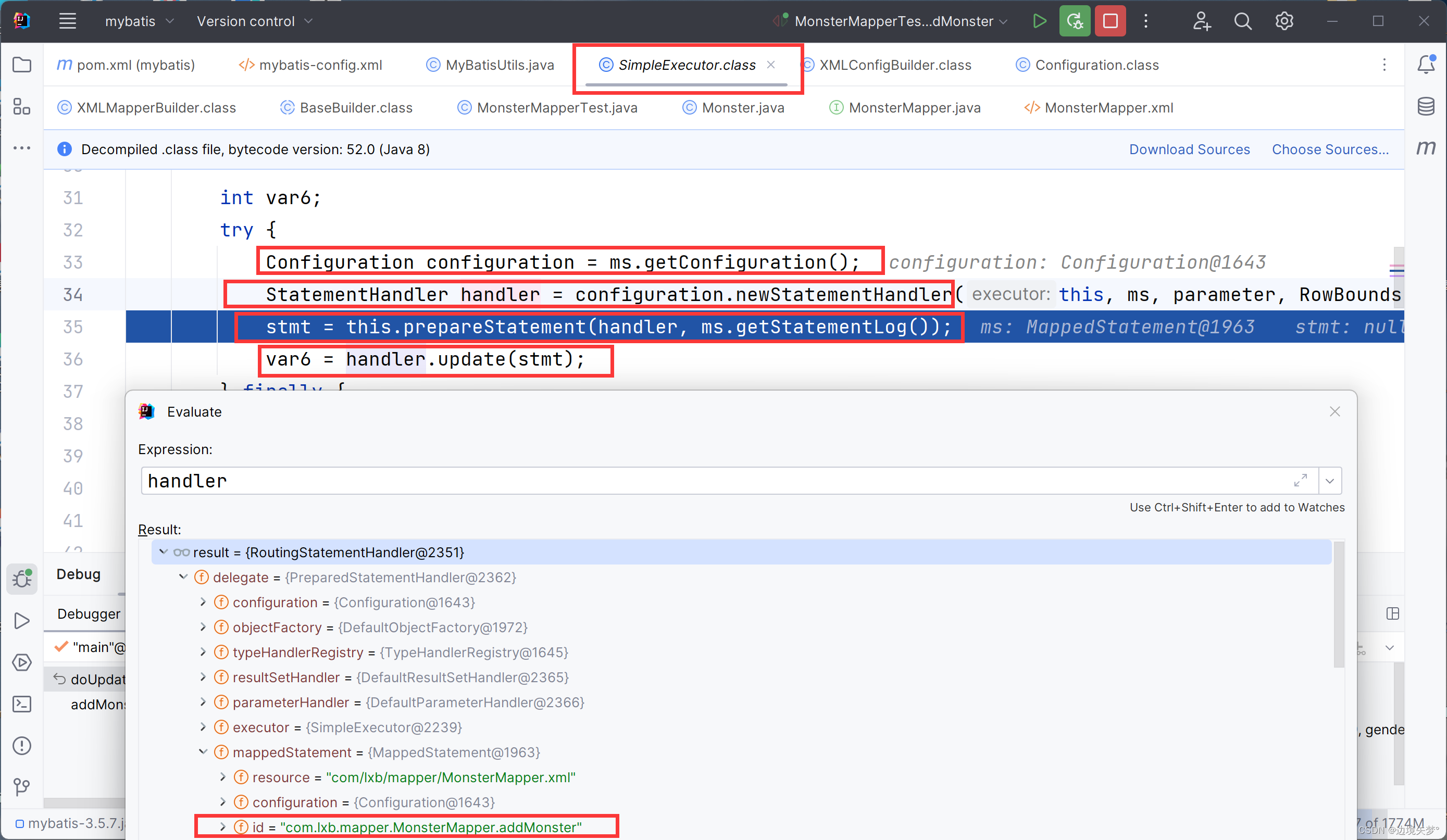
MyBatis注解
〉Arg.class
〉AutomapConstructor.class
〉CacheNamespace.class
〉CacheNamespaceRef.class
〉Case.class
〉ConstructorArgs.class
〉Delete.class @Delete:实现删除功能
〉DeleteProvider.class
〉Flush.class
〉Insert.class @Insert:实现新增功能 @Insert:实现插入功能
〉InsertProvider.class
〉Lang.class
〉Many.class @many:用于一对多关系映射
〉MapKey.class
〉Mapper.class
〉One.class @one:用于一对一关系映射
〉Options.class
〉Param.class @Param:映射多个参数
〉Property.class
〉Result.class 结果集映射
〉ResultMap.class 结果集映射
〉Results.class 结果集映射
〉ResultType.class 返回类型
〉Select.class @Select:实现查询功能
〉SelectKey.class @SelectKey:插入后,获取id的值
〉SelectProvider.class
〉TypeDiscriminator.class
〉Update.class @Update:实现更新功能
〉UpdateProvider.class
动态SQL
⚠ : if 标签中的test属性的值可以不带#{}, 对象中的属性
动态SQL就是让SQL的拼接不那么死板, 可以由程序员自定义拼接
映射关系
一对一映射关系
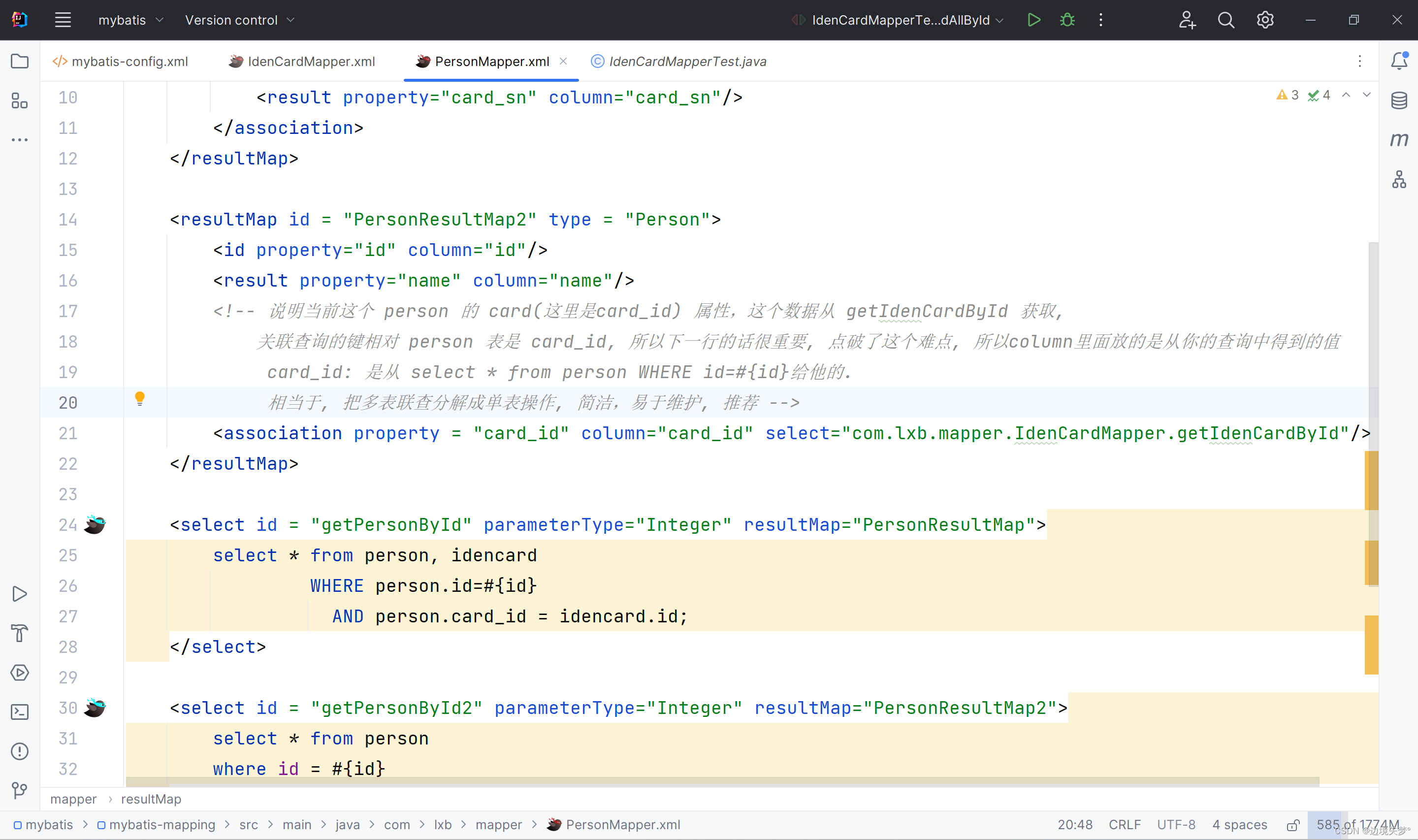
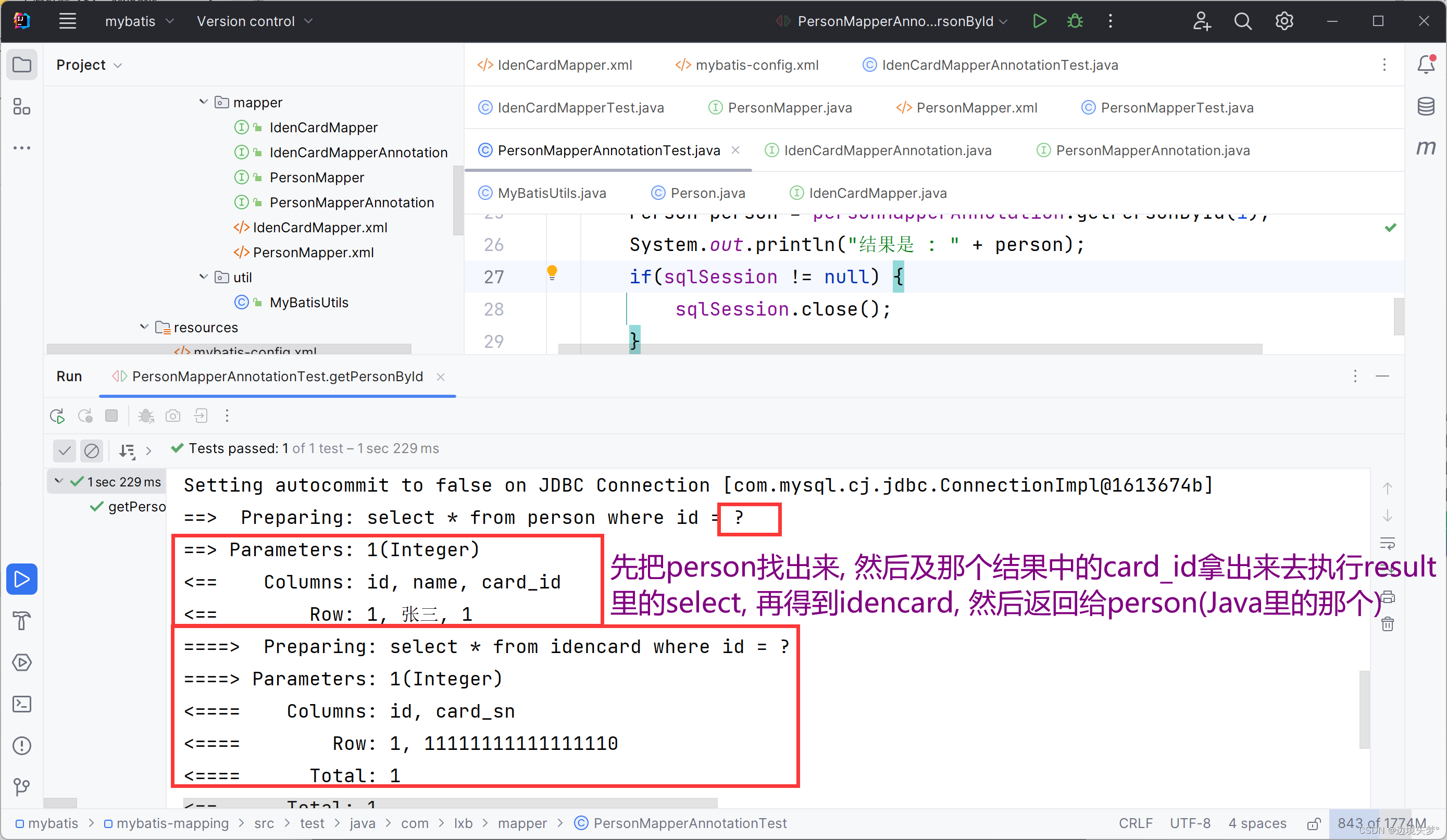
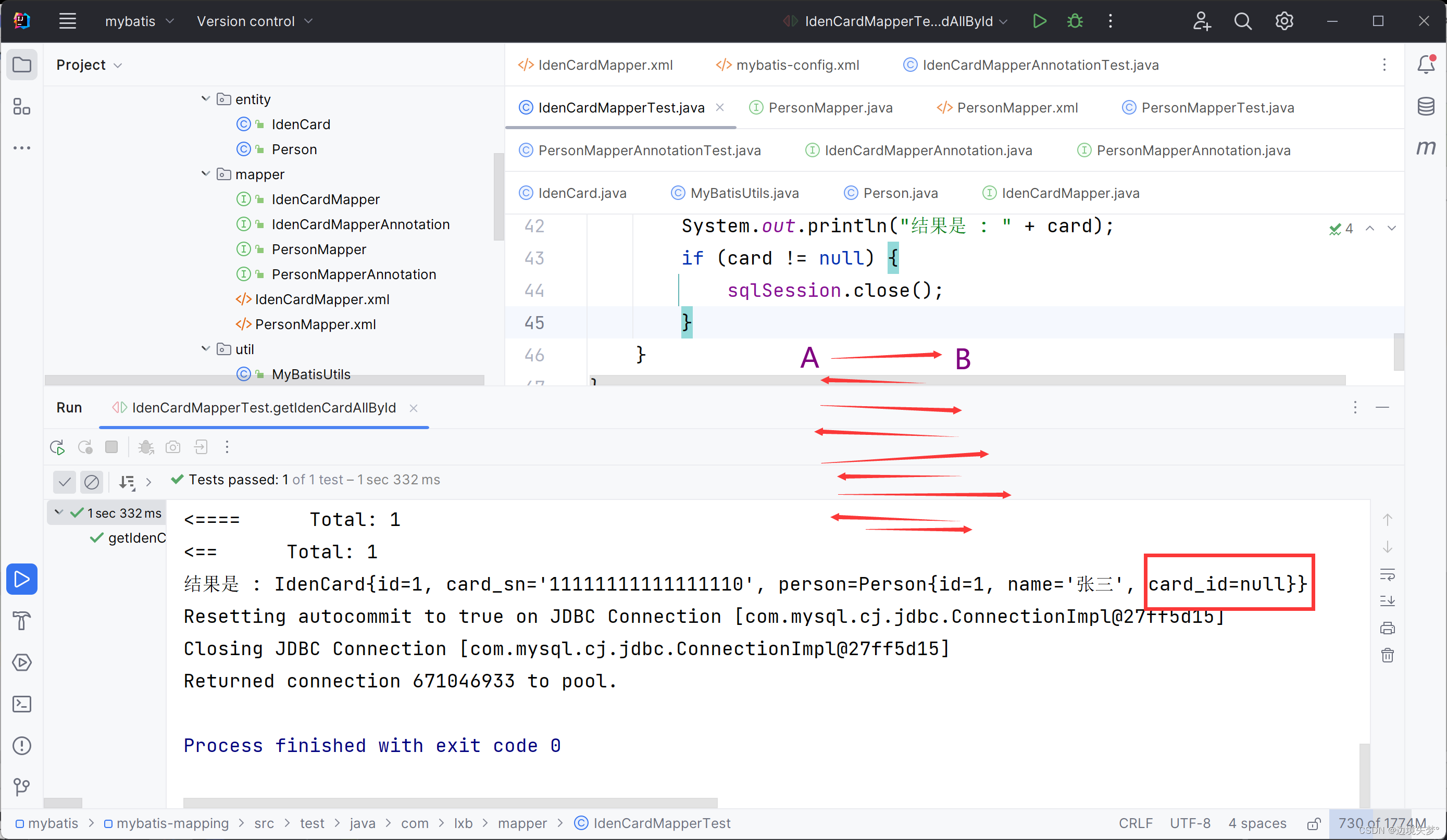
值得注意的是MyBatis有自己的机制, 那就是可以避免无限级联查询, 之前思考过的问题 : 主人和宠物之间的一对多关系的时候
MyBatis执行SQL的两种方式

执行器随记
CachingExecutor 和 SimpleExecutor 都是 MyBatis 框架中的执行器(Executor)的实现,用于执行 SQL 语句和处理数据库操作。它们之间的主要区别在于缓存的使用方式。
- SimpleExecutor:
SimpleExecutor是 MyBatis 默认的执行器。它执行 SQL 语句,但不使用缓存机制。每次执行相同的 SQL 语句时,都会直接查询数据库,不会对查询结果进行缓存。这意味着每次执行查询都会从数据库中获取数据,不会利用内存中的缓存。 - CachingExecutor:
CachingExecutor是一个装饰者模式下的执行器,它可以包装其他执行器,通常是SimpleExecutor。它的主要作用是添加缓存支持。当一个查询语句被执行时,CachingExecutor会首先检查缓存中是否已经有相同的查询结果。如果缓存中有数据,它会从缓存中返回结果,而不会实际执行 SQL 查询。如果缓存中没有数据,它会调用包装的执行器(通常是SimpleExecutor)执行 SQL 查询,然后将结果缓存起来,以便下次查询时使用。
使用 CachingExecutor 可以提高查询性能,特别是在需要频繁执行相同查询的情况下,因为它避免了不必要的数据库查询操作。然而,需要注意的是,缓存可能导致数据一致性问题,因此在使用缓存时,你需要谨慎处理缓存的清除和更新。
你可以在 MyBatis 的配置文件中配置执行器的类型,以决定使用哪种执行器。例如,你可以在配置文件中指定以下内容来选择 CachingExecutor:
xmlCopy code<settings><setting name="defaultExecutorType" value="REUSE" />
</settings>
这将在全局范围内将执行器类型设置为 REUSE,这将使用 CachingExecutor 来执行 SQL 查询。但是,你也可以在具体的 Mapper 接口中使用 @Select 注解的 useCache 属性来覆盖全局配置,以决定是否使用缓存。
缓存
二级缓存的大开关(mybatis-config.xml)和小配置(XxxxMapper.xml)

如何禁用二级缓存
1)
在D:\hspedu_mybatis_lx\mybatis\mybatis_cache\src\main\resources\mybatis-config.xml
2)
在D:\hspedu_mybatis_lx\mybatis\mybatis_cache\src\main\java\com\hspedu\mapper\MonsterMapper.xml
3) 或者更加细粒度的 , 在配置方法上指定
设置 useCache=false 可以禁用当前 select 语句的二级缓存,即每次查询都会发出 sql 去查询,默认情况是 true,即该 sql 使用二级缓存。
注意:一般我们不需要去修改,使用默认的即可
4. mybatis 刷新二级缓存的设置
UPDATE mybatis_monster SET NAME=#{name},age=#{age} WHERE id=#{id}
insert、update、delete 操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读
默认为 true ,默认情况下为 true 即刷新缓存,一般不用修改。
两个缓存的事
sqlSession.clearCache() 方法在 MyBatis 中用于清理一级缓存(本地缓存)。它不会清理二级缓存。
- 一级缓存: 也称为本地缓存,它是在同一个
sqlSession中有效的,用于缓存从数据库中检索的数据,以提高性能和避免多次查询相同的数据。 - 二级缓存: 也称为全局缓存,它是在不同的
sqlSession之间共享的,通常用于跨会话的数据共享。sqlSession.clearCache()不会清理二级缓存。
如果您希望清理二级缓存,可以在 MyBatis 的配置中配置相应的 <cache/> 标签来管理二级缓存,或者使用相应的方式来手动清理。但是,sqlSession.clearCache() 主要用于清理当前 sqlSession 中的一级缓存。
⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️⚠️☣️
解释一下这句话 : 不会出现一级缓存和二级缓存中有同一个数据。因为二级缓存(数据)是在一级缓存关闭之后才有的
这句话的含义是,一级缓存(本地缓存)和二级缓存(全局缓存)中不会同时包含相同的数据。这是因为二级缓存中的数据只有在一级缓存关闭(或未命中)的情况下才会被添加到二级缓存中。
具体来说:
- 一级缓存(本地缓存): 当您执行一个查询操作时,查询结果会被缓存在当前的
sqlSession中。如果您再次执行相同的查询,MyBatis会首先查看一级缓存,如果有缓存的数据,将直接返回,而不需要再次查询数据库。这是一级缓存的工作方式。 - 二级缓存(全局缓存): 二级缓存是一个跨
sqlSession的缓存。如果您在一个sqlSession中查询了数据,然后关闭了该sqlSession,在另一个新的sqlSession中再次查询相同的数据,MyBatis会首先查看二级缓存。如果在二级缓存中有缓存的数据,将直接返回,而不需要查询数据库。这是二级缓存的工作方式。
由于一级缓存是在每个 sqlSession 中独立的,而二级缓存是在多个 sqlSession 之间共享的,因此在一个 sqlSession 中缓存了数据后,这些数据不会立刻添加到二级缓存。只有在该 sqlSession 关闭时,如果有相应的配置,数据才会被写入二级缓存。
因此,一级缓存和二级缓存的数据是不会重叠的,因为在同一个 sqlSession 中使用一级缓存,而在不同 sqlSession 之间使用二级缓存。这保证了数据的一致性和避免了数据冗余。
Ehcache
第三方二级缓存Ehcache
属性解释
| 属性名 | 含义 | 解释 |
|---|---|---|
| name | 缓存名称 | 每个缓存区域都应该有一个唯一的名称,以便在 MyBatis 中引用和配置缓存。 |
| maxElementsInMemory | 缓存最大数目 | 用于配置缓存在内存中的缓存元素的最大数量。它决定了内存缓存的容量上限。 |
| maxElementsOnDisk | 硬盘最大缓存个数 | 用于配置磁盘上存储的缓存元素的最大数量 |
| eternal | 对象是否永久有效 | 一但设置了,TTL和TTI将不起作用 |
| overflowToDisk | 是否保存到磁盘,当系统宕机时 | 缓存中的元素是否应在内存不足时写入磁盘以释放内存 |
| ☣️timeToIdleSeconds | 设置对象在失效前的允许闲置时间(单位:秒) | 在一直不访问这个对象的前提下,这个对象可以在cache中的存活时间。 |
| ☣️timeToLiveSeconds | 设置对象在失效前允许存活时间(单位:秒), 最大时间介于创建时间和失效时间之间。 | 就是 无论对象访问或是不访问(闲置),这个对象在cache中的存活时间。 |
| diskPersistent | 是否缓存虚拟机重启期数据 | 用于控制在缓存关闭(或系统重启)后是否保留磁盘上的缓存数据。默认值为false。 |
| diskSpoolBufferSizeMB | 这个参数设置 DiskStore (磁盘缓存) 的缓存区大小 | 默认是30MB。这个属性决定了当数据被写入磁盘时,缓冲区的大小,以及一次写入多少数据到磁盘。 |
| diskExpiryThreadIntervalSeconds | 磁盘失效线程运行时间间隔,默认是 120秒。 | 用于配置在磁盘上存储的缓存数据的过期检查线程的运行间隔时间,以秒为单位。 |
| memoryStoreEvictionPolicy | 当达到maxElementsInMemory 限制时,Ehcache 将会根据指定的策略去清理内存。 | FIFO,first in first out,先进先出。LFU,Less Frequently Used,一直以来. 最少被使用的。LRU,Least Recently Used (默认策略),最近最少使用的。 |
| clearOnFlush | 内存数量最大时是否清除 | 用于控制在缓存刷新(flush)时是否清空缓存中的所有数据。 |
FIFO,first in first out,这个是大家最熟的,先进先出。LFU, Less Frequently Used,直白一点就是一直以来. 最少被使用的。如上面所讲,缓存的元素有一个 hit 属性,hit 值最小的将会被清出缓存。LRU,Least Recently Used,最近最少使用的,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存






:基础知识考察)
试用 12 -- 年终再总结)


)








