Editor’s summary
蛋白质中单个氨基酸的变化有时影响不大,但通常会导致蛋白质折叠、活性或稳定性方面的问题。只有一小部分变体进行了实验研究,但有大量的生物序列数据适合用作机器学习方法的训练数据。程等人开发了AlphaMissense,这是一种基于蛋白质结构预测工具AlphaFold2的深度学习模型(见Marsh和Teichmann的观点)。该模型基于人口频率数据进行训练,并使用序列和预测的结构上下文,所有这些都有助于其性能。作者使用未包含在训练中的临床数据库,对照相关方法评估了该模型,并证明其与变异效应的多重分析一致。人类蛋白质组中所有单氨基酸取代的预测都是作为一种社区资源提供的。
个人补充知识:蛋白质与氨基酸的关系:
蛋白质是由氨基酸组成的。氨基酸是组成蛋白质的基本结构单位。蛋白质当中含有必须氨基酸和非必需氨基酸。无论是蛋白质还是氨基酸都属于人体所需要的营养成分。在患者出现有蛋白质与氨基酸缺乏的情况下,容易出现有营养不良所引起的各种疾病的病情发生,从而会对患者的身体健康造成严重的损害,尤其是在患者出现有低蛋白血症的病情发作时,患者会呈现有极度虚弱的状态,需要及时进行治疗以免病情加重。
DNA是绝大多数生物的遗传物质,以DNA为模板利用四种核糖核昔酸为原料经过转录形成RNA,以RNA为模板利用20种氨基酸为原料料经过翻译形成蛋白质,蛋白质是生命活动的承担者
DNA是脱氧核糖核酸,RNA是核糖核酸,蛋白质是由氨基酸经脱水缩合而成组成的。DNA是绝大多数生物的遗传物质,以DNA为模板经过转录形成RNA,以RNA为模板经过翻译形成蛋白质。

INTRODUCTION
基因组测序揭示了人类群体中广泛的遗传变异。错义变体Missense variants是改变蛋白质氨基酸序列的遗传变体。致病性错义变体破坏蛋白质功能并降低生物体适应性,而良性错义变体的作用有限。
RATIONALE基本原理
对这些变体进行分类是人类遗传学中一个重要的持续挑战。在观察到的400多万个错义变体中,估计只有2%在临床上被归类为致病性或良性,而其中绝大多数具有未知的临床意义。这限制了罕见病的诊断,以及针对潜在遗传原因的临床治疗的开发或应用。机器学习方法可以通过利用生物数据中的模式来预测未标记变体的致病性,从而缩小变体解释的差距。具体来说,AlphaFold可以从蛋白质序列中准确预测蛋白质结构,可以作为预测变体对蛋白质致病性的基础。
RESULTS
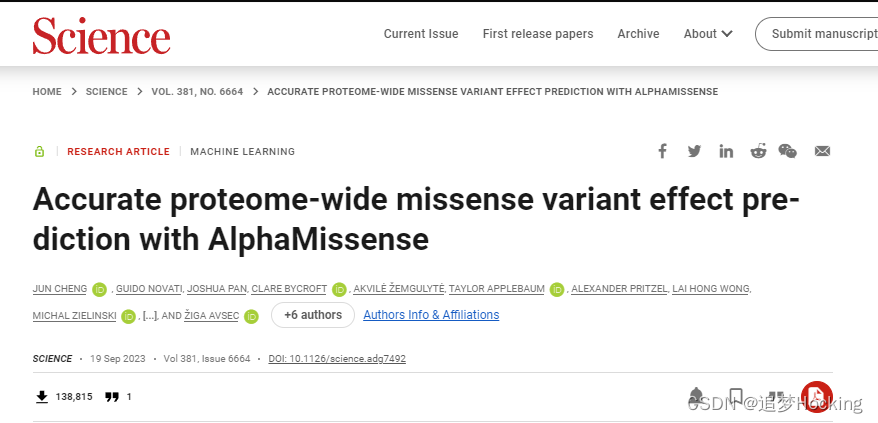
我们开发了AlphaMissense,以利用多个方面的进展:(i)无监督蛋白质语言建模,以学习基于序列上下文的氨基酸分布;(ii)通过使用源自AlphaFold的系统来结合结构上下文;以及(iii)对来自群体频率数据的弱标签进行微调,从而避免来自人类策划的注释的偏差。AlphaMissense在临床注释、新发疾病变体和实验测定基准中实现了最先进的错义致病性预测,而无需对这些数据进行明确的训练。作为社区的资源,我们提供了一个预测人类蛋白质组中所有可能的单个氨基酸取代的数据库。我们使用ClinVar数据集上产生90%准确度的截止值,将32%的错义变体归类为可能的致病性变体,57%的错义变种归类为良性变体,从而为大多数人类错义变体提供了可靠的预测。
我们展示了如何利用这些资源来加速多个领域的研究。分子生物学家可以将该数据库作为设计和解释探测人类蛋白质组中饱和氨基酸取代的实验的起点。人类遗传学家可以将基因水平的AlphaMissense预测与基于群体队列的方法相结合,以量化基因的功能意义,尤其是对于较短的人类基因,基于队列的方法缺乏统计能力。最后,临床医生在优先考虑罕见病诊断的从头变异时,可以从自信分类的致病性变异的覆盖率的提高中受益,AlphaMissense预测可以为使用罕见、可能有害变异注释的复杂性状遗传学研究提供信息。
CONCLUSION
AlphaMisense预测可能阐明变体对蛋白质功能的分子影响,有助于识别致病性错义突变pathogenic missense mutations 和以前未知的致病基因,并提高罕见遗传病的诊断率。AlphaMissense还将促进从结构预测模型中进一步开发专门的蛋白质变体效应预测因子。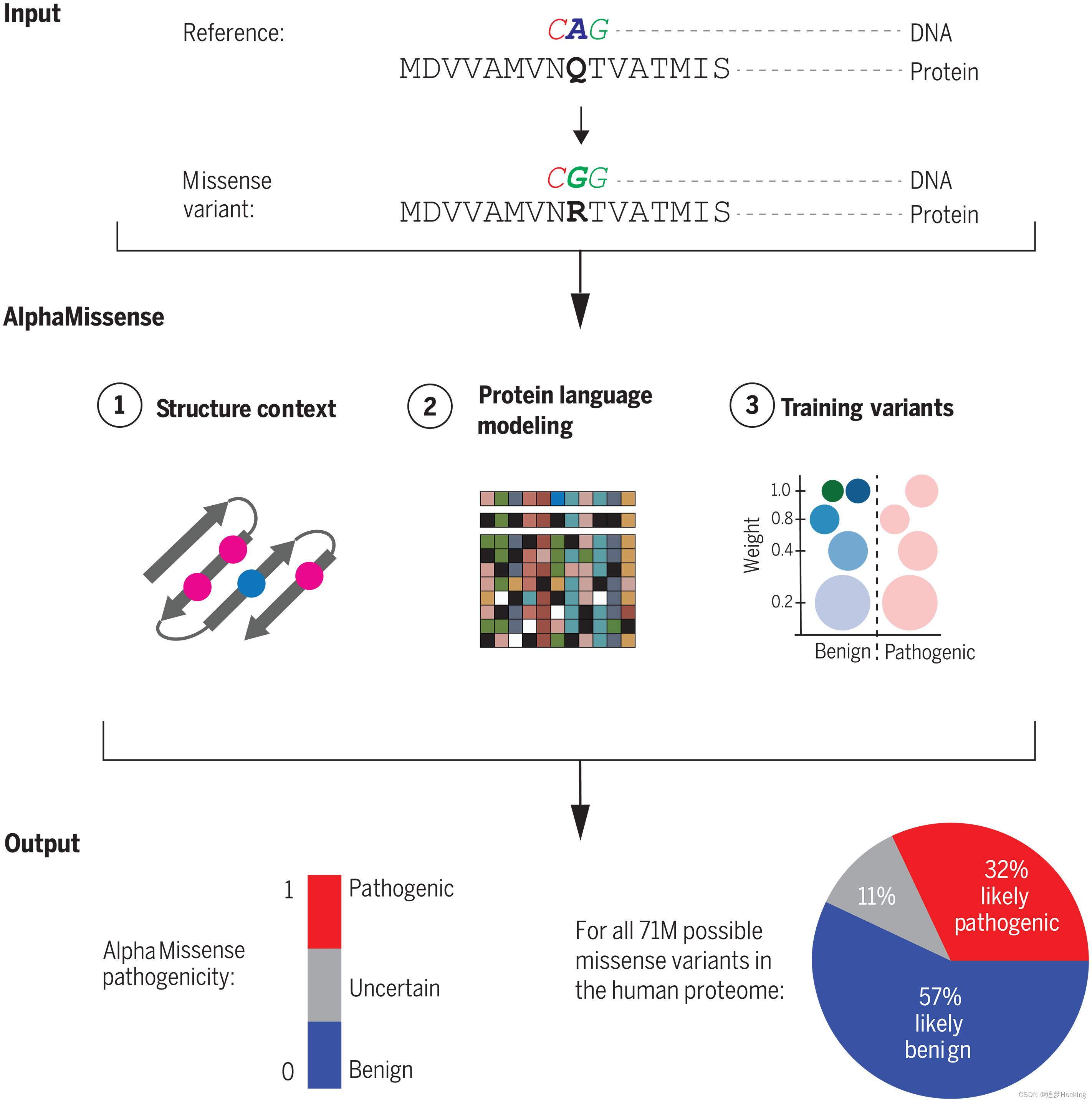
AlphaMissense致病性预测。
AlphaMisense将错义变体作为输入,并预测其致病性。我们对人类和灵长类动物变异种群频率数据进行了微调,并校准了已知疾病变异的置信度。AlphaMisense预测错义变体致病的可能性,并将其分类为可能良性benign、可能致病pathogenic或不确定uncertain。我们为社区提供了所有可能的人类错义变体的预测。
Abstract
在人类基因组中观察到的绝大多数错义变体具有未知的临床意义。我们提出了AlphaMisense,这是AlphaFold的一种改编,对人类和灵长类动物的变体群体频率数据库进行了微调,以预测错义变体的致病性。通过将结构背景和进化守恒相结合,我们的模型在广泛的遗传和实验基准上取得了最先进的结果,而无需对这些数据进行明确的训练。基因的平均致病性得分也可以预测其细胞重要性,能够识别现有统计方法检测能力不足的短必需基因。作为社区的一种资源,我们提供了一个预测所有可能的人类单氨基酸取代的数据库,并将89%的错义变体分类为可能的良性或可能的致病性。
基因组测序揭示了人类群体中广泛的遗传变异(1-3)。错义变体Missense variants是改变蛋白质氨基酸序列的遗传变体。致病性错义变体严重破坏蛋白质功能并降低生物体适应性,而良性错义变体的作用有限。在观察到的400多万个错义变体中,估计只有2%在临床上被归类为致病性或良性。对意义未知的剩余变体进行分类是人类遗传学中一项重要的持续挑战(3)。缺乏准确的错义变体功能预测限制了罕见病的诊断率,以及针对潜在遗传原因的临床治疗的开发或应用。尽管变异效应的多重分析(MAVE)系统地测量了蛋白质变异效应(4),并可以准确预测变异的临床结果(5),但由于MAVE实验所需的成本和劳动力,对变异致病性的全蛋白质组调查仍然不完整(6)。
机器学习方法可以通过利用生物学数据中的模式来预测未标记变体的致病性,从而缩小变体解释的差距。机器学习方法遵循四大策略。第一类方法直接在人类策划的变体数据库上进行训练(7-10),从而利用先验知识来告知未标记变体的状态。这种策略将继承人类策展人和以前的计算机预测者的偏见,并且它们很容易在训练和测试之间泄露数据(11)。
为了克服这种循环性,第二类方法使用不依赖于人类分类的弱标签进行训练(12,13)。在训练数据中,“良性”变异被定义为在人类或其他灵长类物种中经常观察到的变异。“致病性”类别近似于人类中未观察到的假设变体。这种方法代表了一个有希望的方向,以减轻潜在的人类管理偏见。然而,由于训练数据包含许多虚假标签,因此此类模型需要对更可靠的标签进行评估,以评估其真实性能。
第三类方法避免直接对变体注释进行训练,而是使用无监督方法,以氨基酸序列上下文为条件,对给定序列位置的氨基酸分布进行建模(14-16)。最近,从蛋白质序列中学习氨基酸之间的高阶依赖性的深度学习模型,如自动编码器或语言模型,已经获得了强大的性能(17-19)。在这样的模型中,致病性被解释为参考序列和替代序列之间预测的对数似然性的差异。尽管这些模型有效地捕捉了自然进化序列的分布,但它们缺乏AlphaFold(AF)对蛋白质结构的最先进理解(20,21)。
第四种策略是利用蛋白质结构来推断致病性,因为改变的氨基酸的结构背景提供了解释其对蛋白质影响的关键信息。对预测蛋白质结构的初步探索显示了希望(22,23),预测蛋白质结构有助于对遗传进化约束的估计(24)。尽管该策略改进了遗传约束量化,但直接使用该方法进行致病性预测在ClinVar变体上仅显示出中等性能(24),这可能是因为在当前人类序列数据库中观察到的遗传多样性较低。
AF最近已经表明,使用蛋白质序列作为输入可以大规模预测高度准确的蛋白质结构(21,25)。这样的蛋白质结构模型可以作为理解蛋白质生物学的其他方面的基础,例如变体致病性。尽管AF在很大程度上对输入序列变异不敏感,并且不能准确预测点突变后的结构变化(26),但我们假设AF对多序列比对(MSAs)和蛋白质结构的内在理解为直接预测错义变体致病性的模型提供了有价值的起点。
在这里,我们提出了AlphaMissense,它结合了现有策略的以下元素:(i)对来自群体频率数据的弱标签进行训练,通过不使用人类注释来避免循环性;(ii)结合无监督蛋白质语言建模任务来学习以序列上下文为条件的氨基酸分布;以及(iii)通过使用源自AF的系统来结合结构上下文。我们在临床注释、新发疾病变异和实验MAVE基准方面实现了最先进的预测,而没有根据这些数据明确训练我们的模型。我们预测并表征了人类蛋白质组中所有单个氨基酸取代的致病性,并将这些预测提供给社区。
AlphaMissense: Fine-tuning AlphaFold for variant effect prediction
AlphaMissense:微调AlphaFold以进行变体效果预测
AlphaMissense将氨基酸序列作为输入,并预测序列中给定位置上所有可能的单个氨基酸变化的致病性。AlphaMissense利用了AF的两个关键功能:其高度准确的蛋白质结构模型和从相关序列中学习进化约束的能力(21)。因此,AlphaMissense的实现与AF的实现非常相似,但在架构上略有差异(图1和图S1;参见补充材料中的方法)。值得注意的是,AlphaMissense并不预测突变氨基酸序列的结构变化,而是以标量值预测致病性。
Fig. 1. Overview of AlphaMissense.
(A) AlphaMissense架构。模型输入由参考蛋白质序列[裁剪为长度(L)=256个残基]、从训练集中为相同序列采样的一组变体(最多N=50个变体)和多序列比对(MSAs,最多Nall=2048)组成。一次对一个变体进行推理(N=1)。参考序列在MSA的第二行中重复,所有采样的变体位置都被屏蔽(见方法)。如在AlphaFold中一样,该模型从参考序列(嵌入大小Kpair)构建对表示(即,编码关于残基之间双向相互作用的信息),并从掩蔽的MSA(嵌入大小Kmsa)构建MSA表示。MSA和对表示由一堆Evoformer层进行处理,并进行回收。最后,该模型预测了参考序列的结构和致病性评分 � � � 对于变体,其从掩蔽残差预测头导出为残差a相对于位置i处的参考残差之间的对数似然差(参见方法)。(B) 致病性评分被微调为良性变异(在人类或灵长类动物群体中观察到或频繁的错义变异)或致病性变异(未观察到的人类错义变体)的二元分类。我们根据良性变异的次要等位基因频率(MAF)将其划分为簇,并在损失函数中引入权重,以减少罕见变异的贡献。对于良性组中观察到的每个变体,我们从致病组中抽取一个错义变体,并将其分配给与良性变体相同的损失权重(见方法)。(C) 我们在一组不同的基准数据集上评估了AlphaMisense,包括ClinVar中的注释错义变体(30)、新发疾病变体(54)和ProteinGym中收集的MAVE数据(19)。
AlphaMissense分两个阶段进行训练。在第一阶段,像AF一样训练网络,以通过预测MSA中随机位置掩蔽的氨基酸的身份来执行单链结构预测(AF预训练)以及蛋白质语言建模。我们对AF进行了一些小的结构修改,并增加了蛋白质语言建模的损失,同时仍然实现了与AF相当的结构预测性能(见方法)。在预训练之后,通过计算参考和替代氨基酸概率之间的对数似然比,掩蔽语言建模头已经可以用于变体效应预测,如在MSA Transformer(27)和进化尺度建模[ESM(28)]中所做的那样。
在第二阶段(图1A),该模型在人类蛋白质上进行了微调,并为MSA第二行中的变体序列定义了额外的变体致病性分类目标(图第1A段)。对于训练集,我们将良性标签分配给在人类和灵长类动物群体中经常观察到的变体,将致病性标签分配给人类和灵长目动物群体中不存在的变体,就像在PrimateAI中所做的那样(12)(图1B;见方法)。一旦模型开始在验证集上过度拟合,我们就停止训练模型(2526个ClinVar变体,每个基因的致病性和良性变体数量相等;见方法)。
我们的训练集本质上是有噪声的,因为许多未观察到的变体可能是良性的,但与单独预训练相比,它提供了足够的学习信号来提高变体致病性得分。为了提高训练集的质量和大小,我们通过使用初步的AlphaMissense模型来过滤未观察到的预测可能是良性的变体,从而采用自蒸馏。然后使用这个过滤的训练集重复微调阶段(参见方法)。进一步的创新包括自定义分类损失函数、在训练期间对多个变体进行采样、改进变体的匹配采样以及在向预训练的参数值进行微调期间的权重衰减(见下文的方法和消融研究部分)。
Improved pathogenicity classification across multiple clinical benchmarks跨多个临床基准改进致病性分类
临床数据库收集导致人类疾病的错义变体。这些数据库可用于确定致病性预测模型的基准,但这些数据包含人类偏见,可能会歪曲临床相关变异的真实分布(见补充材料中的补充说明)。在这些数据库上训练的模型(例如ClinVar)继承了这些偏差,并且往往无法推广到其他基准(11,29)。我们避免直接对临床策划的标签进行培训,以缓解此类问题,并能够对各种基准进行忠实评估,包括ClinVar中注释错义变体的测试集(30)、罕见发育障碍患者和对照组的新变体(12)、ProteinGym中的MAVE基准(19),以及本研究中策划的其他MAVE基准(图1C;见方法)。
我们首先在ClinVar错义变体上评估了我们的模型。在平衡了每个基因的致病性和良性变异的数量后,AlphaMissense在18924个ClinVar测试变异上实现了0.940的受试者-算子曲线下面积(auROC),而变异效应进化模型(EVE;P=0.001,bootstrap)实现了0.911的auROC,该模型是第二好的模型,没有直接在ClinVar上训练(17)(图2A)。AlphaMissense也优于直接在ClinVar上训练的模型,尽管这些模型表现出数据泄露和标签循环性(图2A;见补充注释)(11,17,29)。此外,我们观察到AlphaMissense能够在高度进化约束的区域内区分致病性和良性ClinVar变体(31),并且它在这项任务上优于最佳竞争模型(ESM1b,P=0.001,bootstrap)(图S2A)。这一结果表明,该模型不仅依赖于识别受约束的领域,而且捕捉到了这些领域内个体变体效果的差异。我们的模型性能在不同的AlphaFold置信水平上是一致的(图S2B)。然而,我们注意到来自预测为无序的残基的变体的性能降低(图S2C)。

Fig. 2. Performance of AlphaMissense on clinically curated classification benchmarks.
图2。AlphaMissense在临床策划的分类基准上的表现。
基准是根据受试者-操作员曲线(auROC)下的面积进行评估的。误差条显示1000个引导重采样的95%置信区间(见方法)。一些手动选择的方法是彩色的,以说明不同基准上的相对位置。(A) ClinVar变体(来自999种蛋白质的9462种致病性变体和9462种良性变体)的分类性能平衡了每个基因的阳性和阴性变体的数量。灰色显示的方法直接在ClinVar上进行训练。他们的一些训练变体包含在这个测试集中,因此他们的性能可能被高估了。误差条显示1000个引导重采样的95%置信区间(见方法)。(B) ClinVar测试集上每个基因的平均auROC。共考虑了612种蛋白质,其中至少有五种良性和五种致病性ClinVar测试变体。(C) AlphaMissense和其他预测因素在区分DDD队列患者和健康对照中的新变异方面的比较(12)。共考虑了来自215个DDD相关基因的353个患者变体和57个对照变体。我们排除了EVE,因为它在该数据集中的变体覆盖率较低(227/410个变体)。(D) AlphaMissense分数在类平衡的ClinVar验证集上进行校准(见方法)。该图显示了校准曲线,该曲线绘制了在ClinVar测试集(82872个变体)上计算的每个垃圾箱的致病性变体分数的平均分数。误差条表示从1000个自举重采样计算的95%置信区间。直方图显示了致病性(红色)和良性(蓝色)变异之间的得分分布。(E) 不同目标精度水平下已解决(明确)错义变体的分数。精确性被定义为在致病性和良性分类预测中真实预测的分数。用ClinVar测试集变体从EVE评分的蛋白质中计算解析的组分(全部为黑线),然后过滤为每个标记至少有3、5或10个变体的蛋白质(浅色线)。(F) 从ACMG临床可操作基因中选择的示例蛋白质(32)。蛋白质名称写为“[HUGO符号]/[Uniprot登录ID]”。(左图)用点表示的错义变体与AlphaMissense(AM)致病性评分(y轴)和氨基酸位置(x轴)相对应。预测为可能致病的变异以红色显示,预测为可能良性的变异以蓝色显示,不明确的变异以灰色显示。如果变体在ClinVar中包含临床标签,则将其绘制为实心圆。对于长度超过1400个氨基酸的蛋白质,显示了前1400个氨基酸。(右图)显示了所选区域的AlphaFold蛋白质结构预测。预测结构中的每个残基根据该残基的平均AlphaMissense致病性得分(每个残基19个可能的氨基酸变化中)进行着色。另请参见图S3A。(G) 与(F)相同,但从MAVE社区优先考虑的基因中选择的例子用于进一步研究(33)。另请参见图S3B。 崩溃 在查看器中打开
变异的临床评估通常集中在特定的疾病相关基因上,区分这些基因中的良性和致病性变异是预测模型的一项重要的临床相关任务。为了了解AlphaMissense模型在这项任务中的表现,我们分析了ClinVar测试集中至少有五种致病性和五种良性变异的612个基因。对于这些基因,我们计算了基因水平的auROC,它捕捉了模型在对单个基因中的变异进行分类方面的表现。当以这种方式进行评估时,AlphaMissense优于不直接在ClinVar上训练的次优方法EVE(17),平均基因水平auROC为0.950对0.921(P=0.001,自举)(图2B)。
我们进一步评估了AlphaMissense在两组重要蛋白质上的性能。第一组包括由美国医学遗传学学院(ACMG)优先考虑的临床可操作基因编码的蛋白质(32),该学院建议将这些基因的临床外显子组和基因组测序作为临床的次要发现返回,因为它们具有明确的疾病表型和高度渗透性突变。对于具有足够ClinVar标记和两种方法评分的34个ACMG基因,26个基因(77%)使用AlphaMissense致病性预测比EVE有所改善(图S3A)。第二组是基于临床相关性和实验易处理性,社区为未来MAVE研究优先考虑的蛋白质(33)。对于两种方法中具有足够ClinVar标记和评分的20个基因,使用AlphaMissense致病性预测,发现16个基因(80%)相对于EVE有改善(图S3B)。
最后,我们在解码发育障碍(DDD)基准上评估了AlphaMissense,其中AlphaMissSense实现了0.809的auROC,与PrimateAI持平(auROC=0.797,P=0.31,bootstrap)(12)(图2C)。我们还评估了我们的模型对癌症热点的分类,其中AlphaMissense实现了0.907的auROC,而下一个最佳模型VARITY(P=0.001,bootstrap)(9)(图S2D)。总体而言,AlphaMissense在所有策划的临床基准中都实现了最先进的性能,而之前报道的其他模型在这些基准中的排名都不高。
Calibrated AlphaMissense predictions expand the number of confidently classified variants relative to other methods相对于其他方法,校准的AlphaMissense预测扩大了自信分类变体的数量
在建立了AlphaMissense在临床基准上的最先进性能后,我们接下来生成并分析了整个蛋白质组的预测。我们使用AlphaMissense预测了19233种典型人类蛋白质中所有2.16亿个可能的单个氨基酸变化的致病性,导致7100万个错义变体预测使人类蛋白质组饱和(见方法)。
预测分数的实际使用需要对照临床策划的致病性和良性变异的金标准集进行仔细校准。我们使用来自ClinVar的2526个变体的平衡验证集(见方法),使用单变量逻辑回归模型校准我们的预测。这种方法产生校准的分数,如ClinVar测试集所示(图2D;见方法)。校准的AlphaMissense评分(范围在0到1之间)可以解释为变体具有临床致病性的近似概率。我们注意到,由于大多数预测接近0或1,0.2至0.8之间的分数校准可能不太准确。
接下来,我们使用校准的预测分数将变体分为三个离散类别,类似于ACMG术语(32,34):可能致病、可能良性和不明确[选择临界值,以便分类为可能致病或可能良性的变体具有根据ClinVar估计的90%的预期精度,如(17)所述](图S4A)。由于具有更高的预测性能,与最近性能良好的无监督模型EVE相比,我们可以自信地以90%的精度分类的ClinVar测试变体的比例增加了25.8个百分点(从67.1%增加到92.9%)。(17) (图2E和图S4B)。这种方法在蛋白质组范围内提供了一个具有自信预测的变体数量的重大扩展。
Overall properties and examples of AlphaMissense predictions
AlphaMissense预测的总体性质和示例
为了了解预测的总体性质,我们将其与有效序列比对次数(Neff评分)、遗传约束和预测的蛋白质紊乱进行了比较(图S4,C至F)。具有较低有效比对序列数并因此具有较低保守性水平的残留物往往具有较低的预测致病性(图S4C)。当观察聚集蛋白水平的结果时,这种关系不那么明显(图S4D),这表明AlphaMissense捕获了蛋白质内的结构域保守性,而不是整个蛋白质水平的进化保守性。类似地,位于进化受限基因中的变体被系统地预测为与不受约束基因中的变种相比更具致病性(图S4E)。位于结构化区域的变体可能会改变蛋白质稳定性(35,36),与位于紊乱区域的变体相比,其致病性得分更高(图S4F;用AlphaFold预测蛋白质紊乱)。这与最近的观察结果一致,即已知的致病变体更有可能存在于热稳定蛋白中(37)。
为了进一步了解AlphaMissense学习的氨基酸取代的特性,我们计算了所有人类蛋白质中每个氨基酸取代的平均预测致病性(图S4G)。正如预期的那样,芳香族氨基酸或半胱氨酸的突变更有可能是致病性的,因为它们在维持蛋白质结构方面发挥着作用。预测的取代分数是不对称的,如先前报道的(38),并且与BLOSUM62(39)取代矩阵总体[相关系数(r)=-0.61;图S4H]和每个参考氨基酸相关(图S4I)。总之,这些结果表明,该模型使用MSA中存在的结构信息和进化信息来做出与已知生物学一致的预测。
我们将致病性预测与ClinVar标签一起可视化(图2,F和G,左图)和AF预测的蛋白质结构(图2、F和G、右图)。可以观察到这些特定蛋白质的总体趋势。例如,结构紊乱的区域与良性预测和良性临床注释一致,与整个蛋白质组的结果一致(图S4F)。在特定情况下,根据蛋白质功能,致病性预测是有意义的。例如,我们预测ACVRL1的跨膜结构域(氨基酸119至141)比代表酶或蛋白质-蛋白质相互作用位点的球形结构域更能耐受突变(图2F)。
AlphaMissense achieves state-of-the-art agreement with multiplexed assays of variant effect
AlphaMissense通过变异效应的多重分析实现了最先进的一致性
MAVE实验通过在细胞中表达蛋白质变体并使用生长或荧光读数测量活性,生成变体效应的“主动”图谱(40)。由于MAVE实验密集地覆盖(并且经常饱和)感兴趣的蛋白质,它们提供了关于蛋白质区域的有价值的信息,否则会被稀疏的临床管理所遗漏,尽管MAVE数据的直接临床效用取决于测定读数和实验质量(41)。
为了评估AlphaMissense和MAVE研究之间的一致性,我们根据MAVE数据的两个来源对预测进行了基准测试:ProteinGym中收集的72种蛋白质的150万个变体(19)和由20种最近发表的蛋白质组成的额外基准集(见方法)。相对于其他方法,AlphaMissense与MAVE数据的一致性最强(ProteinGym上的平均Spearman相关性:0.514;附加MAVE基准:0.450;图3,A至C)。当仅限于所有方法评分的25种人类蛋白质的氨基酸变体时,AlphaMissense仍然是13种方法中ProteinGym评分最高的方法(平均Spearman相关性:0.474;图3B)。与次优模型相比,AlphaMissense在两个基准中改进了对大多数蛋白质的预测[62/72,相对于ProteinGym中的预测突变效应的全球突出模型(GEMME)(16),60/72相对于ProteinGym中的EVE,13/20相对于附加MAVE基准中的ESM1v](图S5,A和B)。

图3。AlphaMissense通过变异效应的多重分析实现了最先进的一致性。 (A) MAVE基准测试的性能。ProteinGym(19)是一个包含MAVE数据的72种蛋白质的集合。显示了每个模型的预测和ProteinGym MAVE数据之间的每个蛋白质Spearman相关性的分布,平均值显示为一个点(在小提琴图上方的数字上)。(B) 通过所有方法评分的ProteinGym变体子集(608175个变体,25种人类蛋白质)的性能比较。点表示每种方法中蛋白质之间的平均斯皮尔曼相关性,也在每个小提琴图上方用数字表示。(C) 我们策划了一个额外的20种人类蛋白质的基准数据集,这些蛋白质未包含在ProteinGym中。显示了预测和额外MAVE数据之间的每蛋白质Spearman相关性的分布。(D) SHOC2的前200个氨基酸上的氨基酸取代的观察和预测效果的热图。(上图)通过MAVE测定依赖于SHOC2的癌症细胞的细胞生长,观察到致病性(43)。分数是来自实验测定的百分位标准化测量值。分数接近零(蓝色)的变体保留SHOC2功能,而分数接近一(红色)的变体失去SHOC2功能。(中间和底部热图)AlphaMissense(AM)和EVE致病性评分。这两个分数都在0到1之间,分数越高,致病性越强。没有预测的变体颜色为灰色(请参见EVE热图)。热图上方显示了域级注释(Annot.),包括RVxF和富含亮氨酸重复序列(LRR)区域。还显示了残基水平注释[如来自蛋白质数据库(PDB)ID 7UPI的(43)中计算的],表示表面、核心和蛋白质-蛋白质相互作用残基。(E) SHOC2(蓝色和红色)与MRAS(黄色)和PP1C(金色)复合物的实验衍生结构[PDB ID 7UPI(43)]。每个位置的平均AlphaMissense致病性得分显示在SHOC2结构中,蓝色对应良性,红色对应致病性。(插图)接触PP1C的SHOC2的RVxF结合区以及接触MRAS和PP1C的LRR区的特写。(F) GCK(蓝色和红色)的实验推导结构[PDB ID 3F9M(55)]。每个位置的平均AlphaMissense致病性得分显示在GCK结构中,蓝色对应良性,红色对应致病性。还显示了活性位点配体(黄色)和变构抑制剂(绿色)。(插图)与配体(如D205,催化位点)接触的残基和与变构抑制剂结合的残基(如T65I)的特写。(G) 葡萄糖激酶突变体(56)对AlphaMissense致病性的相对活性指数的比较。在logx轴上,得分为1表示相当于野生型的体外活动,得分低于1表示活动较少,得分高于1表示多动。Spearman相关性显示在面板的左下方。每个点代表不同的蛋白质变体,根据AlphaMissense分类阈值进行着色。该形状表示临床标签(45)。虚线显示了体外测量与AlphaMissense致病性之间的线性拟合。引起高胰岛素血症性低血糖(HH)的T65I被标记。MODY,年轻人的成熟期糖尿病。
我们将观察到的MAVE数据和可用的模型预测与实验解析的蛋白质结构和疾病相关蛋白质的结构域注释进行了比较。SHOC2蛋白与MRAS和PP1C形成复合物,以激活癌症中的Ras-MAPK(促分裂原活化蛋白激酶)信号通路(42)。AlphaMissense致病性与MAVE数据相关,MAVE数据测量SHOC2变体对Ras-活化的癌症细胞适应性的影响(43)(斯皮尔曼相关性:0.47),优于ESM1v、ESM1b和EVE(斯皮尔曼相关:分别为0.41、0.40和0.32;图S5B)。
我们研究了AlphaMissense是否能更好地捕捉SHOC2内特定结构域驱动的致病性,这将通过每个氨基酸位置的平均致病性来反映。每个位置的AlphaMissense平均致病性与每个位置的MAVE平均值非常一致(位置Spearman相关性:0.64),优于ESM1b、ESM1v和EVE(位置Speadman相关性:分别为0.56、0.55和0.48;图S5C)。根据MAVE测定,在SHOC2的前80个氨基酸中,位置63至74是致病性的(图3D)。该区域在结构上显示通过RVxF基序结合PP1C(43)(图3E)。AlphaMissense是唯一能够正确预测该功能重要区域突变致病作用的模型(图3D和图S5D)。此外,在第80位之后,MAVE数据和AlphaMissense预测的致病性大约每23个氨基酸达到一个峰值(图3D),对应于大约每隔23个氨基酸接触MRAS和PP1C的20个富含亮氨酸的重复结构域(图第3、D和E段)。总体而言,直接接触MRAS或PP1C的残基得分为高致病性(中位AlphaMissense致病性:分别为0.98和0.96),几乎与核心疏水性残基一样高(中位alphaMissenses致病性:0.99),并且高于不形成蛋白质-蛋白质接触的表面残基(中位lphaMisense致病力:0.51;图S5E)。
接下来,我们试图确定20种可能的氨基酸中每一种的平均取代效应是否更好地反映在我们的模型中,这是由它们的化学性质驱动的。对于SHOC2,与其他模型相比,AlphaMissense与测量的每个氨基酸的平均取代效应最为一致(图S5C)。总的来说,当在ProteinGym中的所有蛋白质和额外的MAVE基准中以这种方式计算时,AlphaMissense在氨基酸取代和位置度量方面显示出最高的平均性能,表明结构域水平致病性预测和氨基酸特性的改善都是模型性能的基础(ProteinGym上的平均位置Spearman相关性:0.54;ProteinGy姆上的平均取代Spearman相关:0.545;图S5F)。
另一个实例蛋白质是人葡萄糖传感器GCK。降低GCK活性的变体可导致年轻人成熟期糖尿病(MODY)(44)。AlphaMissense致病性与MAVE数据相关,MAVE数据测量在葡萄糖存在下表达人GCK变体的营养缺陷型酵母菌株的适应性(45)(Spearman相关性:0.53),优于ESM1v、EVE和ESM1b(Spearmman相关性:分别为0.49、0.48和0.45;图S5B)。GCK主要起催化葡萄糖的作用;催化残基Asp205(D205)是平均AlphaMissense致病性排名最高的残基(0.999),与配体直接接触的其他残基也具有类似的致病性(图3F)。在携带GCK错义变体的患者中,AlphaMisense致病性与空腹血糖下降有关(Spearman相关性:−0.49)(45)。AlphaMissense致病性与36种临床变体的体外GCK活性测量结果呈对数线性关系(Spearman相关性:−0.65;图3G),达不到MAVE数据估计的实验准确性(Spearmman相关性:0.75),但比其他预测方法更接近(ESM1v:0.61;ESM1b:0.50;EVE:−0.50;图S5G)。根据AlphaMissense的高致病性变体表现出较低数量级的GCK活性,这与大多数临床证实的致病性GCK变体是活性降低的MODY变体的事实一致。另一方面,少数过度活跃的致病性变体[聚集在变构位点附近,例如Thr65→Ile(T65I)](图3F和图S5H)可引起高胰岛素血症性低血糖(44)。AlphaMissense通常将这些分类为模糊或良性(图3G)。












:反射介绍)



)
)

